文章目录
- 1.OSD坏盘更换操作
- 2.判断OSD是否出现故障的思路
- 3.模拟osd.5故障
- 4.OSD故障更换硬盘流程
- 4.1.将故障的osd.5从集群中删除
- 4.1.1.从OSD Map中将故障的OSD删除
- 4.1.2.从Crush Map中将故障的OSD删除
- 4.1.3.在OSD列表中将故障的OSD删除
- 4.1.4.将故障的OSD认证信息删除
- 4.1.5.验证集群中是否已经将故障的OSD删除
- 4.2.换盘操作
1.OSD坏盘更换操作
在实际环境中,可能会经常遇到OSD对应的硬盘出现了故障,此时就需要对这个OSD进行操作了。
坏盘更换中包括两个阶段:
- 首先将OSD从Ceph集群中踢出,也就是所谓的缩减OSD。
- 硬盘修复完成后再以新的OSD的方式加入到集群中。
OSD从集群中踢出时,也会触发Reblanceing数据重分布机制,将OSD中的数据迁移到其他的OSD中,当OSD的数据全部同步完成后,再将OSD彻底移除。
硬盘修复成功后,以新的OSD加入到集群中,此时也会触发Reblanceing机制,将数据再次同步到这个OSD中。
2.判断OSD是否出现故障的思路
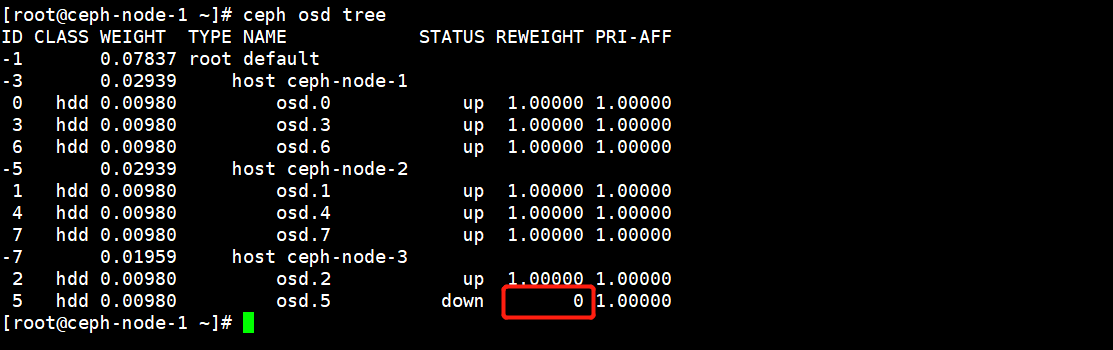
比如说ceph-node-3节点中的osd.5出现了故障,对应的状态就会是down,首先去登陆上这台机器,看看系统日志有没有说明硬盘问题。
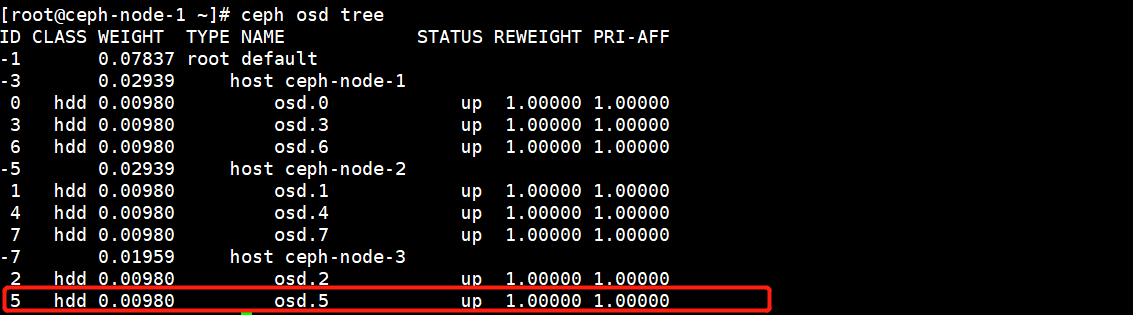
如果硬盘出现了坏道的情况,就会影响整个集群的性能,从而拖垮整个Ceph集群,遇到这种情况执行上述命令不会显示down的状态,因为磁盘出现了坏道,磁盘还是可以用的,只不过性能有所下降。
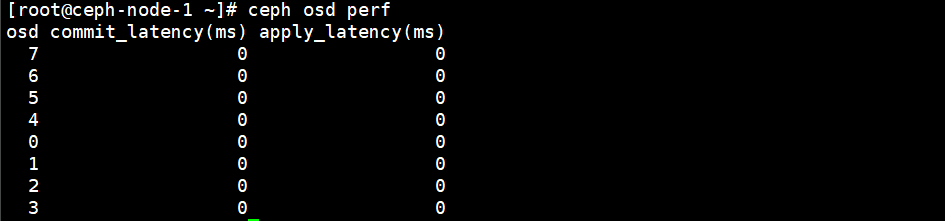
此时我们可以通过以下命令看到OSD的延迟,如果值很高的话,就表示OSD可能出现了坏道,一定要把它从集群中删除。
3.模拟osd.5故障
osd.5运行在ceph-node-3中,直接将服务停掉即可。
[root@ceph-node-1 ~]# ssh ceph-node-3
[root@ceph-node-3 ~]# systemctl stop ceph-osd@5@后面的数字表示osd的id号
此时osd.5已经出现了故障,下面我们来实现当osd出现故障的更换操作。
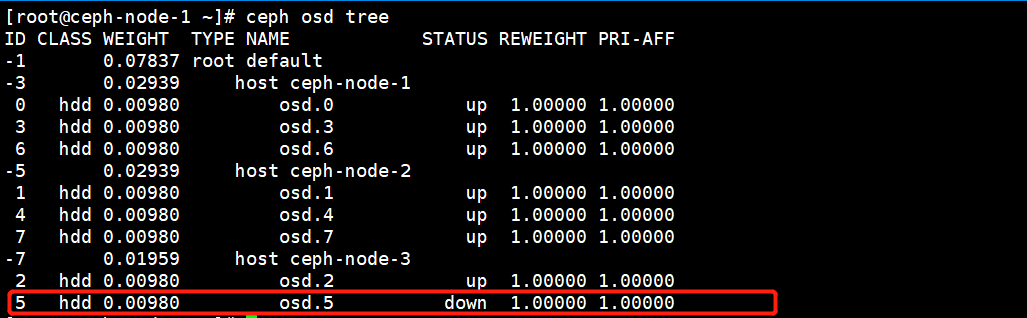
当有一个OSD出现故障后,就会触发Reblanceing机制,大概在10分钟后才会真正的迁移数据,等数据同步完再进行更换操作。
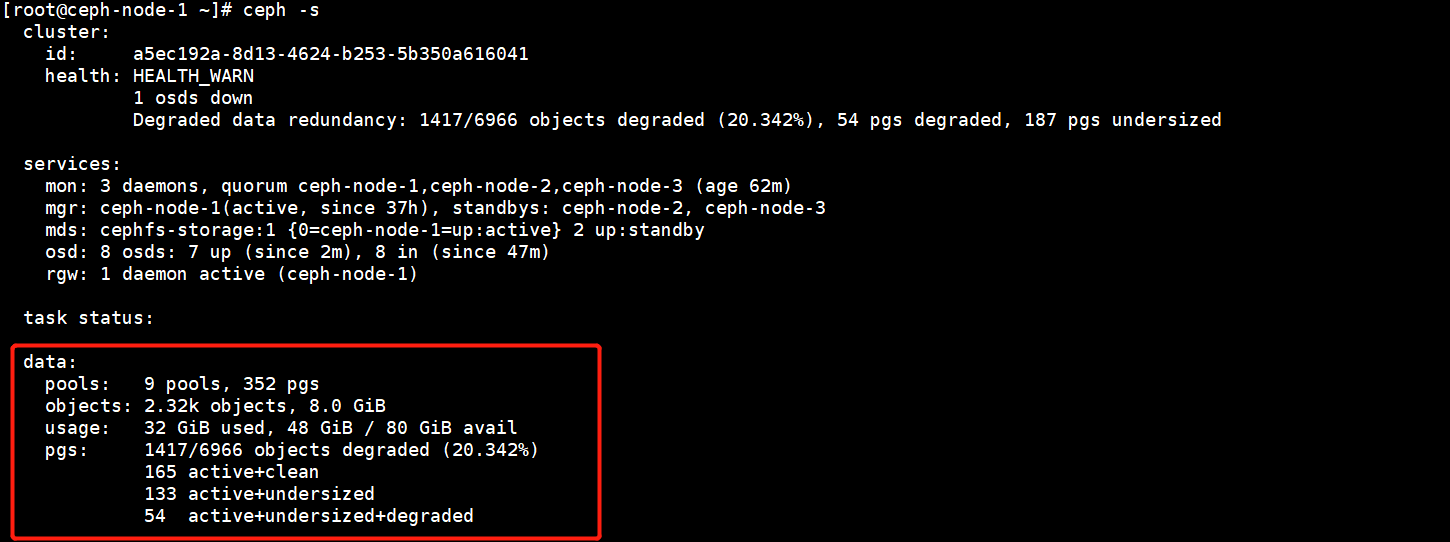
4.OSD故障更换硬盘流程
OSD故障更换硬盘的流程:
1、首先将硬盘坏掉的OSD从集群中删除。
2、修复硬盘。
3、将硬盘以新的OSD方式加入到集群中。
4.1.将故障的osd.5从集群中删除
和缩减OSD节点的方式一样。
4.1.1.从OSD Map中将故障的OSD删除
[root@ceph-node-1 ~]# ceph osd out osd.5
marked out osd.5.
从OSD Map中删除故障的OSD后,此时这个OSD的权限就为0了,不再写入数据。
4.1.2.从Crush Map中将故障的OSD删除
在Crush Map中会记录OSD的信息,我们需要在Crush Map中将OSD删除。
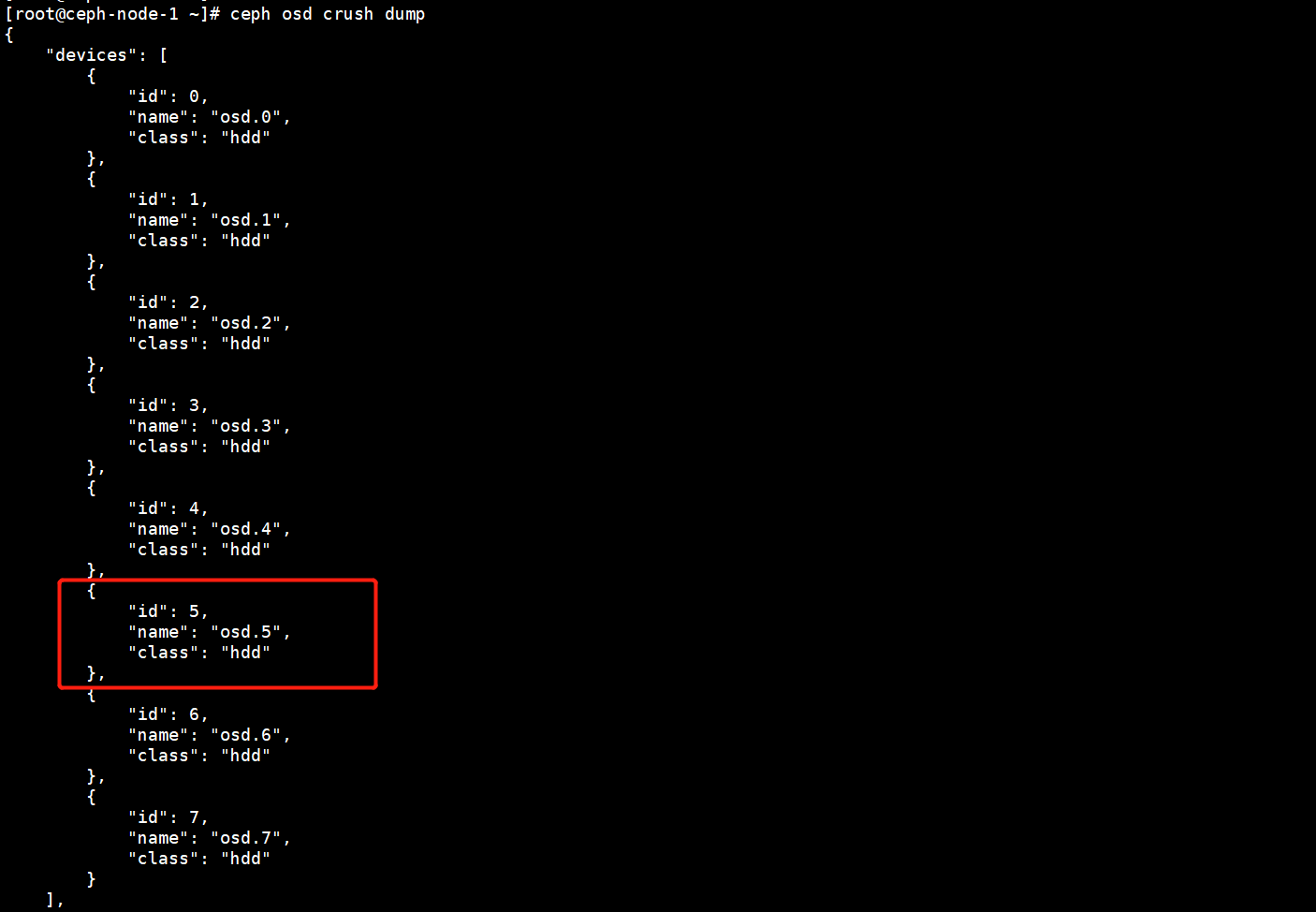
在Crush Map中删除OSD。
[root@ceph-node-1 ~]# ceph osd crush rm osd.5
removed item id 5 name 'osd.5' from crush map
4.1.3.在OSD列表中将故障的OSD删除
虽然在Crush Map中已经将OSD删除了,但是在OSD列表中还是有故障的OSD的。
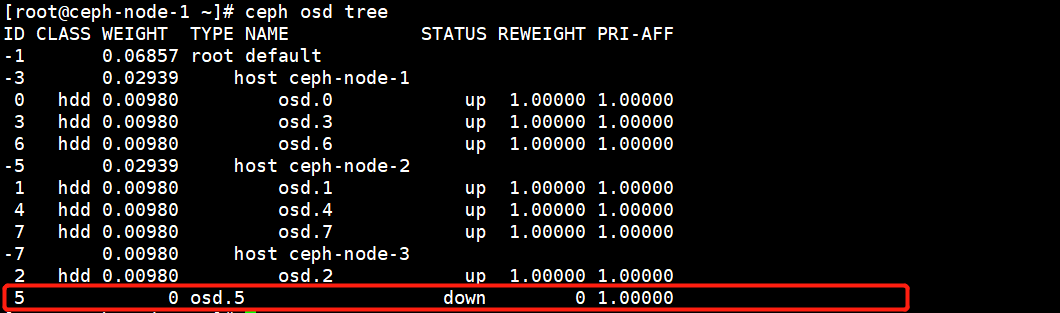
将故障的OSD在OSD列表中删除。
[root@ceph-node-1 ~]# ceph osd rm osd.5
removed osd.5
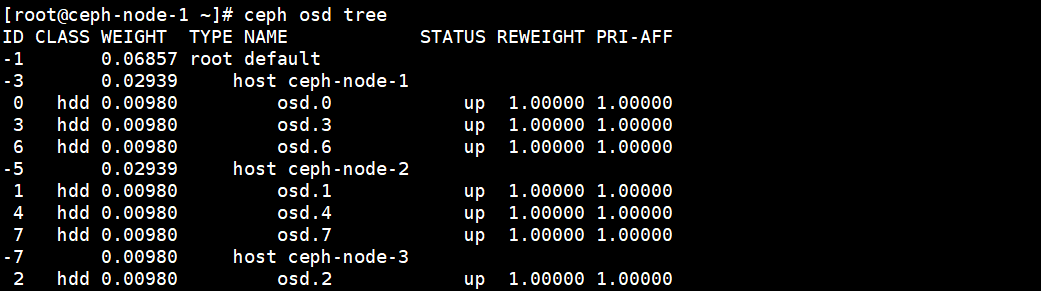
再次查看,OSD列表中已经没有故障的OSD了。
4.1.4.将故障的OSD认证信息删除
在OSD的认证信息中会记录所有OSD的认证凭据,在这里也需要将故障的OSD删除。
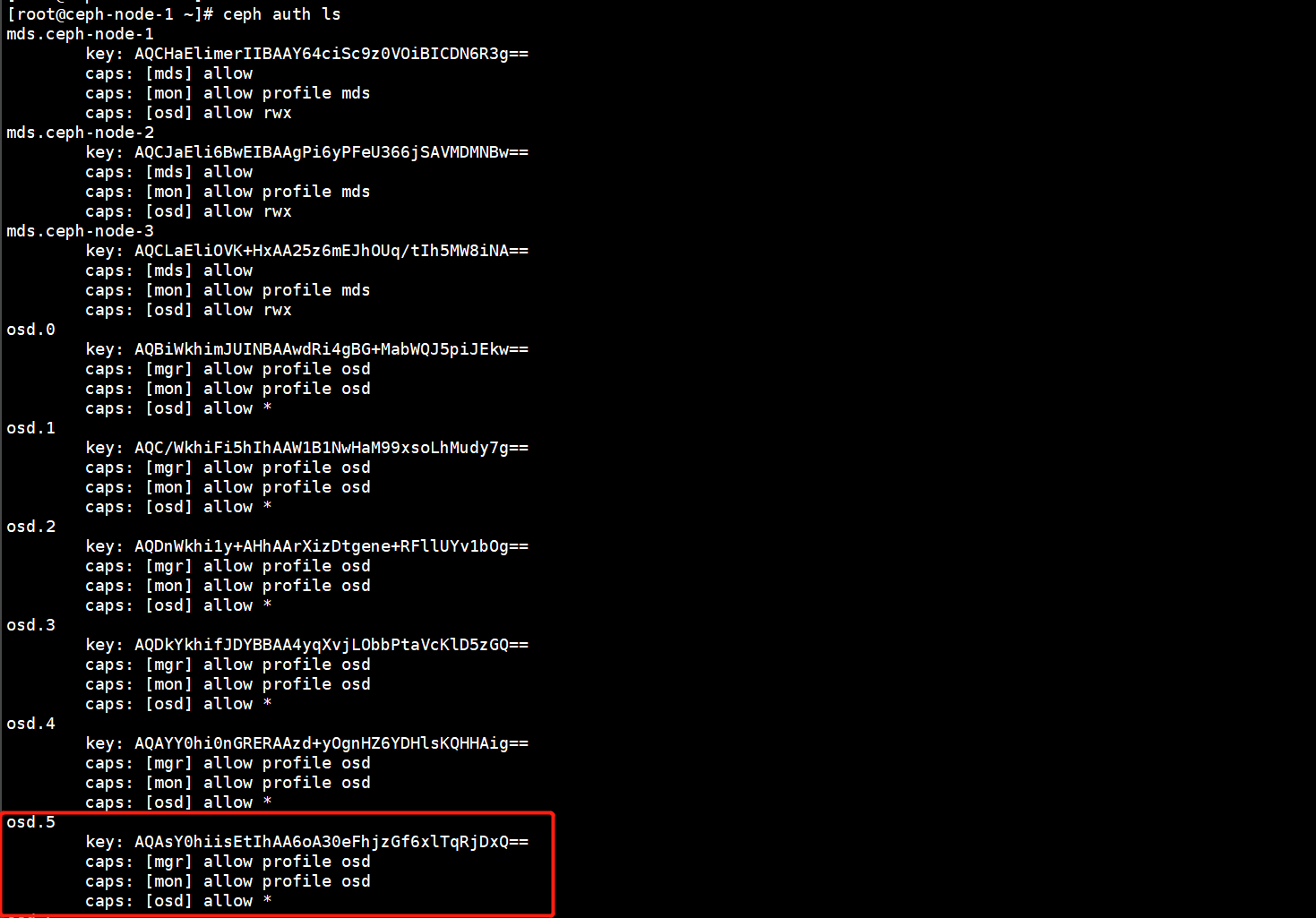
删除故障的OSD认证信息。
[root@ceph-node-1 ~]# ceph auth rm osd.5
updated
再次查看认证信息列表,就会发现故障的OSD已经被删除了。
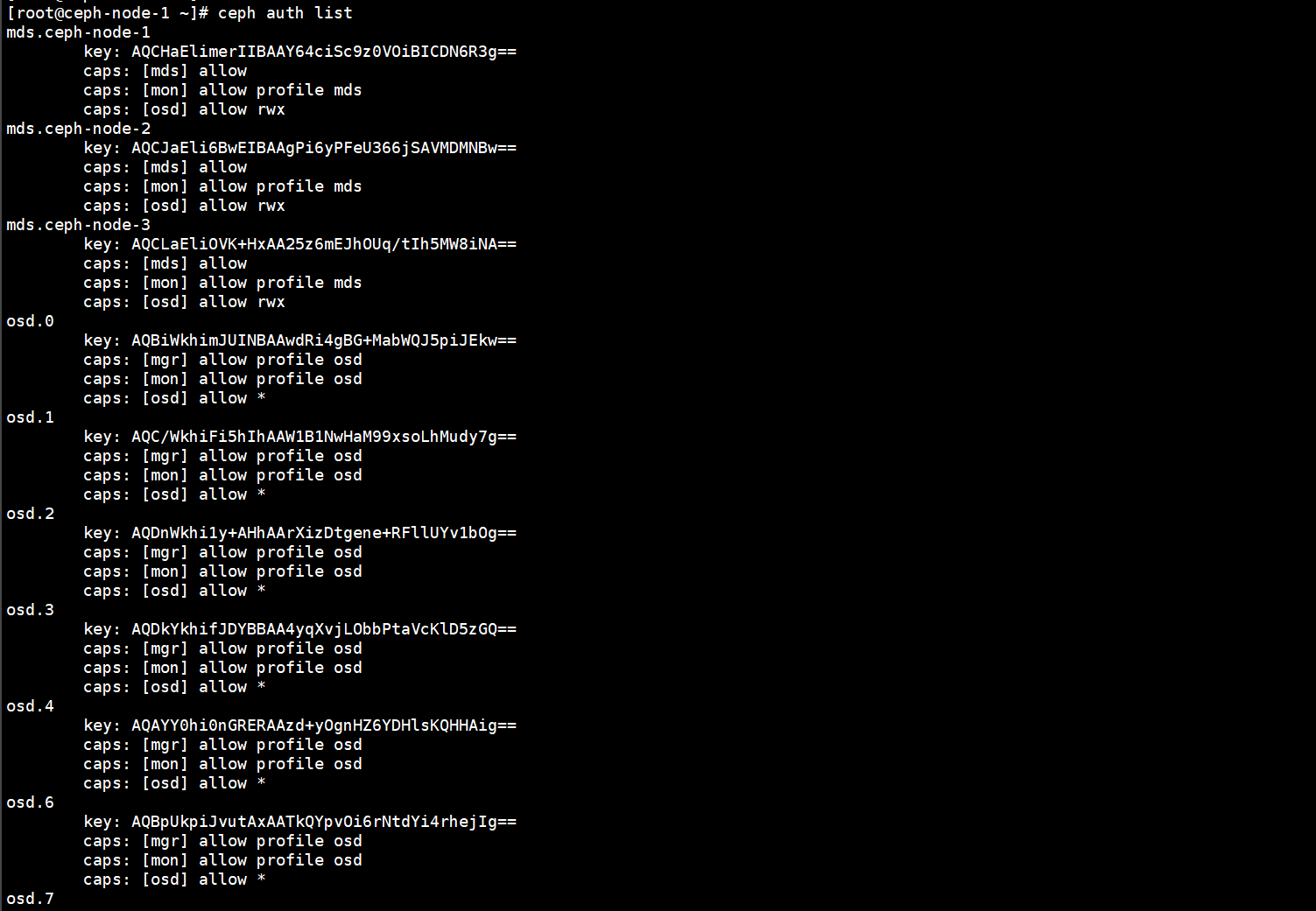
4.1.5.验证集群中是否已经将故障的OSD删除
原来集群中有8个OSD,选择已经变成7个OSD了,删除成功。
[root@ceph-node-1 ~]# ceph -scluster:id: a5ec192a-8d13-4624-b253-5b350a616041health: HEALTH_WARN1 nearfull osd(s)9 pool(s) nearfullDegraded data redundancy: 80/6966 objects degraded (1.148%), 4 pgs degraded, 2 pgs undersizedservices:mon: 3 daemons, quorum ceph-node-1,ceph-node-2,ceph-node-3 (age 81m)mgr: ceph-node-1(active, since 37h), standbys: ceph-node-2, ceph-node-3mds: cephfs-storage:1 {0=ceph-node-1=up:active} 2 up:standbyosd: 7 osds: 7 up (since 20m), 7 in (since 14m); 3 remapped pgsrgw: 1 daemon active (ceph-node-1)
4.2.换盘操作
将故障的OSD硬盘修复好之后,将该盘的LVM卷删除,然后通过添加OSD的方式,将该OSD重新加入集群即可。