微服务熔断概述
- go 微服务保稳三剑客: 熔断,限流,负载均衡
- 微服务熔断(hystrix-go) 与 服务雪崩效应
- 在服务里面,有服务A调用服务B, 会有依赖调用关系,同时服务C被B依赖
- 如果依赖关系在生产环境中多的话,C挂了之后
- 服务B原本正常,也会因为C导致不正常
- 同时,A因为依赖B导致A也出了问题
- 这时候,会级联反应,就是服务雪崩效应,如下图

- 微服务熔断 (hystrix-go) 目标
- 组织故障的连锁反应
- 快速失败并迅速恢复
- 它会走一个熔断的逻辑
- 回退并优雅降级
- 对出问题的微服务进行回退和降级
- 提供近实时的监控与告警
微服务熔断 (hystrix-go) 使用原则
- 防止任何单独的依赖耗尽资源(线程)
- 过载立即切断并快速失败,防止排队
- 尽可能提供回退来保护用户免受故障
- 通过近实时的指标,监控和告警,确保故障被及时发现
微服务熔断 (hystrix-go) 的请求原理

- 从开始,紫色箭头是正常状态下的流转
- command 可以有多个
- 第一步判断,熔断是否开启,是否开启的判断是通过 计数器
- 计数器这块 它会有一个信息的收集,黄色箭头是信息的上报
- 上报到计数器时,计数器会根据它的业务逻辑判断熔断是否开启
- 第一步判断熔断是否开启会依赖计数器给出的最终结果
- 如果熔断没有开启,即:否,需要判断熔断是否超过并发,计数器上会设置并发值
- 超过并发,走callback逻辑,如果没超过走程序逻辑
- 程序逻辑调用判断是否执行成功,如果执行成功,会鸡儿判断是否执行超时
- 这些:是否否执行成功,是否超时,是否超过并发,这些都会把信息进行上报
- 上报到计数器里面,当流程上的判断都是成功的时候,紫色箭头就是正常状态
- 如果有异常,都会执行 callback, 这就是熔断器整个调用过程的整体架构
微服务熔断 (hystrix-go) 的熔断器状态
closed关闭状态: 允许流量通过open打开状态: 不允许流量通过,即处于降级状态,走降级逻辑half_open半开状态,允许某些流量通过,如果出现超时,异常等情况- 将进入
open状态,如果成功,那么将进入closed状态
微服务熔断 (hystrix-go) 的重要字段
Timeout: 执行command的超时时间,默认时间是 1000 毫秒MaxConcurrentRequests: 最大并发量,默认值是 10SleepWindow: 熔断打开后多久进行再次尝试,默认值 5000 毫秒RequestVolumeThreshold: 10s 内的请求量,默认值20,判断是否熔断ErrorPercentThreshold: 熔断百分比,默认值50%, 超过启动熔断- 主要是这5个重要的参数
微服务熔断 (hystrix-go) 的熔断计数器
- 每个 Command 都会有一个默认统计控制器
- 默认的统计控制器 DefaultMetricCollector
- 保存熔断器的所有状态,调用次数,失败次数,被拒绝次数等信息
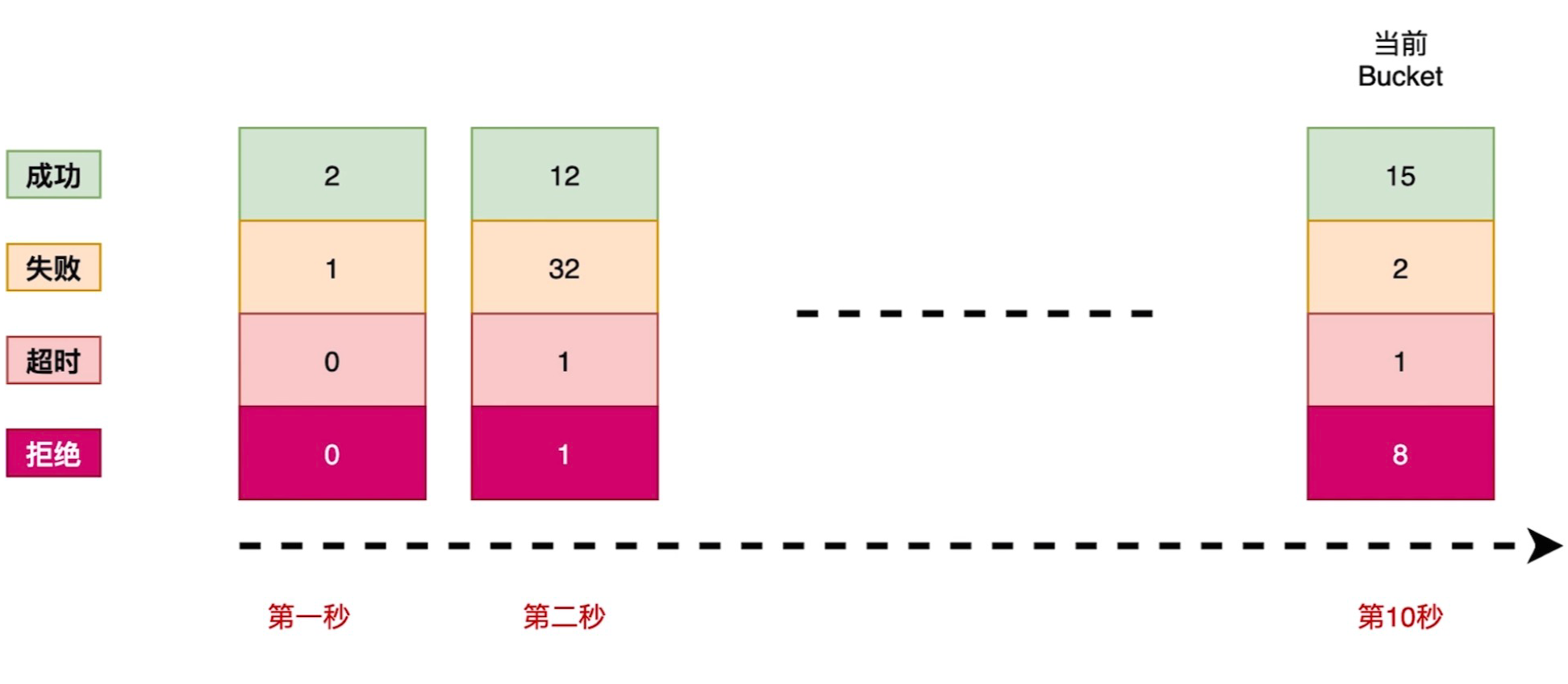
- 在10s的窗口中,有上述一个图
- 有4个状态:成功,失败,超时,拒绝
- 在每一秒的窗口中,熔断记录的状态,各个状态产生的计数
- 当超过10s, 第一个会被销毁,后面会再添加一个,始终保持10个
- 这个是计数的原理,有的是根据10s内的平均值进行判断的
- 以上是它的实现方式
微服务熔断 (hystrix-go) 的熔断-上报状态信息原理
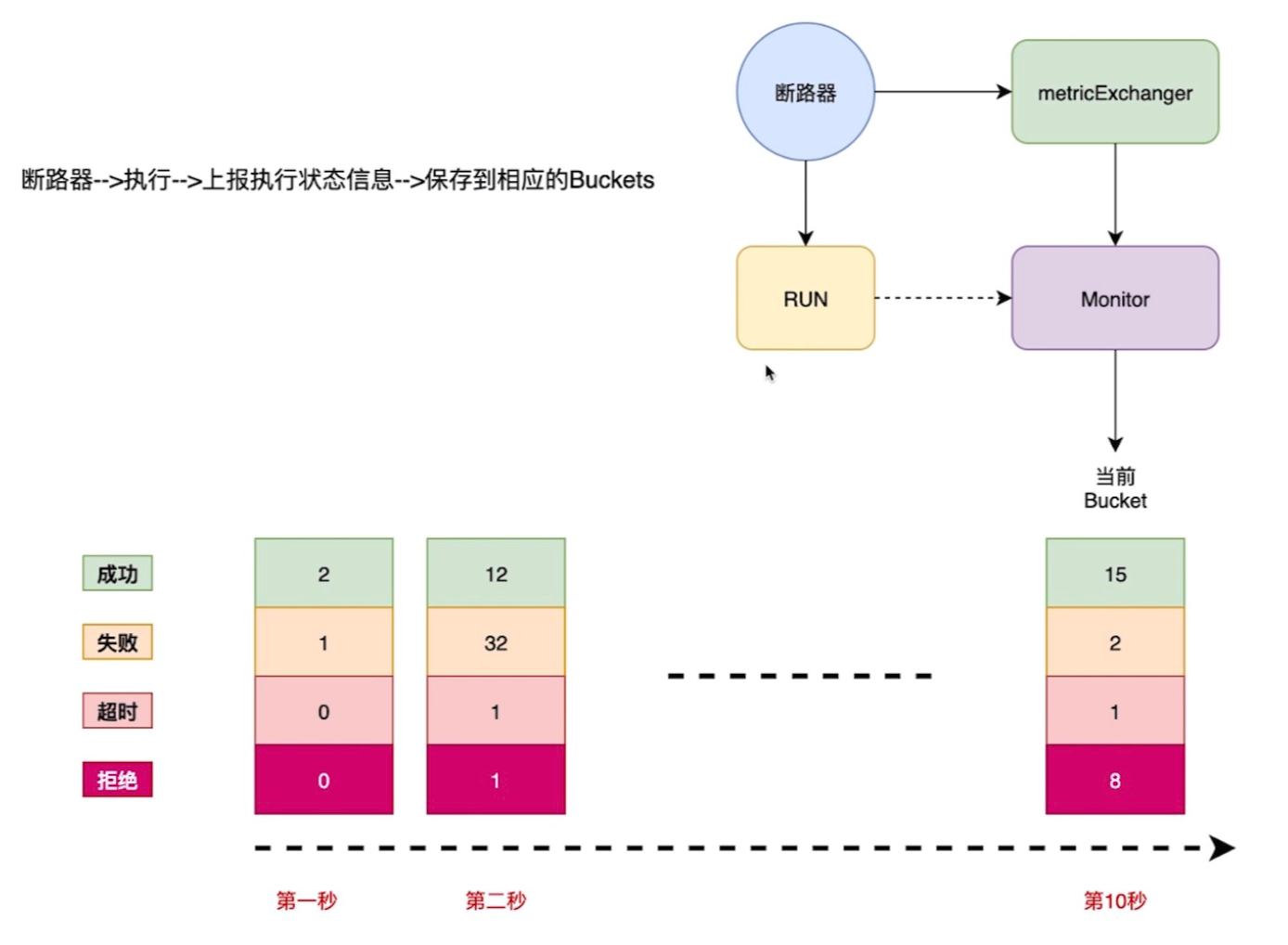
- 信息上传就是通过断路器, 断路器执行完就上报信息
- 上报信息之后就写入熔断器,写入的过程,就是每一秒建立一个bucket
- 时间窗口默认是10s, 在这个时间内记录请求的状态
- 根据这些请求的状态判断熔断是否开启
- 熔断计数器主要是信息的上报,把每一秒的信息中统计成功,失败,超时和拒绝的状态
- 记录完了之后,当你查询熔断是否需要开启时,它是根据这些信息进行判断的
- 这个熔断器主要是这样的一个原理
微服务熔断 (hystrix-go) 的观测面板的安装
- $
docker pull mlabouardy/hystrix-dashboard:latest - $
docker run --name hystrix-dashboard -d -p 9002:9002 mlabouardy/hystrix-dashboard:latest - 访问: http://localhost:9002/hystrix 到控制面板UI界面