目录
简介
导入
超参数
MobileViT 实用程序
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras机器学习实战
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
本文目标:MobileViT 利用卷积和变换器的综合优势进行图像分类。
简介
在本示例中,我们实现了 MobileViT 架构(Mehta 等人),该架构结合了 Transformers(Vaswani 等人)和卷积的优点。通过变换器,我们可以捕捉长距离依赖关系,从而实现全局表示。通过卷积,我们可以捕捉空间关系,从而建立局部模型。
除了结合变换器和卷积的特性,作者还介绍了 MobileViT,将其作为通用的移动友好骨干,用于不同的图像识别任务。他们的研究结果表明,从性能上看,MobileViT 优于其他具有相同或更高复杂度的模型(例如 MobileNetV3),同时在移动设备上也很高效。
注:本示例应在 Tensorflow 2.13 及更高版本上运行。
导入
import os
import tensorflow as tfos.environ["KERAS_BACKEND"] = "tensorflow"import keras
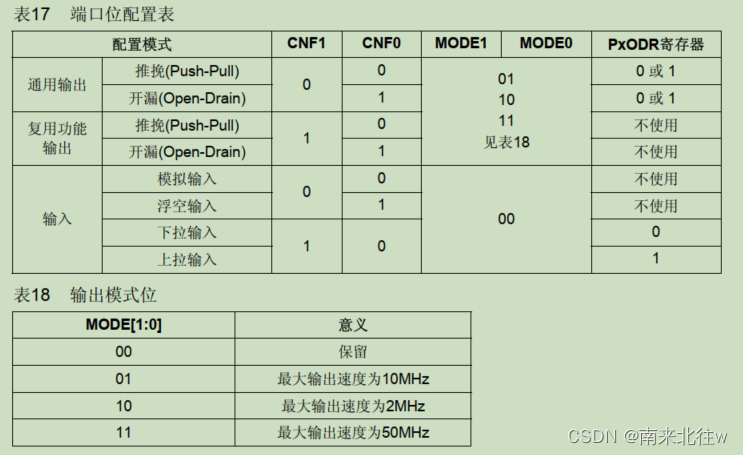
from keras import layers
from keras import backendimport tensorflow_datasets as tfdstfds.disable_progress_bar()超参数
# Values are from table 4.
patch_size = 4 # 2x2, for the Transformer blocks.
image_size = 256
expansion_factor = 2 # expansion factor for the MobileNetV2 blocks.MobileViT 实用程序
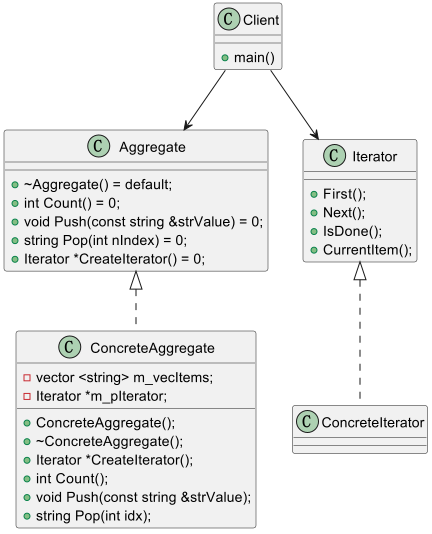
MobileViT 架构由以下模块组成:
处理输入图像的阶梯式 3x3 卷积。
MobileNetV2 风格的反转残差块,用于降低中间特征图的分辨率。
MobileViT 块,结合了变换器和卷积的优势。
如下图所示(摘自论文原文):
def conv_block(x, filters=16, kernel_size=3, strides=2):conv_layer = layers.Conv2D(filters,kernel_size,strides=strides,activation=keras.activations.swish,padding="same",)return conv_layer(x)# Reference: https://github.com/keras-team/keras/blob/e3858739d178fe16a0c77ce7fab88b0be6dbbdc7/keras/applications/imagenet_utils.py#L413C17-L435def correct_pad(inputs, kernel_size):img_dim = 2 if backend.image_data_format() == "channels_first" else 1input_size = inputs.shape[img_dim : (img_dim + 2)]if isinstance(kernel_size, int):kernel_size = (kernel_size, kernel_size)if input_size[0] is None:adjust = (1, 1)else:adjust = (1 - input_size[0] % 2, 1 - input_size[1] % 2)correct = (kernel_size[0] // 2, kernel_size[1] // 2)return ((correct[0] - adjust[0], correct[0]),(correct[1] - adjust[1], correct[1]),)# Reference: https://git.io/JKgtCdef inverted_residual_block(x, expanded_channels, output_channels, strides=1):m = layers.Conv2D(expanded_channels, 1, padding="same", use_bias=False)(x)m = layers.BatchNormalization()(m)m = keras.activations.swish(m)if strides == 2:m = layers.ZeroPadding2D(padding=correct_pad(m, 3))(m)m = layers.DepthwiseConv2D(3, strides=strides, padding="same" if strides == 1 else "valid", use_bias=False)(m)m = layers.BatchNormalization()(m)m = keras.activations.swish(m)m = layers.Conv2D(output_channels, 1, padding="same", use_bias=False)(m)m = layers.BatchNormalization()(m)if keras.ops.equal(x.shape[-1], output_channels) and strides == 1:return layers.Add()([m, x])return m# Reference:
# https://keras.io/examples/vision/image_classification_with_vision_transformer/def mlp(x, hidden_units, dropout_rate):for units in hidden_units:x = layers.Dense(units, activation=keras.activations.swish)(x)x = layers.Dropout(dropout_rate)(x)return xdef transformer_block(x, transformer_layers, projection_dim, num_heads=2):for _ in range(transformer_layers):# Layer normalization 1.x1 = layers.LayerNormalization(epsilon=1e-6)(x)# Create a multi-head attention layer.attention_output = layers.MultiHeadAttention(num_heads=num_heads, key_dim=projection_dim, dropout=0.1)(x1, x1)# Skip connection 1.x2 = layers.Add()([attention_output, x])# Layer normalization 2.x3 = layers.LayerNormalization(epsilon=1e-6)(x2)# MLP.x3 = mlp(x3,hidden_units=[x.shape[-1] * 2, x.shape[-1]],dropout_rate=0.1,)# Skip connection 2.x = layers.Add()([x3, x2])return xdef mobilevit_block(x, num_blocks, projection_dim, strides=1):# Local projection with convolutions.local_features = conv_block(x, filters=projection_dim, strides=strides)local_features = conv_block(local_features, filters=projection_dim, kernel_size=1, strides=strides)# Unfold into patches and then pass through Transformers.num_patches = int((local_features.shape[1] * local_features.shape[2]) / patch_size)non_overlapping_patches = layers.Reshape((patch_size, num_patches, projection_dim))(local_features)global_features = transformer_block(non_overlapping_patches, num_blocks, projection_dim)# Fold into conv-like feature-maps.folded_feature_map = layers.Reshape((*local_features.shape[1:-1], projection_dim))(global_features)# Apply point-wise conv -> concatenate with the input features.folded_feature_map = conv_block(folded_feature_map, filters=x.shape[-1], kernel_size=1, strides=strides)local_global_features = layers.Concatenate(axis=-1)([x, folded_feature_map])# Fuse the local and global features using a convoluion layer.local_global_features = conv_block(local_global_features, filters=projection_dim, strides=strides)return local_global_features更多关于 MobileViT 区块的信息:
首先,特征表示(A)要经过卷积块,以捕捉局部关系。这里单个条目的预期形状是(h, w, num_channels)。
然后,它们会被展开成另一个形状为(p, n, num_channels)的向量,其中 p 是一个小块的面积,n 是(h * w)/p。展开后的矢量会经过一个变换器模块,以捕捉补丁之间的全局关系。输出向量(B)再次被折叠成一个形状(h、w、num_channels)类似于卷积产生的特征图的向量。
然后,向量 A 和 B 再经过两个卷积层,将局部和全局表征融合在一起。请注意,此时最终向量的空间分辨率保持不变。作者还解释了 MobileViT 块如何与 CNN 的卷积块相似。
更多详情,请参阅原始论文。
接下来,我们将这些模块组合在一起,实现 MobileViT 架构(XXS 变体)。
def create_mobilevit(num_classes=5):inputs = keras.Input((image_size, image_size, 3))x = layers.Rescaling(scale=1.0 / 255)(inputs)# Initial conv-stem -> MV2 block.x = conv_block(x, filters=16)x = inverted_residual_block(x, expanded_channels=16 * expansion_factor, output_channels=16)# Downsampling with MV2 block.x = inverted_residual_block(x, expanded_channels=16 * expansion_factor, output_channels=24, strides=2)x = inverted_residual_block(x, expanded_channels=24 * expansion_factor, output_channels=24)x = inverted_residual_block(x, expanded_channels=24 * expansion_factor, output_channels=24)# First MV2 -> MobileViT block.x = inverted_residual_block(x, expanded_channels=24 * expansion_factor, output_channels=48, strides=2)x = mobilevit_block(x, num_blocks=2, projection_dim=64)# Second MV2 -> MobileViT block.x = inverted_residual_block(x, expanded_channels=64 * expansion_factor, output_channels=64, strides=2)x = mobilevit_block(x, num_blocks=4, projection_dim=80)# Third MV2 -> MobileViT block.x = inverted_residual_block(x, expanded_channels=80 * expansion_factor, output_channels=80, strides=2)x = mobilevit_block(x, num_blocks=3, projection_dim=96)x = conv_block(x, filters=320, kernel_size=1, strides=1)# Classification head.x = layers.GlobalAvgPool2D()(x)outputs = layers.Dense(num_classes, activation="softmax")(x)return keras.Model(inputs, outputs)mobilevit_xxs = create_mobilevit()
mobilevit_xxs.summary()演绎如下:
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 256, 256, 3) 0
__________________________________________________________________________________________________
rescaling (Rescaling) (None, 256, 256, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 128, 128, 16) 448 rescaling[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 128, 128, 32) 512 conv2d[0][0]
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 128, 128, 32) 128 conv2d_1[0][0]
__________________________________________________________________________________________________
tf.nn.silu (TFOpLambda) (None, 128, 128, 32) 0 batch_normalization[0][0]
__________________________________________________________________________________________________
depthwise_conv2d (DepthwiseConv (None, 128, 128, 32) 288 tf.nn.silu[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 128, 128, 32) 128 depthwise_conv2d[0][0]
__________________________________________________________________________________________________
tf.nn.silu_1 (TFOpLambda) (None, 128, 128, 32) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 128, 128, 16) 512 tf.nn.silu_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 128, 128, 16) 64 conv2d_2[0][0]
__________________________________________________________________________________________________
add (Add) (None, 128, 128, 16) 0 batch_normalization_2[0][0] conv2d[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 128, 128, 32) 512 add[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 128, 128, 32) 128 conv2d_3[0][0]
__________________________________________________________________________________________________
tf.nn.silu_2 (TFOpLambda) (None, 128, 128, 32) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
zero_padding2d (ZeroPadding2D) (None, 129, 129, 32) 0 tf.nn.silu_2[0][0]
__________________________________________________________________________________________________
depthwise_conv2d_1 (DepthwiseCo (None, 64, 64, 32) 288 zero_padding2d[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 64, 64, 32) 128 depthwise_conv2d_1[0][0]
__________________________________________________________________________________________________
tf.nn.silu_3 (TFOpLambda) (None, 64, 64, 32) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 64, 64, 24) 768 tf.nn.silu_3[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 64, 64, 24) 96 conv2d_4[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 64, 64, 48) 1152 batch_normalization_5[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 64, 64, 48) 192 conv2d_5[0][0]
__________________________________________________________________________________________________
tf.nn.silu_4 (TFOpLambda) (None, 64, 64, 48) 0 batch_normalization_6[0][0]
__________________________________________________________________________________________________
depthwise_conv2d_2 (DepthwiseCo (None, 64, 64, 48) 432 tf.nn.silu_4[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, 64, 64, 48) 192 depthwise_conv2d_2[0][0]
__________________________________________________________________________________________________
tf.nn.silu_5 (TFOpLambda) (None, 64, 64, 48) 0 batch_normalization_7[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 64, 64, 24) 1152 tf.nn.silu_5[0][0]
__________________________________________________________________________________________________
batch_normalization_8 (BatchNor (None, 64, 64, 24) 96 conv2d_6[0][0]
__________________________________________________________________________________________________
add_1 (Add) (None, 64, 64, 24) 0 batch_normalization_8[0][0] batch_normalization_5[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 64, 64, 48) 1152 add_1[0][0]
__________________________________________________________________________________________________
batch_normalization_9 (BatchNor (None, 64, 64, 48) 192 conv2d_7[0][0]
__________________________________________________________________________________________________
tf.nn.silu_6 (TFOpLambda) (None, 64, 64, 48) 0 batch_normalization_9[0][0]
__________________________________________________________________________________________________
depthwise_conv2d_3 (DepthwiseCo (None, 64, 64, 48) 432 tf.nn.silu_6[0][0]
__________________________________________________________________________________________________
batch_normalization_10 (BatchNo (None, 64, 64, 48) 192 depthwise_conv2d_3[0][0]
__________________________________________________________________________________________________
tf.nn.silu_7 (TFOpLambda) (None, 64, 64, 48) 0 batch_normalization_10[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 64, 64, 24) 1152 tf.nn.silu_7[0][0]
__________________________________________________________________________________________________
batch_normalization_11 (BatchNo (None, 64, 64, 24) 96 conv2d_8[0][0]
__________________________________________________________________________________________________
add_2 (Add) (None, 64, 64, 24) 0 batch_normalization_11[0][0] add_1[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 64, 64, 48) 1152 add_2[0][0]
__________________________________________________________________________________________________
batch_normalization_12 (BatchNo (None, 64, 64, 48) 192 conv2d_9[0][0]
__________________________________________________________________________________________________
tf.nn.silu_8 (TFOpLambda) (None, 64, 64, 48) 0 batch_normalization_12[0][0]
__________________________________________________________________________________________________
zero_padding2d_1 (ZeroPadding2D (None, 65, 65, 48) 0 tf.nn.silu_8[0][0]
__________________________________________________________________________________________________
depthwise_conv2d_4 (DepthwiseCo (None, 32, 32, 48) 432 zero_padding2d_1[0][0]
__________________________________________________________________________________________________
batch_normalization_13 (BatchNo (None, 32, 32, 48) 192 depthwise_conv2d_4[0][0]
__________________________________________________________________________________________________
tf.nn.silu_9 (TFOpLambda) (None, 32, 32, 48) 0 batch_normalization_13[0][0]
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 32, 32, 48) 2304 tf.nn.silu_9[0][0]
__________________________________________________________________________________________________
batch_normalization_14 (BatchNo (None, 32, 32, 48) 192 conv2d_10[0][0]
__________________________________________________________________________________________________
conv2d_11 (Conv2D) (None, 32, 32, 64) 27712 batch_normalization_14[0][0]
__________________________________________________________________________________________________
conv2d_12 (Conv2D) (None, 32, 32, 64) 4160 conv2d_11[0][0]
__________________________________________________________________________________________________
reshape (Reshape) (None, 4, 256, 64) 0 conv2d_12[0][0]
__________________________________________________________________________________________________
layer_normalization (LayerNorma (None, 4, 256, 64) 128 reshape[0][0]
__________________________________________________________________________________________________
multi_head_attention (MultiHead (None, 4, 256, 64) 33216 layer_normalization[0][0] layer_normalization[0][0]
__________________________________________________________________________________________________
add_3 (Add) (None, 4, 256, 64) 0 multi_head_attention[0][0] reshape[0][0]
__________________________________________________________________________________________________
layer_normalization_1 (LayerNor (None, 4, 256, 64) 128 add_3[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 4, 256, 128) 8320 layer_normalization_1[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 4, 256, 128) 0 dense[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 4, 256, 64) 8256 dropout[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 4, 256, 64) 0 dense_1[0][0]
__________________________________________________________________________________________________
add_4 (Add) (None, 4, 256, 64) 0 dropout_1[0][0] add_3[0][0]
__________________________________________________________________________________________________
layer_normalization_2 (LayerNor (None, 4, 256, 64) 128 add_4[0][0]
__________________________________________________________________________________________________
multi_head_attention_1 (MultiHe (None, 4, 256, 64) 33216 layer_normalization_2[0][0] layer_normalization_2[0][0]
__________________________________________________________________________________________________
add_5 (Add) (None, 4, 256, 64) 0 multi_head_attention_1[0][0] add_4[0][0]
__________________________________________________________________________________________________
layer_normalization_3 (LayerNor (None, 4, 256, 64) 128 add_5[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 4, 256, 128) 8320 layer_normalization_3[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 4, 256, 128) 0 dense_2[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 4, 256, 64) 8256 dropout_2[0][0]
__________________________________________________________________________________________________
dropout_3 (Dropout) (None, 4, 256, 64) 0 dense_3[0][0]
__________________________________________________________________________________________________
add_6 (Add) (None, 4, 256, 64) 0 dropout_3[0][0] add_5[0][0]
__________________________________________________________________________________________________
reshape_1 (Reshape) (None, 32, 32, 64) 0 add_6[0][0]
__________________________________________________________________________________________________
conv2d_13 (Conv2D) (None, 32, 32, 48) 3120 reshape_1[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 32, 32, 96) 0 batch_normalization_14[0][0] conv2d_13[0][0]
__________________________________________________________________________________________________
conv2d_14 (Conv2D) (None, 32, 32, 64) 55360 concatenate[0][0]
__________________________________________________________________________________________________
conv2d_15 (Conv2D) (None, 32, 32, 128) 8192 conv2d_14[0][0]
__________________________________________________________________________________________________
batch_normalization_15 (BatchNo (None, 32, 32, 128) 512 conv2d_15[0][0]
__________________________________________________________________________________________________
tf.nn.silu_10 (TFOpLambda) (None, 32, 32, 128) 0 batch_normalization_15[0][0]
__________________________________________________________________________________________________
zero_padding2d_2 (ZeroPadding2D (None, 33, 33, 128) 0 tf.nn.silu_10[0][0]
__________________________________________________________________________________________________
depthwise_conv2d_5 (DepthwiseCo (None, 16, 16, 128) 1152 zero_padding2d_2[0][0]
__________________________________________________________________________________________________
batch_normalization_16 (BatchNo (None, 16, 16, 128) 512 depthwise_conv2d_5[0][0]
__________________________________________________________________________________________________
tf.nn.silu_11 (TFOpLambda) (None, 16, 16, 128) 0 batch_normalization_16[0][0]
__________________________________________________________________________________________________
conv2d_16 (Conv2D) (None, 16, 16, 64) 8192 tf.nn.silu_11[0][0]
__________________________________________________________________________________________________
batch_normalization_17 (BatchNo (None, 16, 16, 64) 256 conv2d_16[0][0]
__________________________________________________________________________________________________
conv2d_17 (Conv2D) (None, 16, 16, 80) 46160 batch_normalization_17[0][0]
__________________________________________________________________________________________________
conv2d_18 (Conv2D) (None, 16, 16, 80) 6480 conv2d_17[0][0]
__________________________________________________________________________________________________
reshape_2 (Reshape) (None, 4, 64, 80) 0 conv2d_18[0][0]
__________________________________________________________________________________________________
layer_normalization_4 (LayerNor (None, 4, 64, 80) 160 reshape_2[0][0]
__________________________________________________________________________________________________
multi_head_attention_2 (MultiHe (None, 4, 64, 80) 51760 layer_normalization_4[0][0] layer_normalization_4[0][0]
__________________________________________________________________________________________________
add_7 (Add) (None, 4, 64, 80) 0 multi_head_attention_2[0][0] reshape_2[0][0]
__________________________________________________________________________________________________
layer_normalization_5 (LayerNor (None, 4, 64, 80) 160 add_7[0][0]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 4, 64, 160) 12960 layer_normalization_5[0][0]
__________________________________________________________________________________________________
dropout_4 (Dropout) (None, 4, 64, 160) 0 dense_4[0][0]
__________________________________________________________________________________________________
dense_5 (Dense) (None, 4, 64, 80) 12880 dropout_4[0][0]
__________________________________________________________________________________________________
dropout_5 (Dropout) (None, 4, 64, 80) 0 dense_5[0][0]
__________________________________________________________________________________________________
add_8 (Add) (None, 4, 64, 80) 0 dropout_5[0][0] add_7[0][0]
__________________________________________________________________________________________________
layer_normalization_6 (LayerNor (None, 4, 64, 80) 160 add_8[0][0]
__________________________________________________________________________________________________
multi_head_attention_3 (MultiHe (None, 4, 64, 80) 51760 layer_normalization_6[0][0] layer_normalization_6[0][0]
__________________________________________________________________________________________________
add_9 (Add) (None, 4, 64, 80) 0 multi_head_attention_3[0][0] add_8[0][0]
__________________________________________________________________________________________________
layer_normalization_7 (LayerNor (None, 4, 64, 80) 160 add_9[0][0]
__________________________________________________________________________________________________
dense_6 (Dense) (None, 4, 64, 160) 12960 layer_normalization_7[0][0]
__________________________________________________________________________________________________
dropout_6 (Dropout) (None, 4, 64, 160) 0 dense_6[0][0]
__________________________________________________________________________________________________
dense_7 (Dense) (None, 4, 64, 80) 12880 dropout_6[0][0]
__________________________________________________________________________________________________
dropout_7 (Dropout) (None, 4, 64, 80) 0 dense_7[0][0]
__________________________________________________________________________________________________
add_10 (Add) (None, 4, 64, 80) 0 dropout_7[0][0] add_9[0][0]
__________________________________________________________________________________________________
layer_normalization_8 (LayerNor (None, 4, 64, 80) 160 add_10[0][0]
__________________________________________________________________________________________________
multi_head_attention_4 (MultiHe (None, 4, 64, 80) 51760 layer_normalization_8[0][0] layer_normalization_8[0][0]
__________________________________________________________________________________________________
add_11 (Add) (None, 4, 64, 80) 0 multi_head_attention_4[0][0] add_10[0][0]
__________________________________________________________________________________________________
layer_normalization_9 (LayerNor (None, 4, 64, 80) 160 add_11[0][0]
__________________________________________________________________________________________________
dense_8 (Dense) (None, 4, 64, 160) 12960 layer_normalization_9[0][0]
__________________________________________________________________________________________________
dropout_8 (Dropout) (None, 4, 64, 160) 0 dense_8[0][0]
__________________________________________________________________________________________________
dense_9 (Dense) (None, 4, 64, 80) 12880 dropout_8[0][0]
__________________________________________________________________________________________________
dropout_9 (Dropout) (None, 4, 64, 80) 0 dense_9[0][0]
__________________________________________________________________________________________________
add_12 (Add) (None, 4, 64, 80) 0 dropout_9[0][0] add_11[0][0]
__________________________________________________________________________________________________
layer_normalization_10 (LayerNo (None, 4, 64, 80) 160 add_12[0][0]
__________________________________________________________________________________________________
multi_head_attention_5 (MultiHe (None, 4, 64, 80) 51760 layer_normalization_10[0][0] layer_normalization_10[0][0]
__________________________________________________________________________________________________
add_13 (Add) (None, 4, 64, 80) 0 multi_head_attention_5[0][0] add_12[0][0]
__________________________________________________________________________________________________
layer_normalization_11 (LayerNo (None, 4, 64, 80) 160 add_13[0][0]
__________________________________________________________________________________________________
dense_10 (Dense) (None, 4, 64, 160) 12960 layer_normalization_11[0][0]
__________________________________________________________________________________________________
dropout_10 (Dropout) (None, 4, 64, 160) 0 dense_10[0][0]
__________________________________________________________________________________________________
dense_11 (Dense) (None, 4, 64, 80) 12880 dropout_10[0][0]
__________________________________________________________________________________________________
dropout_11 (Dropout) (None, 4, 64, 80) 0 dense_11[0][0]
__________________________________________________________________________________________________
add_14 (Add) (None, 4, 64, 80) 0 dropout_11[0][0] add_13[0][0]
__________________________________________________________________________________________________
reshape_3 (Reshape) (None, 16, 16, 80) 0 add_14[0][0]
__________________________________________________________________________________________________
conv2d_19 (Conv2D) (None, 16, 16, 64) 5184 reshape_3[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 16, 16, 128) 0 batch_normalization_17[0][0] conv2d_19[0][0]
__________________________________________________________________________________________________
conv2d_20 (Conv2D) (None, 16, 16, 80) 92240 concatenate_1[0][0]
__________________________________________________________________________________________________
conv2d_21 (Conv2D) (None, 16, 16, 160) 12800 conv2d_20[0][0]
__________________________________________________________________________________________________
batch_normalization_18 (BatchNo (None, 16, 16, 160) 640 conv2d_21[0][0]
__________________________________________________________________________________________________
tf.nn.silu_12 (TFOpLambda) (None, 16, 16, 160) 0 batch_normalization_18[0][0]
__________________________________________________________________________________________________
zero_padding2d_3 (ZeroPadding2D (None, 17, 17, 160) 0 tf.nn.silu_12[0][0]
__________________________________________________________________________________________________
depthwise_conv2d_6 (DepthwiseCo (None, 8, 8, 160) 1440 zero_padding2d_3[0][0]
__________________________________________________________________________________________________
batch_normalization_19 (BatchNo (None, 8, 8, 160) 640 depthwise_conv2d_6[0][0]
__________________________________________________________________________________________________
tf.nn.silu_13 (TFOpLambda) (None, 8, 8, 160) 0 batch_normalization_19[0][0]
__________________________________________________________________________________________________
conv2d_22 (Conv2D) (None, 8, 8, 80) 12800 tf.nn.silu_13[0][0]
__________________________________________________________________________________________________
batch_normalization_20 (BatchNo (None, 8, 8, 80) 320 conv2d_22[0][0]
__________________________________________________________________________________________________
conv2d_23 (Conv2D) (None, 8, 8, 96) 69216 batch_normalization_20[0][0]
__________________________________________________________________________________________________
conv2d_24 (Conv2D) (None, 8, 8, 96) 9312 conv2d_23[0][0]
__________________________________________________________________________________________________
reshape_4 (Reshape) (None, 4, 16, 96) 0 conv2d_24[0][0]
__________________________________________________________________________________________________
layer_normalization_12 (LayerNo (None, 4, 16, 96) 192 reshape_4[0][0]
__________________________________________________________________________________________________
multi_head_attention_6 (MultiHe (None, 4, 16, 96) 74400 layer_normalization_12[0][0] layer_normalization_12[0][0]
__________________________________________________________________________________________________
add_15 (Add) (None, 4, 16, 96) 0 multi_head_attention_6[0][0] reshape_4[0][0]
__________________________________________________________________________________________________
layer_normalization_13 (LayerNo (None, 4, 16, 96) 192 add_15[0][0]
__________________________________________________________________________________________________
dense_12 (Dense) (None, 4, 16, 192) 18624 layer_normalization_13[0][0]
__________________________________________________________________________________________________
dropout_12 (Dropout) (None, 4, 16, 192) 0 dense_12[0][0]
__________________________________________________________________________________________________
dense_13 (Dense) (None, 4, 16, 96) 18528 dropout_12[0][0]
__________________________________________________________________________________________________
dropout_13 (Dropout) (None, 4, 16, 96) 0 dense_13[0][0]
__________________________________________________________________________________________________
add_16 (Add) (None, 4, 16, 96) 0 dropout_13[0][0] add_15[0][0]
__________________________________________________________________________________________________
layer_normalization_14 (LayerNo (None, 4, 16, 96) 192 add_16[0][0]
__________________________________________________________________________________________________
multi_head_attention_7 (MultiHe (None, 4, 16, 96) 74400 layer_normalization_14[0][0] layer_normalization_14[0][0]
__________________________________________________________________________________________________
add_17 (Add) (None, 4, 16, 96) 0 multi_head_attention_7[0][0] add_16[0][0]
__________________________________________________________________________________________________
layer_normalization_15 (LayerNo (None, 4, 16, 96) 192 add_17[0][0]
__________________________________________________________________________________________________
dense_14 (Dense) (None, 4, 16, 192) 18624 layer_normalization_15[0][0]
__________________________________________________________________________________________________
dropout_14 (Dropout) (None, 4, 16, 192) 0 dense_14[0][0]
__________________________________________________________________________________________________
dense_15 (Dense) (None, 4, 16, 96) 18528 dropout_14[0][0]
__________________________________________________________________________________________________
dropout_15 (Dropout) (None, 4, 16, 96) 0 dense_15[0][0]
__________________________________________________________________________________________________
add_18 (Add) (None, 4, 16, 96) 0 dropout_15[0][0] add_17[0][0]
__________________________________________________________________________________________________
layer_normalization_16 (LayerNo (None, 4, 16, 96) 192 add_18[0][0]
__________________________________________________________________________________________________
multi_head_attention_8 (MultiHe (None, 4, 16, 96) 74400 layer_normalization_16[0][0] layer_normalization_16[0][0]
__________________________________________________________________________________________________
add_19 (Add) (None, 4, 16, 96) 0 multi_head_attention_8[0][0] add_18[0][0]
__________________________________________________________________________________________________
layer_normalization_17 (LayerNo (None, 4, 16, 96) 192 add_19[0][0]
__________________________________________________________________________________________________
dense_16 (Dense) (None, 4, 16, 192) 18624 layer_normalization_17[0][0]
__________________________________________________________________________________________________
dropout_16 (Dropout) (None, 4, 16, 192) 0 dense_16[0][0]
__________________________________________________________________________________________________
dense_17 (Dense) (None, 4, 16, 96) 18528 dropout_16[0][0]
__________________________________________________________________________________________________
dropout_17 (Dropout) (None, 4, 16, 96) 0 dense_17[0][0]
__________________________________________________________________________________________________
add_20 (Add) (None, 4, 16, 96) 0 dropout_17[0][0] add_19[0][0]
__________________________________________________________________________________________________
reshape_5 (Reshape) (None, 8, 8, 96) 0 add_20[0][0]
__________________________________________________________________________________________________
conv2d_25 (Conv2D) (None, 8, 8, 80) 7760 reshape_5[0][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 8, 8, 160) 0 batch_normalization_20[0][0] conv2d_25[0][0]
__________________________________________________________________________________________________
conv2d_26 (Conv2D) (None, 8, 8, 96) 138336 concatenate_2[0][0]
__________________________________________________________________________________________________
conv2d_27 (Conv2D) (None, 8, 8, 320) 31040 conv2d_26[0][0]
__________________________________________________________________________________________________
global_average_pooling2d (Globa (None, 320) 0 conv2d_27[0][0]
__________________________________________________________________________________________________
dense_18 (Dense) (None, 5) 1605 global_average_pooling2d[0][0]
==================================================================================================
Total params: 1,307,621
Trainable params: 1,305,077
Non-trainable params: 2,544
__________________________________________________________________________________________________---
## Dataset preparationWe will be using the
[`tf_flowers`](https://www.tensorflow.org/datasets/catalog/tf_flowers)
dataset to demonstrate the model. Unlike other Transformer-based architectures,
MobileViT uses a simple augmentation pipeline primarily because it has the properties
of a CNN.```python
batch_size = 64
auto = tf.data.AUTOTUNE
resize_bigger = 280
num_classes = 5def preprocess_dataset(is_training=True):def _pp(image, label):if is_training:# Resize to a bigger spatial resolution and take the random# crops.image = tf.image.resize(image, (resize_bigger, resize_bigger))image = tf.image.random_crop(image, (image_size, image_size, 3))image = tf.image.random_flip_left_right(image)else:image = tf.image.resize(image, (image_size, image_size))label = tf.one_hot(label, depth=num_classes)return image, labelreturn _ppdef prepare_dataset(dataset, is_training=True):if is_training:dataset = dataset.shuffle(batch_size * 10)dataset = dataset.map(preprocess_dataset(is_training), num_parallel_calls=auto)return dataset.batch(batch_size).prefetch(auto)咱们使用多尺度数据采样器来帮助模型学习不同尺度的表征。
train_dataset, val_dataset = tfds.load("tf_flowers", split=["train[:90%]", "train[90%:]"], as_supervised=True
)num_train = train_dataset.cardinality()
num_val = val_dataset.cardinality()
print(f"Number of training examples: {num_train}")
print(f"Number of validation examples: {num_val}")train_dataset = prepare_dataset(train_dataset, is_training=True)
val_dataset = prepare_dataset(val_dataset, is_training=False)演绎如下:
Number of training examples: 3303
Number of validation examples: 367--- ## Train a MobileViT (XXS) model
learning_rate = 0.002
label_smoothing_factor = 0.1
epochs = 30optimizer = keras.optimizers.Adam(learning_rate=learning_rate)
loss_fn = keras.losses.CategoricalCrossentropy(label_smoothing=label_smoothing_factor)def run_experiment(epochs=epochs):mobilevit_xxs = create_mobilevit(num_classes=num_classes)mobilevit_xxs.compile(optimizer=optimizer, loss=loss_fn, metrics=["accuracy"])# When using `save_weights_only=True` in `ModelCheckpoint`, the filepath provided must end in `.weights.h5`checkpoint_filepath = "/tmp/checkpoint.weights.h5"checkpoint_callback = keras.callbacks.ModelCheckpoint(checkpoint_filepath,monitor="val_accuracy",save_best_only=True,save_weights_only=True,)mobilevit_xxs.fit(train_dataset,validation_data=val_dataset,epochs=epochs,callbacks=[checkpoint_callback],)mobilevit_xxs.load_weights(checkpoint_filepath)_, accuracy = mobilevit_xxs.evaluate(val_dataset)print(f"Validation accuracy: {round(accuracy * 100, 2)}%")return mobilevit_xxsmobilevit_xxs = run_experiment()演绎:
Epoch 1/30
52/52 [==============================] - 47s 459ms/step - loss: 1.3397 - accuracy: 0.4832 - val_loss: 1.7250 - val_accuracy: 0.1662
Epoch 2/30
52/52 [==============================] - 21s 404ms/step - loss: 1.1167 - accuracy: 0.6210 - val_loss: 1.9844 - val_accuracy: 0.1907
Epoch 3/30
52/52 [==============================] - 21s 403ms/step - loss: 1.0217 - accuracy: 0.6709 - val_loss: 1.8187 - val_accuracy: 0.1907
Epoch 4/30
52/52 [==============================] - 21s 409ms/step - loss: 0.9682 - accuracy: 0.7048 - val_loss: 2.0329 - val_accuracy: 0.1907
Epoch 5/30
52/52 [==============================] - 21s 408ms/step - loss: 0.9552 - accuracy: 0.7196 - val_loss: 2.1150 - val_accuracy: 0.1907
Epoch 6/30
52/52 [==============================] - 21s 407ms/step - loss: 0.9186 - accuracy: 0.7318 - val_loss: 2.9713 - val_accuracy: 0.1907
Epoch 7/30
52/52 [==============================] - 21s 407ms/step - loss: 0.8986 - accuracy: 0.7457 - val_loss: 3.2062 - val_accuracy: 0.1907
Epoch 8/30
52/52 [==============================] - 21s 408ms/step - loss: 0.8831 - accuracy: 0.7542 - val_loss: 3.8631 - val_accuracy: 0.1907
Epoch 9/30
52/52 [==============================] - 21s 408ms/step - loss: 0.8433 - accuracy: 0.7714 - val_loss: 1.8029 - val_accuracy: 0.3542
Epoch 10/30
52/52 [==============================] - 21s 408ms/step - loss: 0.8489 - accuracy: 0.7763 - val_loss: 1.7920 - val_accuracy: 0.4796
Epoch 11/30
52/52 [==============================] - 21s 409ms/step - loss: 0.8256 - accuracy: 0.7884 - val_loss: 1.4992 - val_accuracy: 0.5477
Epoch 12/30
52/52 [==============================] - 21s 407ms/step - loss: 0.7859 - accuracy: 0.8123 - val_loss: 0.9236 - val_accuracy: 0.7330
Epoch 13/30
52/52 [==============================] - 21s 409ms/step - loss: 0.7702 - accuracy: 0.8159 - val_loss: 0.8059 - val_accuracy: 0.8011
Epoch 14/30
52/52 [==============================] - 21s 403ms/step - loss: 0.7670 - accuracy: 0.8153 - val_loss: 1.1535 - val_accuracy: 0.7084
Epoch 15/30
52/52 [==============================] - 21s 408ms/step - loss: 0.7332 - accuracy: 0.8344 - val_loss: 0.7746 - val_accuracy: 0.8147
Epoch 16/30
52/52 [==============================] - 21s 404ms/step - loss: 0.7284 - accuracy: 0.8335 - val_loss: 1.0342 - val_accuracy: 0.7330
Epoch 17/30
52/52 [==============================] - 21s 409ms/step - loss: 0.7484 - accuracy: 0.8262 - val_loss: 1.0523 - val_accuracy: 0.7112
Epoch 18/30
52/52 [==============================] - 21s 408ms/step - loss: 0.7209 - accuracy: 0.8450 - val_loss: 0.8146 - val_accuracy: 0.8174
Epoch 19/30
52/52 [==============================] - 21s 409ms/step - loss: 0.7141 - accuracy: 0.8435 - val_loss: 0.8016 - val_accuracy: 0.7875
Epoch 20/30
52/52 [==============================] - 21s 410ms/step - loss: 0.7075 - accuracy: 0.8435 - val_loss: 0.9352 - val_accuracy: 0.7439
Epoch 21/30
52/52 [==============================] - 21s 406ms/step - loss: 0.7066 - accuracy: 0.8504 - val_loss: 1.0171 - val_accuracy: 0.7139
Epoch 22/30
52/52 [==============================] - 21s 405ms/step - loss: 0.6913 - accuracy: 0.8532 - val_loss: 0.7059 - val_accuracy: 0.8610
Epoch 23/30
52/52 [==============================] - 21s 408ms/step - loss: 0.6681 - accuracy: 0.8671 - val_loss: 0.8007 - val_accuracy: 0.8147
Epoch 24/30
52/52 [==============================] - 21s 409ms/step - loss: 0.6636 - accuracy: 0.8747 - val_loss: 0.9490 - val_accuracy: 0.7302
Epoch 25/30
52/52 [==============================] - 21s 408ms/step - loss: 0.6637 - accuracy: 0.8722 - val_loss: 0.6913 - val_accuracy: 0.8556
Epoch 26/30
52/52 [==============================] - 21s 406ms/step - loss: 0.6443 - accuracy: 0.8837 - val_loss: 1.0483 - val_accuracy: 0.7139
Epoch 27/30
52/52 [==============================] - 21s 407ms/step - loss: 0.6555 - accuracy: 0.8695 - val_loss: 0.9448 - val_accuracy: 0.7602
Epoch 28/30
52/52 [==============================] - 21s 409ms/step - loss: 0.6409 - accuracy: 0.8807 - val_loss: 0.9337 - val_accuracy: 0.7302
Epoch 29/30
52/52 [==============================] - 21s 408ms/step - loss: 0.6300 - accuracy: 0.8910 - val_loss: 0.7461 - val_accuracy: 0.8256
Epoch 30/30
52/52 [==============================] - 21s 408ms/step - loss: 0.6093 - accuracy: 0.8968 - val_loss: 0.8651 - val_accuracy: 0.7766
6/6 [==============================] - 0s 65ms/step - loss: 0.7059 - accuracy: 0.8610
Validation accuracy: 86.1%--- ## 结果和 TFLite 转换 大约有一百万个参数,在 256x256 分辨率下达到 ~85% top-1 的准确率是一个很好的结果。这款 MobileViT 移动设备与 TensorFlow Lite (TFLite) 完全兼容,可以用以下代码进行转换:
# Serialize the model as a SavedModel.
tf.saved_model.save(mobilevit_xxs, "mobilevit_xxs")# Convert to TFLite. This form of quantization is called
# post-training dynamic-range quantization in TFLite.
converter = tf.lite.TFLiteConverter.from_saved_model("mobilevit_xxs")
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS, # Enable TensorFlow Lite ops.tf.lite.OpsSet.SELECT_TF_OPS, # Enable TensorFlow ops.
]
tflite_model = converter.convert()
open("mobilevit_xxs.tflite", "wb").write(tflite_model)要了解有关 TFLite 中可用的不同量化配方以及使用 TFLite 模型运行推理的更多信息,请查阅 [本官方资源](https://www.tensorflow.org/lite/performance/post_training_quantization)。
您可以使用[Hugging Face Hub](https://huggingface.co/keras-io/mobile-vit-xxs)上托管的训练有素的模型,并尝试[Hugging Face Spaces](https://huggingface.co/spaces/keras-io/Flowers-Classification-MobileViT)上的演示。