AGILEFORMER:用于医学图像分割的空间敏捷 Transformer UNET
- 摘要
- Introduction
- Method
- Deformable Patch Embedding
- 2.1.1 Rigid patch embedding
- 2.1.2 Deformable patch embedding
- Spatially Dynamic Self-Attention
- Deformable Multi-head Self-Attention (DMSA)
- Neighborhood Multi-head Self-Attention (NMSA)
- Multi-scale Deformable Positional Encoding
AGILEFORMER: SPATIALLY AGILE TRANSFORMER UNET FOR MEDICAL IMAGE SEGMENTATION
摘要
在过去的几十年中,深度神经网络,尤其是卷积神经网络,已经在各种医学图像分割任务中取得了最先进的表现。近年来,视觉Transformer(ViT)的引入显著改变了深度分割模型的格局。由于它们出色的性能和可扩展性,对ViTs的关注日益增加。然而,我们认为目前基于视觉Transformer的UNet(ViT-UNet)分割模型的设计可能无法有效地处理医学图像分割任务中感兴趣对象的异质外观(例如,不同的形状和大小)。
为了应对这一挑战,我们提出了一种结构化的方法,将空间动态组件引入到ViT-UNet中。这种适应使得模型能够有效地捕捉到具有不同外观的目标对象特征。这是通过以下三个主要组件实现的:
可变形的Patch嵌入;
空间动态的多头注意力;
可变形的位置编码。
这些组件被集成到一个称为AgileFormer的新颖架构中。AgileFormer是一个为医学图像分割设计的空间灵活的ViT-UNet。在三个分割任务中使用公开可用数据集进行的实验证明了所提出方法的有效性。
代码:https://github.com/sotiraslab/AgileFormer
Introduction
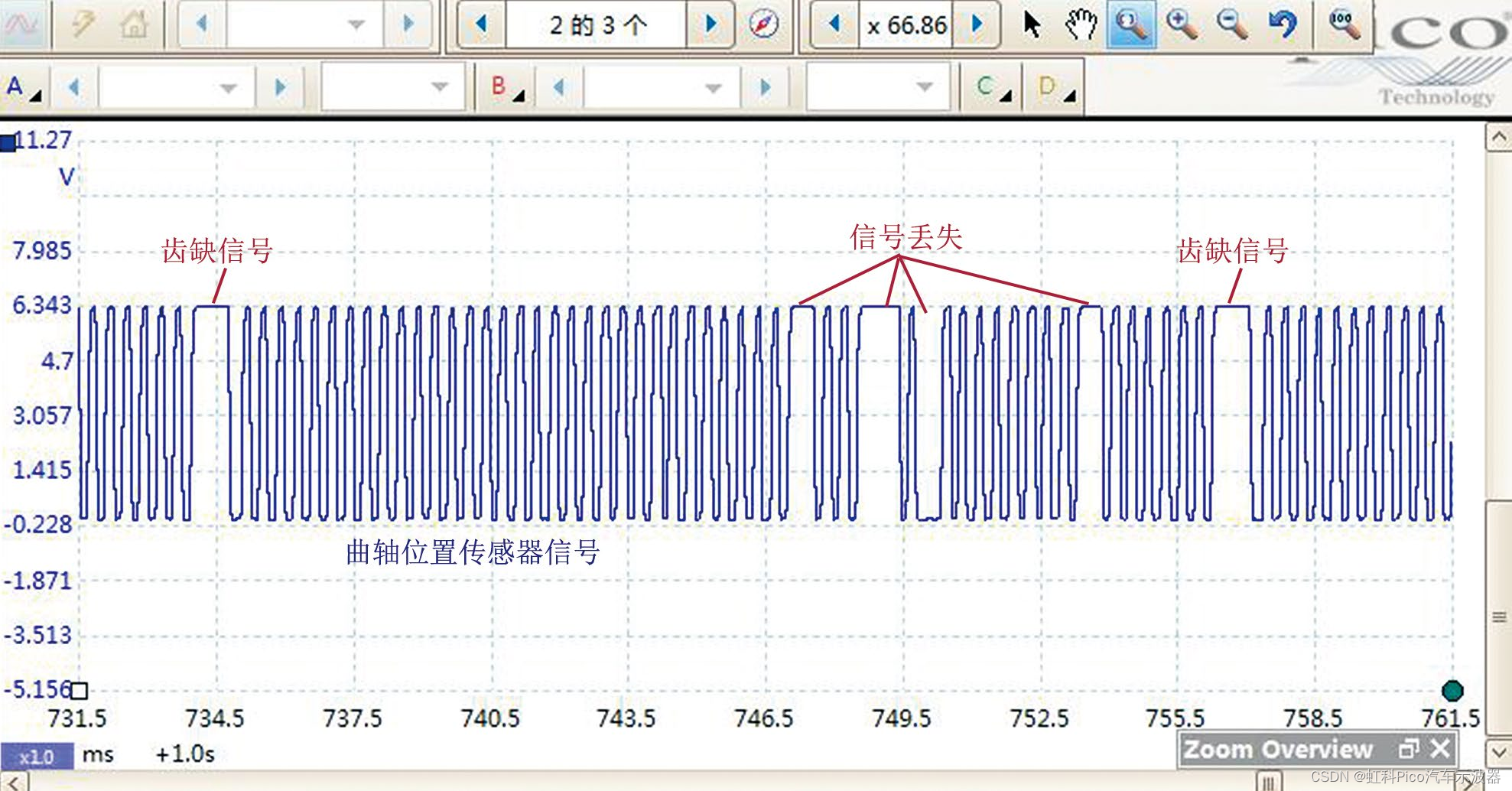
医学图像分割任务在现代医学中至关重要,因为它是许多基于图像的诊断和分析的第一步[1, 2]。基于深度学习的自动化分割方法由于其高效率和最先进的表现而在这一领域占据主导地位。其中,卷积神经网络(CNNs)[3, 4, 5, 6, 7, 8]自从UNet[3]提出以来已成为最流行的选择。这是因为CNN在处理图像驱动任务时具有固有的优势,例如它们捕捉局部性和平移不变性的能力。然而,它们主要由于受限的感受野而在捕捉全局语义方面存在困难。
相比之下,最近提出的视觉Transformer(ViT)[9]通过自注意力机制缓解了这个问题,该机制捕捉图像块之间的依赖关系,而不管它们的空间距离如何。首个基于ViT的UNet(ViT-UNet)医学图像分割模型结合了ViT编码器和CNN解码器,因此被称为TransUNet[1]。然而,TransUNet由于参数量巨大(约1亿)和计算复杂度较高而受到限制。
这是因为它采用了标准自注意力,其时间和内存复杂度与输入标记大小成二次关系。利用窗口注意力[10],它在所有图像块中对一个小窗口内的自注意力进行并行处理,SwinUNet[2]缓解了这一挑战,并且是第一个以自注意力作为主要特征提取器的纯ViT-UNet。然而,SwinUNet使用固定大小的窗口,这可能限制了其捕捉不同大小和形状目标对象的精确表示的能力。这可能限制了其在多类分割任务中的适应性和泛化能力。
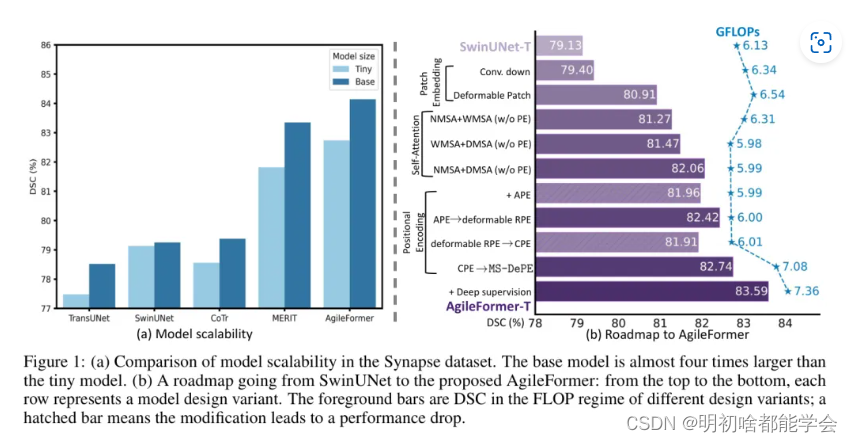
此外,SwinUNet并没有表现出良好的扩展行为。换句话说,当增加模型大小时(如图1(a)所示),它们的性能并没有有效地扩展。这与使用自然图像的实证研究提供的证据形成对比,这些研究表明ViT表现出卓越的扩展行为。我们假设这一现象也可能归因于针对分割的目标对象在大小和形状上的异质性,这无法通过固定大小的窗口处理。
为了解决这些挑战,提高ViT-UNet的性能和可扩展性需要空间动态组件。尽管最近的工作已经探索将动态(例如,多尺度[11],可变形[12; 13])组件引入到医学成像的ViT-UNet中,但它们主要关注采用现有的可变形注意力。然而,它们没有研究将动态组件引入到ViT-UNet的其他部分(即,图像块嵌入和位置编码)。我们认为,增强这些其他部分的动态元素同样重要。关于AgileFormer如何从根本上与上述三篇工作不同,我们将在附录A中为读者提供深入讨论。
因此,我们开发了一种新颖的空间敏捷纯ViT-UNet,以捕捉医学图像分割任务中多样的目标对象。首先,我们用一种新颖的可变形图像块嵌入替换了ViT-UNet中的标准刚性正方形图像块嵌入。其次,我们采用空间动态自注意力[14]作为捕捉空间变化特征的建筑块。第三,我们提出了一种新颖的多尺度可变形位置编码,以在自注意力中建模不规则采样的网格。我们将这些动态组件集成到一个名为AgileFormer的新颖ViT-UNet架构中。广泛的实验证明了所提出方法在三个医学图像分割任务中的有效性。AgileFormer优于最近的医学图像分割领域的最先进的UNet模型,并展示了卓越的可扩展性。
Method
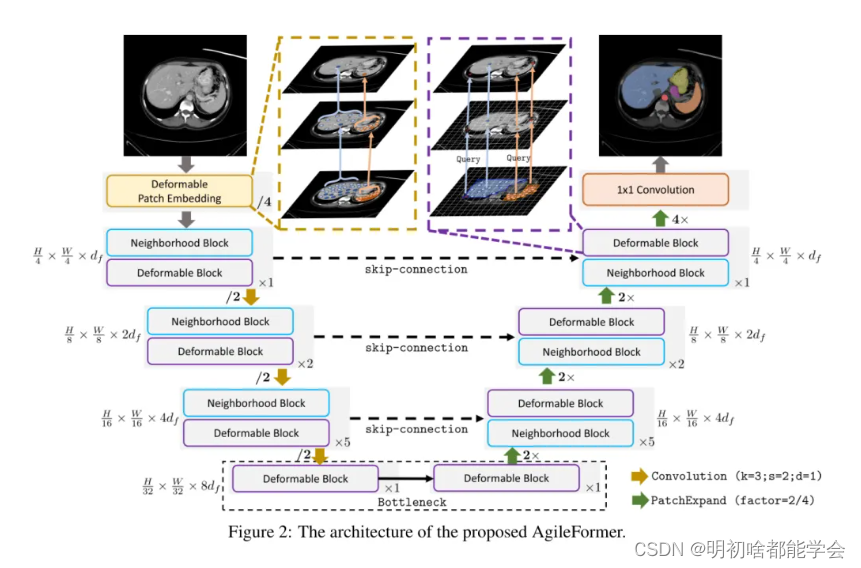
在本节中,我们提供了一个从标准SwinUNet到所提AgileFormer的路线图(见图1(b))。为了使本文内容自包含,我们首先简要介绍ViT-UNets中的基本要素。一个ViT-UNet(例如,SwinUNet)是一个带有跳跃连接的U形编码器-解码器网络,其中编码器和解码器的主要特征提取是通过自注意力机制实现的。标准ViT-UNet的构建块由三个基本组成部分组成:Patch嵌入、自注意力和位置编码。Patch嵌入将图像Patch投影到特征嵌入中。更近期的ViTs甚至将下采样(即在SwinUNet中的Patch合并)视为Patch嵌入的一部分。在本文中,我们将遵循相同的惯例。
自注意力,用于捕获图像Patch之间的依赖关系,用于主要特征提取。为了计算的可行性和局部性需求,最近的ViT-UNets使用基于窗口的自注意力机制。与卷积不同,自注意力丢弃了图像Patch之间的空间相关性,这阻碍了纯ViT在分割任务中的定位能力。位置编码用于解决这一限制。我们想指出,也有混合模型,其中编码器/解码器中的主要特征提取是通过CNN和ViT实现的。然而,本文关注于开发一个纯ViT-UNet。
Deformable Patch Embedding
可变形Patch嵌入是一种最近提出的技术,用于改进深度学习模型中视觉数据的表示。它特别适用于需要高分辨率输入的任务,例如语义分割和目标检测。
2.1.1 Rigid patch embedding
ViT-UNet首先将图像块转换为tokens。这个过程通常包括将图像分割成—系列不重叠的n x n (×n)(例如,在SwinUNet中为4×4(x4))固定大小的块。随后,这些块中的每一个都会被投影成一个1D特征向量。执行刚性((正方形)块嵌入的主要原因是其简单性,因为它可以很容易地通过标准卷积(卷积核大小k=n;步长s =n;膨胀系数d=1)来实现。
然而,我们认为这种刚性块嵌入对于分割任务并不是最优的选择,主要有两个原因。首先,分割需要更精确的像素级定位。然而,刚性块嵌入只能提供块级定位。其次,在大多数医学图像分割任务中(例如,多器官分割任务),目标对象的形状和大小差异显著。
2.1.2 Deformable patch embedding
为了解决刚性Patch嵌入的限制,我们提出了一个可变形Patch嵌入(见图2),通过利用可变形卷积。可变形卷积定义为
(f * k)p]=>p.eo 队(f; p+△p + p:)·k[p:],其中f ∈RLxd是一个具有L个位置的统─网格的d,维特征图p ∈RLxD(D=2为2D; D=3为3D)。k是在网格=pke]上操作的卷积核,定义了p的k-最近(即核大小)邻近位置。[Ap]是从不规则网格采样的偏移量。这些偏移量通过一个卷积层△p = Convoffset (f)学习得到。如是一个采样函数,它通过双线性/三线性插值来采样f 中的位置[p+△p+ pi],因为偏移量△p通常为分数。
首次Patch嵌入。我们用两个连续的可变形卷积层(k =3; s = n/2; d=1)替换了标准SwinUNet中的单层刚性卷积Patch嵌入。这样做的原因是,两个连续的、重叠的可变形Patch嵌入可以提取更好的局部表示,这弥补了自注意力中的局部性不足。
下采样Patch嵌入。我们还用单层卷积下采样(k=3; s = 2; d =1)替换了标准SwinUNet中的Patch合并,用于下采样。我们使用重叠核以更好地保留局部模式[22,15,20],这也与重叠的可变形Patch嵌入相一致。
Spatially Dynamic Self-Attention
自我关注是ViT UNet的基本构建块。与卷积不同,自我关注不强制任何空间感应偏差,而是纯粹通过依赖标记之间的依赖关系(主要是相似性)来做决策,同时缺乏捕捉适应多类分割的空间特征的能力。因此,我们提出使用空间动态自我关注模块作为ViT-UNet的构建块。这个模块受到[15]的启发,它包括可变形多头注意力(DMSA)[15]和邻域多头注意力(NMSA)[23]。Transformer块是通过交替这两种注意力机制构建的(见图2)。我们还将在第三编码器块中分配更多的计算,其阶段比例为1:2:5:1,而不是SwinUNet中的2:2:2:2。这是因为编码器的第三层通常比其他层捕捉到更好的特征表示[24]。
Deformable Multi-head Self-Attention (DMSA)
第h个头部的可变形多头(即H个头部)注意力[15]被表述为
DMSAn(f) = softmax(Qnkh /√de)Vh
其中:
= fwR,k= fwK,V1= fwX,f =(f;p+pn ).
这里,我们重用了方程(1)中的表示法,其中p是均匀的点网格,△p是为第h个头部生成的偏移量,p是一个插值函数。{W;, w}∈ Rd×dk和WK ∈ Rdr×d是可训练的参数,dx和d.分别是DMSA中键K,和值Vh的线性投影的隐藏维度。DMSA中的偏移量也是通过将查询通过一个卷积层△p = Convoffset(Qh)生成的。方程(3)中表示的由此产生的非规则采样特征图记为f。与可变形卷积类似,非规则采样的特征图随后通过使用非规则采样的键K,和值Vn应用于自注意力(见方程(2))。
Neighborhood Multi-head Self-Attention (NMSA)
此外,这重新将局部操作引入自注意力机制,允许平移等方差,从而增强更好地保留局部信息的能力。按照方程(2)中的记法,位置pr的邻域多头注意力计算如下:
NMSAn(f[p])= softmax(Q,lp]Kn [pi]T / √dx)Vh pi]
其中:
kn[P]=[Kn[Pu],………,Kn [Puk]],K)= fWAV, pi]= [Vh[Pu]T,…., Vh[Pu]T]T,VA= fWX.
这里,[pu;]表示给定位置pr的第 k个邻域位置。值得注意的是,所得到的注意力的维度是RLxK,其中K=k x k(×k),而不是标准自注意力或窗口注意力中的RLxL
Multi-scale Deformable Positional Encoding
在之前的ViT UNets中,位置编码(PE)的设计几乎没有被探索。大多数ViT-UNets要么忽略位置编码[1],要么继承自其祖先模型[25; 2; 16]。具体来说,[25]使用了绝对位置编码(APE),为每个标记分配一个绝对值。而其他研究[2; 16; 20]使用了相对位置编码(RPE)[26]来编码标记之间的相对位置。然而,这些设计都是针对1D信号而忽略空间相关性。因此,它们并不很好地适应于具有空间相关性的2D/3D信号的建模。最近,条件位置编码(CPE)[27]被设计用于视觉任务,同时具有APE和RPE的能力。
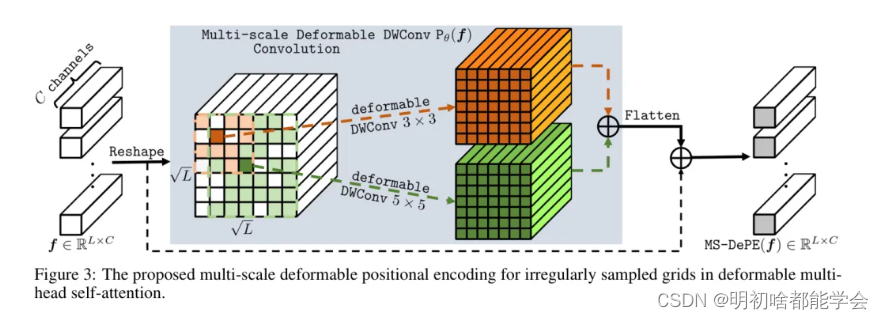
更重要的是,标准的APE、RPE和CPE并不直接适用于不规则采样的网格,因为它们都是在刚性网格中公式化的。与本文提出的非规则采样DMSA相一致,我们提出了一个多尺度可变形位置编码(MS-DePE),旨在跨多个尺度编码非规则采样的位置信息(见图3)。
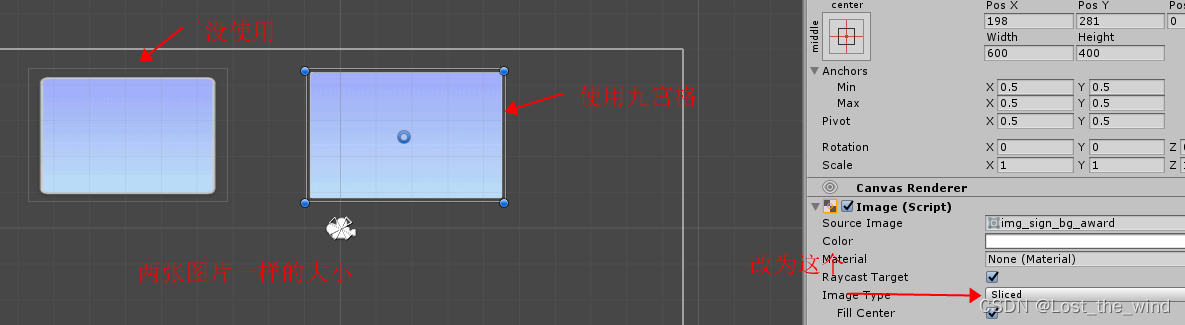
![[Mac]安装App后“XX已损坏,无法打开“](https://img-blog.csdnimg.cn/direct/1c853bec01454fe48d87bbfa5f35f91e.png)