前言:
在现代软件开发中,数据存储和处理是至关重要的一环。为了高效地管理数据,并实现快速的读写操作,各种数据库技术应运而生。其中,Redis作为一种高性能的内存数据库,广泛应用于缓存、会话存储、消息队列等场景。要深入了解Redis的工作原理,就必须先了解其底层数据结构。
Redis之所以能够在性能上表现出色,部分原因在于其精心设计的数据结构。这些数据结构不仅简单高效,而且能够满足各种复杂的数据处理需求。本文将深入探讨Redis底层数据结构的设计原理,包括字符串、哈希、列表、集合、有序集合等,希望能够帮助读者更好地理解Redis的内部机制,为进一步应用和优化Redis提供指导。
在前面的文章中,我们介绍了Redis的底层数据结构,而这篇文章,我们来介绍一下Redis中能够被我们直接使用的数据结构
底层数据结构:
【从零开始学习Redis | 第七篇】认识Redis底层数据结构(上)-CSDN博客文章浏览阅读1k次,点赞14次,收藏13次。在现代软件开发中,数据存储和处理是至关重要的一环。为了高效地管理数据,并实现快速的读写操作,各种数据库技术应运而生。其中,Redis作为一种高性能的内存数据库,广泛应用于缓存、会话存储、消息队列等场景。要深入了解Redis的工作原理,就必须先了解其底层数据结构。Redis之所以能够在性能上表现出色,部分原因在于其精心设计的数据结构。这些数据结构不仅简单高效,而且能够满足各种复杂的数据处理需求。本文将深入探讨Redis底层数据结构的设计原理,包括字符串哈希列表集合有序集合。
https://liyuanxin.blog.csdn.net/article/details/136991225

目录
前言:
String:
List:
Set:
ZSet:
Hash:
总结:
String:
String 是Redis中最常见的部分,他的基本编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512mb。
我们用图片来表示一下数据结构(RAW):

如果存储的SDS长度小于44字节,则会采用EMBSTR编码,此时object head 和SDS是一段连续空间,申请内存的时候只需要调用一次内存分配函数,效率更高。
我们来看一下EMBSTR作为编码方式时的数据结构:

也就是说:当我们采用EMBSTR来作为编码方式的时候,能够减少内存申请的次数,而内存的申请需要操作系统从用户态转变为内核态,因此减少了内存申请的次数,就变相提升了效率。
当我们存储的字符串是整数的时候,而且大小在LONG_MAX(2,147,483,647)范围内,则会采用INT编码,直接把数据保存在ptr指针位置,不再需要SDS。

EMBSTR为什么最大存储44个字节?
Redis的底层采用的是 jemalloc 这种内存回收算法,而这个算法在分配内存的时候,会以去做内存分配,而64字节是Redis的分片大小,也就是说:如果我们采用一整个分片的话,就不会产生内存碎片。
那么我们来看看:RedisObject头部的字节数为16。我们采用最节省空间的SDS结构也会占据三个个字节大小(len,alloc,flags),加上字符串结束标识符“/0”,我们能够存储字符串的最大字节数就是:64 - 16 - 4 = 44字节。
这也就是为什么EMBSTR编码方式能够存储的最大字节数为44字节的原因。
我们可以用Redis中的这个命令来查看此时的编码方式:
object encoding name1.存入范围小于LONG_MAX的整数:

2.存入字节数小于44的字符串:

3.存入字节数大于44的字符串:
结果:

List:
在Redis3.2版本之前,Redis采用的是ZipList和LinkedList来实现List,当元素数量小于512且元素大小小于64字节的时候采用ZipList,超过则采用LinkedList编码。
在3.2之后,Redis同一采用QuicList来实现List。
在当前的最新版本中,redis引入了一个新的数据结构:ListPack。来作为List的底层数据结构。
我们来看一看整个发展流程:
因为可以节省内存空间,创造了ZipList结构体---->因为为了降低连锁更新的影响面,创造了QuickList---->为了解决连锁更新问题,创建了ListPack
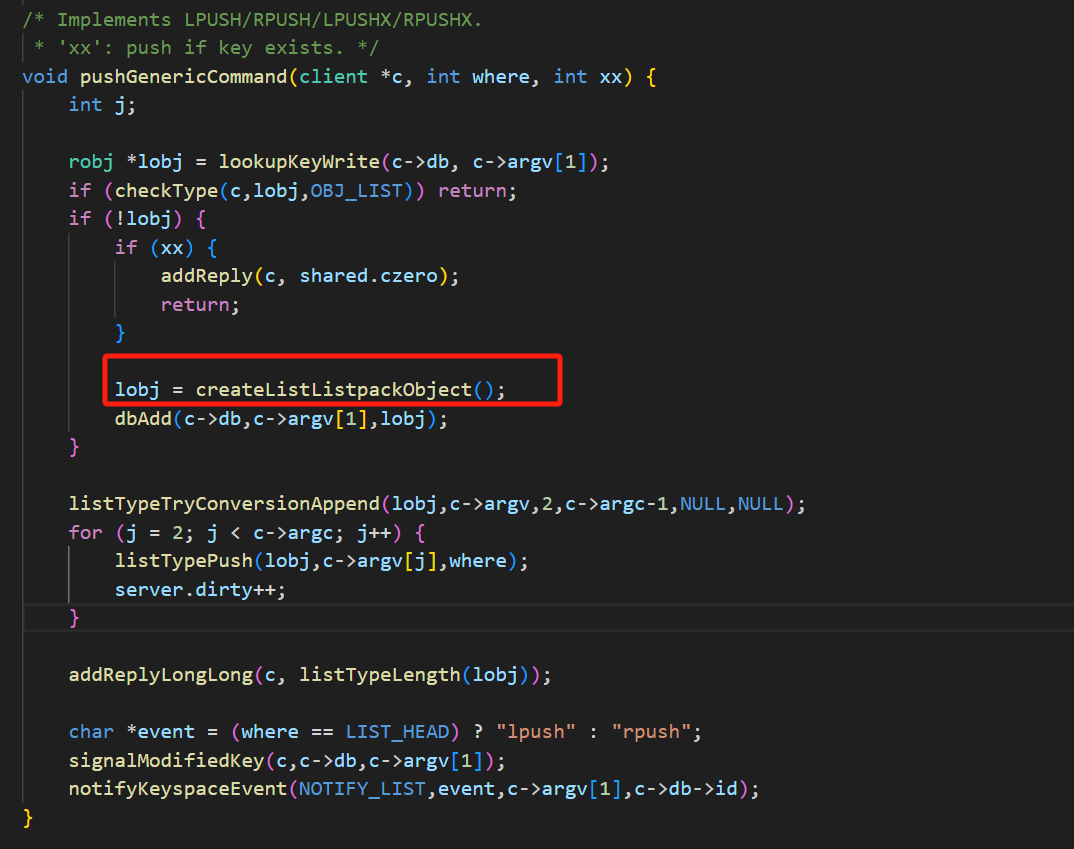
创建新的数据结构调用的是这个方法,我们点进去看一看:

在这里我们创建了一个类型叫做Listpack的变量。因此我们来看一看这个数据结构。

通过对listpackEntry源码的查看,我们可以发现:
为了规避掉zipList的连续更新的风险,listPack不再记录上一个结点的长度,而是改为记录本节点自身的长度。

在listpack.c文件中,官方用了大量的宏定义来指定编码类型:
#define LP_ENCODING_7BIT_UINT 0
#define LP_ENCODING_7BIT_UINT_MASK 0x80
#define LP_ENCODING_IS_7BIT_UINT(byte) (((byte)&LP_ENCODING_7BIT_UINT_MASK)==LP_ENCODING_7BIT_UINT)
#define LP_ENCODING_7BIT_UINT_ENTRY_SIZE 2#define LP_ENCODING_6BIT_STR 0x80
#define LP_ENCODING_6BIT_STR_MASK 0xC0
#define LP_ENCODING_IS_6BIT_STR(byte) (((byte)&LP_ENCODING_6BIT_STR_MASK)==LP_ENCODING_6BIT_STR)#define LP_ENCODING_13BIT_INT 0xC0
#define LP_ENCODING_13BIT_INT_MASK 0xE0
#define LP_ENCODING_IS_13BIT_INT(byte) (((byte)&LP_ENCODING_13BIT_INT_MASK)==LP_ENCODING_13BIT_INT)
#define LP_ENCODING_13BIT_INT_ENTRY_SIZE 3#define LP_ENCODING_12BIT_STR 0xE0
#define LP_ENCODING_12BIT_STR_MASK 0xF0
#define LP_ENCODING_IS_12BIT_STR(byte) (((byte)&LP_ENCODING_12BIT_STR_MASK)==LP_ENCODING_12BIT_STR)#define LP_ENCODING_16BIT_INT 0xF1
#define LP_ENCODING_16BIT_INT_MASK 0xFF
#define LP_ENCODING_IS_16BIT_INT(byte) (((byte)&LP_ENCODING_16BIT_INT_MASK)==LP_ENCODING_16BIT_INT)
#define LP_ENCODING_16BIT_INT_ENTRY_SIZE 4#define LP_ENCODING_24BIT_INT 0xF2
#define LP_ENCODING_24BIT_INT_MASK 0xFF
#define LP_ENCODING_IS_24BIT_INT(byte) (((byte)&LP_ENCODING_24BIT_INT_MASK)==LP_ENCODING_24BIT_INT)
#define LP_ENCODING_24BIT_INT_ENTRY_SIZE 5#define LP_ENCODING_32BIT_INT 0xF3
#define LP_ENCODING_32BIT_INT_MASK 0xFF
#define LP_ENCODING_IS_32BIT_INT(byte) (((byte)&LP_ENCODING_32BIT_INT_MASK)==LP_ENCODING_32BIT_INT)
#define LP_ENCODING_32BIT_INT_ENTRY_SIZE 6#define LP_ENCODING_64BIT_INT 0xF4
#define LP_ENCODING_64BIT_INT_MASK 0xFF
#define LP_ENCODING_IS_64BIT_INT(byte) (((byte)&LP_ENCODING_64BIT_INT_MASK)==LP_ENCODING_64BIT_INT)
#define LP_ENCODING_64BIT_INT_ENTRY_SIZE 10#define LP_ENCODING_32BIT_STR 0xF0
#define LP_ENCODING_32BIT_STR_MASK 0xFF
#define LP_ENCODING_IS_32BIT_STR(byte) (((byte)&LP_ENCODING_32BIT_STR_MASK)==LP_ENCODING_32BIT_STR)
在这之中,int类型的编码方式一共有六种:
- LP_ENCODING_7BIT_UIN
- LP_ENCODING_13BIT_UIN
- LP_ENCODING_16BIT_UIN
- LP_ENCODING_24BIT_UIN
- LP_ENCODING_32BIT_UIN
- LP_ENCODING_64BIT_UIN
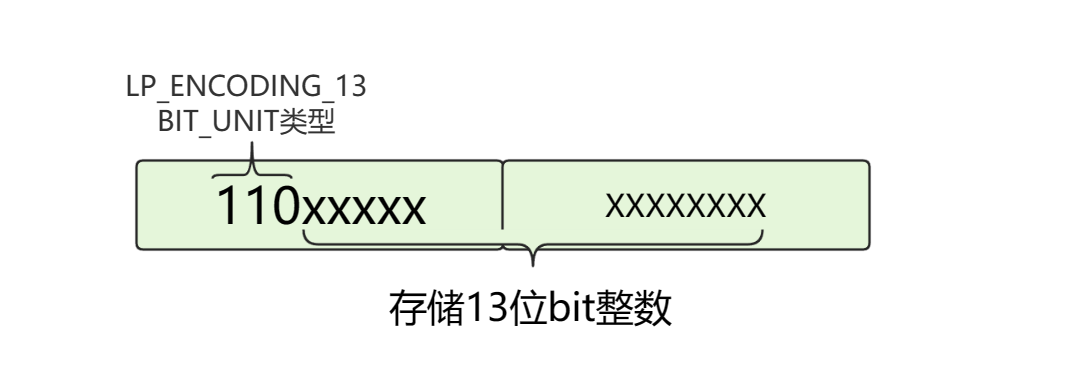
字符串编码方式一共有三种:
- LP_ENCODING_6BIT_STR
- LP_ENCODING_12BIT_STR
- LP_ENCODING_32BIT_STR

我们用图来表示一下listPack的样式:

Set:
set是Redis的单列集合,它满足以下特点:
- 不保证有序性
- 保证元素唯一
- 可以求交集,并集和差集
Set底层为了查询效率和唯一性,set采用HT编码(Dict)。Dict的key用来存储元素,Value统一为null。
我们之前的文章中介绍过Dict这种底层数据结构,感兴趣的可以看一看。
【从零开始学习Redis | 第七篇】认识Redis底层数据结构(上)-CSDN博客文章浏览阅读1k次,点赞14次,收藏13次。在现代软件开发中,数据存储和处理是至关重要的一环。为了高效地管理数据,并实现快速的读写操作,各种数据库技术应运而生。其中,Redis作为一种高性能的内存数据库,广泛应用于缓存、会话存储、消息队列等场景。要深入了解Redis的工作原理,就必须先了解其底层数据结构。Redis之所以能够在性能上表现出色,部分原因在于其精心设计的数据结构。这些数据结构不仅简单高效,而且能够满足各种复杂的数据处理需求。本文将深入探讨Redis底层数据结构的设计原理,包括字符串哈希列表集合有序集合。https://liyuanxin.blog.csdn.net/article/details/136991225当所有存储的数据都是整数的时候,并且元素个数不超过set-max-intset-entries时,Set会采用IntSet编码,以此来节省内存。
如果我们使用IntSet存储编码的时候,存储的元素个数超过了set-max-intset-entries的时候,就会转为Dict来进行存储。
set-max-intset-entries的最大值是512
ZSet:
Zset实际上就是SortedSet,其中每一个元素都需要指定一个socre值和member值,他满足以下特点:
- 可以根据socre值排序
- member必须唯一
- 可以根据member查询分数
也就是说:Zset必须满足键值对存储,键必须唯一,可排序这几个需求
SkipList:可以排序,并且可以同时存储socre值和ele值。
HT(Dict):可以键值对存储,并且可以根据key找Value。
那么ZSet结合了这两种结构体:
typedef struct zset {dict *dict;zskiplist *zsl;
} zset;我们来看一看创建Zset方法:
robj *createZsetObject(void) {zset *zs = zmalloc(sizeof(*zs));robj *o;//创建dictzs->dict = dictCreate(&zsetDictType);//创建ziplistzs->zsl = zslCreate();o = createObject(OBJ_ZSET,zs);o->encoding = OBJ_ENCODING_SKIPLIST;return o;
}它使用dict实现键值对的存储和唯一性,使用Skiplist来实现排序性。Zset的编码声明的是SKPIList。
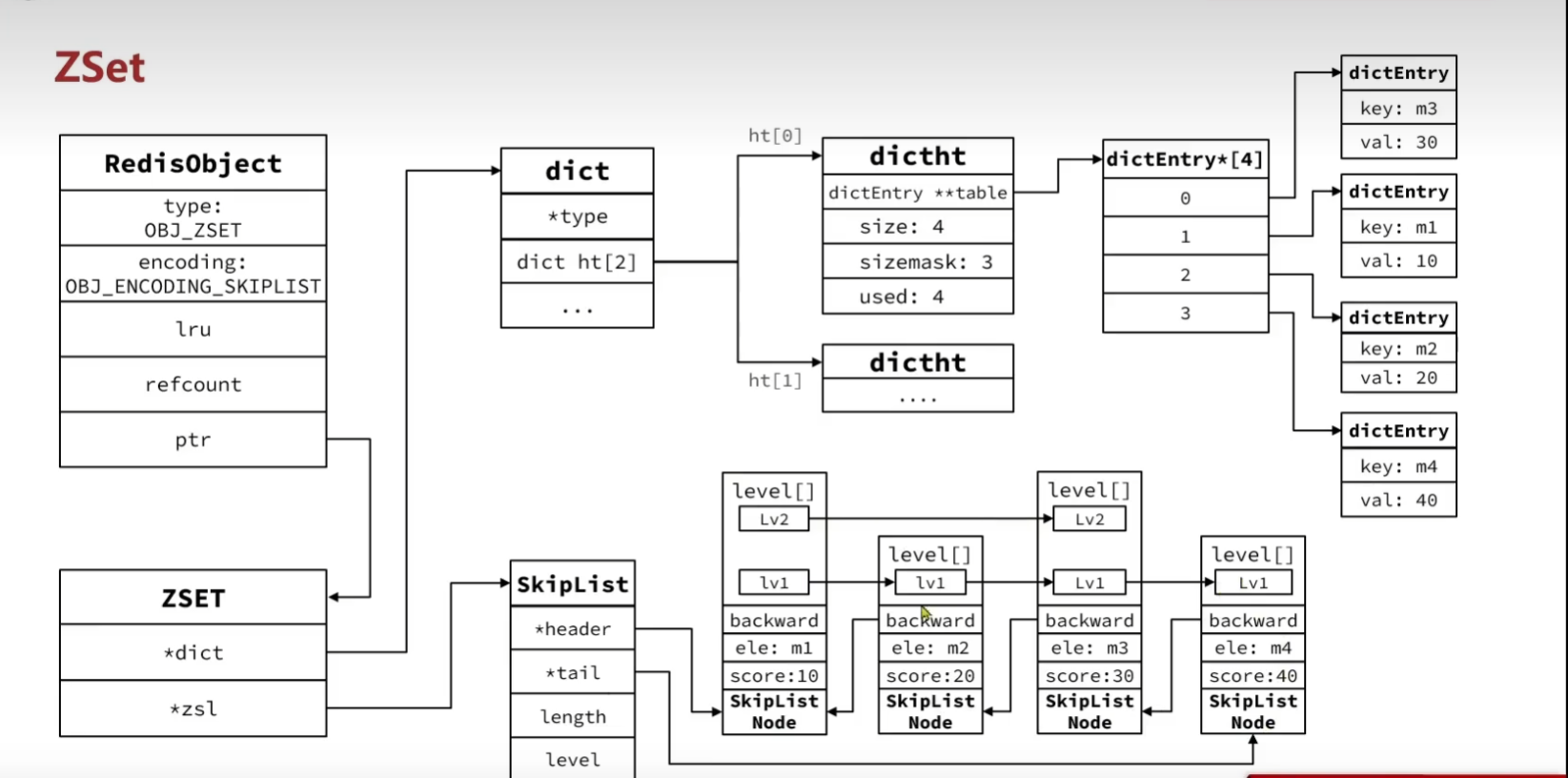 而这种Zset结构实在是太浪费空间了,所以官方也给出了自己的优化方案:
而这种Zset结构实在是太浪费空间了,所以官方也给出了自己的优化方案:
(老)Zset在满足以下条件的时候,会采用ZipList结构来节省内存:
元素数量小于zset_max_ziplist_entries,默认值为128。
每个元素都小于zset_max_ziplist_value,默认值为64。
(新)Zset在满足以下条件的时候,会采用listpackt结构来节省内存:
元素数量小于zset_max_listpack_entries。
每个元素都小于zset_max_listpack_value。
robj *zsetTypeCreate(size_t size_hint, size_t val_len_hint) {if (size_hint <= server.zset_max_listpack_entries &&val_len_hint <= server.zset_max_listpack_value){return createZsetListpackObject();}robj *zobj = createZsetObject();zset *zs = zobj->ptr;dictExpand(zs->dict, size_hint);return zobj;
}
Hash:
Hash结构与Zset的结构非常类似:
- 都是键值对存储。
- 都需要根据键获取值
- 键必须唯一
最关键的是Hash不需要进行排序。Hash的底层默认采用的是ListPack的编码方式。老的版本中是zipList。新版本为了规避ziplist连锁更新的问题,所以大量的替换了原有的ziplist为listpack
robj *createHashObject(void) {unsigned char *zl = lpNew(0);robj *o = createObject(OBJ_HASH, zl);o->encoding = OBJ_ENCODING_LISTPACK;return o;
}在一些情况下,我们会把插入的对象转为dict类型的,在源码中可以看到: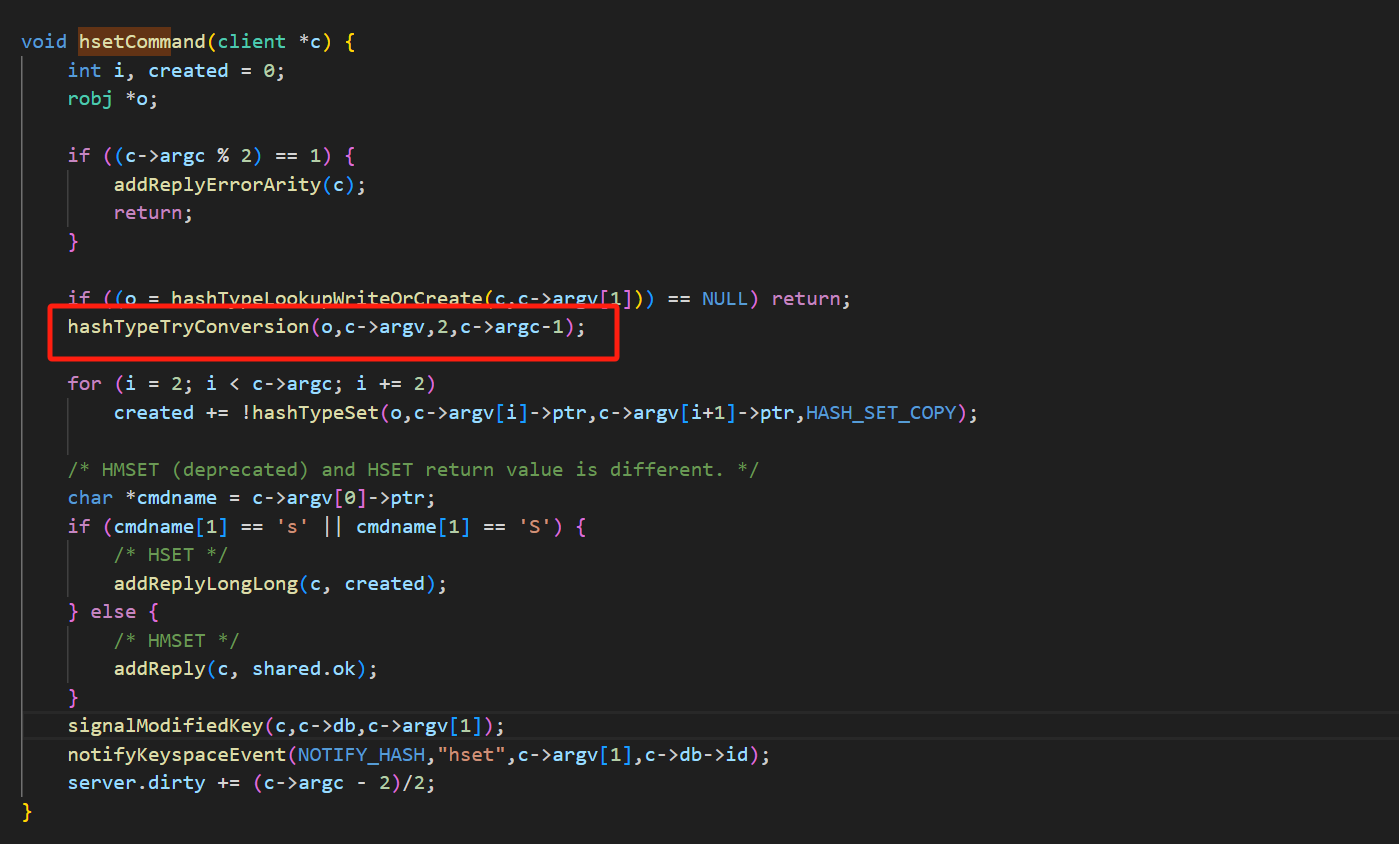
我们点进这个方法:

这段代码是 Redis 中用于尝试将哈希对象转换为合适类型的函数 hashTypeTryConversion。让我解释一下它的主要作用:
-
if (o->encoding != OBJ_ENCODING_LISTPACK) return;: 首先,它检查哈希对象的编码方式是否为列表包装编码。如果不是,则不执行转换,直接返回。 -
计算需要添加到哈希对象的新字段数量,并根据一定的条件决定是否将哈希对象转换为哈希表编码。
-
如果新字段数量超过了预设的阈值
server.hash_max_listpack_entries,则将哈希对象转换为哈希表编码,并根据新字段数量扩展哈希表的空间。 -
遍历输入参数列表中的键值对,计算它们的总长度,并检查每个值的长度是否超过了最大允许长度
server.hash_max_listpack_value。如果有任何一个值的长度超过了限制,则将哈希对象转换为哈希表编码。 -
最后,如果列表包装编码不适合将新字段添加到哈希对象中,或者任何值的长度超过了限制,那么就将哈希对象转换为哈希表编码。
这段代码的作用是在执行 HSET 或 HMSET 命令时,根据参数列表中键值对的特征和限制条件,决定是否将哈希对象转换为哈希表编码,以确保能够有效地存储和操作数据。
总结:
通过本文的介绍,我们深入探讨了 Redis 中常用的数据结构及其应用。Redis 提供了丰富的数据类型,包括字符串、哈希、列表、集合和有序集合,每种数据结构都有其独特的特点和适用场景。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!