主要内容
- 分布式文件系统HDFS
一.HDFS
1.数据错误与恢复
HDFS具有较高的容错性,可以兼容廉价的硬件,它把硬件出错看作一种常态,而不是异常,并设计了相应的机制检测数据错误和进行自动恢复,主要包括以下几种情形:名称节点出错、数据节点出错和数据出错。
2.名称节点出错
名称节点保存了所有的元数据信息,其中,最核心的两大数据结构是FsImage和Editlog,如果这两个文件发生损坏,那么整个HDFS实例将失效。因此,HDFS设置了备份机制,把这些核心文件同步复制到备份服务器SecondaryNameNode上。当名称节点出错时,就可以根据备份服务器SecondaryNameNode中的FsImage和Editlog数据进行恢复。
3.数据节点出错
- 每个数据节点会定期向名称节点发送“心跳”信息,向名称节点报告自己的状态
- 当数据节点发生故障,或者网络发生断网时,名称节点就无法收到来自一些数据节点的心跳信息,这时,这些数据节点就会被标记为“宕机”,节点上面的所有数据都会被标记为“不可读”,名称节点不会再给它们发送任何I/O请求
- 这时,有可能出现一种情形,即由于一些数据节点的不可用,会导致一些数据块的副本数量小于冗余因子;名称节点会定期检查这种情况,一旦发现就会启动数据冗余复制,为它生成新的副本
4.数据出错
- 网络传输和磁盘错误等因素,都会造成数据错误
- 客户端在读取到数据后,会采用md5和sha1对数据块进行校验,以确定读取到正确的数据
- 在文件被创建时,客户端就会对每一个文件块进行信息摘录,并把这些信息写入到同一个路径的隐藏文件里面
- 当客户端读取文件的时候,会先读取该信息文件,然后,利用该信息文件对每个读取的数据块进行校验,如果校验出错,客户端就会请求到另外一个数据节点读取该文件块,并且向名称节点报告这个文件块有错误,名称节点会定期检查并且重新复制这个块
5.HDFS读写过程
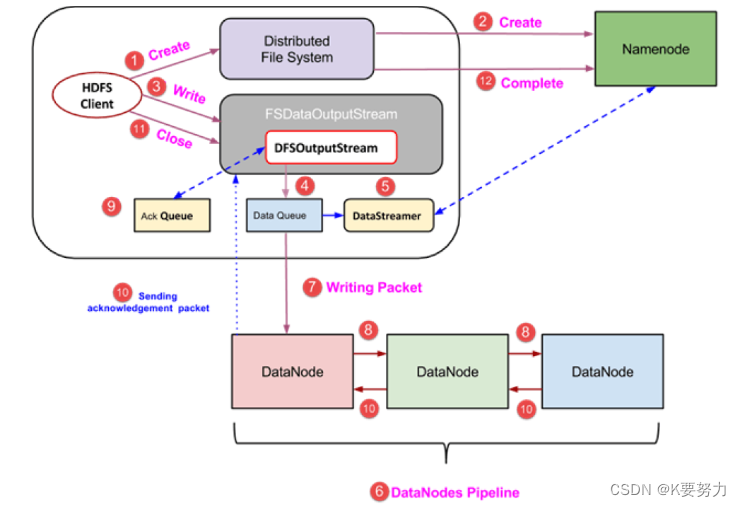
- FileSystem是一个通用文件系统的抽象基类,可以被分布式文件系统继承,所有可能使用Hadoop文件系统的代码,都要使用这个类
- Hadoop为FileSystem这个抽象类提供了多种具体实现
- DistributedFileSystem就是FileSystem在HDFS文件系统中的具体实现
- FileSystem的open()方法返回的是一个输入流FSDataInputStream对象,在HDFS文件系统中,具体的输入流就是DFSInputStream;FileSystem
中的create()方法返回的是一个输出流FSDataOutputStream对象,在HDFS文件系统中,具体的输出流就是DFSOutputStream。
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
FSDataInputStream in = fs.open(new Path(uri));
FSDataOutputStream out = fs.create(new Path(uri));
6.写操作
-
场景:一个文件200MB,客户端需要将该文件写到HDFS上。 HDFS配置:HDFS分布在三个机架Rack1,Rack2和Rack3。
-
写入配置:文件被分成128MB和72MB的两个数据块,复制三份
-
第一步 客户端将该文件分成128MB和72MB的两个Block,block1和block2
-
第二步
客户端向Namenode发送数据写入请求,点虚线1, Namenode节点记录数据节点信息,并且返回可用的Datanode,点虚线2
Block1: DN1 DN3 DN4
Block2:DN5 DN7 DN8
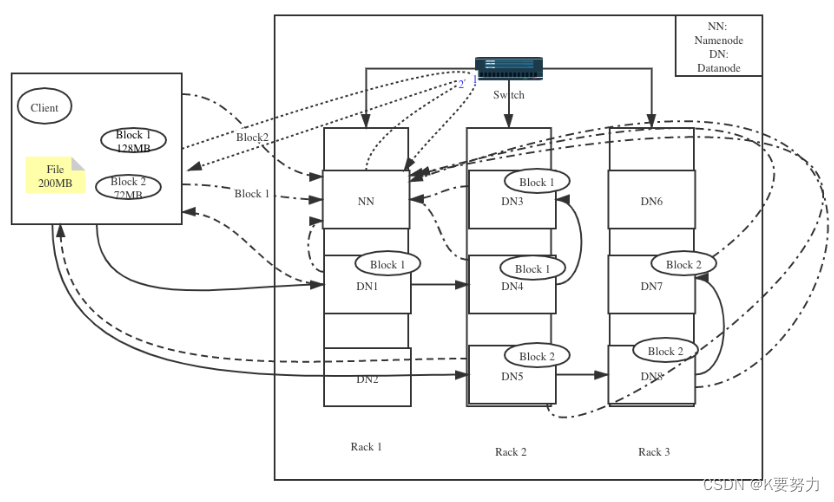
- 第三步
- 1.客户端向Datanode发送block1,发送过程是流式写入,将128MB的block按照64k的传输包划分
- 2.将第一个传输包发送个DN1,DN1接受完第一个传输包后,将该传输包发送给DN4,同时客户端向DN1发送第二个传输包
3.DN4接收完第一传输包后,向DN3传送第一个传输包,同时接收从DN1发来的第二个传输包
4.以此重复,直至block1发送完毕。(数据传输是实线)
5.DN1,DN4,DN3向Namenode发送消息,DN1向客户端发送消息,说明block1已经传输完毕
6.客户端收到DN1的消息后,向Namenode发送消息,说明block1已经写完了。到此为止,block1正式写完
7.依照以上原理,将block2 写入DN5,DN8,DN7,写完后,DN5,DN8,DN7告诉Namenode已经写完DN5告诉客户端已经写入完毕
8.客户端会告诉Namenode,已经写完block2,至此整个文件已经写入完毕
7.读操作
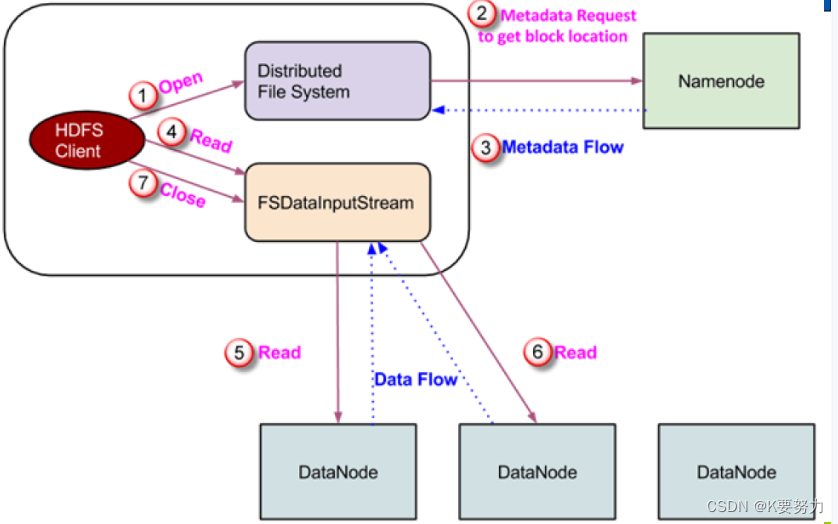
- 第一步
客户端向Namenode发送读请求 - 第二步 Namenode查看元数据信息,返回文件block的位置
Block1: DN1 DN3 DN4
Block2: DN5 DN7 DN8 - 第三步 Block的位置是有先后顺序的,先读block1,再读block2.
- 读取的条件是:先从本机架的Datanode上进行数据的读取,如果本机架上没有数据,则从就近的机架中的Datanode中读取数据

8.读写数据过程
-
读数据过程
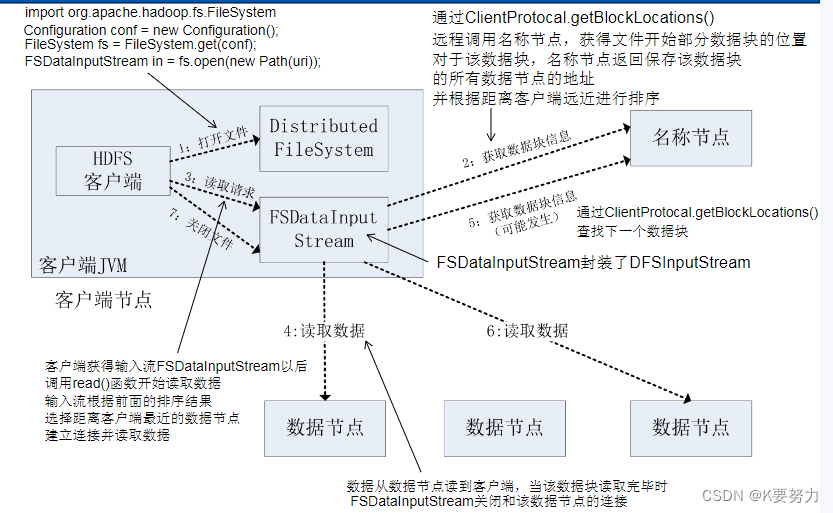
-
写数据过程

总结
以上是今天要讲的内容,学到了分布式文件系HDFS相关操作。