UI自动化测试能够在一定程度上确保产品质量,尤其在降本提效的大背景下,其重要性愈发凸显。理想情况下,UI自动化测试不仅能够能帮我们规避不少线上问题,又能加快产品上线速度。然而现实却往往相去甚远,在多数情况下,编写测试脚本的工作量很大,且由于应用程序的频繁迭代,这些脚本很快就会过时。此外,网络数据的多变也常常导致测试结果不稳定,从而影响测试的可信度。
基于这些挑战,我们开发了一套UI自动化测试平台- AutoMotion,旨在降低UI自动化测试的使用门槛、提升易用性。该平台不但能便捷地生成用例,且借助最新的大型语言模型,该平台也具备了用例自愈能力,能够智能适应界面的合理变动,并自动修正测试脚本;同时,通过构造数据沙箱来隔离和控制测试数据,使平台能够确保测试的一致性和可重复性。
本文将对AutoMotion平台的设计理念、核心功能以及实现原理进行介绍。
背景
我们组内曾尝试过使用cypress等常见工具进行UI自动化测试,但遇到不少问题和痛点,主要归为以下四类:
手写脚本成本高
页面多如繁星,手写自动化测试脚本成本很高。(这点无需赘述)
(有些工具支持根据录制你的操作,然后生成脚本,但普遍能力有限,比如cypress提供的这种工具就无法记录滚动操作)
网络数据变化导致测试结果不可信
无论是线上、预发还是测试环境,数据都会不断变化,导致很多情况下执行通过与否不能正确反应实际功能逻辑有无问题。哪怕指定某个固定测试账号去做某个特定用例的测试也会如此,比如存在一些非幂等的操作时便可能导致问题。
举个简单的例子。某活动页,用户可报名参与该活动(每人只能报名一次),测试用例是“登录账号1,点击活动的报名按钮,页面显示’报名成功‘” ,假如第一次执行用例成功了,此时活动会变为“已报名”状态,第二次执行该用例将无法再次报名,用例不通过,但此时前后端代码并无任何问题。
当然,可以考虑写个重置数据的脚本,然而:第一,需要后端同学的配合;第二,数据背后的关联逻辑可能很复杂(比如以上例子下可以重置账号1的报名状态,但活动可能还会有报名结束时间,或活动被下架,或报名名额达到上限,等等各类情况),且针对不同项目不同场景要准备不同数据,实现成本很高;第三,很难重置线上数据
项目迭代频繁导致用例脚本维护成本高
当页面发生迭代后,哪怕从功能上看此次迭代与某用例无关,也往往会导致该用例脚本失去作用,需要被更新。
参考如下例子:
测试用例是”...点击任务的’去完成‘按钮...“。
页面结构如图所示:
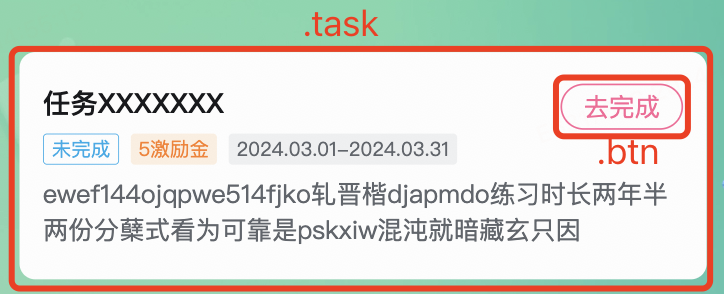
在自动化测试脚本中,我们可以通过“.task > .btn”这个selector选取到“去完成”按钮,然后执行点击操作,cypress代码为:
cy.get('.task > .btn').click()
但在后续迭代中,可能发生一些变化,比如在“.btn”外多包了一层“.task-content”:
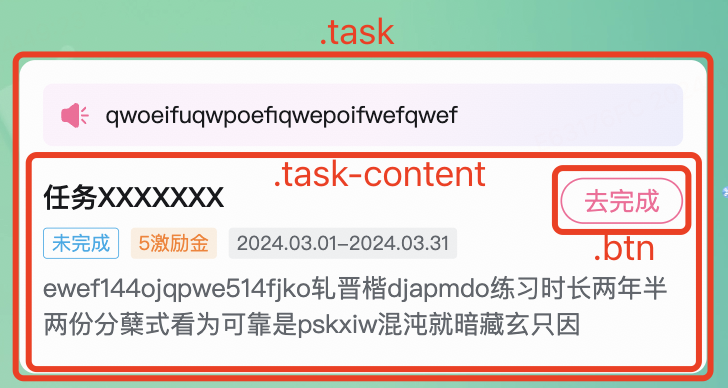
此时通过“.task > .btn”就获取不到了,所以我们需要在用例脚本中将selector更新为”.task > .task-content > .btn“。
当然,在这个特定例子下,我们还可以将selector写成“.task .btn”,这样即使在“.btn”外多包了任意层元素也不影响。但如果“.btn”被改成了“.btn-primary”呢?类似的情况还有很多,很多理应与旧用例无关的迭代,都需要我们去更新用例脚本,大大提高了维护成本。甚至在有些时候,每次迭代都需大幅更新大量用例脚本,导致自动化测试完全失去了意义,还不如人肉回归。
如何接入标准流程中
如何把各项目的自动化测试任务便捷地、灵活地接入到开发、发布流程中。(此条也无需赘述)
为了解决以上问题,我们决定自研一个UI自动化测试平台:
UI自动化测试平台 - AutoMotion
针对以上四大问题,该平台对应提供了四大机制以解决:

针对以上四大问题,该平台对应提供了四大机制以解决:
用例脚本录制生成
用以解决:手写脚本成本高
提供chrome插件,开启录制后,你可以模仿用户在页面中进行一系列操作,该插件可识别你的操作,自动生成UI自动化测试脚本。支持点击、键盘输入、滚动、拖动等大部分常见操作。
数据沙箱
用以解决:网络数据变化导致测试结果不可信
为了对之有更确切的理解,这里不妨先将目光从该问题本身向上拉至更一般的角度。
我们可将某浏览器看做一个函数,该函数的“输入”为前端代码、用户操作、接口数据、日期、随机数等,“输出”为渲染后的界面,在几乎99.9%的情况下,可以认为该函数是确定的、无副作用的、可预测的(即在以上“输入”保持不变的情况下,使浏览器运任意次,“输出”也应始终不变)。
然后带着以上视角下重新审视UI自动化测试:
如下图,通常,在某次迭代后执行UI自动化测试用例时,相比前一次的执行,“用户操作”是不变的(写死在测试脚本里),但在它之外可能存在多个输入项的变化,此时若渲染结果发生了变化,导致用例执行失败(中断或不符合断言),我们很难直接将其归因为“前端代码变更所致”:
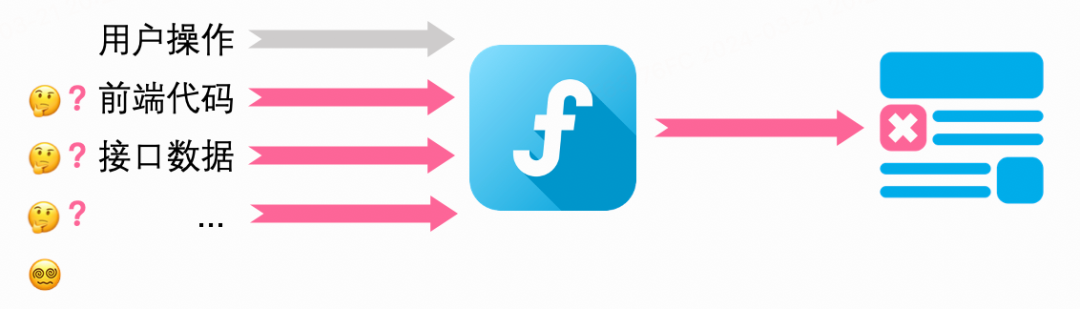
而若能使得每次执行UI自动化测试用例时,仅前端代码存在变化,若某次用例执行失败,便能更确切地得知其为“前端代码变更所致”:

至此,“数据沙箱”的想法应运而生:
在用例录制阶段,于录制用户操作的同时,收集过程中的接口请求、storage、cookies、窗口大小等外部数据(你也可以自行修改这些数据),并在用例执行阶段1:1地“复现”出来。
当然,使用“数据沙箱”是有取舍的,使用后虽然避免了接口数据干扰问题,大幅省心,但这样相当于只测前端代码了。所以该平台也支持根据需要关闭特定数据沙箱(比如关闭接口请求沙箱以测到后端逻辑、保留cookies沙箱以避免登录问题)。
用例可视化编辑、用例自愈机制
用以解决:项目迭代频繁导致用例脚本维护成本高
首先,上文介绍的“用例脚本录制生成”能力就已很大程度上解决了该问题,用例需要更新时重新录制一遍即可。
其次,该平台还提供了:
-
“用例可视化编辑”能力,在用例仅需小幅更新时,可快速编辑、更新;
-
“用例脚本编辑”能力,录制的用例可直接转为cypress脚本(后续考虑支持playwright),以进行更加灵活、无约束的编辑。
这些更新方式都较为便捷,但在实际使用中依然存在一大问题:
经过某些迭代后执行用例时,可能很多用例执行不通过,但大部分是页面结构的合理更新后所至,而非新引入的bug,此时需人工一一审阅报错原因,确认是feature或bug。且此次因feature导致的用例不通过,若不及时更新,则下次执行时将有极大概率依然不通过,如此不断叠加,不通过的用例越来越多,导致我们不得不在每次迭代后及时地花费很大精力去排查、更新用例,完全违背了“自动化测试”的初衷。
其实观察该类问题后会发现,它们大部分都出自同一个“简单”的原因:页面更新后,用例执行时获取不到目标元素(请回顾一下上文“③ 项目迭代频繁导致用例脚本维护成本高”中所举的例子)。
针对这种情况,我们对传统的css selector规则进行了扩展,并基于现有的LLM实现了目标元素的智能识别与“用例自愈”。使得在页面结构变化后(非大的功能更新),依然能够获取到目标元素,并自动根据最新页面结构自动更新用例脚本。
Open API
用以解决:如何接入标准流程中
对于录制保存后的每个用例,该平台都会生成相应的open api,调用该api即可执行用例并得到结果。该api可被灵活地接入gitlab、流水线/构建/发布平台、cli工具等,实现在任意流程节点上执行自动化测试。
也可在该平台上设置定时器进行定期自动化测试。
方案与原理介绍
以下会介绍该平台的部分关键技术点和一些背后的思考。
用例录入
chrome插件

用例录入是通过chrome插件实现的,在开启录制时,该插件会进行以下处理:
-
在页面头部植入一段js脚本,侵入页面运行时环境,通过操作页面window对象捕获录制过程中的所有操作行为、storage数据等;
-
在devtools page中捕获录制期间所有接口数据;
-
在background page(service worker)中捕获cookies;
-
在content script中捕获useragent、窗口大小等信息。
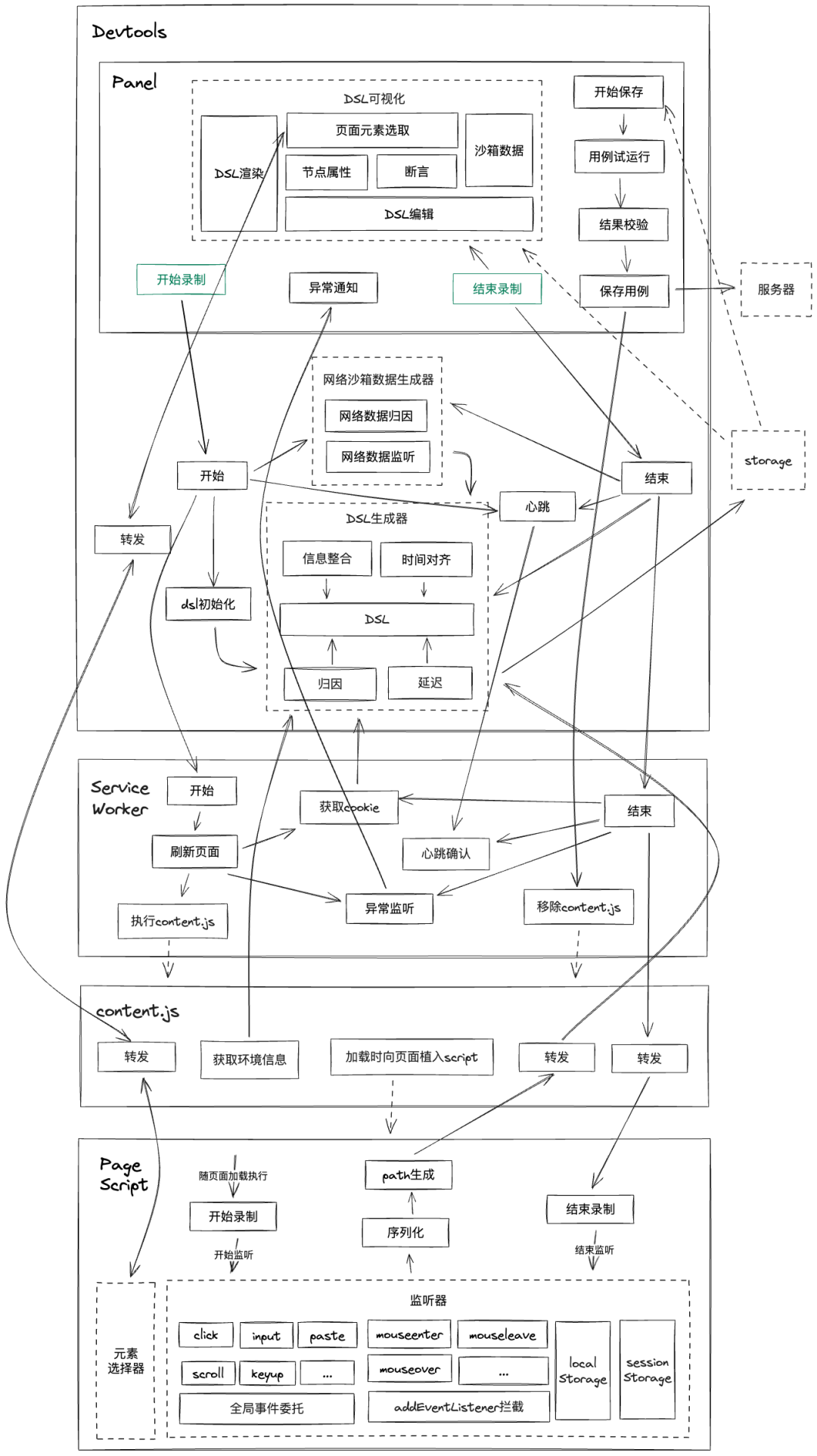
录制结束后,该插件会将以上收集到的信息转成符合我们定义规范的用例DSL,存储至后台。除了以上基础能力,该插件中还实现了DSL可视化/编辑、元素可视化拾取、环境识别、异常检测、用例试运行等功能。
由于chrome插件的一些限制,在实际实现以上功能时,需要按照chrome插件支持的能力范围划分模块,且很多模块间不能直接通信,导致数据流相对难以管理(所以我们对通信数据的类型和格式进行了一定规范,这里不展开)。部分细节如下(示意图,仅供参考,大致浏览即可):
构建与更新
chrome插件与常规前端项目结构有所不同,且该chrome插件目前仅为公司内部使用(未上传至chrome商店),故在构建、打包、版本更新方面也做了一些处理,封装在我们的构建脚本中,运行后可自动完成如下流程:
-
使用webpack对devtools页面(即本插件中所有UI展示的部分)进行构建;
-
对devtools页面以外全部文件进行构建(如统一替换环境变量);
-
更新manifest中版本号;
-
将整个项目压缩为zip包,上传至线上;
-
更新数据库中最新版本号;
-
(用户在打开旧版本chrome插件时会提示更新,点击即可下载)。
用例执行
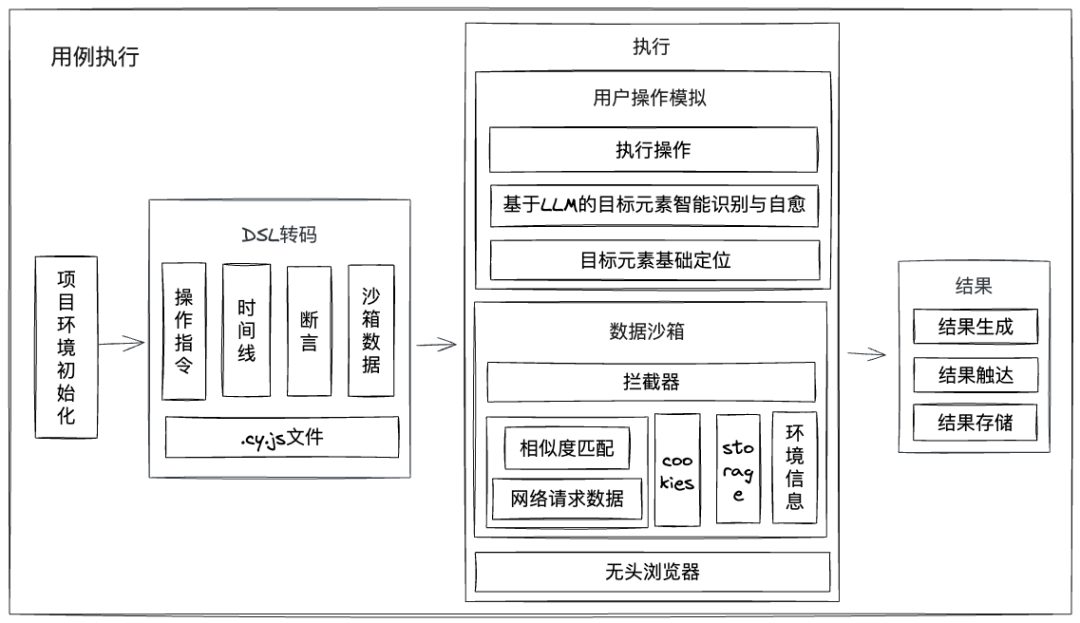
我们是通过nodejs和cypress实现用例执行的。nodejs服务会在容器中初始化cypress项目环境,在需执行用例时,将用例DSL转为可执行的cypress脚本和相关数据文件,其中包含用户操作、数据沙箱等信息,然后通过cypress运行(支持数个cypress实例并发),最后生成运行结果,并触达给前台触发方或预警方。
行为监听
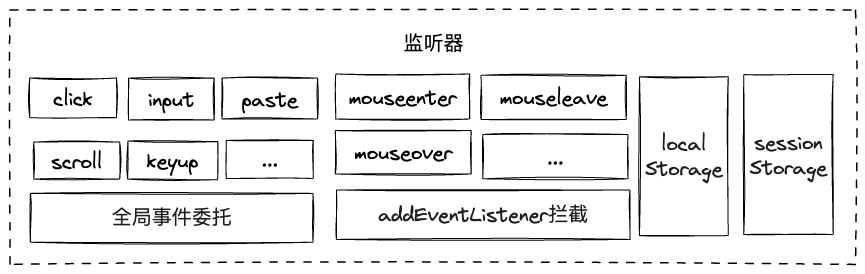
在上文中已经提到了,在用例录制时,chrome插件会在页面头部植入一段js脚本,监听操作者行为,这里进一步阐述一下监听方式。
基础事件监听
chrome插件植入的js脚本会在页面window对象上进行全局事件委托,以监听用户相关操作。如:
window.addEventListener('input', this.handleInput, true)
特殊事件监听
以上“基础事件监听”方式似乎已经足够,但细想一下,mouseenter、mouseleave、mousemove、mouseover、mouseout等事件也能通过这种方式绑在window或document节点上进行监听吗?
显然不合理,比如若在document上监听mouseenter事件,那么当我们的鼠标划过页面中任意元素时,都会触发该事件,这些信息是冗余的。可以对比一下click,因为用户在页面中的大部分点击操作都是“有意义”的(是整个”页面函数“中的一个有意义的输入),所以整个页面中任意位置触发click是都可以记录,而大部分鼠标移动操作都对页面无实际意义。
这里应当反过来思考:只有本身已经绑定了这些事件的元素,触发这些事件对它来说才大概率是有意义的,我们对这些元素做监听就行。比如页面中有个元素A,它被绑定了mouseenter事件以在鼠标移入时展示tips,那么在用例录制时,若用户将鼠标移入元素A,触发了tips展示,就需要将该mouseenter事件录制下来、在用例执行时触发,否则就无需记录。那么如何知道哪些元素被绑定了这些事件呢?可以将页面中window.Element.prototype.addEventListener函数替换成我们自己构造的函数,实现对任意页面中原本的所有”事件绑定“行为的拦截,当然同时也需调用原函数,不影响原功能。代码示意如下:
const originalAddEventListener = window.Element.prototype.addEventListener;// 替换所有元素的addEventListenerwindow.Element.prototype.addEventListener = function(type, originalListener, ...others) { // 替换所有元素的listener回调函数,进而拦截mouseenter、mouseleave、mouseover、mouseout事件 const listener = function(event) { if (isRecording && ['mouseenter', 'mouseleave', 'mouseover', 'mouseout', 'mousemove'].includes(event.type) && event.target === this) { handleMouseAction(event) } originalListener.call(this, event) } return originalAddEventListener.call(this, type, listener, ...others)}
目标元素定位
“行为”实际上包括“动作”和“作用对象”(即“目标元素”)两块。比如“用户点击元素A”,其中“动作”是“点击”,“目标元素”是“元素A”。上文已经介绍了如何识别“动作”,这里介绍如何定位“目标元素”
基础定位
以“从根节点到目标元素的唯一路径的css selector”作为定位方式。如:body > div > #app > div.app-right > div > div:nth-child(2) > div.text
基础定位增强
请先看一个例子,如下图,“导出”按钮是目标元素,通过“基础定位”记录下的selector可能是“xxx > div:nth-child(2)”:
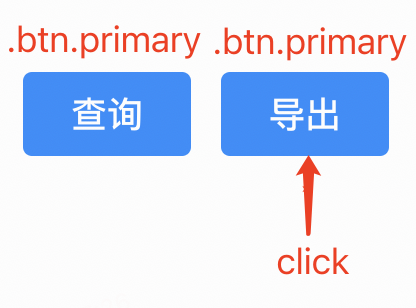
但在某次迭代后,在“导出”之前新增了一个“重置”按钮:

此时“xxx > div:nth-child(2)”定位到的就是“重置”按钮了。
这里我们会发现,常规css selector的描述能力似乎并不够,对于某个元素,你可以准确描述它的class,也可以准确描述它是当前层级中的第几个元素,但无法将二者结合,即无法描述“它是当前层级中class为xx的第几个元素”(前端界的“测不准原理”?😑)。
所以不如定义一套新的规则(基于css selector进行扩展),如“xx > div.btn.primary:nth(2)”,含义为“在xx的子节点中,选取所有符合div.btn.primary的节点,再在其中选取第2个”,这样放在上面的例子里,新增“重置”按钮后也不会影响到“导出”按钮的定位了。
此外,我们还可以加入文本内容信息,如“xx > div.btn.primary:contains('导出'):nth(1)”,这样哪怕新增的“重置”按钮也是“.btn.primary”,也不影响了(当然,若信息过多,在页面迭代后、进行精准匹配时反而更容易出错。但倘若是“模糊匹配”,则信息越多越好,这点下面会探讨)。
(其实xpath就能够描述这些信息,但最新的cypress已不支持xpath了,而手动实现xpath查找的成本很高,所以我们选择手动实现自定义增强版的“css selector”)
基于LLM的目标元素智能识别与用例自愈
方案
使用以上增强版的css selector在部分情况下能够降低页面结构变化后元素定位失败的概率,但依然有很多情况会导致失败,比如元素class改变、元素位置改变、元素内容文本改变等。
可以想象一下,在人工回归时,大部分情况下我们“聪明的人类”能轻松地识别出变化后的目标元素,那么能否让UI自动化测试拥有接近人类的目标元素识别能力呢?
一个最显然的方案是:基于图像识别选取元素。这原本也几乎是唯一最佳选择,但随着近几年LLM的迅速发展,我们想到了另一种可能:基于LLM实现目标元素智能识别。毕竟最新LLM模型的文本理解能力已经相当惊人,而“页面结构”本身也是通过文本(dom)进行描述的。因为对图像识别相关经验不多,且第二种方案也有望扩展至“目标元素智能识别”以外的各种场景,故选取了第二种。
该方案大致为:在用例执行中,若selector获取失败,则暂停执行,将页面dom、selector等信息交由LLM进行处理,让其识别出该“过时的”selector真正想获取的元素是什么,返回更新后的selector路径,然后更新相应用例并重新执行,达到“用例自愈”。
DOM压缩
在将信息输入LLM前,有一个很明显的问题:页面dom可能会很大,导致LLM处理时间很长,甚至可能直接超过LLM支持的大小上限。比如这是b站首页渲染完成后的dom大小:

高达22万tokens!不过其中大部分信息对“目标元素识别”来说都几乎是无意义的,我们可以将它们全部删除,进行“dom压缩”:
-
删除script、style、link等结构无关tag
-
空格、换行合并
-
对于剩下的所有tag,仅保留tag、id、class、text信息,其它全部删除
经过这些步骤后,该页面占用的tokens大幅降低至1.3万:
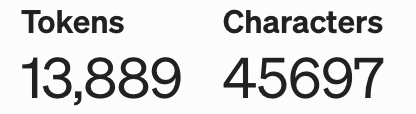
可剩下的dom中重复内容还是不少的。比如某个class名可能在页面中出现很多次,占用了很多字符。所以可生成一个”class压缩映射表“,把每个class名映射为一个数字,最终可能用0-500这些数字就能表示所有class名,当然,数字每位”密度“还是太低了(只能包含10个不同的值),且class名开头不能为数字,所以用字母”计数“更佳,比如先从a到z,再+1就是aa,以此类推,大部分class名都会被压缩至两个字符以内(经过试验,仅此步就可将该页面tokens数进一步降低至0.9万)。
同理,tag名称也可压缩。甚至”class“这个字段本身也可压缩(比如压缩成”c“)。
经过这些压缩后,dom确实会继续缩小,然而这些压缩会丢失不少”有语义“的信息,无论是一些class名(比如”task-btn“)还是tag名,它们有助于LLM去理解页面内容、做出更准确的目标元素识别,所以我们最终未选择这些进一步压缩的方式(另一种方式是将压缩映射表也告知LLM,不过也会提高LLM理解难度,有待试验)。
实际上,b站首页算是b站dom最庞大的页面之一了,大部分页面经过第一步的压缩后,tokens会远低于1.3万(比如很多移动端页面压缩后tokens数为1500-5000)。
Prompt
压缩完dom后,便可以构造promot了,我们的prompt结构大致如下:

其中会先通过一些例子让LLM学会如何进行“模糊匹配”(即根据“不准确的selector”找到正确的元素),然后将压缩后的dom、selector交由它完成任务。
对于实际效果,我们进行了一些初步试验:
在一般情况下,“用例自愈”能力已可满足要求(仍在优化中)。对于确实变化很大难以“自愈”的,将提示用户重新录制用例。
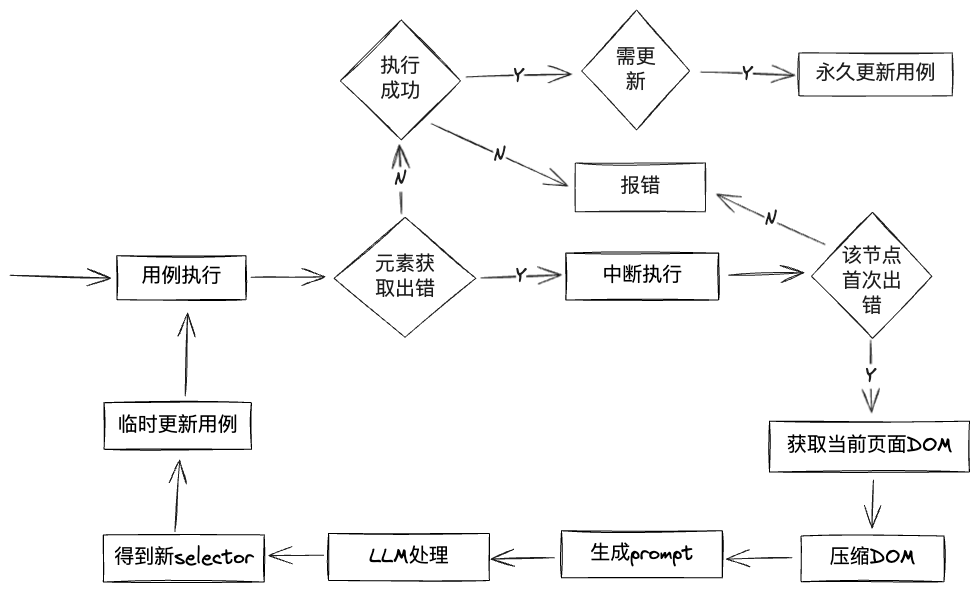
执行流程
采用标元素智能识别与用例自愈后的执行流程如下:
Fine-Tuning?
目前我们对LLM的所有要求都被囊括在prompt中,这可能并不是最佳方式,毕竟prompt的长度有上限,我们无法灌输给LLM足够多的信息去提高正确率,也会消耗较多处理时间和费用。
而fine-tuning允许我们根据自己的特定需求和数据集来定制和优化模型,以适应特定场景,相比上面的纯prompt方案,我们可以预先喂给大模型多得多的“模糊匹配”例子,进一步提高其识别目标元素的能力,且prompt大小可大幅缩减(prompt中“前置能力学习”的部分可以去掉了)。所以fine-tuning应该是更好的方式,由于当下时间有限暂未尝试,后续会深入。
唯一标识符定位
基础方案
上面介绍了常规定位+智能定位的方案,已经可以相对丝滑地覆盖大部分场景,但有时LLM也会出错以及部分敏感页面可能不适合传入LLM。有没有其它可选的、接入成本稍高一点的、但更加稳定的方式呢?当然有,很直接:为所有目标元素加上唯一标识。
可于用例录制前,为需要录制操作的元素绑上唯一标识,如:“
<div data-atm-id="(uuid)" ”(这里没有直接使用“id”属性是为了避免影响原项目业务逻辑),在用例录制时,若目标元素有此类标识,则记录该标识即可。因为该标识全局唯一,故任何dom结构的变动后都不影响获取该元素(除非删除该元素,当然,这时也说明该用例已与新需求不符,应重新录制用例了)。
问题与改进
有一些细节但关键的问题需要处理:
问题1:
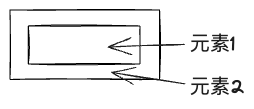
若只有元素2绑定了唯一标识,而录制时是元素1被点击,对不上,这样记录下的依然是元素1的selector。
解法:用例录制时,若被捕获的元素没有data-atm-id,则向上找到离其最近的含data-atm-id的节点,作为真正的目标元素并记录。
问题2:难以给一些npm组件库中某组件的内部元素打上标识。
解法:增加“data-atm-parentId”标识,写在组件最外层(若不方便写,也可在组件外自己加一层div写上该标识),用例录制时,若被捕获的元素没有data-atm-id,(且在问题1解法未满足时),向上找到离其最近的含data-atm-parentId的节点,构建以它为开头的selector(如“[data-atm-parentId="xxx"] > div”),若找不到才记录当前元素的常规selector。
权衡
当然,唯一标识符定位也存在一些弊端:
-
有一定接入成本,需侵入被测项目,修改其项目代码;
-
处理组件库内部元素的方式依然不够稳定可靠;
-
倘若后续想进一步实现“全自动”用例生成(结尾“展望”部分会介绍)——要对成百上千个页面生成用例,此方案就不适用了。
可见,在”元素定位“方面,几乎没有既简单高效、又稳定可靠的完美方案,现在可以做的是将以上方案结合,让使用者能够按需要自行选择。不过,我们认为在“目标元素智能识别与用例自愈“上仍然有不断优化的空间,也是我们主要着眼的方向,且在使用fine-tuning或更强大的LLM问世后,此方案大概率将得到又一次增强。
数据沙箱
这里介绍一下“数据沙箱”中的核心部分:“网络请求沙箱”。
基础方案
基础方案很简单:
-
用例录制时,通过chrome插件的chrome.devtools方法捕获所有接口数据;
-
用例执行时,通过接口入参(url(含query)+method+body)匹配录制时记录下的相应网络数据、通过cypress的cy.intercept方法进行拦截和mock。
问题与改进方案
基础方案乍一看挺美好,但仔细一想坑不少。
问题1:“url(含query)+method+body”并不足以精准匹配。比如同样的接口被先后请求两次,但返回值不一样,基础方案下记录的信息并不能区分这两次接口请求。举例:用户进入某活动页,调用接口a获取报名状态,返回“未报名”,点击报名按钮,成功,重新调用接口a,返回“已报名”,用例执行时如何得知每次接口a的调用应该返回什么呢?
解法:两次接口调用之间,接口入参完全不变,那什么发生了变化可能导致接口出参改变呢?操作行为和时间。所以在记录每个接口信息时,我们还会进行“数据归因”+“时间对齐”,将其“归因”到某个用例节点上,并记录相对时间。如:接口a归因于“点击报名按钮”节点,滞后200ms左右。
问题2:有些项目的接口入参中会包含一些前端生成的随机信息,导致执行用例时每次的入参都不一样,匹配不上(有了“随机数沙箱”后倒可以解决,还未实现);页面迭代可能会修改接口入参,导致匹配不上;页面迭代后运行时间可能变化较大,导致归因的时间对不上;等等。
解法:这些问题都是“精准匹配”导致的,其实解决思路与上文的目标元素定位类似,即增加“模糊匹配”。这里目前不需要LLM,因为匹配信息结构固定且可被量化,所以我们制定了"接口相似度匹配算法",根据url、query相似度(kv匹配、k匹配、多余的k等)、method、距归因节点时间等指标综合计算得分,选择得分最高的接口然后返回。(若无一个得分高的,则发往真实后端)
问题3:页面迭代后可能会引入新接口,该接口甚至可能跟用例所测模块毫无关系(所以正常来说,肯定不想因为它去更新用例),但因匹配不上,会发往后端,此时若无登录态会跳登录页或使页面出错,导致用例失败。
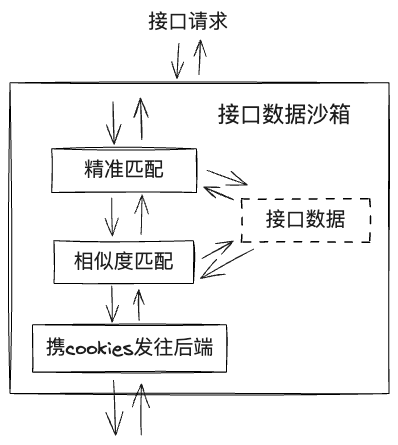
解法:用例录制时记录下cookies,用例执行时注入。这样通过”模糊匹配“也匹配不上的接口,会携cookies发往后端,至少大概率保证页面不报错。
如此,我们将“接口数据沙箱”划分为如下图所示的三层,每当上一层匹配失败时,触发下一层:
多环境与多用例并发执行
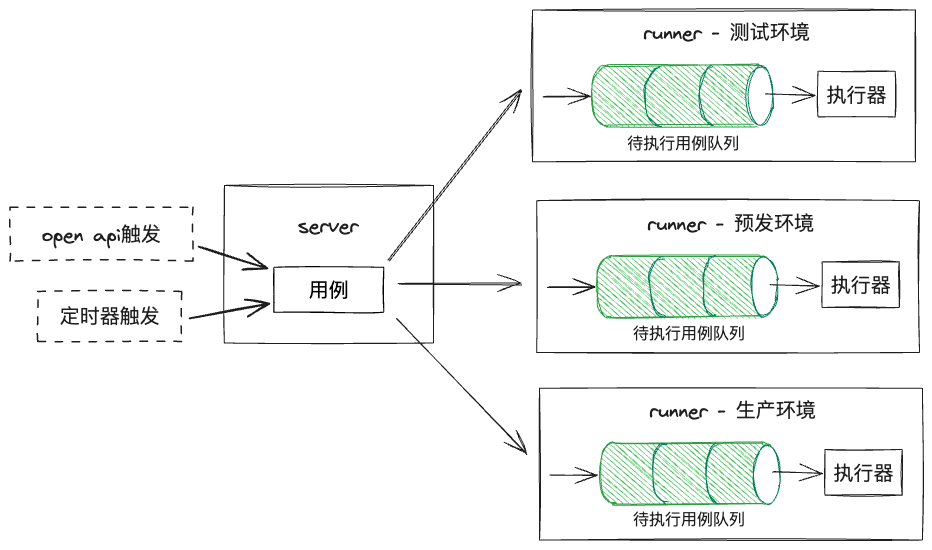
如图,由于需要支持在不同环境执行用例,所以我们将“用例执行”的部分单独拆了出来,作为“runner”,分别部署在不同环境,”runner“容器中也需预先装好无头浏览器、cypress和相关运行环境;将常规的crud部分作为”server“,同时它也负责将用例分发至对应环境的”runner“。
此外,每个用例的执行需占用一定资源和时间,执行器支持的最大用例并发数有上限,所以,用例进入runner时会进入队列中等候,在执行器有空余时执行。
主要流程如下:
-
在用例录制时,获取每个url最终指向的ip地址,自动识别出当前运行环境,保存在用例中(也支持手动修改环境);
-
触发用例执行时,server将用例发往对应环境的runner执行;
-
用例进入runner的队列中等待执行。
DSL
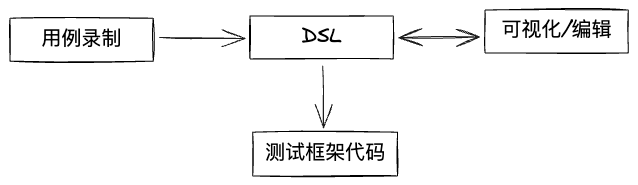
我们测试框架代码之上定义了DSL层,它是对于用例的结构化描述,JSON格式,包含某个用例的全部信息。它的作用是:
-
便于用例录制时快速生成,便于存储;
-
便于可视化展示以及可视化编辑;
-
对用例进行结构上的约束,减小出错概率,收敛系统复杂度;
-
理论上可被转为各类测试框架代码并执行。
导出用例脚本并编辑
部分用例需高度定制,通过可视化编辑无法满足,因而我们提供了将用例DSL导出为cypress脚本的功能(后续考虑支持playwright脚本),通过修改cypress脚本便能实现一切cypress可实现的能力。
从上方“DSL“章节的图中可知,DSL可以转成cypress脚本代码,但该过程不可逆(DSL的能力是cypress脚本的子集),所以在用户导出cypress脚本后,该脚本会成为新的用例,作为”脚本类型用例“与”DSL类型用例“区分开来。
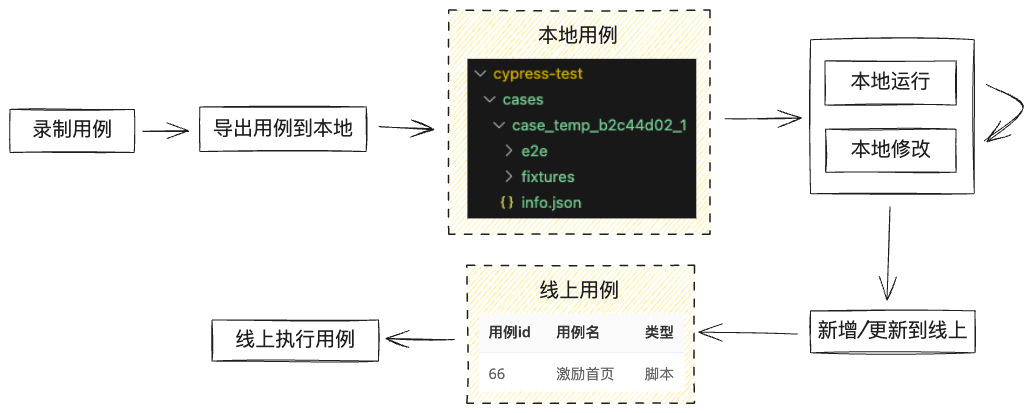
我们提供了cli工具,可在任意目录下初始化cypress项目,然后可将任意用例转为cypress脚本下载至此,以便在本地修改和运行调试,修改完成后可通过cli将用例上传至线上,成为一个新的”脚本类型用例“。”脚本类型用例“能够与”DSL类型用例“一样在线上执行。
流程示意如下:
展望
现在已经实现了录制后自动生成用例脚本、代码小幅更新后自动修复用例脚本,但“录制”操作本身依然需要人工执行,而且在这之前还需制定用例,能否把这些过程也“自动”做掉?
一个直接的想法是:让LLM了解产品背景、阅读最新产品需求,生成用例。理论上让LLM生成文字描述的用例显然是可行的,而想要进一步生成用例DSL或用例脚本,还需使LLM知晓所有相关页面运行时的具体结构,如何运行、如何存储、如何理解、如何关联等都会是难题。
所以不如换一个角度:页面最终是服务于线上用户的,他们的操作本身不就是最好的”用例“么?所以可以自动采集线上线上用户的真实操作链路,自动识别出高频链路、核心链路,自动归总为用例。相比之下,该方案更易实现(当然尚待深入的细节问题依然不少),且生成的用例质量甚至可能更好,同时也有借助LLM继续优化的可能性。
流程示意如下:
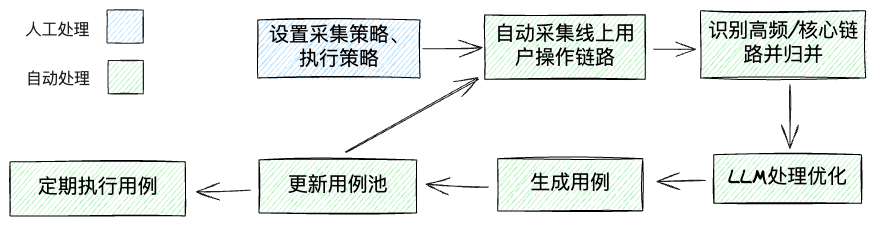
如此,在设定好策略后,便可自动批量产出用例、自动执行,做到“全流程全自动”,这才是真正“自动”的“自动化测试”。预期主要可以服务于数量庞大的、非核心的前端页面(数量太多难以一个个录入和维护,但又想一定程度上保证质量),大幅降低生产和维护用例的时间。