1、简单介绍
首先说明,本文目的主要是水一篇CSDN博客,顺便说一下和标题相关的认识。
近几年,在目标检测领域关于多模态的目标检测工作已成了主流,趋势仍在延续,未来仍有很大挖掘空间。这里说的多模态不是简单的多源数据的多模态,比如不同形式的图像数据等,这里是文本和图像的数据,对标自然语言处理领域和计算机视觉领域。
在看了一些结合文本的目标检测的工作后,主要是OVD方向的,总感觉这些网络有些复杂,或许是数据处理上,既需要文本标签,又要文本向量,还要一些特殊的预训练模型,在过程中稍显复杂。然后是网络结构的理解,如何将文本加进来的,又是怎么把文本和图像进行处理的,模型是怎么训练更新参数的?这些都曾让我疑惑。
我也在不断地查看文献等相关工作,试图有更深的理解。我一开始就想简单的把类别换成文本名称,甚至想在yolov5上写一个网络实现这种功能,但当我实际思索起来时,我发现事情也没那么容易。我要把文本处理模块加入到现有的图像处理网络中,要让两个模块的文本特征和视觉特征进行相似度度量;在head模块中还要实现文本驱动的位置解码,这都让我觉得这并没有那么简单。
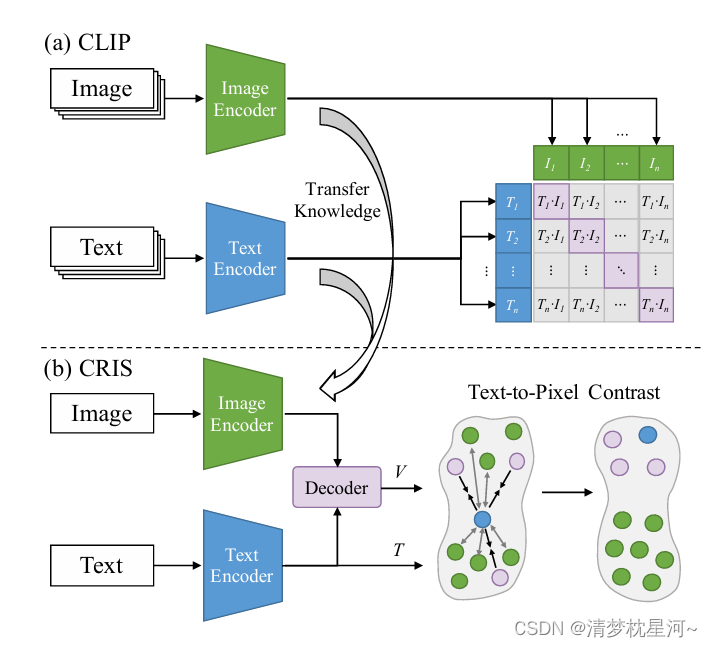
于是我开始找较早和文本结合的视觉解译工作,发现较早的可能是语义分割方向的研究,直接通过文本对图像进行分割,真正的将文本处理和图像处理的模块集成到一个网络中我关注到的文章是这篇:CRIS: CLIP-Driven Referring Image Segmentation,时间是2022年,也不算早,作为了解在目标检测如何加文本模块还是可以提供帮助的。语义分割任务的目标是把像素进行分类,比类别和定位输出的目标检测要简单,所以理解了这个的操作,在目标检测上也很好理解。
CRIS: CLIP-Driven Referring Image Segmentation的论文网址:
https://openaccess.thecvf.com/content/CVPR2022/papers/Wang_CRIS_CLIP-Driven_Referring_Image_Segmentation_CVPR_2022_paper.pdf
对应的代码网址:https://github.com/DerrickWang005/CRIS.pytorch
从下面的图中可以看到大致的网络结构:

其实在了解的多了以后,也就觉得其实这种语义分割还是目标检测其实就是加了一个文本进去,本质上对图像解译还是促进作用有限,不过显得花里胡哨一些。语义分割加文本有什么意义?文本、视觉特征匹配提升分割精度?感觉没那么神奇。所以为什么没有直接 CLIP-Driven Referring Image Object Detection,而是转为OVD,既用文本替换了类别的数字代号,又有zero-shot的检测能力,就是检测新类别,显然这样讲故事的可读性要高一些,所以直接找加文本做目标检测的工作不好找。
2、新的看法
既然直接找加文本做目标检测的工作不好找,那么这些OVD的工作其实已经实现了加文本进行目标检测的工作,那么能不能从中找到好迁移的OVD网络,迁移到我们自己的数据集中做模型训练,显然是可以的。
前面已经说了OVD具备文本编码解码能力,只要找到一种具有普适性的网络,可以对不同的文本进行处理,可以制作多样的数据集进行学习训练,那对结合文本的目标检测的学习就找到方向了,所以接下来更深入的去学习发现一些OVD研究工作,将有效帮助理解这个方向的认识。
相关的学习网站:
Open-Vocabulary-Object-Detection:https://github.com/witnessai/Awesome-Open-Vocabulary-Object-Detection
Open-Vocabulary-Semantic-Segmentation:https://github.com/Qinying-Liu/Awesome-Open-Vocabulary-Semantic-Segmentation
Referring-Image-Segmentation:https://github.com/MarkMoHR/Awesome-Referring-Image-Segmentation

3、CRIS的结构附录
import torch
import torch.nn as nn
import torch.nn.functional as Ffrom model.clip import build_modelfrom .layers import FPN, Projector, TransformerDecoderclass CRIS(nn.Module):def __init__(self, cfg):super().__init__()# Vision & Text Encoderclip_model = torch.jit.load(cfg.clip_pretrain,map_location="cpu").eval()self.backbone = build_model(clip_model.state_dict(), cfg.word_len).float()# Multi-Modal FPNself.neck = FPN(in_channels=cfg.fpn_in, out_channels=cfg.fpn_out)# Decoderself.decoder = TransformerDecoder(num_layers=cfg.num_layers,d_model=cfg.vis_dim,nhead=cfg.num_head,dim_ffn=cfg.dim_ffn,dropout=cfg.dropout,return_intermediate=cfg.intermediate)# Projectorself.proj = Projector(cfg.word_dim, cfg.vis_dim // 2, 3)def forward(self, img, word, mask=None):'''img: b, 3, h, wword: b, wordsword_mask: b, wordsmask: b, 1, h, w'''# padding mask used in decoderpad_mask = torch.zeros_like(word).masked_fill_(word == 0, 1).bool()# vis: C3 / C4 / C5# word: b, length, 1024# state: b, 1024vis = self.backbone.encode_image(img)word, state = self.backbone.encode_text(word)# b, 512, 26, 26 (C4)fq = self.neck(vis, state)b, c, h, w = fq.size()fq = self.decoder(fq, word, pad_mask)fq = fq.reshape(b, c, h, w)# b, 1, 104, 104pred = self.proj(fq, state)if self.training:# resize maskif pred.shape[-2:] != mask.shape[-2:]:mask = F.interpolate(mask, pred.shape[-2:],mode='nearest').detach()loss = F.binary_cross_entropy_with_logits(pred, mask)return pred.detach(), mask, losselse:return pred.detach()
可以看到 clip_model 、backbone 、neck 和 decoder 的结构定义,具体结构的定义可以继续深入看代码。上面的forward函数还包含了损失函数 binary_cross_entropy_with_logits,整体结构还是比较简单的。大致了解这个之后对了解OVD上加入文本也会更好理解过渡。