def calculate_similarity(model, image_1, image_2, draw=False):image_1_pil = Image.fromarray(image_1)image_2_pil = Image.fromarray(image_2)probability = model.detect_image(image_1_pil, image_2_pil, draw)'''每次跑完显存代码都释放显存'''torch.cuda.empty_cache()return probability
当我写了一个多线程代码,但是没有释放显存的习惯时:
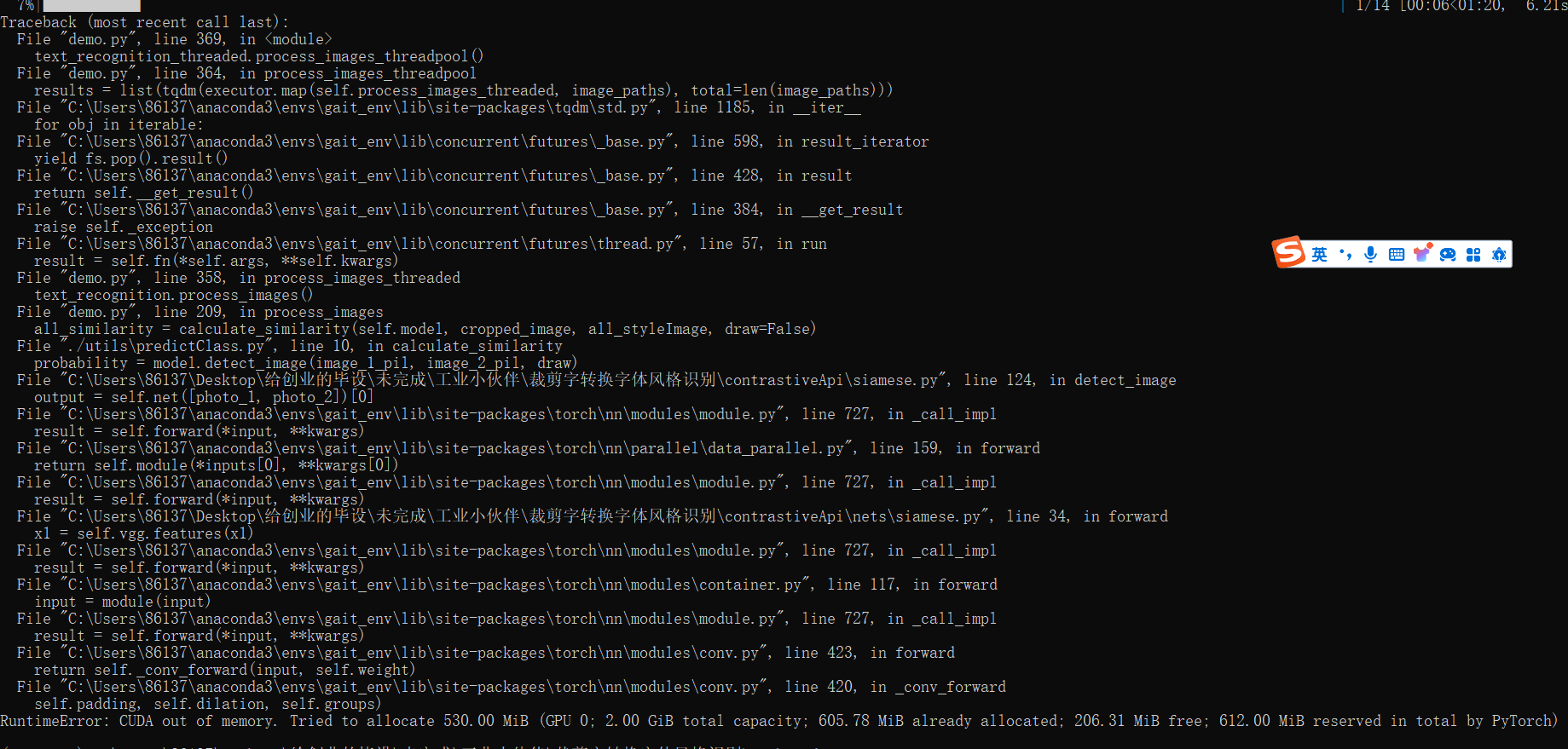
疯狂的爆OOM,
RuntimeError: CUDA out of memory. Tried to allocate 530.00 MiB (GPU 0; 2.00 GiB total capacity; 605.78 MiB already allocated; 206.31 MiB free; 612.00 MiB reserved in total by PyTorch)
非常的痛苦,
那么我们如何释放显存呢?
1. 把需要使用显存的代码,也就是需要调用CUDA的代码,打包为一个函数。
2.在函数的结尾加上。
'''
torch.cuda.empty_cache()`是PyTorch提供的函数,
用于清空当前GPU上的缓存。在深度学习模型训练过程中,
GPU显存可能会被一些中间结果占用而没有及时释放,
导致显存不足的问题。调用torch.cuda.empty_cache()可以手动清理这些未释放的显存,
确保GPU显存能够被有效地管理和利用。
这个函数通常在模型训练的迭代过程中的适当时机调用,
以避免显存占用过高而导致程序崩溃。
'''
torch.cuda.empty_cache()torch.cuda.empty_cache()`是PyTorch提供的函数,用于清空当前GPU上的缓存。在深度学习模型训练过程中,GPU显存可能会被一些中间结果占用而没有及时释放,导致显存不足的问题。调用torch.cuda.empty_cache()可以手动清理这些未释放的显存,确保GPU显存能够被有效地管理和利用。这个函数通常在模型训练的迭代过程中的适当时机调用,以避免显存占用过高而导致程序崩溃。