直接开始
有一张表:trade_user,表结构如下:
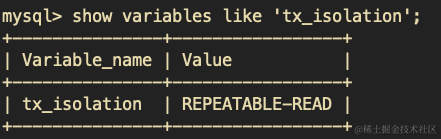
mysql> desc trade_user;
+------------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+------------------+------+-----+---------+----------------+
| id | bigint unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | MUL | NULL | |
| email | longtext | YES | | NULL | |
| age | tinyint unsigned | YES | | NULL | |
| birthday | datetime | YES | | NULL | |
| created_at | datetime | YES | | NULL | |
| updated_at | datetime | YES | | NULL | |
| id_no | char(18) | NO | | | |
+------------+------------------+------+-----+---------+----------------+
8 rows in set (0.02 sec)
COPY
表行数
mysql> select count(*) from trade_user;
+----------+
| count(*) |
+----------+
| 3536655 |
+----------+
1 row in set (0.60 sec)
COPY
无索引limit n offset m
OFFSET 0:limit 10 offset 0
select * from trade_user order by email limit 10 offset 0;COPY
执行耗时:1.41 秒
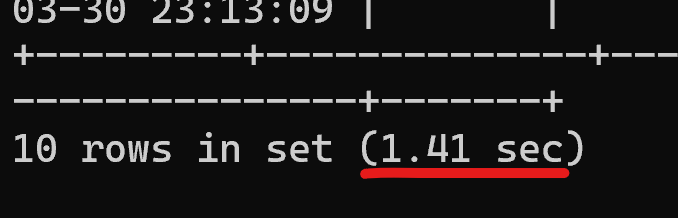
OFFSET 1万: limit 10 offset 10000
select * from trade_user order by email limit 10 offset 10000;
COPY
执行耗时: 1.68秒
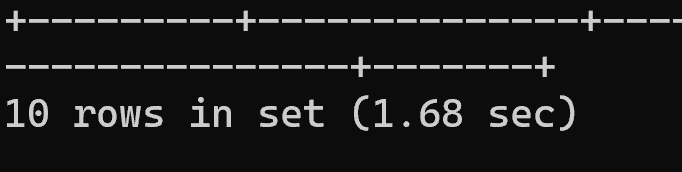
OFFSET:10万:limit 10 offfet 100000
select * from trade_user order by email limit 10 offset 100000;
COPY
执行耗时:1.89秒
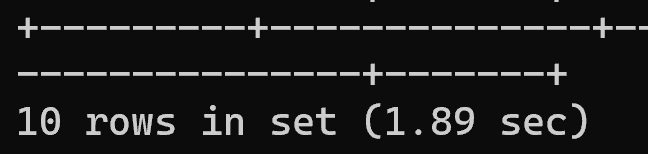
OFFSET:100万:limit 10 offset 1000000
select * from trade_user order by email limit 10 offset 1000000;
COPY
执行耗时:4.06秒
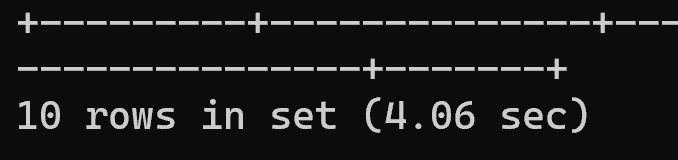
OFFSET:200万:limit 10 offset 2000000
select * from trade_user order by email limit 10 offset 2000000;
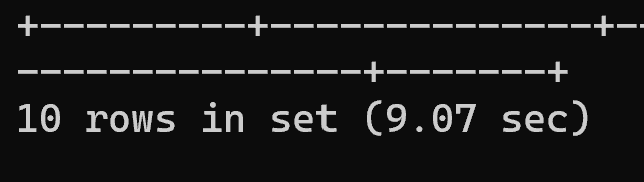
COPY
执行耗时:9.07秒
有索引limit n offset m
trade_user表的name列有一个普通索引。
OFFSET 0:limit 10 offset 0
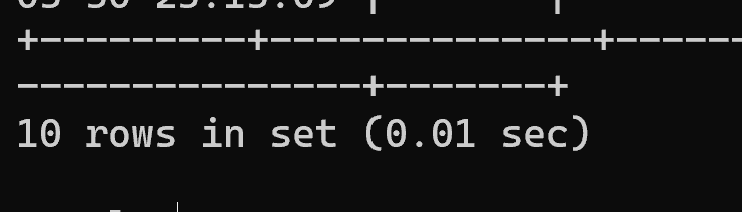
select * from trade_user order by name limit 10 offset 0;COPY
执行耗时:0.01 秒
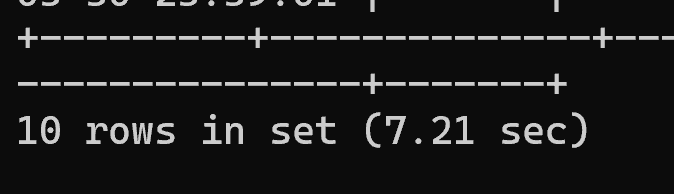
OFFSET 200万:limit 10 offset 2000000
select * from trade_user order by name limit 10 offset 2000000;COPY
执行耗时:7.21 秒
为什么?
OFFSET越大,MySQL扫描行数越多:
+----+-------------+------------+------------+------+---------------+------+---------+------+---------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+------+---------+------+---------+----------+----------------+
| 1 | SIMPLE | trade_user | NULL | ALL | NULL | NULL | NULL | NULL | 3447992 | 100.00 | Using filesort |
+----+-------------+------------+------------+------+---------------+------+---------+------+---------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
COPY
| EXPLAIN| -> Limit/Offset: 10/2000000 row(s) (cost=359470 rows=10) (actual time=8737..8737 rows=10 loops=1)-> Sort row IDs: trade_user.`name`, limit input to 2000010 row(s) per chunk (cost=359470 rows=3.45e+6) (actual time=2552..8699 rows=2e+6 loops=1)-> Table scan on trade_user (cost=359470 rows=3.45e+6) (actual time=0.0247..1870 rows=3.54e+6 loops=1)|
1 row in set (8.74 sec)
COPY
总结
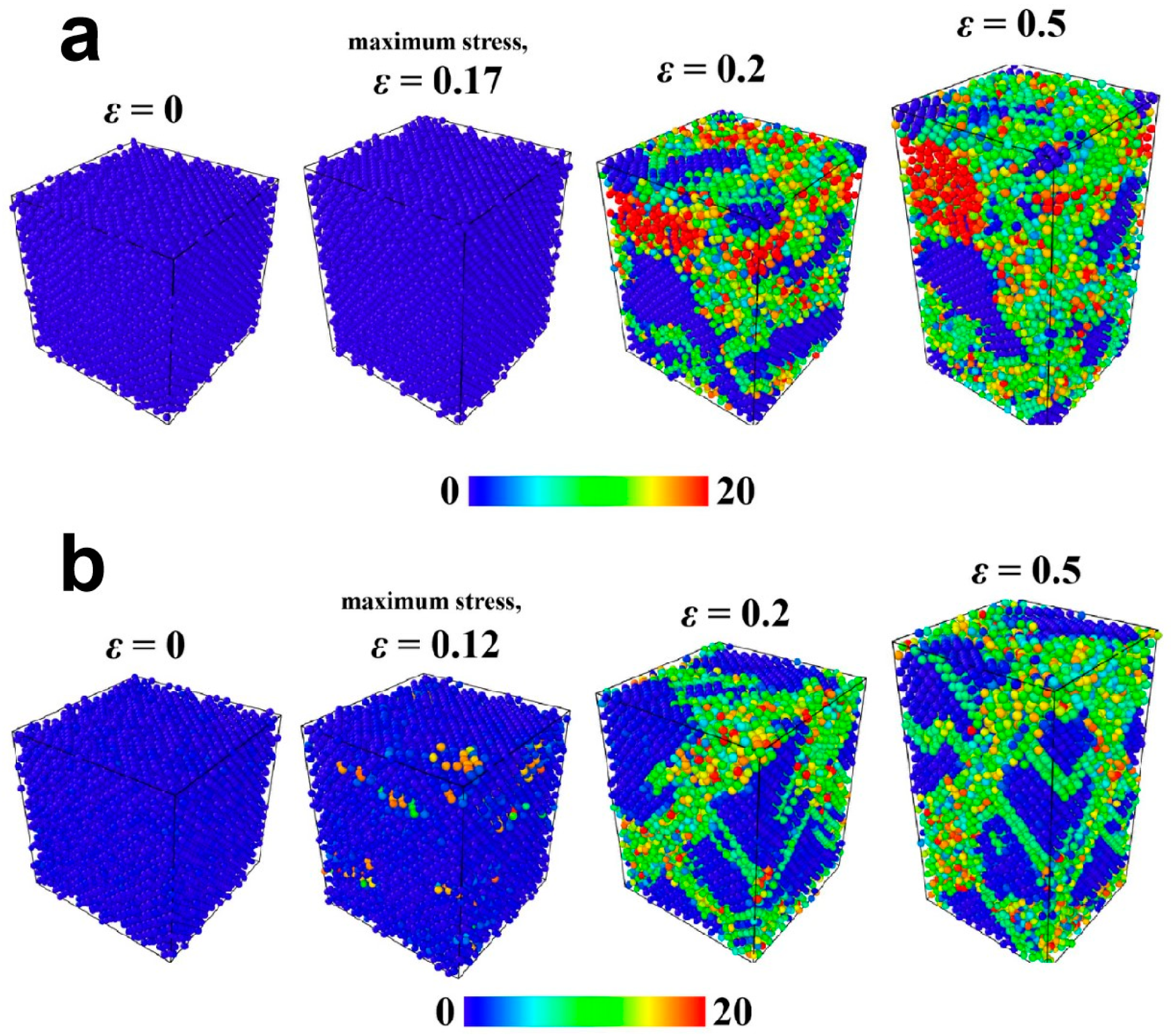
在对大表进行 LIMIT 和 OFFSET 操作时,随着偏移量(OFFSET)的增加,性能会显著下降。由于 MySQL 必须首先跳过 OFFSET 之前的所有行,才能获取到 LIMIT 指定的数据量,因此当 OFFSET 值较大时,这会导致显著的性能开销,尤其是在没有对排序列添加索引的情况下。通过性能测试得出,即使 LIMIT 的值相同,越大的 OFFSET 会使 MySQL 扫描的行数越多,因此执行时间越长。
性能测试的总结如下:
- 当没有索引支持
ORDER BY子句时,即使是小范围的LIMIT查询,随着OFFSET的增加,查询性能会急剧下降。从测试结果来看,相同的LIMIT值下,OFFSET值为 0 时查询耗时为 1.41 秒,而OFFSET值为 200 万时耗时增加到了 9.07 秒。 - 当存在索引支持
ORDER BY子句时,查询性能显著提升,OFFSET为 0 时耗时只需 0.01 秒。这表明,有索引的情况下,小OFFSET值查询的性能提升非常明显。但即使有索引支持,大OFFSET值仍然会导致较高的性能开销,如OFFSET值为 200 万时耗时为 7.21 秒。 - 测试中观察到的性能差异主要是由于 MySQL 在未使用索引的情况下需要对所有数据进行全表扫描,并使用文件排序来找到
ORDER BY子句中指定的顺序,然后才能跳过OFFSET指定的行。
为了优化大表的 LIMIT 和 OFFSET 查询:
- 避免使用大的
OFFSET值,特别是在没有对ORDER BY的字段进行索引优化的情况下。 - 考虑使用 "keyset pagination" 或 "seek method" 方法,即通过跟踪上一次检索的最后一个记录的标识,来避免使用
OFFSET。 - 确保
ORDER BY中的列上有适当的索引以提高排序和检索效率。 - 尽量减少查询结果中的列数,只取需要的列。
- 如果有可能,调整应用逻辑以减少数据量,或将常用查询结果进行缓存。
大表不用使用大OFFSET。
参考
MySQL limit N offset M 速度慢?来实际体验下 – 小厂程序员