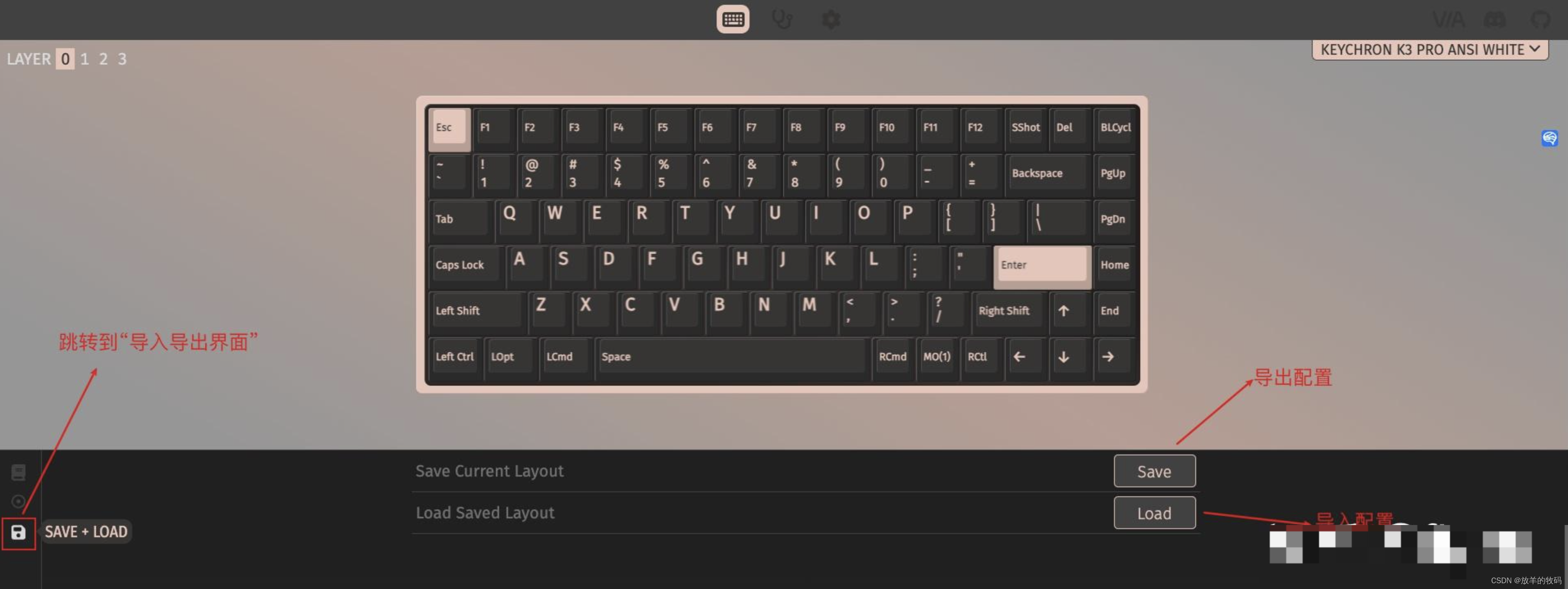
CLoVe:在对比视觉语言模型中编码组合语言
- 摘要
- 引言
- 相关工作
- CLoVe: A Framework to Increase Compositionality in Contrastive VLMs
- Synthetic Captions
- Hard Negatives
- Model Patching
CLoVe: Encoding Compositional Language inContrastive Vision-Language Models
摘要
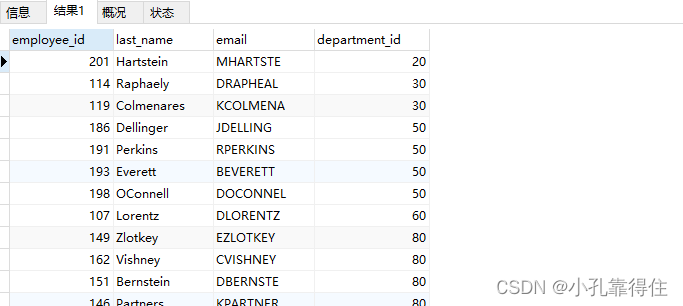
近年来,视觉与语言任务的性能显著提高。基础视觉-语言模型(VLMs),如CLIP,已在多种场景中得到应用,并在多项任务中展现出卓越的性能。这些模型擅长以目标为中心的识别,但学习到的文本表示对词序似乎是不变的,无法以新颖方式组合已知概念。
然而,目前没有证据表明任何VLM,包括大规模的单流模型如GPT-4V,能够成功地识别组合。
在本文中,作者引入了一个框架,可以显著提高现有模型编码组合语言的能力,在组合性基准测试上实现了超过10%的绝对改进,同时在标准的目标识别和检索基准测试上保持或提高性能。
代码和预训练模型:https://github.com/netflix/clove
引言
在过去的几年里,视觉和语言任务的性能有了显著的提升(Radford et al., 2021; Jia et al., 2021; Rombach et al., 2022; Alayrac et al., 2022; Laurencon et al., 2023)。视觉-语言模型(VLMs),如CLIP(Radford et al., 2021),已在多种环境下得到应用,直接或间接作为基础模型,并在多个任务中展示了卓越的性能(Bommasani et al., 2021; Ramesh et al., 2021, 2022; Rombach et al., 2022; Castro和Caba, 2022; Li et al., 2023)。
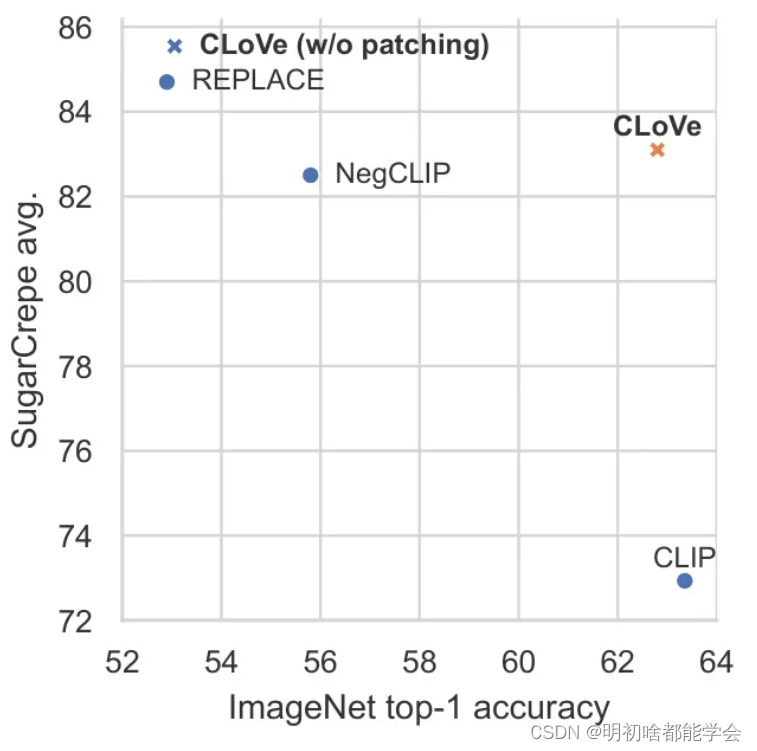
这类模型在以目标为中心的识别上表现出色,但学习到的文本表示似乎对词汇顺序不变(Thrush et al., 2022; Yuksekgonul et al., 2023; Castro et al., 2023),无法以新的方式组合已知概念(Ma et al., 2023; Hsieh et al., 2023)。例如,如图1所示,CLIP在ImageNet任务上性能顶尖,但在组合性基准测试中表现不佳。
语言组合性对于在图像中识别更复杂的概念或使文本到图像模型成功生成具有特定约束的新场景至关重要(Hafri等人,2023年)。例如,在描绘_“女人对男人大喊”_的图像中,正确理解场景的关键是要认识到是谁在向谁大喊。
然而,没有证据表明任何视觉语言模型(VLM),包括大规模的单一流模型如GPT 4V(OpenAI,2023年),能够成功地识别组合。这一论断得到了现有测试组合性的基准仍然是开放挑战这一事实的支持(Thresh等人,2022年;Yuksekgonul等人,2023年;马等人,2023年;Hsieh等人,2023年)。
为了解决这些限制,之前的研究引入了一些技术来增强预训练视觉语言模型(VLMs)的复合能力,例如NegCLIP(Yuksekgonul等人,2023)和REPLACE(Hsieh等人,2023)。然而,这些方法付出了显著的代价:它们牺牲了在更为常见的以目标为中心的识别任务上的性能,这些性能是通过ImageNet(Deng等人,2009)、EuroSAT(Helber等人,2019,2018)和CIFAR100(Krizhevsky,2009)来衡量的。例如,如图1所示,NegCLIP在SugarCrepe(Hsieh等人,2023)复合性基准上的能力相较于预训练模型有所提升,从72.9%增加到82.5%,而与此同时,其在ImageNet(Deng等人,2009)上的top-1准确度从63.4%下降到55.8%。同样,Hsieh等人(2023)应用REPLACE在SugarCrepe上达到了84.7%的高分,但其ImageNet准确度显著下降至52.9%。
在本文中,作者介绍了一个框架,用以显著提高现有双塔模型编码组合语言的能力,同时保持了在更标准基准测试上的性能,如图1所示。具体来说,作者的贡献如下。首先,作者展示了数据策展可以对模型处理组合知识的方式产生重大影响。其次,作者证实了与困难负样本一同训练可以带来额外的改进。第三,作者通过实验证明,模型修补可以用于保持模型在先前任务上的性能。最后,作者将这些想法融合到一个名为CLoVe的新框架中,并展示了它可以在对比预训练的VLM上显著提高组合性。作为一个案例研究,作者展示了作者的框架如何有效地提高CLIP的组合能力,同时保持其他任务上的性能。在发表时,作者将提供预训练权重,供其他人使用,以便用具有显著更好语言组合能力的版本替换其类似CLIP的模型权重。
相关工作
对组合性的基准测试。已经提出了几种框架来衡量模型在语言组合性上的表现。Shekhar等人(2017年)精心设计了一个基准测试,其中包含通过改变正确标题中的一个单词生成的干扰性图像标题。模型必须确定图像和标题对是否相互对应,以及其他任务。Winoground(Thresh等人,2022年)仔细构建了一个由400个示例组成的高质量数据集,每个示例包含两张图片和两个标题。这两个标题包含完全相同的单词,但按照几种策略中的一种以不同的顺序排列(例如,交换主语和宾语)。为了通过这个测试,每张图像必须与正确的标题相匹配。模型不能仅仅依靠它们在图像中识别概念的能力,因为元素虽然重复,但组合方式不同。
迪万等人(2022年)发现,成功通过Winoground基准测试需要组合技能以及其他许多技能,如常识推理和定位微小物体。尤克塞尔贡等人(2023年)认为Winoground太小,无法得出统计上显著性的结论,并构建了一个名为ARO的基准,其中包括单一图像、正确标题和多个自动生成的错误标题的例子。CREPE(马等人,2023年)制定了一个基准,以衡量系统性和生产率方面的组合性。它同时考虑了已见和未见的复合现象。SugarCrepe(谢等人,2023年)是一个最近的基准,它避免了不语法和荒谬的负面标题,同时数据量庞大。他们展示了不能仅通过计算文本标题的概率而不查看图像来轻易解决这一问题。其他基准也已经创建,它们考虑了组合性以及其他现象,例如VALSE(帕卡尔贝斯库等人,2022年)、RareAct(米奇等人,2020年)、VL-Checklist(赵等人,2022年)、Cola(雷等人,2023年)、SVO-Probes(亨德里克斯和内马茨哈德,2021年)和CLEVR(约翰逊等人,2017年)
提高组合性的方法。几项研究显示视觉语言模型(VLMs)无法成功地识别组合(Shekhar et al., 2017; Miech et al., 2020; Parcalabescu et al., 2022; Thrush et al., 2022; Hendricks and Nematzadeh, 2021; Yuksekgonul et al., 2023; Castro et al., 2023; Ma et al., 2023)。因此,提出了NegCLIP(Yuksekgonul et al., 2023)以改进CLIP(Radford et al., 2021)概念组合的方式。这包括通过获取训练批次中的标题并自动生成含有相同词汇但顺序不同的句子来添加困难负文本。这种方法使模型能够区分正确顺序的图像与标题与任意顺序的确切词汇(以及批次内其他负标题)。Hsieh等人(2023)在NegCLIP和CREPE(Ma et al., 2023)的基础上,提出了三种生成随机负样本的方法:REPLACE,SWAP和NEGATE。所有这些方法都从句子的场景图表示出发并对其进行操作。REPLACE,取得了最好的整体效果,执行单一原子的替换。SWAP在场景图中交换两个原子。最后,NEGATE引入否定词(例如,没有_或_不是)。作者在NegCLIP(Yuksekgonul et al., 2023)和REPLACE(Hsieh et al., 2023)的基础上,提出使用合成生成的标题来扩大规模,并应用模型修补(Ilharco et al., 2022)以避免灾难性遗忘。据作者所知,作者引入了第一种方法,该方法显著提高了对比训练模型的组合技能,同时保留了它们在其他下游任务上的零样本性能。
Cap和CapPa(Tschannen等人,2023年)是两种最近引入的模型,它们采用字幕生成而不是对比学习(如CLIP中那样)来训练视觉语言模型(VLMs)。Tschannen等人(2023年)展示,这些模型在由ARO(Yuksekgonul等人,2023年)和SugarCrepe(Hsieh等人,2023年)测量的组合性方面表现出色。由于这些模型依赖于字幕生成,也即计算给定图像的文本概率,它们对于检索和分类来说效率不高。对于ARO,他们展示无需查看图像就能达到高性能(他们称之为“盲目解码器”)。对于SugarCrepe,作者没有计算这一具体 Baseline 。因此,作者无法推理这些模型在多大程度上成功地处理了组合。作者的方法与它们不同,因为它是建立在对比双塔模型之上的,这些模型对于检索和分类是有效的,且不依赖于计算文本概率,这在这些设置中通常不重要,因为所有文本都是等可能出现的(与图像字幕生成不同)。
CLoVe: A Framework to Increase Compositionality in Contrastive VLMs
为了解决在先前模型中观察到的组合性限制,作者提出了针对开发对比视觉语言模型(VLM)三个主要方面的策略:数据整理、对比学习和模型调优。作者引入了CLoVe框架,它利用现有预训练对比视觉语言模型的优点,并通过语言组合技能进行增强。图2展示了总体概览。
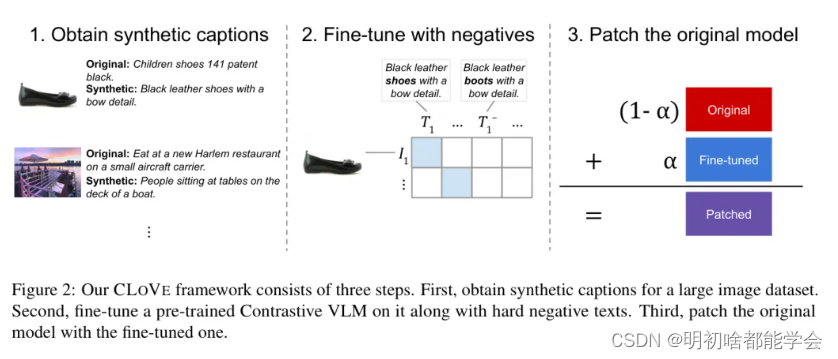
CLoVe包括以下步骤,下面将详细描述:
3.1 综合字幕。:合成数据生成可以有效地用来扩大训练数据集。作者使用了一个带有综合字幕的大型数据集。
3.2 难以区分的负样本。:对比视觉语言模型依赖于负训练数据的可用性。作者在数据集中添加了随机生成的难以区分的文本负样本,并训练了一个具有增强的组合能力的高精度模型。
3.3 模型修补。:通过模型修补将预训练模型和精调模型结合起来。修补使作者能够在保持精调模型获得的组合性的同时,恢复预训练模型在先前支持的任务上的性能。
Synthetic Captions
合成标题在训练数据集大小和标题质量之间提供了很好的结合。作者利用了LAION-COCO(Schuhmann等人,2022年),一个拥有6亿数据集,其中的图片来自LAION-5B(Schuhmann等人,2022年)的20亿规模英文子集,并且使用了BLIP ViT-L/14(Li等人,2022年)生成的标题,该模型在COCO上进行了微调,并使用两种版本的OpenAI预训练CLIP(Radford等人,2021年;ViT-L/14和RN50x64)进行了过滤。尽管标题的风格有限(通常遵循COCO标题的风格),但LAION-COCO的作者发现,合成的生成的标题与人类编写的标题质量相似。作者相信这些标题更多地关注描述视觉信息,而不是其原始数据集(LAION)中的标题,这是基于该数据集的多个示例得出的。有关训练数据集的消融研究,请参见第4.3节。
Hard Negatives
文本硬负例可以强制模型更好地学习每个单词的含义,因为它们需要根据单词在标题中的使用方式判断其是否与图像相关。Yuksekgonul等人(2023年)提出了NegCLIP,这是对CLIP训练过程的扩展,它通过重新排列图像标题单词为批次中的每个示例生成一个硬负文本。这些生成的负例被包含在学习目标的负测试集中。Hsieh等人(2023年)提出了一个名为REPLACE的替代方法,并显示如果这样的负例是从精心挑选的单个单词替换生成的,模型可以实现更好的组合技能。这些替换是在首先将句子解析为场景图,从中获取实体、关系或属性之一,然后通过利用WordNet(Fellbaum, 2010)从它的反义词或同下义词中选择一个替代词来完成的。这些方法依赖于高质量的标题。否则,生成的负例将会有无法视觉欣赏的变化,或者大多数情况下会是不合语法或无意义的,并且模型的下游性能将受到严重影响。以下面的来自LAION的例子为例,它伴随一张卡片持有者的图片:“5x Orange Ball Wedding Party PLACE CARD HOLDER Table Name Memo Paper Note Clip.” 如果作者应用REPLACE,假设作者可以正确解析这个句子,“table"这个词可以被替换为"bed”。然而,这并不会使其成为负例,因为"table"是标题中包含的无法视觉欣赏的附加上下文信息。这样的变化将给模型的训练过程引入更多噪声。
因此,这些研究工作采用了COCO标题(Lin等人,2014;Chen等人,2015)数据集。COCO包含了图像以及高质量的人工标注描述它们的内容。然而,拥有60万图像-文本对,COCO至少比通常使用的图像-文本训练数据集小三个数量级。这个问题限制了学习,并使模型过拟合。此外,COCO呈现的目标和动作的数量有限。在ImageNet-1k的1000个目标类别中,有700个在COCO中不存在(Venugopalan等人,2017)。作者建议将这些困难负样本技术与一个合成标题数据集相结合,例如LAION-COCO(Schuhmann等人,2022)(在上一小节中介绍)。
Model Patching
模型修补(Ilharco等人,2022年)使经过微调的模型能够在保持目标任务性能的同时,恢复之前支持任务上的性能。NegCLIP(Yuksekgonul等人,2023年)和REPLACE(Hsieh等人,2023年)微调模型以显著提高语言组合能力。然而,作为交换,它们牺牲了在一般物体识别上的性能,如通过它们的ImageNet性能所衡量的那样。因此,作者建议应用其中一种方法,然后接着使用模型修补。这个过程包括在预训练模型和微调模型之间执行权重空间的平均。具体来说,对于每个预训练模型权重 和微调模型权重 ,作者计算它们的加权平均以得到新的模型权重 :
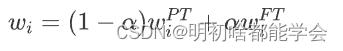
在4.3节中,作者展示了这种方法帮助模型获得了组合性特性,同时保持了其目标识别性能。