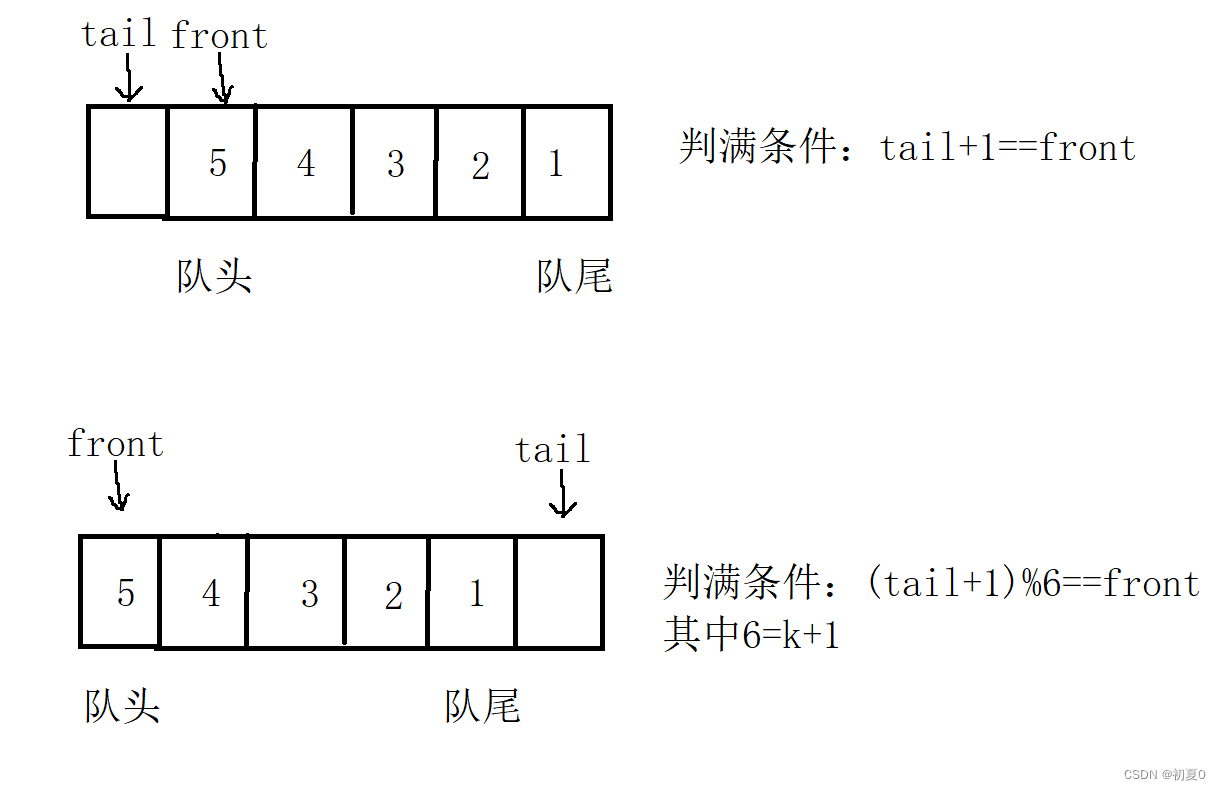
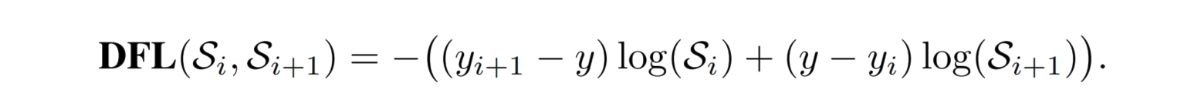目录
一 YOLOv5
二 YOLOv8

yolo通常采用backbone-neck-head的网络结构。
- Backbone 主要负责从输入图像中提取高层次的语义特征,常包含多个卷积层和池化层,构建了一个深层次的特征提取器。
- Neck通常用来进一步整合与调整backbone提取的特征,有利于将不同层次的特征融合进而提升网络对目标的感知能力。
- Head通常包括边界框回归层(用于预测目标的位置)和分类层(用于预测目标的类别)。进行最终的回归预测。
一 YOLOv5
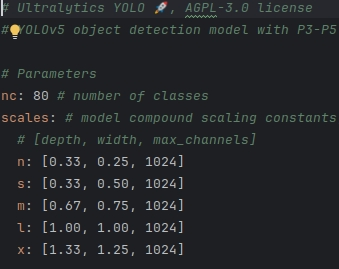
YOLOv5有s、m、l、x四个版本,模型的结构基本一样,不同的是depth_multiple模型深度和width_multiple模型宽度这两个参数。
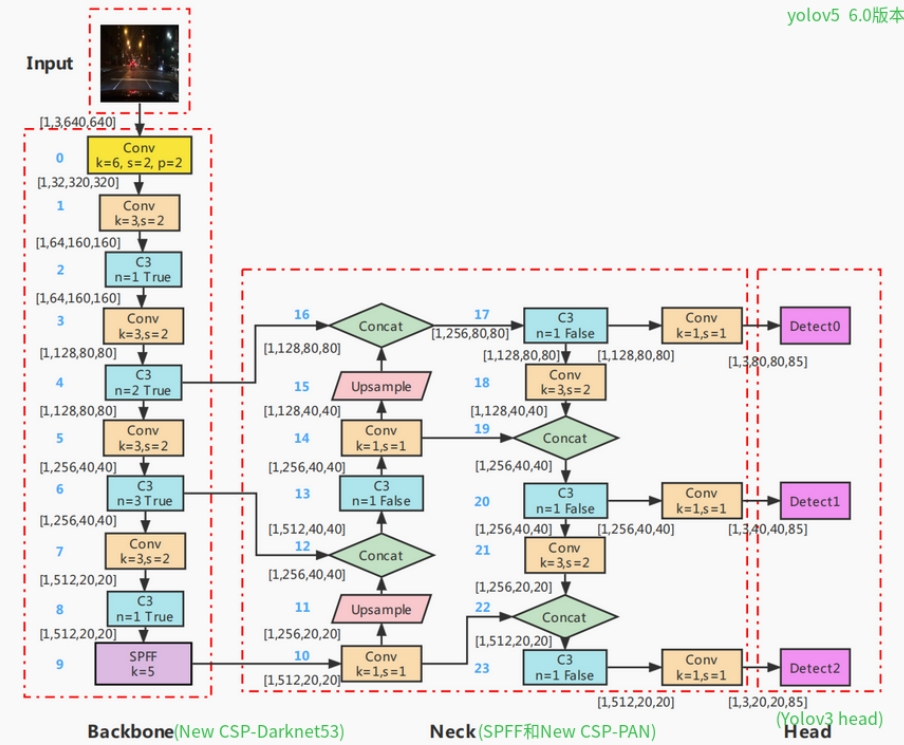
1 YOLOv5的网络结构
主要结构图如下所示:
① Input
YOLOv5在输入端Input采用了Mosaic进行数据增强。
采用Mosaic数据增强的优点:
- 随机使用4张图像,随机缩放后随机拼接,增加很多小目标,丰富数据集。
- 随机拼接的方式让一张图像可以计算四张图像的数据,减少每个batch的数量,即使只有一个GPU,也能得到较好的结果(减少GPU数量)。
- 通过对识别物体的裁剪,使模型根据局部特征识别物体,有助于被遮挡物体的检测,从而提升了模型的检测能力。
② Backbone
Conv卷积层由卷积,Batch Normalization和SiLu激活层组成。其中,BN(batch normalization)具有防止过拟合,加速收敛的作用。BN层的输入为一个batch的特征图,它将每个通道上的特征进行均值和方差的计算,并对每个通道上的特征进行标准化处理。标准化后的特征再通过一个可学习的仿射变换(拉伸和偏移)进行还原,从而得到BN层的输出。激活函数用于给神经网络引入非线性变换能力。综上所述,Conv模块是常用的基础模块,它通过卷积操作提取局部空间信息,并通过BN层规范化特征值分布,最后通过激活函数引入非线性变换能力,从而实现对输入特征的转换和提取。
k:卷积核大小;S:步长;P:padding填充;C:Channels通道数。

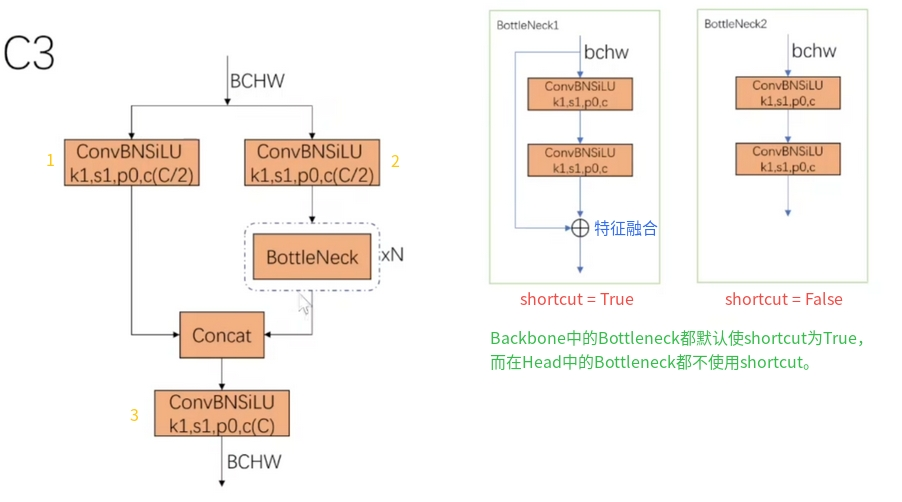
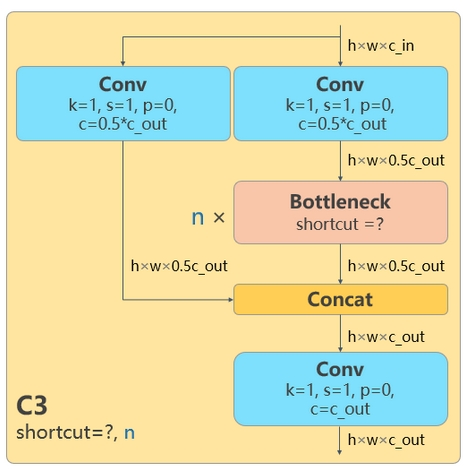
C3模块的作用是增加网络的深度和感受野,从不同维度去提取特征并融合,提高特征提取的能力。
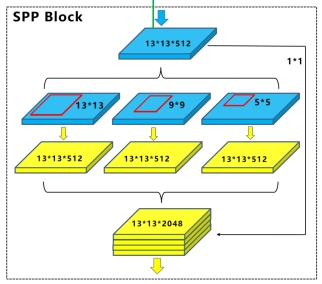
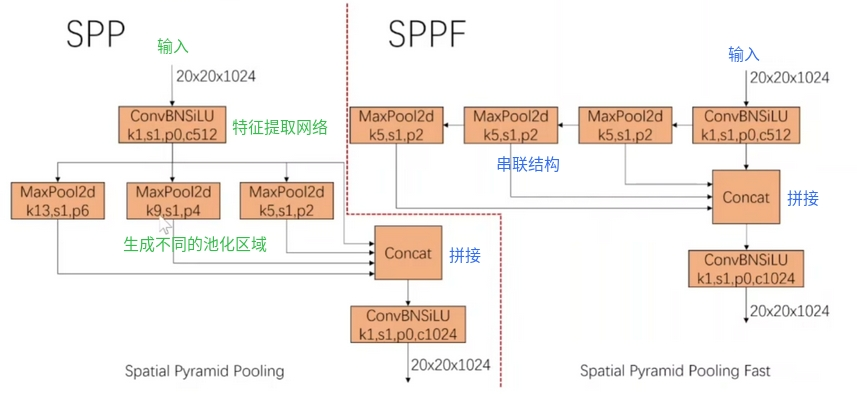
SPP(Spatial Pyramid Pooling),空间金字塔池化模块其主要思想是将不同大小的感受野应用于同一张图像,从而能够捕捉到不同尺度的特征信息。在SPP模块中,首先对输入特征图进行不同大小的池化操作,以得到一组不同大小的特征图。然后将这些特征图连接Concat在一起,并通过全连接层进行降维,最终得到固定大小的特征向量。综上所述,SPP的作用是将不同尺度的特征进行融合,通过对特征图进行金字塔划分和池化操作,将多尺度特征整合到一个固定长度的特征向量中。
SPP模块的具体可参考下图,仅便于理解,不要纠结于数字哈!
与SPP相比,SPPF模块的池化操作由并联变为串联,且池化区域大小不变。后面两次池化是在上一次的基础上进行的。
③ Neck
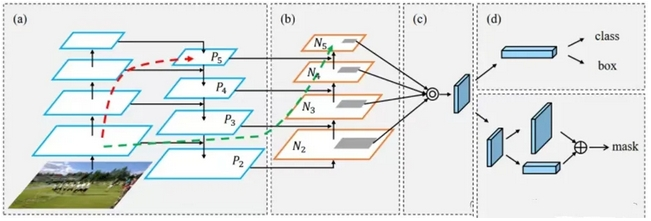
特征金字塔是一种用于处理多尺度目标检测的技术。在Neck部分,yolov5主要采用了PANet结构。
FPN通过自顶向下(Top-down)的结构,将深层的语义信息传递到浅层,但是浅层的位置信息却无法影响到深层特征。PANet在FPN(feature pyramid network)上提取网络内特征层次结构,在FPN的基础上又引入了一个自底向上(Bottom-up)的路径。经过自顶向下(Top-down)的特征融合后,再进行自底向上(Bottom-up)的特征融合,这样底层的位置信息也能够传递到深层,从而增强多个尺度上的定位能力。
其中自底向上(Bottom-up)的过程是沿着N 2 → N 3 → N 4 → N 5 的路径,逐个stage通过卷积进行2倍下采样,然后与FPN中相应大小的feature map进行相加融合(在YOLOv5中采用的是拼接融合)。
④ Head
YOLOv5的Head对Neck中得到的不同尺度的特征图分别通过1×1卷积将通道数扩展,扩展后的特征通道数为:(类别数量+5)×每个检测层上的anchor数量。
5对应的是预测框的中心点横坐标、纵坐标、宽度、高度和置信度。Head中的3个检测层分别对应Neck中得到的3种不同尺寸的特征图。
二 YOLOv8
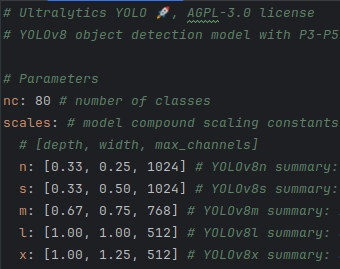
Yolov8提供了N/S/M/L/X不同尺度的模型,以满足不同部署平台和应用场景的需求。
YOLOV8的改进内容如下:
- Backbone:同样借鉴了CSP模块思想,但是将Yolov5中的C3模块替换成了C2f模块,实现了进一步轻量化,同时沿用Yolov5中的SPPF模块,并对不同尺度的模型进行精心微调,不再是无脑式一套参数用于所有模型,大幅提升了模型性能。
- Neck:继续使用PAN的思想,但是删除了上采样阶段的卷积结构,同时将C3模块替换为C2f模块。
- Head:相比YOLOv5改动较大,Yolov8换成了目前主流的解耦头结构(Decoupled-Head),将分类和检测头分离。从Anchor-Based换成了Anchor-Free思想(anchor-free和anchor-based是两种不同的目标检测方法,区别在于是否使用预定义的anchor框来匹配真实的目标框)。
- Loss计算:使用VFL Loss作为分类损失(实际训练中使用BCE Loss);使用DFL Loss+CIOU Loss作为回归损失。
- 标签分配:Yolov8抛弃了以往的IoU分配或者单边比例的方式,而是采用Task-Aligned Assigner分配方式。
1 YOLOV8的网络结构
主要结构图如下所示:
YOLOv5和YOLOv8配置文件参数对比:
| YOLOv5 | YOLOv8 |
|
|
|
① Backbone
V8同样借鉴了CSPDarkNet结构网络结构,但是将Yolov5中的C3模块替换成了C2f模块,实现了进一步轻量化,同时沿用Yolov5中的SPPF模块。
具体改进为:
- 第一个卷积层的卷积核大小(Kernel size)从6×6改为3x3。
- 所有的C3模块改为C2f模块(多了更多的跳层连接和额外Split操作)。
| C3 | C2f |
 | 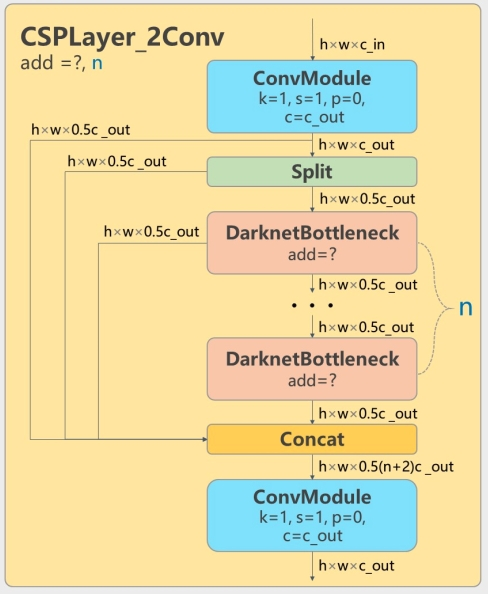 |
- Block数由C3模块3-6-9-3改为C2f模块的3-6-6-3。
YOLOv5和YOLOv8的Backbone对比:
| YOLOv5 | YOLOv8 |
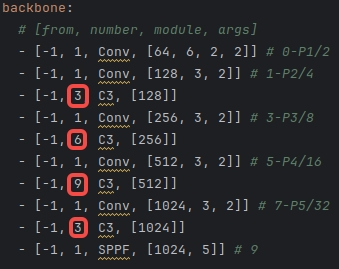 | 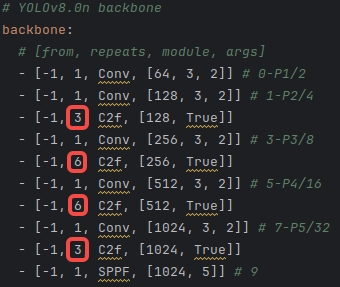 |
② Neck
Neck部分起到的作用是特征提取和特征融合,YOLOv8采用的是PAN-FPN的思想。
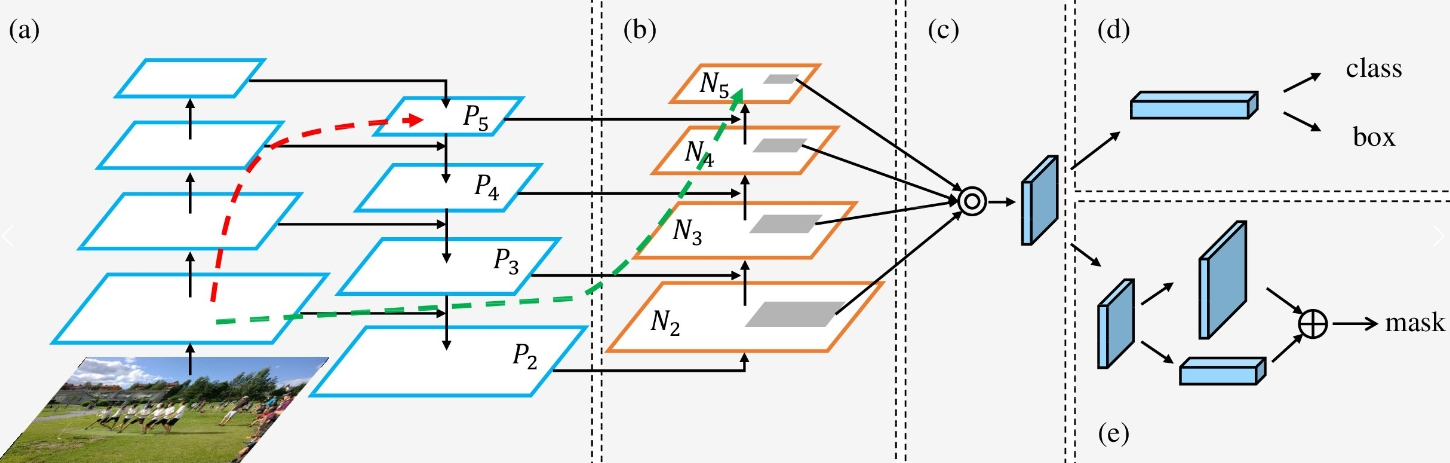
获取Neck产物的过程参考下图:
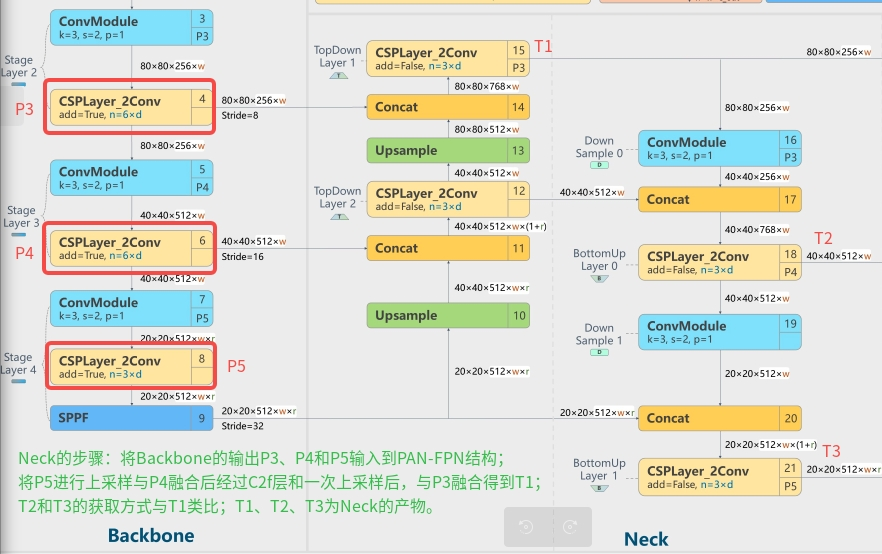
Layer4、Layer6、Layer9作为PANet(PANet是一个双向通路网络,引入了自下向上的路径,使得底层信息更容易传递到顶层)结构的输入,经过上采样,通道融合,最终将PANet的三个输出分支送入到Detect head中进行Loss的计算或结果解析。
③ Head
YOLOv8直接将耦合头改为类似Yolox的解耦头结构(Decoupled-Head),将回归分支和预测分支分离。
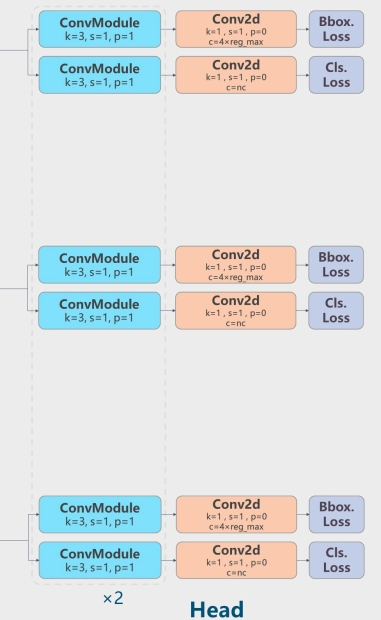
YOLOv5和YOLOv8的Head图对比:

YOLOv5和YOLOv8的配置文件Head对比:
| YOLOv5 | YOLOv8 |
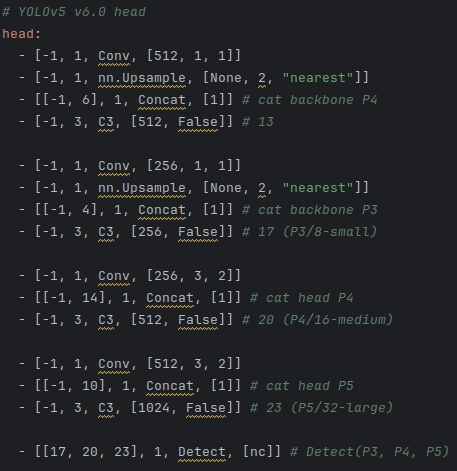 | 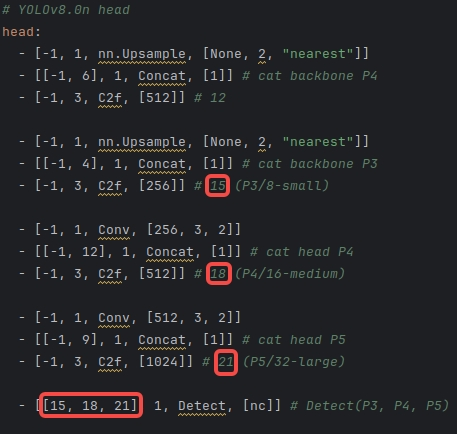 |
④ Loss
Loss计算过程包括两部分:正负样本分配策略和Loss计算(分类和回归分支)。
常见的正负样本分配策略包括动态分配策略和静态分配策略两种。
- 静态分配策略是指在训练开始之前,固定为一组预先定义的权重,这些权重不会在训练过程中改变。
- 动态分配策略则可以根据训练的进展和样本的特点动态调整权重,使之可以更加关注那些容易被错分的样本。动态分配策略可以根据训练损失或者其他指标来进行调整,可以更好地适应不同的数据集和模型。
YOLOv5采用的是静态分配策略,考虑到动态分配策略的优异性,Yolov8算法中直接引用了TOOD中的Task-Aligned Assigner(对齐分配器)正负样本分配策略。
分类得分和 IoU表示了这两个任务的预测效果,所以,TaskAligned使用分类得分和IoU的高阶组合来衡量Task-Alignment的程度。
![]()
s 和 u 分别为分类得分和 IoU 值,α 和 β 为权重超参。从上边的公式可以看出来,t 可以同时控制分类得分和IoU 的优化来实现 Task-Alignment,可以引导网络动态的关注于高质量的Anchor。
LOSS计算
分类损失:Yolov8团队应该是对VFL Loss和BCE Loss都尝试过,但最终发现使用VFL和使用普通的BCE效果相当,优势不明显,故采用了简单的BCE Loss。
回归损失:CIou_Loss + Distribution Focal Loss
其中,CIou_Loss用于计算预测框与目标框之间的IoU。
通常,对于遮挡、模糊场景下目标框的边界存在一定的不确定性,常规的回归方式不能解决这种不确定问题。
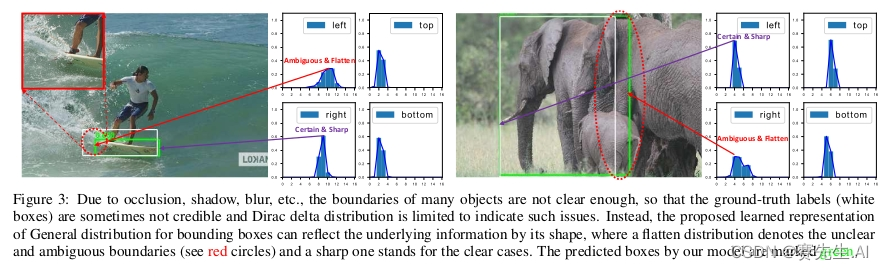
DFL将边界表示成一种分布,解决边界不明确的问题。