文章目录
- 介绍
- 使用方式
- 硬件需求
- 环境安装
- 仓库下载
- 模型下载
- 环境安装
- 安装三方库
- 代码调用
- 从本地加载模型
- Demo演示
- 命令行 Demo
- API Demo
- OpenAI 格式的流式 API Demo
- 基于 Streamlit 的网页版 demo
- 低成本部署
- 相关问题
- No module named ‘readline’
- 解决方法
- module ‘collections’ has no attribute ‘Callable’
- 解决方法
- charset_normalizer
- 解决方式
- transformers_modules.THUDM/chatglm2-6b
- 解决方式
- 参考链接
介绍
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和
- 更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。如果您发现我们的开源模型对您的业务有用,我们欢迎您对下一代模型 ChatGLM3 研发的捐赠。
使用方式
硬件需求
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
环境安装
仓库下载
首先需要下载本仓库:
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B
模型下载
从 Hugging Face Hub 下载模型需要先安装Git LFS,Windows:git lfs install ,Centos:yum install git 。然后运行
git clone https://huggingface.co/THUDM/chatglm2-6b
环境安装
为不影响电脑中的现有环境,请一定要安装Conda,如果您不知道什么是Conda,或者未安装过Conda,请参考如下文章,安装部署Conda之后再继续以下步骤。
Anaconda介绍、安装及入门使用指南
https://blog.csdn.net/qq_43961619/article/details/131632933
在CMD中执行下面的命令行,创建Conda虚拟环境至该项目的目录中,方便日后重装系统也能够正常使用,无需重新部署环境。
conda create -n glm2 python=3.8
chatglm-6b:虚拟环境名称
python==3.8:所依赖python版本
执行完成上面的命令之后,将会在CMD窗口中看到Proceed ([y]/n)?提示,我们直接按下回车即可。
执行以下命令激活已创建的Conda环境,这样我们可以将我们后续所需要的所有环境依赖都安装至此环境下
conda activate glm2
安装三方库
安装必要的第三方库时,执行以下命令
pip install -r requirements.txt
如果下载特别慢可以指定源为国内源进行pip install
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
如果一个一个手动安装第三方库,则会出现库与库之间版本不兼容的问题,安装完运行代码时会报错
官方提示:transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能。环境安装
注意:CUDA版本需≥11.8才能直接创建torch2.0的镜像,需注意
如果是想运行GPU版本Pytorch,pip install 命令,添加--find-links https://download.pytorch.org/whl/torch_stable.html,否则可能下载的是cpu版本torch
代码调用
可以通过如下代码调用 ChatGLM2-6B 模型来生成对话:
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda')
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
从本地加载模型
以上代码会由 transformers 自动下载模型实现和参数,如果将模型下载到本地之后,将以上代码中的 THUDM/chatglm2-6b 替换为你本地的 chatglm2-6b 文件夹的路径,即可从本地加载模型。
官方提示:模型的实现仍然处在变动中。如果希望固定使用的模型实现以保证兼容性,可以在 from_pretrained 的调用中增加
revision="v1.0"参数。v1.0 是当前最新的版本号,完整的版本列表参见 Change Log。
警告:因为源码中模型的加载路径遵从了Liunx的方式,而我们使用了Windows系统来搭建,这与Liunx的路径转义有区别。
所以如果你是Windows系统,需要根据以下步骤修改源码,如果你是Linux请路过该部分,不要进行操作。
此时我们需要做一件事,那就是分别修改cli_demo.py|web_demo.py|web_demo2.py三个文件内的模型路径,将THUDM/chatglm2-6b修改为THUDM\chatglm2-6b即可。
提示:假如你以后只想通过使用web_demo.py的方式来运行该模型,那么只修改web_demo.py这一个文件的内容即可,无需对三个文件全部进行修改,但推荐全部修改。
Demo演示
命令行 Demo
修改cli_demo.py 文件
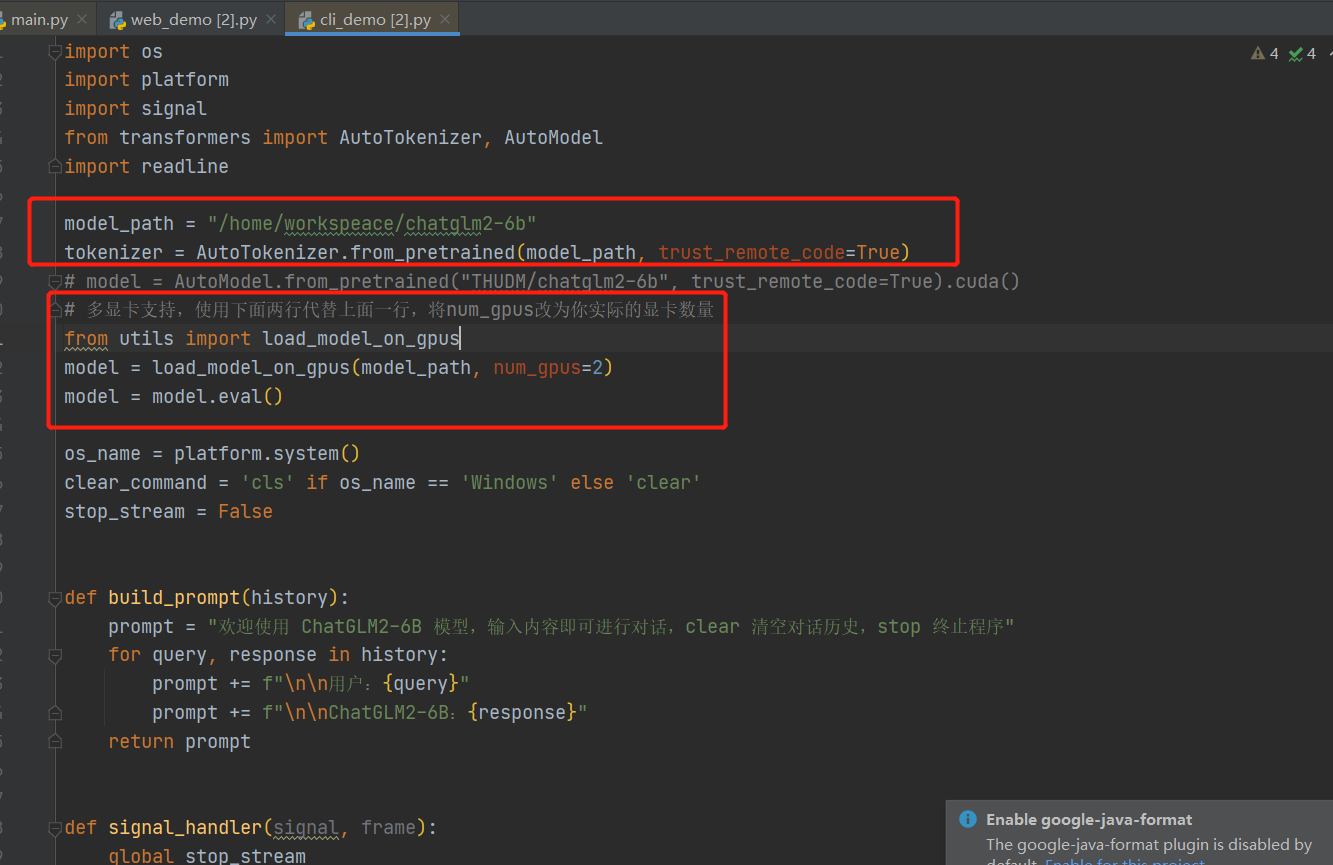
model_path = "/home/workspeace/chatglm2-6b"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
from utils import load_model_on_gpus
model = load_model_on_gpus(model_path, num_gpus=2)
model = model.eval()
运行仓库中 cli_demo.py:
python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
经典问题:

API Demo
需要安装额外的依赖 pip install fastapi uvicorn,然后运行仓库中的 api.py:
python api.py
默认部署在本地的 8000 端口,通过 POST 方法进行调用
curl -X POST "http://127.0.0.1:8000" \-H 'Content-Type: application/json' \-d '{"prompt": "你好", "history": []}'
得到的返回值为
{"response":"你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。","history":[["你好","你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。"]],"status":200,"time":"2023-03-23 21:38:40"
}
OpenAI 格式的流式 API Demo
感谢 @hiyouga 实现了 OpenAI 格式的流式 API 部署,可以作为任意基于 ChatGPT 的应用的后端,比如 ChatGPT-Next-Web。可以通过运行仓库中的openai_api.py 进行部署:
python openai_api.py
进行 API 调用的示例代码为
import openai
if __name__ == "__main__":openai.api_base = "http://localhost:8000/v1"openai.api_key = "none"for chunk in openai.ChatCompletion.create(model="chatglm2-6b",messages=[{"role": "user", "content": "你好"}],stream=True):if hasattr(chunk.choices[0].delta, "content"):print(chunk.choices[0].delta.content, end="", flush=True)
基于 Streamlit 的网页版 demo
通过以下命令启动demo:
streamlit run web_demo2.py
启动web_demo2.py,该步骤需要载入模型,然后自动载入对话交互界面,请耐性等待五分钟左右,等待时间因电脑性能而定。
首先次启动可能看到需要您填写Email的地址,这里填写之后将会自动接收到关于Streamlit的广告,我们直接不输入任何内容,按下回车即可跳过。
等待片刻之后,将会自动打开一个网页,地址为:http://127.0.0.1:7860,之后就可以正常使用啦。
经典问题(没有回答上来):
注意:第一次问答时需要载入模型算法,所以需要等待较长的时间,但是从第二次对话开始,速度将会得到极大的提升。
该方式不支持查看历史对话记录。
低成本部署
官方提供低成本部署,可自行查阅文档
https://github.com/THUDM/ChatGLM2-6B#%E4%BD%8E%E6%88%90%E6%9C%AC%E9%83%A8%E7%BD%B2
相关问题
ImportError: This modeling file requires the following packages that were not found in your environment: icetk. Run pip install icetk
前期准备工作完成,根据readme.md进行demo运行即可进行体验
如果遇到类似于以下的报错提示,那么代表您没有安装正确版本的PyTorch和CUDA
Running setup.py install for sentencepiece ... errorerror: subprocess-exited-with-error× Running setup.py install for sentencepiece did not run successfully.│ exit code: 1╰─> [15 lines of output]running installC:\Users\openA\AppData\Local\Programs\Python\Python311\Lib\site-packages\setuptools\command\install.py:34: SetuptoolsDeprecationWarning: setup.py install is deprecated. Use build and pip and other standards-based tools.warnings.warn(running buildrunning build_pycreating buildcreating build\lib.win-amd64-cpython-311creating build\lib.win-amd64-cpython-311\sentencepiececopying src\sentencepiece/__init__.py -> build\lib.win-amd64-cpython-311\sentencepiececopying src\sentencepiece/_version.py -> build\lib.win-amd64-cpython-311\sentencepiececopying src\sentencepiece/sentencepiece_model_pb2.py -> build\lib.win-amd64-cpython-311\sentencepiececopying src\sentencepiece/sentencepiece_pb2.py -> build\lib.win-amd64-cpython-311\sentencepiecerunning build_extbuilding 'sentencepiece._sentencepiece' extensionerror: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/[end of output]note: This error originates from a subprocess, and is likely not a problem with pip.
error: legacy-install-failure× Encountered error while trying to install package.
╰─> sentencepiecenote: This is an issue with the package mentioned above, not pip.
hint: See above for output from the failure.
No module named ‘readline’
readline 模块是用于在命令行界面中提供交互式输入和历史记录功能的库。它通常是在 Unix/Linux 系统上可用,并且在某些 Windows 环境中可能不会被默认安装。
(D:\openai.wiki\ChatGLM2-6B\ENV) D:\openai.wiki\ChatGLM2-6B>pip install --upgrade charset_normalizer
Requirement already satisfied: charset_normalizer in d:\openai.wiki\chatglm2-6b\env\lib\site-packages (2.0.4)
Collecting charset_normalizerUsing cached charset_normalizer-3.1.0-cp38-cp38-win_amd64.whl (96 kB)
Installing collected packages: charset_normalizerAttempting uninstall: charset_normalizerFound existing installation: charset-normalizer 2.0.4Uninstalling charset-normalizer-2.0.4:Successfully uninstalled charset-normalizer-2.0.4
Successfully installed charset_normalizer-3.1.0(D:\openai.wiki\ChatGLM2-6B\ENV) D:\openai.wiki\ChatGLM2-6B>python cli_demo.py
Traceback (most recent call last):File "cli_demo.py", line 5, in <module>import readline
ModuleNotFoundError: No module named 'readline'
解决方法
执行如下代码,直接通过PIP安装即可。
pip install pyreadline
module ‘collections’ has no attribute ‘Callable’
根据错误消息,它指出在模块pyreadline的modes/emacs.py文件中使用了collections.Callable,但是collections模块中没有Callable属性。
(D:\openai.wiki\ChatGLM2-6B\ENV) D:\openai.wiki\ChatGLM2-6B>python cli_demo.py
Traceback (most recent call last):File "D:\openai.wiki\ChatGLM2-6B\cli_demo.py", line 5, in <module>import readlineFile "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\readline.py", line 34, in <module>rl = Readline()File "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\pyreadline\rlmain.py", line 422, in __init__BaseReadline.__init__(self)File "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\pyreadline\rlmain.py", line 62, in __init__mode.init_editing_mode(None)File "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\pyreadline\modes\emacs.py", line 633, in init_editing_modeself._bind_key('space', self.self_insert)File "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\pyreadline\modes\basemode.py", line 162, in _bind_keyif not callable(func):File "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\pyreadline\py3k_compat.py", line 8, in callablereturn isinstance(x, collections.Callable)
AttributeError: module 'collections' has no attribute 'Callable'
解决方法
你的Python版本可能大于或等于3.10版本,因为 Python 3.10 版本将collections等一些属性放到了collections.abc子模块下。所以会出现collections’ has no attribute的错误。
如果你非要用Python的3.10及以上版本,也可以考虑找到最后报错的文件,一般是报错出现的最后一个文件。更改collections.attr 为 collections.abc.attr,attr 为报错中没有的属性。
charset_normalizer
根据错误消息,这个问题似乎与 charset_normalizer 库相关。
charset_normalizer 是一个用于字符集规范化的Python库,它可能是依赖于 transformers 和 huggingface_hub 的其中之一。
Traceback (most recent call last):File "D:\openai.wiki\ChatGLM2-6B\web_demo.py", line 1, in <module>from transformers import AutoModel, AutoTokenizerFile "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\transformers\__init__.py", line 26, in <module>from . import dependency_versions_checkFile "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\transformers\dependency_versions_check.py", line 17, in <module>from .utils.versions import require_version, require_version_coreFile "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\transformers\utils\__init__.py", line 30, in <module>from .generic import (File "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\transformers\utils\generic.py", line 29, in <module>from .import_utils import is_flax_available, is_tf_available, is_torch_available, is_torch_fx_proxyFile "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\transformers\utils\import_utils.py", line 33, in <module>from . import loggingFile "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\transformers\utils\logging.py", line 35, in <module>import huggingface_hub.utils as hf_hub_utilsFile "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\huggingface_hub\utils\__init__.py", line 32, in <module>from ._errors import (File "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\huggingface_hub\utils\_errors.py", line 3, in <module>from requests import HTTPError, ResponseFile "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\requests\__init__.py", line 45, in <module>from .exceptions import RequestsDependencyWarningFile "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\requests\exceptions.py", line 9, in <module>from .compat import JSONDecodeError as CompatJSONDecodeErrorFile "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\requests\compat.py", line 13, in <module>import charset_normalizer as chardetFile "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\charset_normalizer\__init__.py", line 23, in <module>from charset_normalizer.api import from_fp, from_path, from_bytes, normalizeFile "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\charset_normalizer\api.py", line 10, in <module>from charset_normalizer.md import mess_ratioFile "charset_normalizer\md.py", line 5, in <module>
ImportError: cannot import name 'COMMON_SAFE_ASCII_CHARACTERS' from 'charset_normalizer.constant' (D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\charset_normalizer\constant.py)
解决方式
确保您的环境中安装的 charset_normalizer 库是最新版本,您可以运行以下命令来更新库:
pip install --upgrade charset_normalizer
transformers_modules.THUDM/chatglm2-6b
该错误主要是因为模型路径的问题,并不是我们的模型路径有问题,而是源码中模型的加载路径遵从了Liunx的方式,但我们使用了Windows系统来搭建,这与Liunx的路径转义有区别,所以会看到如下报错内容:
(D:\openai.wiki\ChatGLM2-6B\ENV) D:\openai.wiki\ChatGLM2-6B>python web_demo.py
Traceback (most recent call last):File "D:\openai.wiki\ChatGLM2-6B\web_demo.py", line 5, in <module>tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)File "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\transformers\models\auto\tokenization_auto.py", line 676, in from_pretrainedtokenizer_class = get_class_from_dynamic_module(class_ref, pretrained_model_name_or_path, **kwargs)File "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\transformers\dynamic_module_utils.py", line 443, in get_class_from_dynamic_modulereturn get_class_in_module(class_name, final_module.replace(".py", ""))File "D:\openai.wiki\ChatGLM2-6B\ENV\lib\site-packages\transformers\dynamic_module_utils.py", line 164, in get_class_in_modulemodule = importlib.import_module(module_path)File "D:\openai.wiki\ChatGLM2-6B\ENV\lib\importlib\__init__.py", line 126, in import_modulereturn _bootstrap._gcd_import(name[level:], package, level)File "<frozen importlib._bootstrap>", line 1050, in _gcd_importFile "<frozen importlib._bootstrap>", line 1027, in _find_and_loadFile "<frozen importlib._bootstrap>", line 992, in _find_and_load_unlockedFile "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removedFile "<frozen importlib._bootstrap>", line 1050, in _gcd_importFile "<frozen importlib._bootstrap>", line 1027, in _find_and_loadFile "<frozen importlib._bootstrap>", line 1004, in _find_and_load_unlocked
ModuleNotFoundError: No module named 'transformers_modules.THUDM/chatglm2-6b'
解决方式
将源码中只要包含THUDM/chatglm2-6b的部分,全部修改成THUDM\chatglm2-6b即可。
参考链接
https://blog.csdn.net/fengxiaoyangfeng/article/details/131617214
https://flowus.cn/specialone/share/32ea2887-bac4-4f46-b2ea-97b9faa001de
https://openai.wiki/chatglm-6b.html#%E9%83%A8%E7%BD%B2%E6%95%99%E7%A8%8B
https://openai.wiki/chatglm2-6b.html#nomodulenamed%E2%80%98readline%E2%80%99
![[VScode] 嵌入式软件开发必备插件](https://img-blog.csdnimg.cn/20210620100734264.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzI5MjQ2MTgx,size_16,color_FFFFFF,t_70)