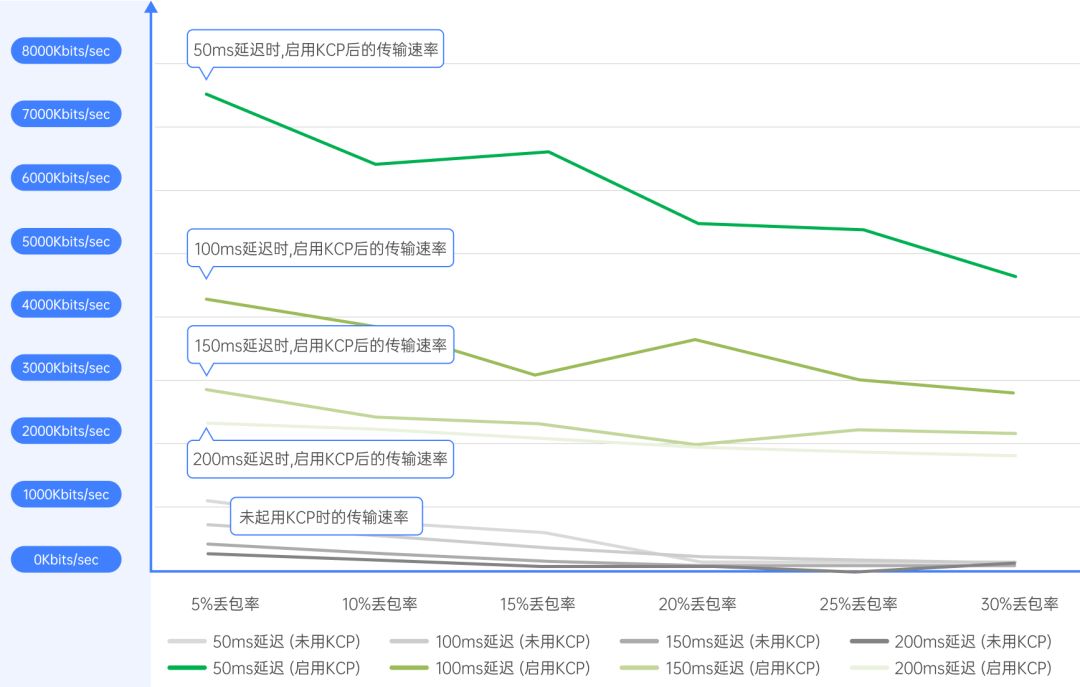
1、处理器QueryDatabaseTable,该组件生成一个 SQL 查询,或者使用用户提供的语句,并执行它以获取所有在指定的最大值列中值大于先前所见最大值的行。查询结果将被转换为 Avro 格式,如下图所示:

本示例通过QueryDatabaseTable处理器连接数据库查询表数据,然后连接到LogMessage打印日志消息。
2、处理器QueryDatabaseTable属性配置,如下图所示:
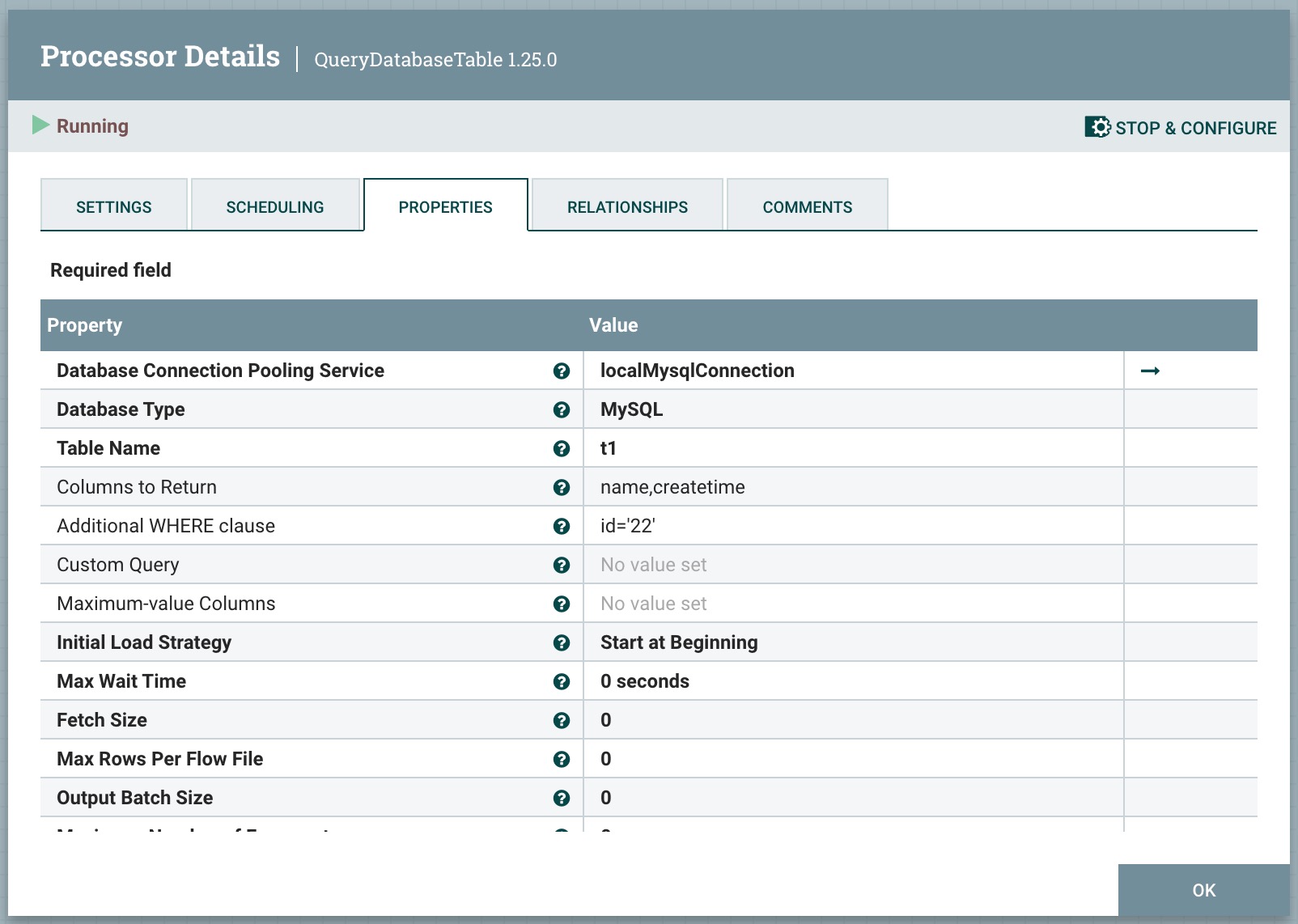
Database Connection Pooling Service:设置数据库连接信息,如设置ip,端口,用户名,密码等。
Database Type:设置数据库类型,有如下选项Generic 、Oracle 、Oracle 12+ 、MS SQL 2012+ 、MS SQL 2008 、MySQL 、PostgreSQL 、Phoenix 。本次演示采用mysql。
Table Name:设置表名,这里设置为t1。
Columns to Return:一个逗号分隔的列名列表,用于在查询中使用。如果您的数据库对这些名称需要特殊处理(例如引号),每个名称都应包括此处理方式。如果未提供列名,则将返回指定表中的所有列。
Additional WHERE clause:构建 SQL 查询时要添加到 WHERE 条件中的自定义子句。
Custom Query:自定义查询语句,如select * from t1 where id='22';
Maximum-value Columns:一个逗号分隔的列名列表。处理器将跟踪自处理器启动以来返回的每个列的最大值。使用多个列意味着对列列表有一个顺序,并且预期每个列的值增长速度比前一个列的值慢。因此,使用多个列意味着列的分层结构,通常用于分区表。此处理器可用于仅检索自上次检索以来已添加/更新的行。请注意,一些 JDBC 类型,如 bit/boolean,并不利于维护最大值,因此不应在此属性中列出这些类型的列,并且在处理过程中会导致错误。如果未提供列,则将考虑来自表的所有行,这可能会影响性能。注意:为了使增量获取正常工作,对于给定表格,使用一致的最大值列名非常重要。
Initial Load Strategy:
Max Wait Time:运行中的 SQL 查询所允许的最长时间,零表示没有限制。小于1秒的最长时间将等同于零。
Fetch Size:每次从结果集中获取的结果行数。这是对数据库驱动程序的提示,可能不会被采纳和/或精确执行。如果指定的值为零,则提示将被忽略。
Max Rows Per Flow File:单个FlowFile中将包含的最大结果行数。这将允许您将非常大的结果集分成多个FlowFiles。如果指定的值为零,则所有行都将在单个FlowFile中返回。
Output Batch Size:在提交处理会话之前排队的输出FlowFiles的数量。当设置为零时,会话将在所有结果集行都已处理并且输出FlowFiles准备好传输到下游关系时提交。对于大型结果集,这可能会导致在处理器执行结束时传输大量的FlowFiles。如果设置了此属性,则当指定数量的FlowFiles准备好传输时,会话将被提交,从而释放FlowFiles到下游关系。注意:当设置此属性时,FlowFiles上将不设置maxvalue.*和fragment.count属性。

Maximum Number of Fragments:最大碎片数量。如果指定的值为零,则返回所有碎片。当此处理器摄取大型表格时,这可以防止OutOfMemoryError。注意:设置此属性可能会导致数据丢失,因为传入的结果未排序,并且碎片可能在不包含在结果集中的行的任意边界结束。
Normalize Table/Column Names:是否将列名中的非Avro兼容字符更改为Avro兼容字符。例如,冒号和句点将被更改为下划线,以构建有效的Avro记录,有true和false两个选项。
Transaction Isolation Level:此设置将为支持此设置的驱动程序设置数据库连接的事务隔离级别。
Use Avro Logical Types:是否使用 Avro 逻辑类型来处理 DECIMAL/NUMBER、DATE、TIME 和 TIMESTAMP 列。如果禁用,则写入为字符串。如果启用,则使用逻辑类型并按其底层类型写入,具体来说,DECIMAL/NUMBER 作为逻辑 ‘decimal’:按字节写入,并附加精度和比例元数据,DATE 作为逻辑 ‘date-millis’:按整数写入,表示自 Unix 纪元(1970-01-01)以来的天数,TIME 作为逻辑 ‘time-millis’:按整数写入,表示自 Unix 纪元以来的毫秒数,以及 TIMESTAMP 作为逻辑 ‘timestamp-millis’:按长整数写入,表示自 Unix 纪元以来的毫秒数。如果写入的 Avro 记录的读取器也了解这些逻辑类型,那么根据读取器实现的不同上下文,这些值可以以更多的上下文进行反序列化。
Default Decimal Precision:当 DECIMAL/NUMBER 值被写入为 ‘decimal’ Avro 逻辑类型时,需要指定表示可用数字的数量的特定 ‘precision’。通常,精度由列数据类型定义或数据库引擎默认值定义。然而,一些数据库引擎可能会返回未定义的精度(0)。在写入这些未定义精度的数字时,将使用“默认十进制精度”。
Default Decimal Scale:当 DECIMAL/NUMBER 值被写入为 ‘decimal’ Avro 逻辑类型时,需要指定表示可用小数位数的特定 ‘scale’。通常,scale 由列数据类型定义或数据库引擎默认值定义。然而,当返回未定义的精度(0)时,在某些数据库引擎中,scale 也可能不确定。在写入这些未定义数字时,将使用“默认十进制 scale”。如果一个值的小数位数超过指定的 scale,则该值将四舍五入,例如,scale 为 0 时,1.53 变为 2,scale 为 1 时,1.5。
3、控制器服务,配置数据库连接,点击Database Connection Pooling Service 属性对应的值,选择Create new service,如下图所示:
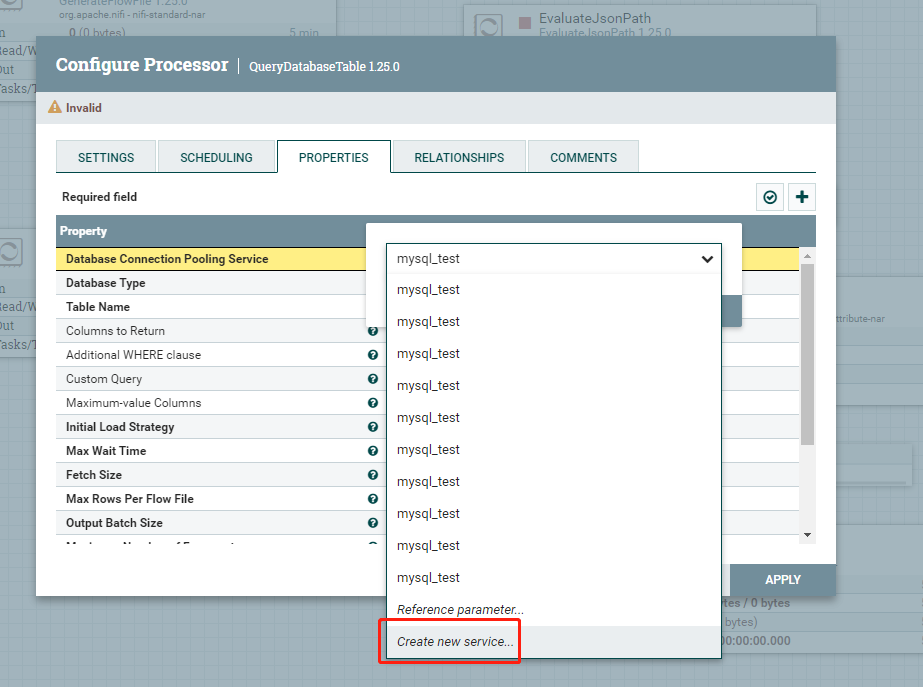
选择合适的Compatible Controller Services,自定义Controller Service Name,如下图所示。

下种中的齿轮可以进行设置数据库连接信息,闪电标记可以启用和禁用。

点击齿轮进行配置数据库连接信息,填写主要信息Database Connection Url、Database Driver Class Name,Database user和Password,如下图所示:

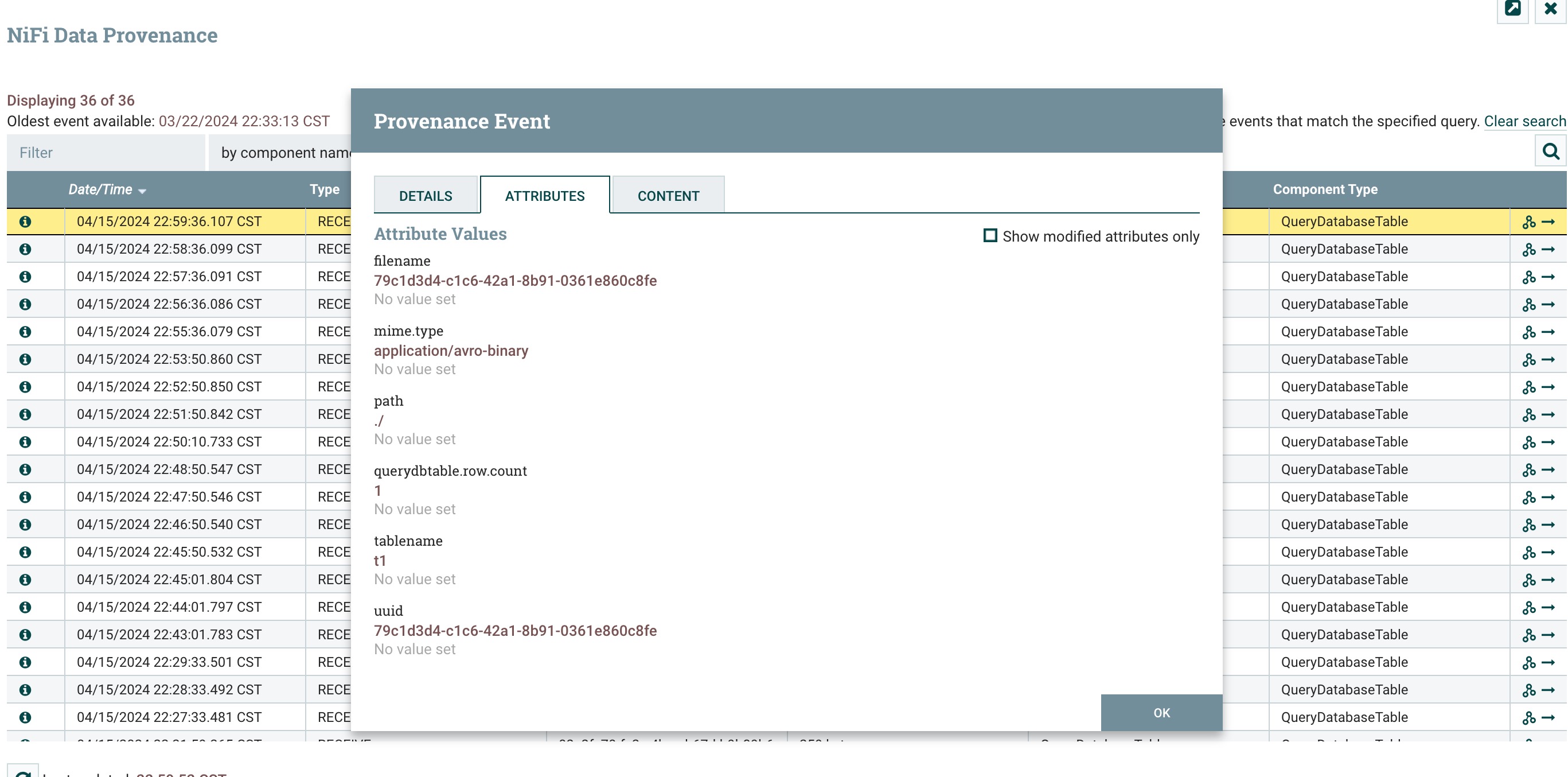
4、点击运行,然后查看数据溯源信息,attributes 中多了tablename、querydbtable.row.count、mime.type属性如下图所示:
点击content选项卡,可以看到flowfile的content,点击view进行查看数据,如下图所示:

点击view查看数据,默认orginal格式为avro二进制数据所以会有中文乱码的情况,此处乱码不影响,忽略即可,如下图所示:

选择formatted,输出json格式的数据,如下图所示: