目录
一、 Docker网络
(一)Docker网络实现原理
(二)Docker网络模式
1. Bridge网络(默认)
2. Host网络
3. None网络
4. Container网络
5. 自定义网络
二、资源控制
(一)cgroup 介绍
(二)CPU限制
1.CPU限制(绝对配额)
2.CPU份额(相对权重)
3.CPU亲和性(CPU绑定)
(三)内存限制
1.内存限制设置
2.交换内存限制
(四)磁盘IO配额控制的限制
三、数据管理
(一)数据卷
(二)数据卷容器
四、容器互联
五、Docker镜像的创建
(一)基于现有镜像创建
(二)基于本地模板创建
(三)基于Dockerfile 创建
1. 什么是Dockerfile
2.为什么要使用Dockerfile
3.镜像加载原理
4.Docker工作原理
5.Docker 镜像结构的分层
6.Dokcerfile指令
7.用Dockerfile文件生成镜像
在当今快速发展的云计算时代,Docker作为容器化技术的领航者,凭借其轻量级、可移植的特性,已经成为软件开发与部署的重要工具
一、 Docker网络
(一)Docker网络实现原理
网络命名空间
每个Docker容器在启动时都会被赋予一个新的网络命名空间,这样每个容器都有其独立的网络栈,包括网络设备、路由表、防火墙规则等,从而实现了容器间的网络隔离。
虚拟网络设备
Docker 使用veth pair技术来建立容器与宿主机或者其他容器的网络连接。veth pair是一对虚拟网络接口设备,它们互相连接,一端放在容器的网络命名空间,另一端放在宿主机或其他容器的网络命名空间,形成一条跨越命名空间的网络通道。
网桥(Bridge)
Docker默认创建了一个名为docker0的网桥,新创建的容器如果不指定网络模式,默认会加入到这个网桥上。容器的veth接口一端会被添加到网桥上,使得容器能够通过这个网桥与其他容器或者宿主机上的进程通信。
IP地址分配
Docker守护进程(Docker daemon)负责为每个容器分配IP地址,并配置相关的网络参数。这些IP地址通常来自于一个预定义的子网段。
iptables和NAT
Docker使用iptables规则来管理容器与宿主机、容器与容器之间、以及容器与外界网络的通信。
对于外部网络访问容器,Docker会设置DNAT规则,将目标为宿主机IP的数据包重定向至相应容器的IP地址。
对于容器访问外部网络,Docker会设置SNAT规则,将容器发出的数据包的源IP地址转换为宿主机IP,以便数据包能正确路由回容器。
网络模式
Docker支持多种网络模式,除了默认的bridge模式,还有none(没有网络)、host(共享宿主机网络栈)等模式。每种模式对应不同的网络配置方式。
(二)Docker网络模式
Docker提供了多种网络模式,以适应不同场景下的网络需求,确保容器间及容器与外界的高效通信,同时保持必要的隔离性。
在安装好docker后,它会自动创建三个网络
可以使用 docker network ls 或 docker network list 查看docker网络列表

#使用docker run创建Docker容器时,可以用 --net 或 --network 选项指定容器的网络模式
host模式:使用 --net=host 指定。
none模式:使用 --net=none 指定。
container模式:使用 --net=container:NAME_or_ID 指定。
bridge模式:使用 --net=bridge 指定,默认设置,可省略。
1. Bridge网络(默认)
Docker默认为每个容器创建一个桥接网络。这种模式下,容器通过虚拟网桥(如docker0)与宿主机相连,每个容器都有独立的IP地址,既实现了网络隔离,又方便容器间的通信。通过端口映射,容器服务可以被宿主机乃至外部网络访问。
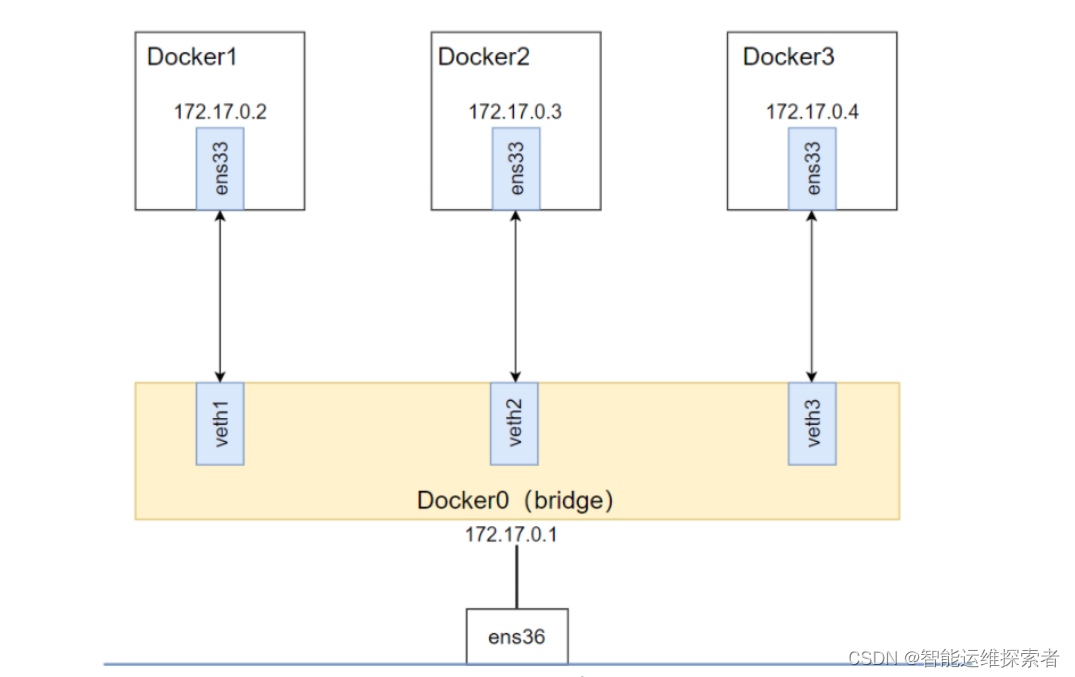
(1)当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。
(2)从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备。veth设备总是成对出现的,它们组成了一个数据的通道,数据从一个设备进入,就会从另一个设备出来。因此,veth设备常用来连接两个网络设备。
(3)Docker将 veth pair 设备的一端放在新创建的容器中,并命名为 eth0(容器的网卡),另一端放在主机中, 以 * 这样类似的名字命名,并将这个网络设备加入到 docker0 网桥中。可以通过 brctl show 命令查看。veth
(4)使用 docker run -p 时,docker实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL 查看。
通过 --network=bridge命令实现,但因为是默认选项,所以可以省略
docker run -d --name 容器名称 -P 镜像名称 #随机映射端口(从32768开始)docker run -d --name 容器名称 -p 指定端口:容器服务端口 nginx #指定映射端口

使用浏览器,或者使用curl命令访问这两个端口可以看到容器提供的nginx服务
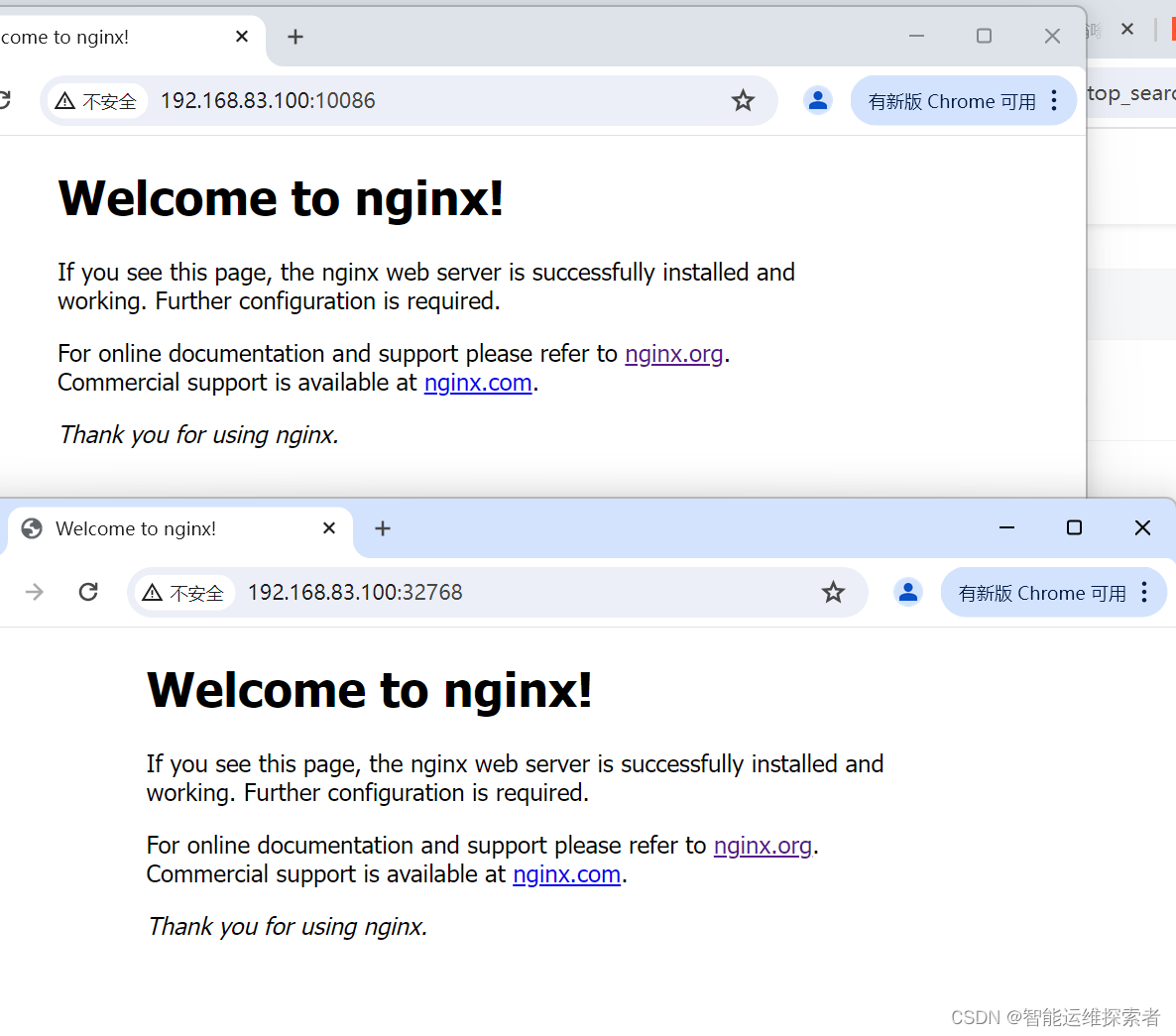
可以查看该容器详细信息,查询该容器的网络模式
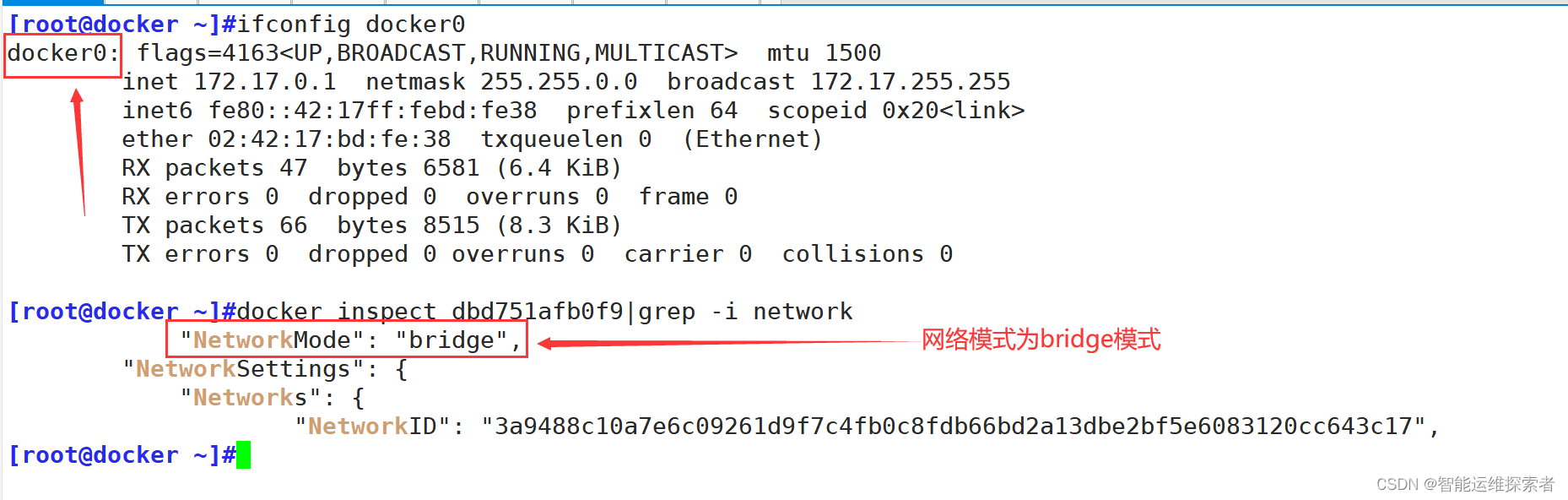
容器的虚拟接口通过与docker0与宿主机相连
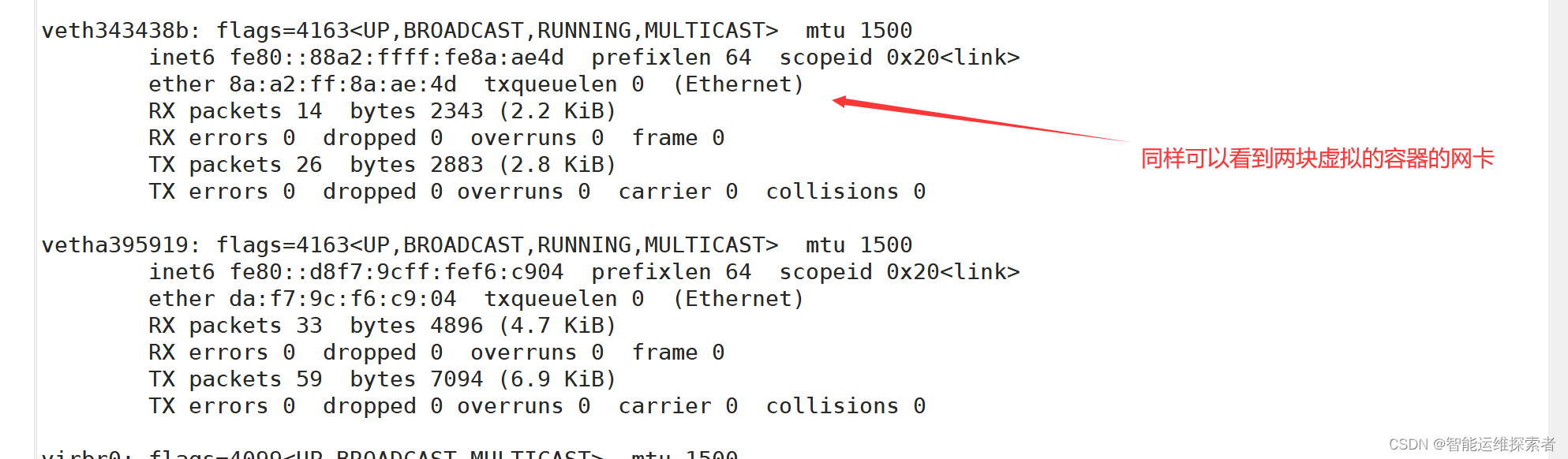
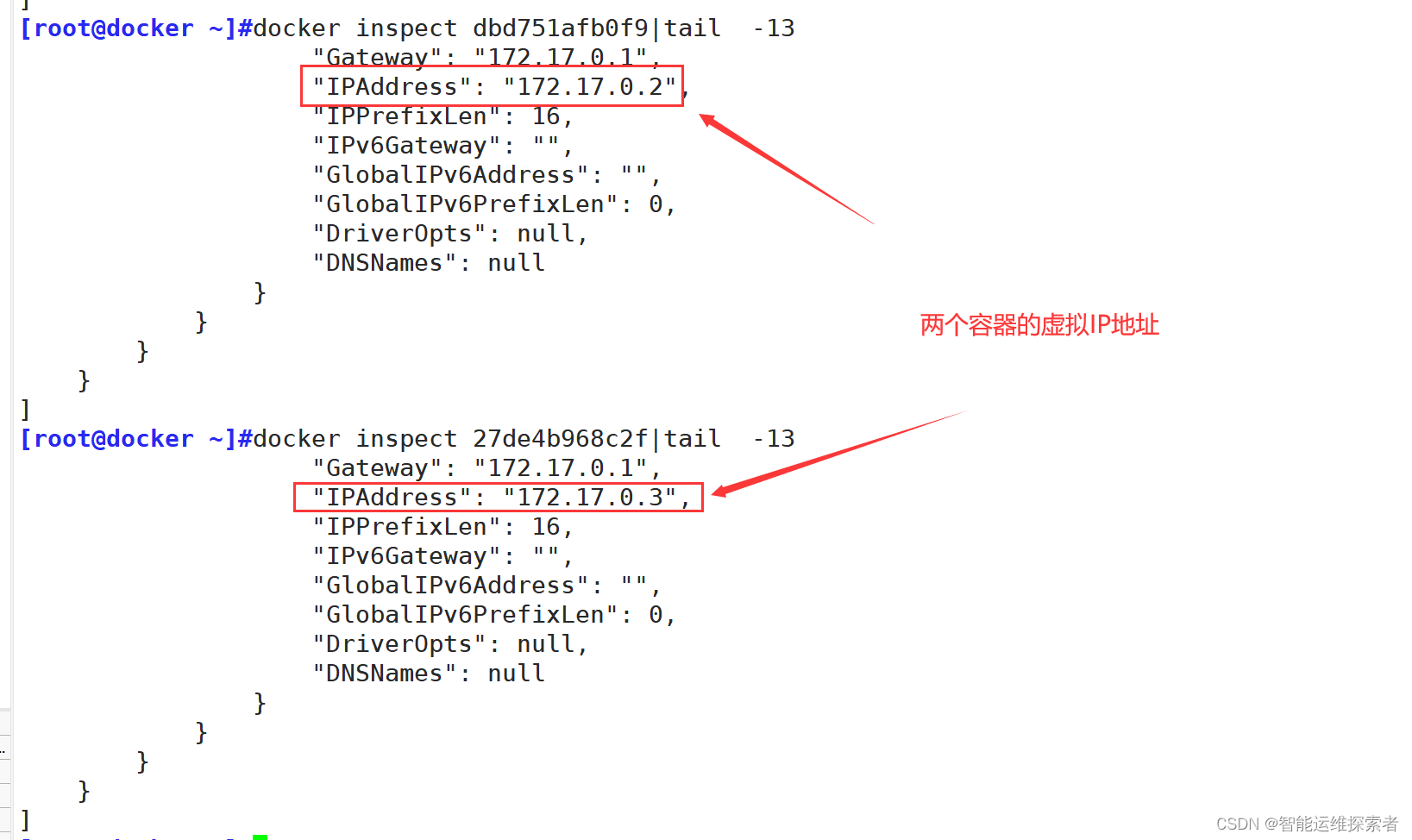
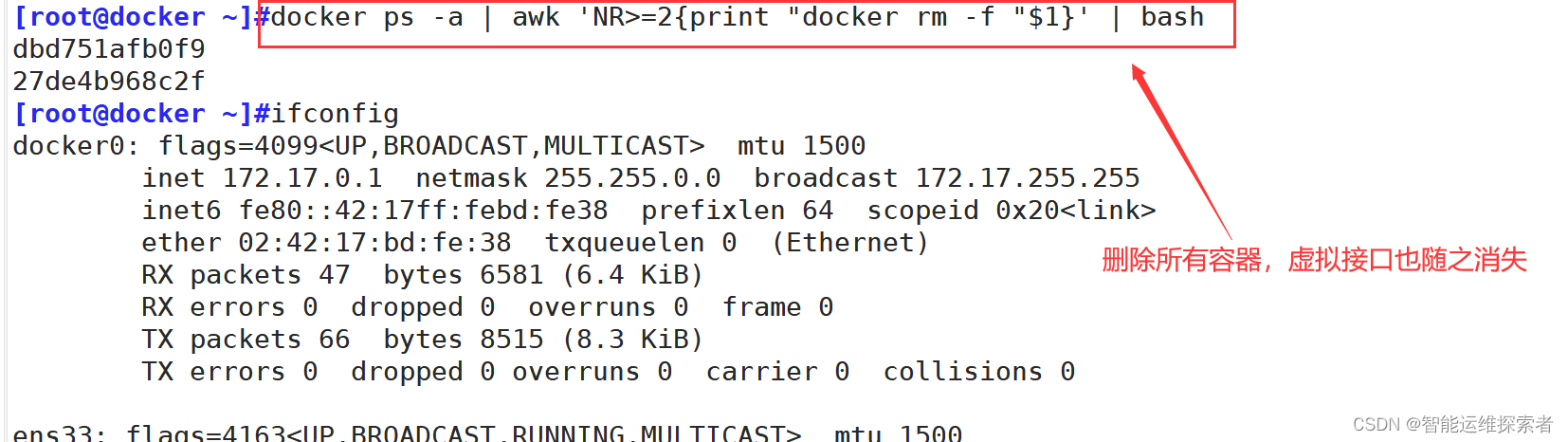
删除容器后,虚拟接口也会一同消失
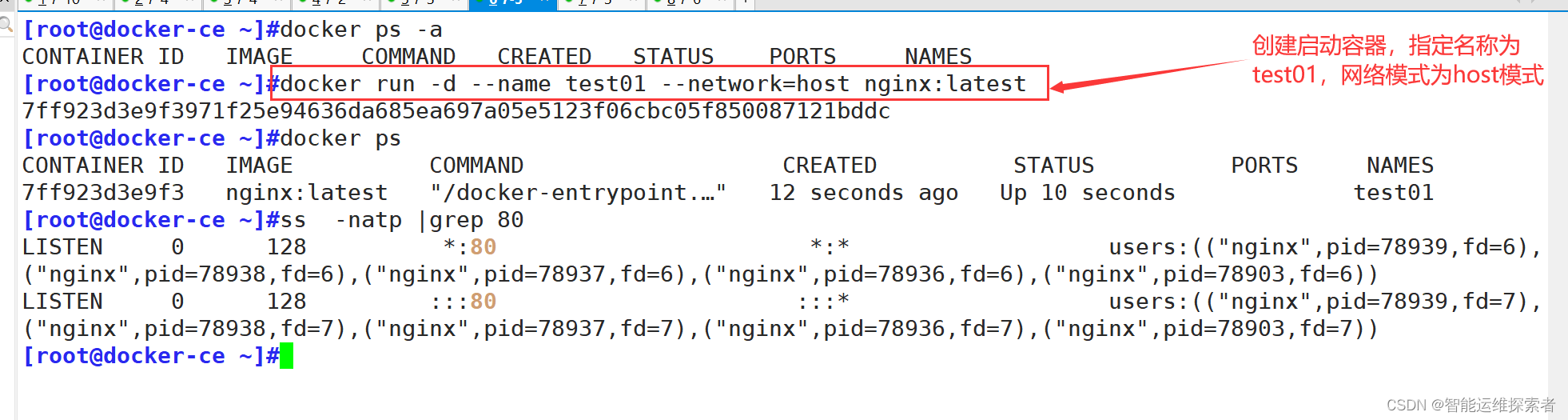
2. Host网络
选择Host网络模式,容器将直接使用宿主机的网络栈,不进行任何网络隔离。这种方式适用于需要高性能网络访问或需要监听宿主机网络端口的场景。
通过使用 --network=host 指令设置
使用浏览器就可以直接访问容器的80端口
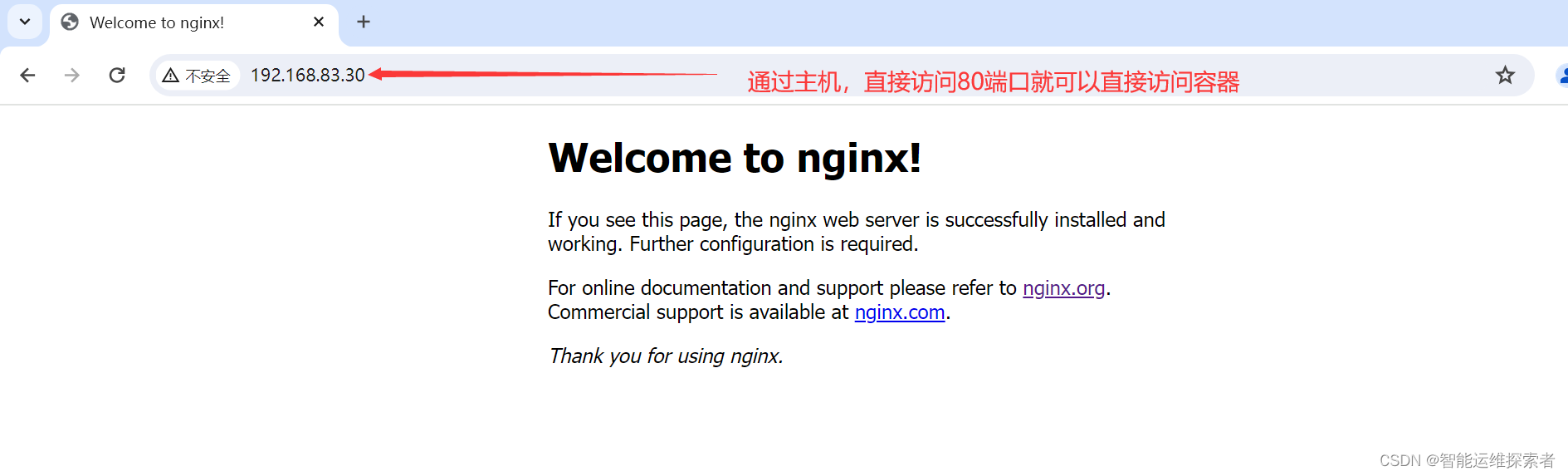
因为host模式下,容器与宿主机共享网络,访问宿主机的80端口,就等于访问容器的80端口
查看容器的详细信息可以看到网络模式与IP地址是否存在

3. None网络
使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。 也就是说,这个Docker容器没有网卡、IP、路由等信息。这种网络模式下容器只有lo回环网络,没有其他网卡,没有办法联网,封闭的网络能很好的保证容器的安全性,适合那些不需要网络连接的后台任务或安全测试环境。
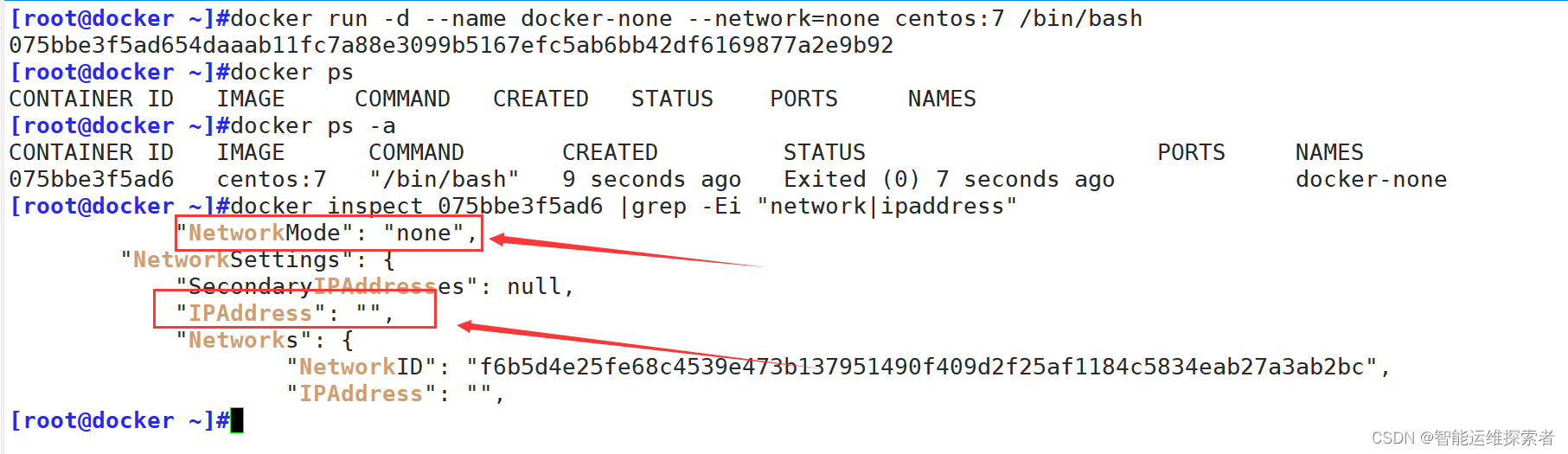
4. Container网络
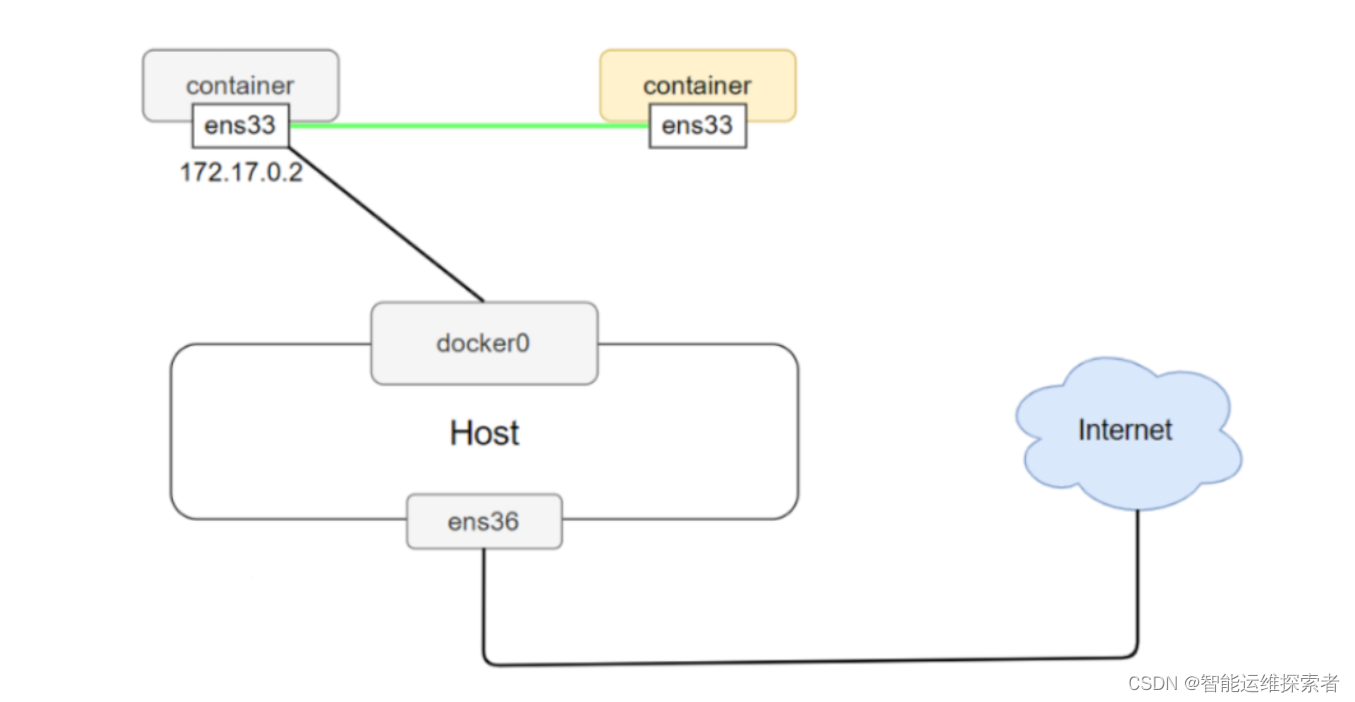
与host不同,该模式允许一个容器共享另一个容器的网络命名空间,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过lo网卡设备通信。适合需要紧密网络耦合的场景,例如数据库和应用服务间的直接通信。
[root@docker ~]#docker run -itd --name test1 centos:7 /bin/bash
#基于镜像centos:7 创建一个名为test1的容器
[root@docker ~]#docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c7a9156c2a77 centos:7 "/bin/bash" 4 seconds ago Up 3 seconds test1
[root@docker ~]#docker inspect -f '{{.State.Pid}}' c7a9156c2a77
#查看容器test1的进程号
[root@docker ~]#ll /proc/4500/ns/
总用量 0
lrwxrwxrwx. 1 root root 0 4月 25 16:35 ipc -> ipc:[4026532506]
lrwxrwxrwx. 1 root root 0 4月 25 16:35 mnt -> mnt:[4026532504]
lrwxrwxrwx. 1 root root 0 4月 25 16:35 net -> net:[4026532509]
lrwxrwxrwx. 1 root root 0 4月 25 16:35 pid -> pid:[4026532507]
lrwxrwxrwx. 1 root root 0 4月 25 16:35 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 4月 25 16:35 uts -> uts:[4026532505]
#查看容器的进程、网络、文件系统等命名空间编号#创建web2容器,使用container网络模式,和test1共享网络命名空间
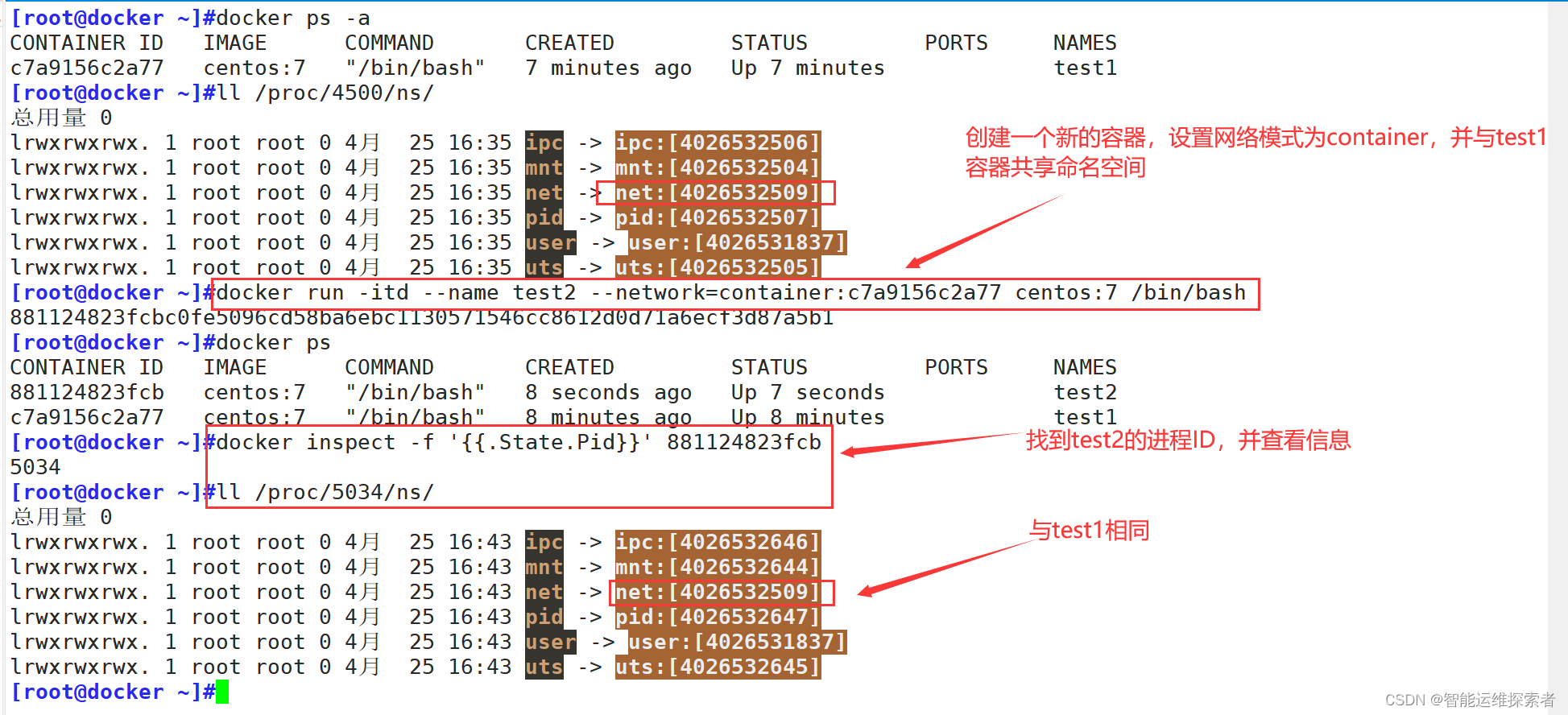
[root@docker ~]#docker run -itd --name test2 --network=container:c7a9156c2a77 centos:7 /bin/bash
[root@docker ~]#docker inspect -f '{{.State.Pid}}' 881124823fcb
5034
#查看test2容器的pid
[root@docker ~]#ll /proc/5034/ns/
#查看test2与test1的网络命名空间编号是否相同,共享同一个网络命名空间
总用量 0
lrwxrwxrwx. 1 root root 0 4月 25 16:43 ipc -> ipc:[4026532646]
lrwxrwxrwx. 1 root root 0 4月 25 16:43 mnt -> mnt:[4026532644]
lrwxrwxrwx. 1 root root 0 4月 25 16:43 net -> net:[4026532509]
lrwxrwxrwx. 1 root root 0 4月 25 16:43 pid -> pid:[4026532647]
lrwxrwxrwx. 1 root root 0 4月 25 16:43 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 4月 25 16:43 uts -> uts:[4026532645]

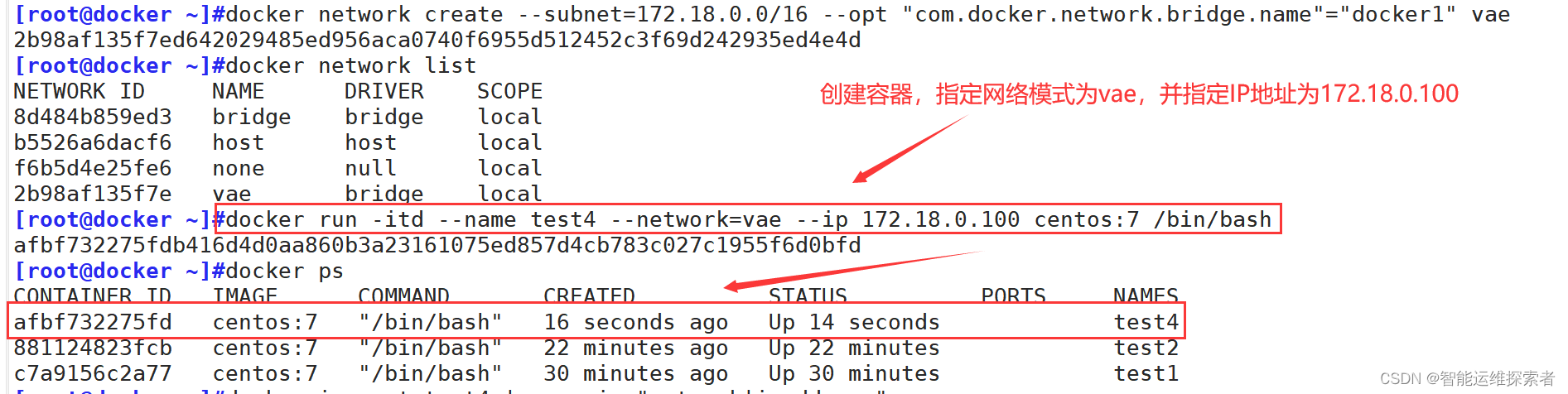
5. 自定义网络
Docker允许创建自定义网络,如Overlay网络(跨主机通信)、MacVLAN网络等,提供了更高级的网络配置选项,如网络隔离、子网划分、DNS配置等,特别适合复杂的微服务架构。
使用--ip选项指定网络,但是直接使用会报错,因为bridge模式不支持指定IP运行docker,所以需要先自定义网络
[root@docker ~]#docker network create --subnet=172.18.0.0/16 --opt "com.docker.network.bridge.name"="docker1" vae
#创建网络,并指定网段、名称等信息
2b98af135f7ed642029485ed956aca0740f6955d512452c3f69d242935ed4e4d
[root@docker ~]#docker network list #查看所有的网络
NETWORK ID NAME DRIVER SCOPE
8d484b859ed3 bridge bridge local
b5526a6dacf6 host host local
f6b5d4e25fe6 none null local
2b98af135f7e vae bridge local
docker network create
#这是创建Docker网络的基本命令。--subnet=172.18.0.0/16
#指定新网络所使用的IP地址范围。--opt "com.docker.network.bridge.name"="docker1"
#这是一个自定义网络选项,用来指定Docker内部创建的网桥设备的名称vae
#这是为新建的Docker网络指定的名称。后续在创建或连接容器到此网络时,将引用这个网络名称创建容器,并指定IP地址

知识小结
| Bridge(桥接)模式 | 默认模式:当不特别指定网络模式时,Docker会使用Bridge模式。 网络隔离:每个容器都有自己的网络命名空间(Network Namespace),提供网络隔离。 虚拟网桥:Docker在宿主机上创建一个名为 IP分配:Docker为每个加入此网络的容器分配一个唯一的IP地址,通常从一个预设的私有IP地址范围中选取。 容器间通信:同一Bridge网络下的容器可以直接通过各自的IP地址进行通信。 对外通信:容器默认无法直接被外部网络访问。若要使其可访问,需要通过端口映射( |
| Host(主机)模式 | 网络共享:容器不再拥有独立的网络命名空间,而是直接使用宿主机的网络堆栈,与宿主机共享IP地址和端口。 无网络隔离:在这种模式下,容器与宿主机在网络层面没有区别,它们使用相同的网络接口和端口。 容器间通信:容器间通过宿主机IP和端口进行通信,无需额外配置。 对外通信:容器的服务可以直接暴露在宿主机的IP和端口上,外部可以直接访问。 |
| None(无网络)模式 | 网络禁用:容器没有网络功能,不配置任何网络接口。 完全隔离:容器不能与其他容器、宿主机或外部网络进行任何网络通信。 特殊用途:适用于那些不需要网络连接,或者用户计划自行配置网络的场景,如安全性极高的环境或仅作为数据卷使用的容器 |
| Container(容器)模式 | 网络共享:新创建的容器共享已存在容器的网络命名空间,即它们使用相同的网络栈。 网络连通性:新容器与目标容器具有相同的网络属性,可以互相通信,且对外部的可见性与目标容器相同。 实例:在Kubernetes(K8s)中,Pod内的多个容器共享同一个网络命名空间,类似于使用Container模式。 |
| Custom(自定义)网络 | 用户定义:除了默认的Bridge网络外,用户可以创建自定义的网络,这些网络同样基于Bridge机制,但提供了更丰富的管理功能。 内部DNS:自定义网络通常支持内置的DNS服务,允许容器通过名称而非IP地址相互通信。 多子网支持:可以创建多个自定义网络,每个网络使用不同的子网,以实现更细粒度的网络划分和隔离。 策略控制:自定义网络可能支持更复杂的网络策略,如访问控制列表(ACLs)、网络策略等,用于精细化管理容器间的网络流量。 |
二、资源控制
Docker资源控制允许用户对运行在其上的容器进行详细的资源限制和配额设定,以确保容器在共享宿主机资源时不会过度消耗,从而保持宿主机的稳定性和整体资源的有效利用
(一)cgroup 介绍
Docker 通过 cgroup 来控制容器使用的资源配额,包括 CPU、内存、磁盘三大方面,基本覆盖了常见的资源配额和使用量控制。。
cgroup 概述
cgroup 是 Control Groups的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组所使用
的物理资源(如 cpu、memory、磁盘I0 等等)的机制,被 LXC、docker 等很多项目用于实现进程资源控制。cgroup将任意进程进行分组化管理的Linux内核功能。cgroup本身是提供将进程进行分组化管理的功能和接口的基础结构,I/0 或内存的分配控制等具体的资源管理功能是通过这个功能来实现的。。
cgroups,是一个非常强大的linux内核工具,他不仅可以限制被 namespace 隔离起来的资源, 还可以为资源设置权重、计算使用量、操控进程启停等等。 所以 cgroups(Control groups)实现了对资源的配额和度量。
cgroups有四大功能
资源限制:可以对任务使用的资源总额进行限制
优先级分配:通过分配的cpu时间片数量以及磁盘IO带宽大小,实际上相当于控制了任务运行优先级
资源统计:可以统计系统的资源使用量,如cpu时长,内存用量等
任务控制:cgroup可以对任务执行挂起、恢复等操作
(二)CPU限制
Docker容器的CPU资源控制允许您对容器在宿主机上使用CPU资源的方式进行限制和管理。当多个容器运行时,防止某个容器把所有的硬件资源都占用了。比如一台被黑的容器,可能会占用所有资源
1.CPU限制(绝对配额)
Linux通过CFS(Completely Fair Scheduler,完全公平调度器)来调度各个进程对CPU的使用。CFS默认的调度周期是100ms。
我们可以设置每个容器进程的调度周期,以及在这个周期内各个容器最多能使用多少 CPU 时间
参数:

--cpus:设置容器可以使用的CPU核心数(如--cpus=1.5表示容器可使用1.5个CPU核心的计算能力)。
--cpu-quota 和 --cpu-period:更精细地控制容器在一个固定周期内可使用的CPU时间。
作用:
--cpus:直接限制容器使用整个CPU资源的比例。
--cpu-quota 和 --cpu-period:配合使用,--cpu-quota 设置容器在一个--cpu-period定义的时间周期内可使用的最大CPU时间(单位为毫秒)。--cpu-period默认为100ms,代表CPU调度的时间间隔。而容器的 CPU 配额必须不小于 1ms,即 --cpu-quota 的值必须 >= 1000
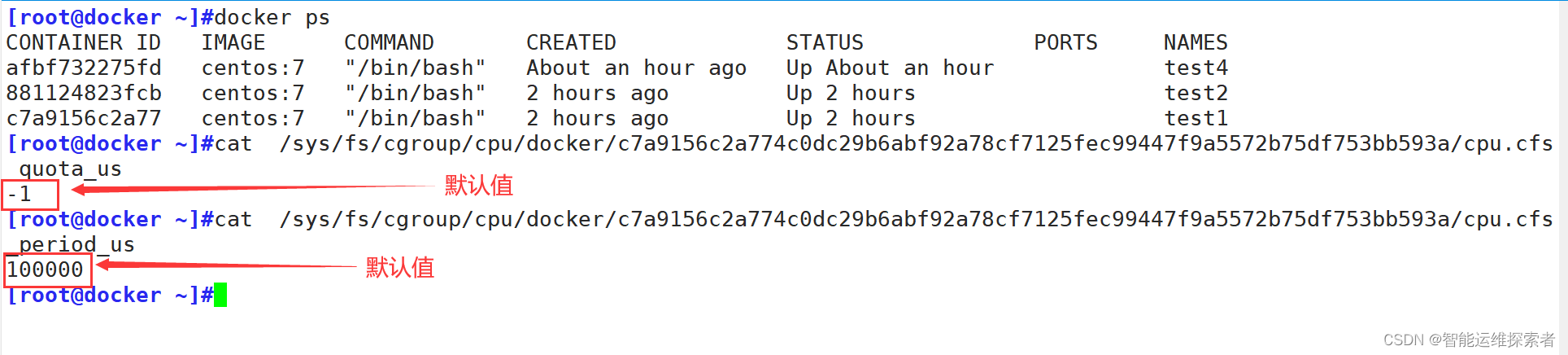
一般period的值不会进行变动,主要设置quota的值。默认为-1,表示不限制。 如果设为50000,表示占用50000/100000=50%的CPU。
默认为-1的情况下,如果容器的CPU使用率过高,会导致宿主机的CPU使用率同样达到瓶颈
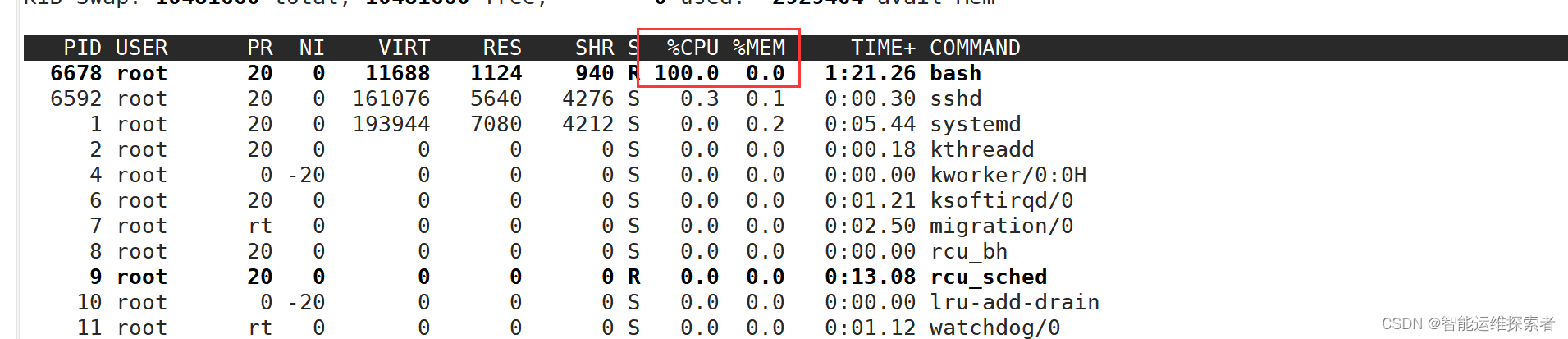
修改quota的值
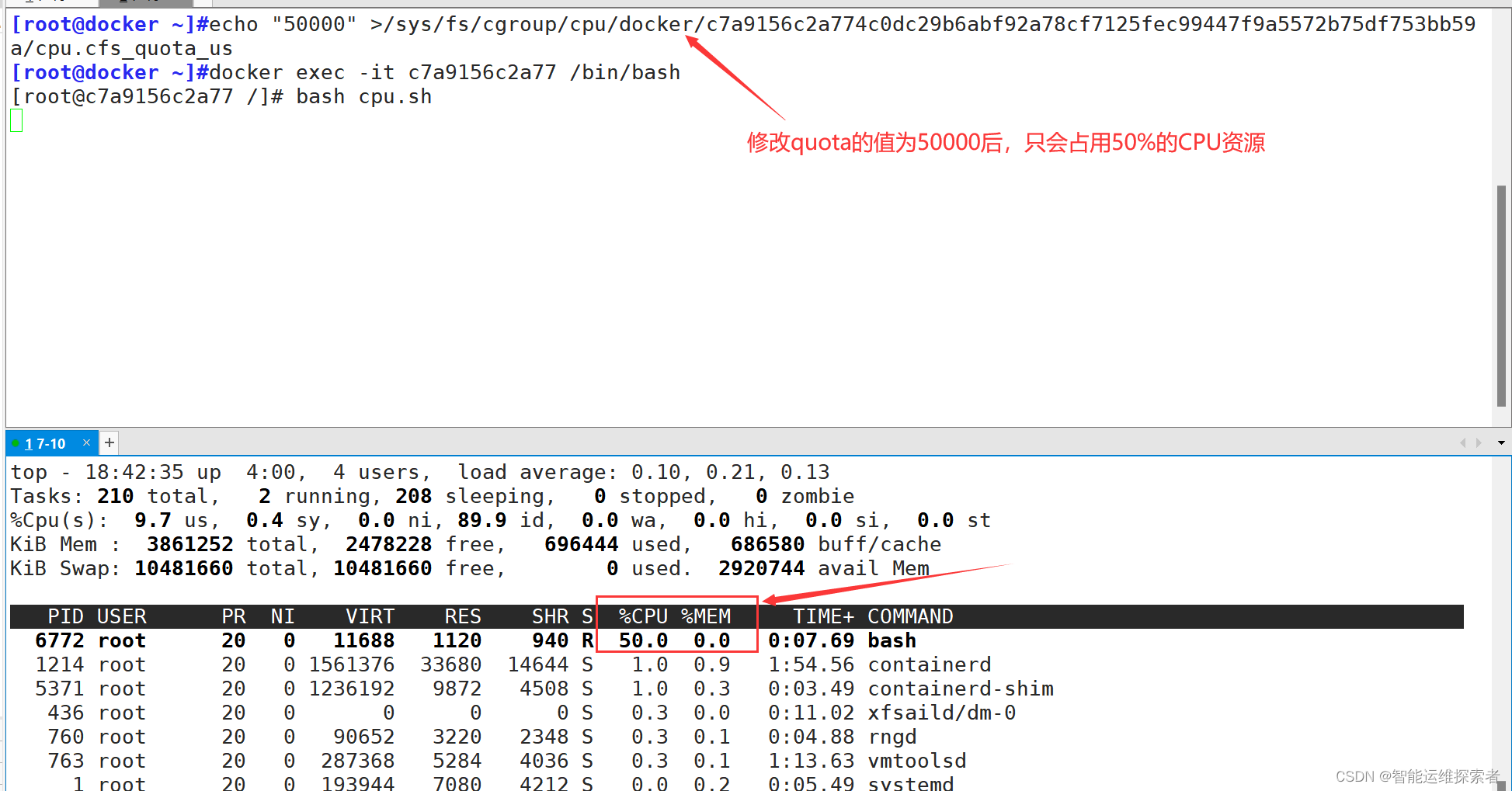
创建容器时直接指定数值
命令格式为
docker run -itd --name 容器名称 --cpu-period=int --cpu-quota=int[root@docker ~]#docker run -itd --name test-cpu --cpu-period=100000 --cpu-quota=50000 centos:7[root@docker ~]#cat/sys/fs/cgroup/cpu/docker/db16bcc79a1d13aaac977c9fcfe4f8a92c03ccddcb260d36d0cbba8feabffc10/cpu.cfs_quota_us
50000
2.CPU份额(相对权重)
参数: --cpu-shares 或 -c
作用: 设置容器相对于其他容器的CPU使用权重。默认值为1024,更高的值意味着当CPU资源紧张时,该容器相对于其他容器有更高的优先级获取CPU时间。这是一种相对公平调度策略,而不是硬性限制容器使用特定的CPU时间。

Docker 通过 --cpu-shares 指定 CPU 份额,默认值为1024,值为1024的倍数。
在创建容器时指定容器所使用的 CPU 份额值。cpu-shares 的值不能保证可以获得1个vcpu 或者多少 GHz的 CPU 资源,仅仅只是一个弹性的加权值。
默认每个 docker 容器的 cpu 份额值都是 1024。在同一个 CPU 核心上,同时运行多个容器时,容器的 cpu 加权的效果才能体现出来。

例如:两个容器 A、B的 cpu 份额分别为 1000 和 500,结果会怎么样?
情况 1:A和 B正常运行,在 cpu 进行时间片分配的时候,容器A比容器B 多一倍的机会获得 CPU的时间片。
情况 2:分配的结果取决于当时其他容器的运行状态。比如容器 A的进程一直是空闲的,那么容器 B是可以获取比容器 A 更多的 CPU 时间片的;比如主机上只运行了一个容器,即使它的 cpu 份额只有 50它也可以独占整个主机的 cpu 资源。
cgroups 只在多个容器同时争抢同一个 cpu 资源时,cpu 配额才会生效。因此,无法单纯根据某个容器的 cpu 份额来确定有多少 cpu 资源分配给它,资源分配结果取决于同时运行的其他容器的 cpu 分配和容器中进程运行情况。
首先设置一个指定权重为512的容器
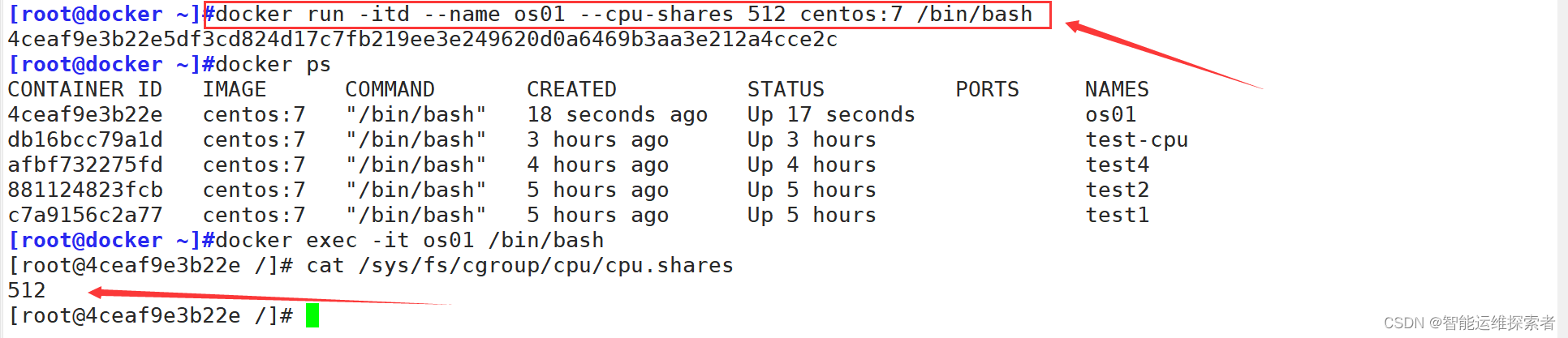
单独一个容器,看不出来使用的 cpu 的比例。因没有 docker 实例同此 docker 实例竞争。需要多起几个容器,而且,容器是一个单线程的进程,如果我们有多个CPU同样无法显示效果,一个进程可能会占用一个CPU,两个进程可能分别使用不同的CPU,所以需要设置单个CPU,或者进行CPU绑定,首先设置单个CPU。

创建一个权重为1024的容器

情况 1:A和B正常运行,在 cpu 进行时间片分配的时候,容器A(权重值为1024)比容器B(权重值为512)更多的机会获得CPU的时间片。
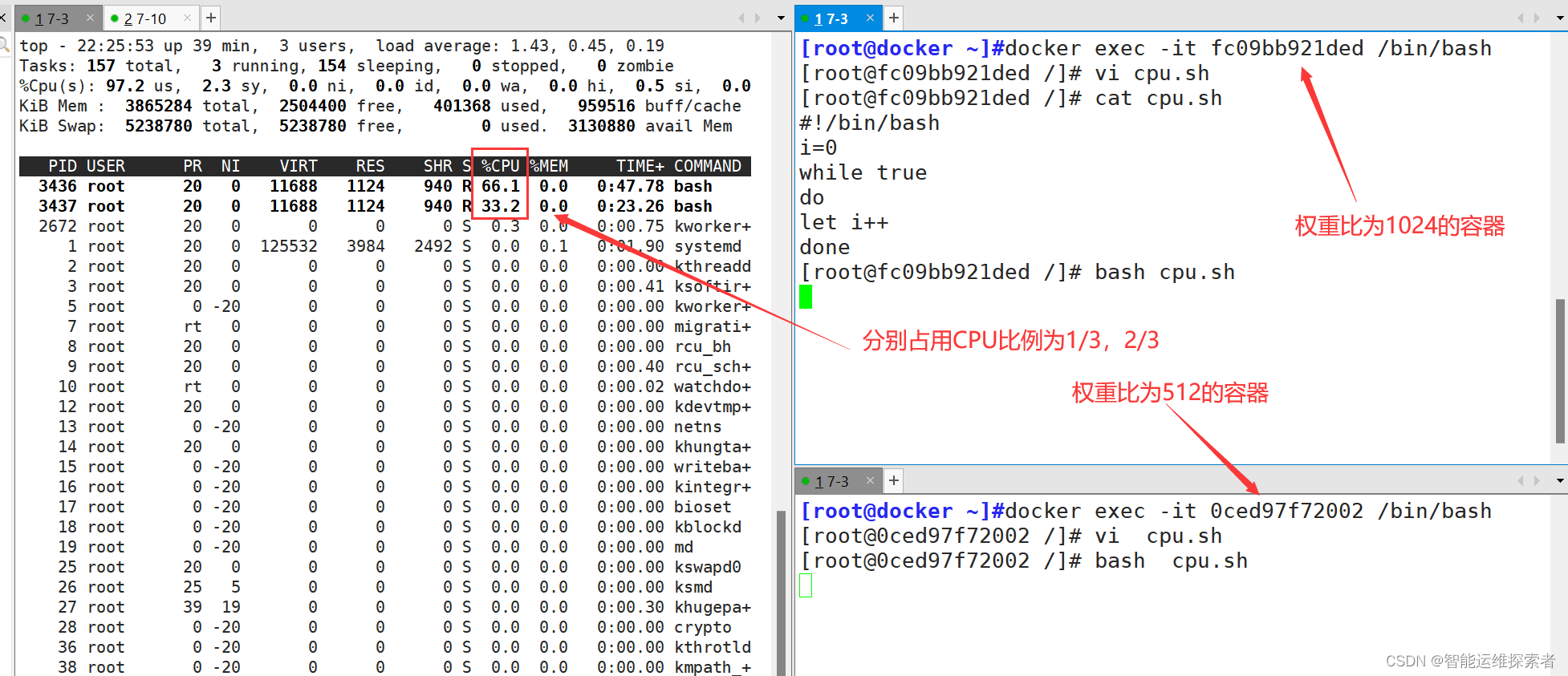
使用stress工具进行压测#分别进入容器,进行压力测试
[root@0ced97f72002 /]#yum install -y epel-release
[root@0ced97f72002 /]#yum install -y stress
[root@0ced97f72002 /]#stress -c 4
#产生四个进程,每个进程都反复不停的计算随机数的平方根
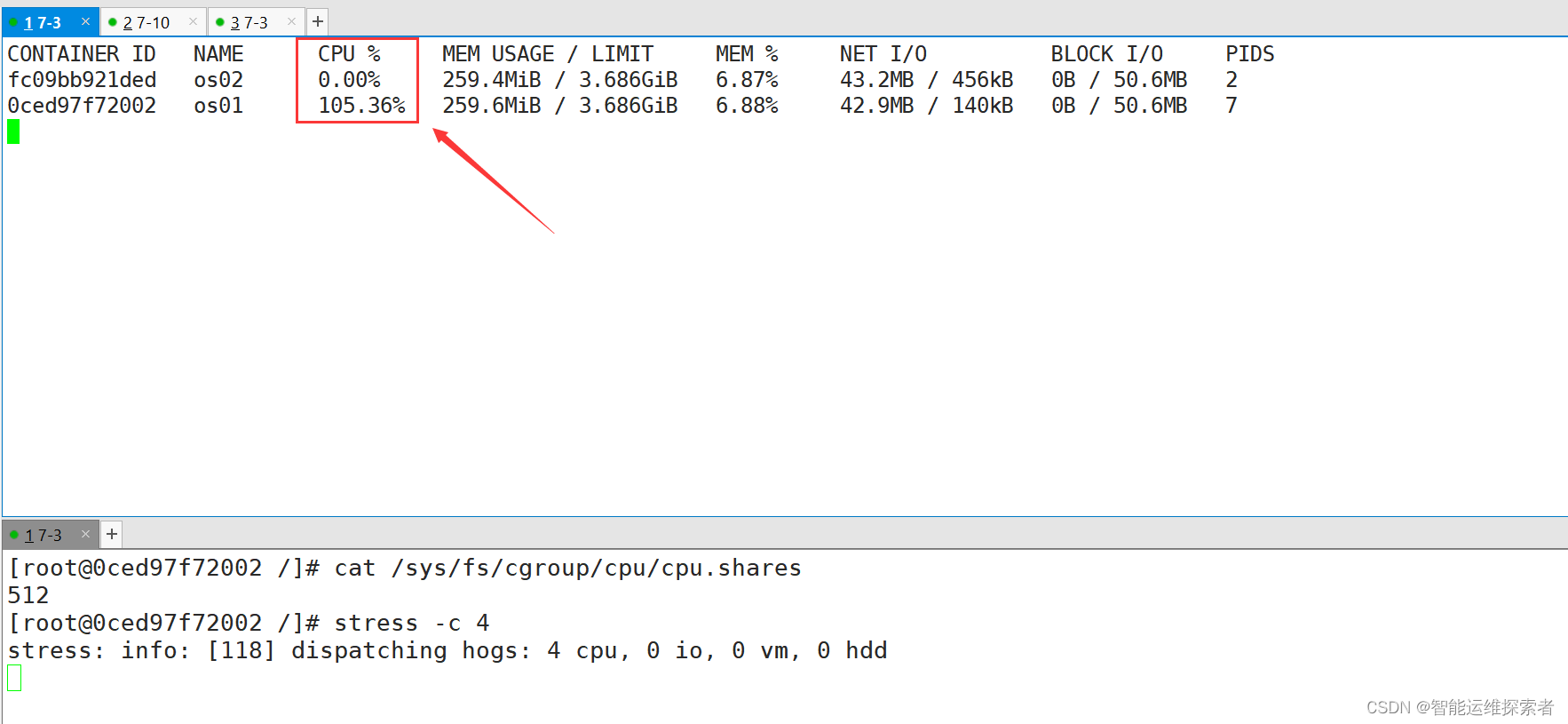
[root@docker ~]#docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
fc09bb921ded os02 66.21% 259.6MiB / 3.686GiB 6.88% 43.2MB/456kB 0B/50.6MB 7
0ced97f72002 os01 33.35% 259.6MiB / 3.686GiB 6.88% 42.9MB/140kB 0B/50.6MB 7
情况 2:容器 A的进程一直是空闲的,那么容器 B是可以获取比容器 A 更多的 CPU 时间片的;比如主机上只运行了一个容器,即使它的权重为512,它也可以独占整个主机的 cpu 资源。
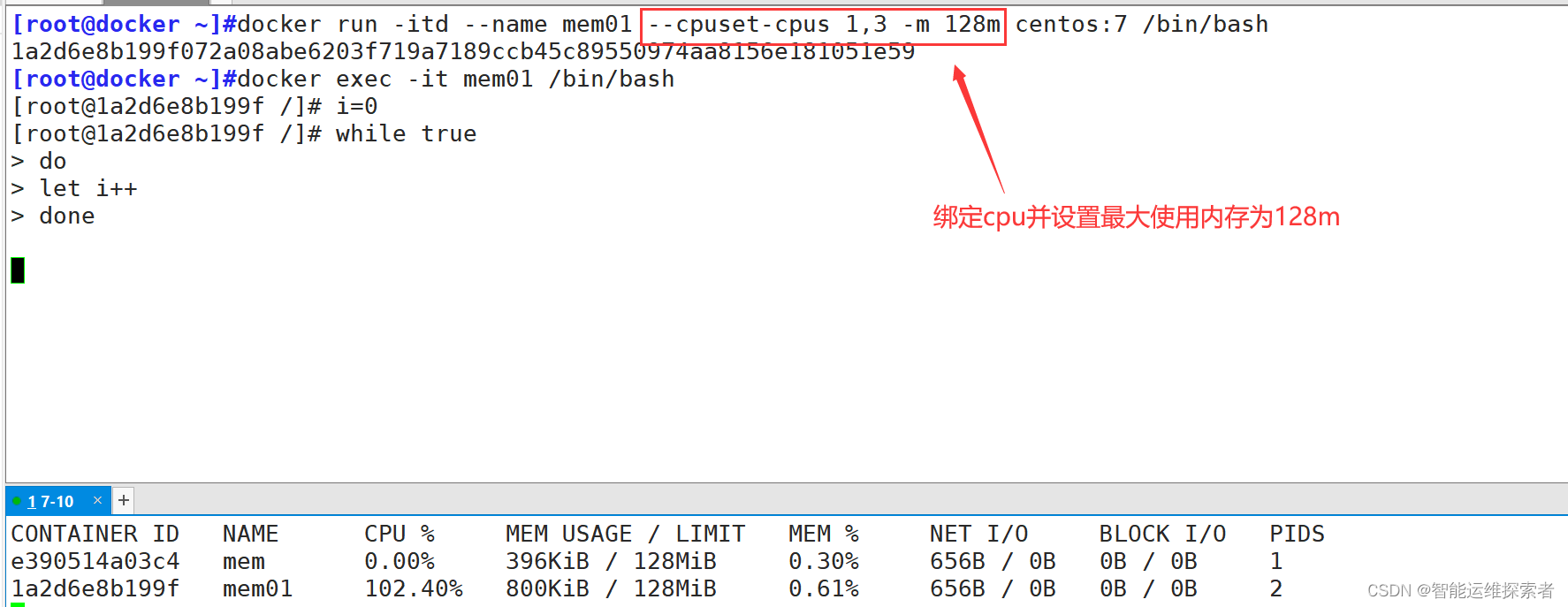
3.CPU亲和性(CPU绑定)
参数: --cpuset-cpus 或 --cpuset-mems
作用:
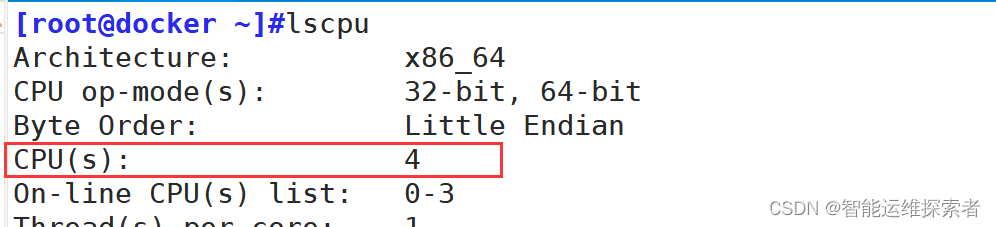
--cpuset-cpus:指定容器可以使用的特定CPU核心编号(从0开始,如果有4个CPU,则编号为0,1,2,3),帮助将容器绑定到特定的CPU核心上,实现物理隔离或优化缓存利用率。
--cpuset-mems(较少使用):指定容器可以使用的NUMA节点(非一致性内存访问节点),用于多插槽服务器的内存亲和性设置。
将CPU调整为4核
创建 容器并绑定CPU
[root@docker ~]#docker run -itd --name cpu-bond --cpuset-cpus 1,3 centos:7 /bin/bash
9cd3854ad345266bb6cc49e8f5155b532abb8f11ed5d1be910ca160a1e8401fd
[root@docker ~]#docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9cd3854ad345 centos:7 "/bin/bash" 2 seconds ago Up 2 seconds cpu-bond
[root@docker ~]#docker exec -it 9cd3854ad345 /bin/bash
[root@9cd3854ad345 /]# yum install epel-release -y
[root@9cd3854ad345 /]# yum install -y stress
[root@9cd3854ad345 /]# stress -c 4#宿主机使用top命令查看CPU使用情况
进入容器进行查看CPU使用情况

(三)内存限制
Docker 允许用户对容器的内存使用进行限制,以防止容器过度消耗宿主机资源,影响其他容器和宿主机系统的稳定性
1.内存限制设置
硬限制 (Hard Limit)
在启动容器时,使用 --memory 或 -m 参数来设置容器可使用的最大内存总量
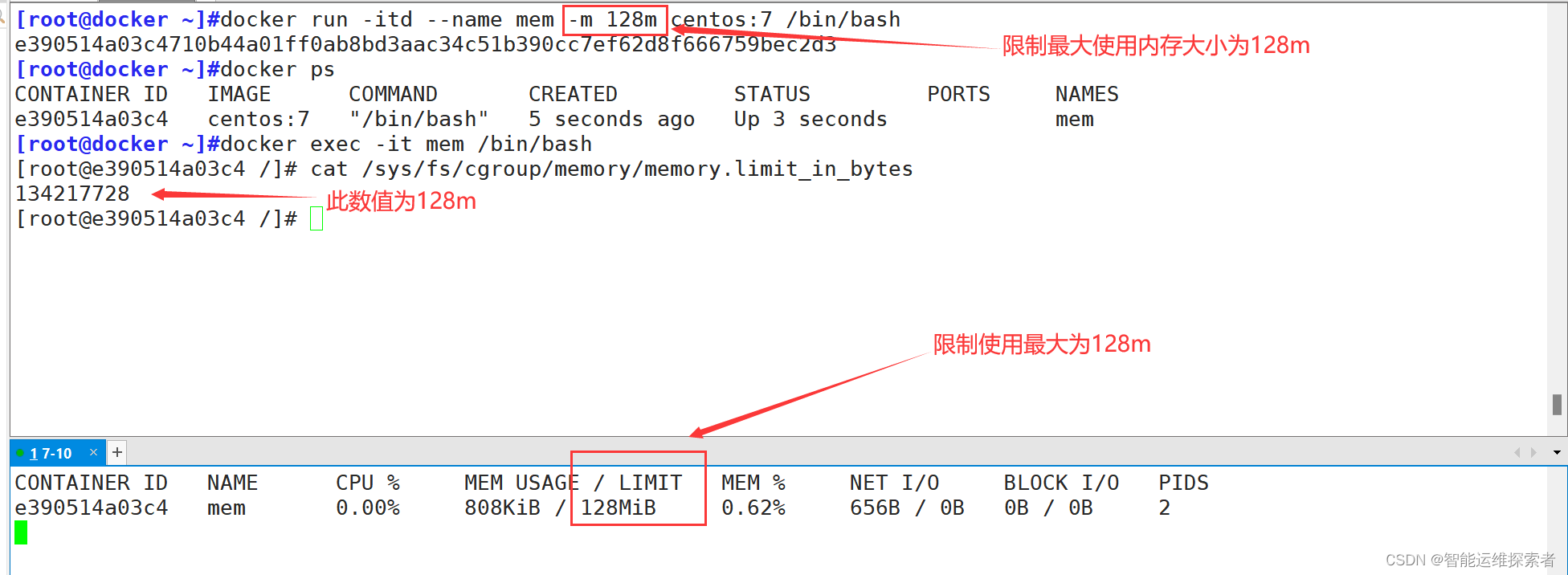
当容器尝试使用超过这个限制的内存时,Docker会根据具体情况采取行动,例如杀死容器(OOM Killer)以释放内存资源。
与cpu绑定一起使用
2.交换内存限制
可以通过 --memory-swap 参数进一步限制容器可以使用的内存加swap空间总量。如果不设置此参数,通常情况下,容器的swap空间将是其内存限制的两倍
--memory-swap 是必须要与 --memory 一起使用的。
正常情况下,--memory-swap 的值包含容器可用内存和可用 swap。
所以 -m 300m --memory-swap=1g 的含义为:容器可以使用 300M 的物理内存,并且可以使用 700M(1G - 300)的 swap。
如果 --memory-swap 设置为 0 或者 不设置,则容器可以使用的 swap 大小为 -m 值的两倍。
如果 --memory-swap 的值和 -m 值相同,则容器不能使用 swap。
如果 --memory-swap 值为 -1,它表示容器程序使用的内存受限,而可以使用的 swap 空间使用不受限制(宿主机有多少 swap 容器就可以使用多少)

[root@docker ~]#docker run -itd --name docker-swap -m 300m --memory-swap=1g centos:7
6246d3ff00960b24bb270df06daeb0e4ae001c309c63a2193380015acdaf31c7
#通过 -m 300m 参数限制了容器的内存使用量为300MB。
#通过 --memory-swap=1g 参数限制了容器的内存和swap空间总和为1GB。[root@docker ~]#docker exec -it docker-swap /bin/bash
[root@6246d3ff0096 /]# cat /sys/fs/cgroup/memory/memory.memsw.limit_in_bytes
1073741824
#这是一个字节数值,转换成GB是1GB[root@6246d3ff0096 /]# free -htotal used free shared buff/cache available
Mem: 3.7G 1.0G 458M 40M 2.2G 2.4G
Swap: 9G 744K 9Gtotal 表示容器可以看到的总内存大小,这里是3.7GB,
这是因为Docker默认会把一部分宿主机的内存分配给容器(具体分配多少取决于宿主机和其他容器的配置)。Swap 行显示容器当前看到的swap空间总大小为9GB,但目前只使用了744KB,剩余9GB未使用。
(四)磁盘IO配额控制的限制
Docker 中对磁盘 I/O 配额的控制是通过 blkio 子系统实现的,该子系统是 Linux 控制组(cgroups)的一部分,用于限制和审计块设备(例如硬盘)的输入输出操作。
--device-read-bps:限制某个设备上的读速度bps(数据量),单位可以是kb、mb(M)或者gb。
--device-write-bps : 限制某个设备上的写速度bps(数据量),单位可以是kb、mb(M)或者gb
例:docker run -it --device-read-bps /dev/sda:1mb --device-write-bps /dev/sda:512kb your_image
#限制了容器对/dev/sda设备的读取速度为每秒1MB,写入速度为每秒512KB。
--device-read-iops :限制读某个设备的iops(次数)
--device-write-iops :限制写入某个设备的iops(次数)
例:docker run -it --device-read-iops /dev/sda:100 --device-write-iops /dev/sda:50 your_image
#限制容器对/dev/sda设备的读取操作为每秒100次,写入操作为每秒50次。
[root@docker ~]#docker run -it --name docker-io --device-read-bps /dev/sda:1mb --device-write-bps /dev/sda:1MB centos:7 /bin/bash
#创建容器并限制读写速度
--device-read-bps /dev/sda:1mb
#对容器可见的 /dev/sda 设备设置读取速率限制,限制容器每秒最多只能从该设备读取1MB的数据。--device-write-bps /dev/sda:1MB
#对容器可见的 /dev/sda 设备设置写入速率限制,限制容器每秒最多只能向该设备写入1MB的数据。[root@78a7f0be1977 /]# dd if=/dev/zero of=test.out bs=1M count=10 oflag=direct
#添加oflag参数以规避掉文件系统cache10+0 records in #表示输入(读取)了10个记录。
10+0 records out #表示输出(写入)了10个记录。
10485760 bytes (10 MB) copied, 10.0048 s, 1.0 MB/s10485760 bytes (10 MB) copied #表明这次操作总共复制了10485760字节的数据,即大约10MB。10.0025 s #指完成这次数据复制操作所花费的时间,约为10.0025秒。1.0 MB/s #计算出的平均传输速率,即每秒传输了约1.0 MB的数据
注意:在使用过程中注意版本问题,在较新的版本中可能不支持使用此参数进行读写限制
三、数据管理
Docker数据管理主要指的是如何在容器生命周期中处理和持久化数据的问题
管理 Docker 容器中数据主要有两种方式:数据卷(Data Volumes)和数据卷容器(DataVolumes Containers)
(一)数据卷
数据卷是一个供容器使用的特殊目录,位于容器中。可将宿主机的目录挂载到数据卷上,对数据卷的修改操作立刻可见,并且更新数据不会影响镜像,从而实现数据在宿主机与容器之间的迁移。数据卷的使用类似于 Linux 下对目录进行的 mount 操作
- 数据卷是独立于容器生命周期的,在宿主机上的一个目录,可以直接映射到容器内部的文件系统中。
- 数据卷的内容在容器重启、停止或删除时都不会丢失。
- 数据卷可以在多个容器之间共享,从而实现多容器之间的数据共享和持久化。
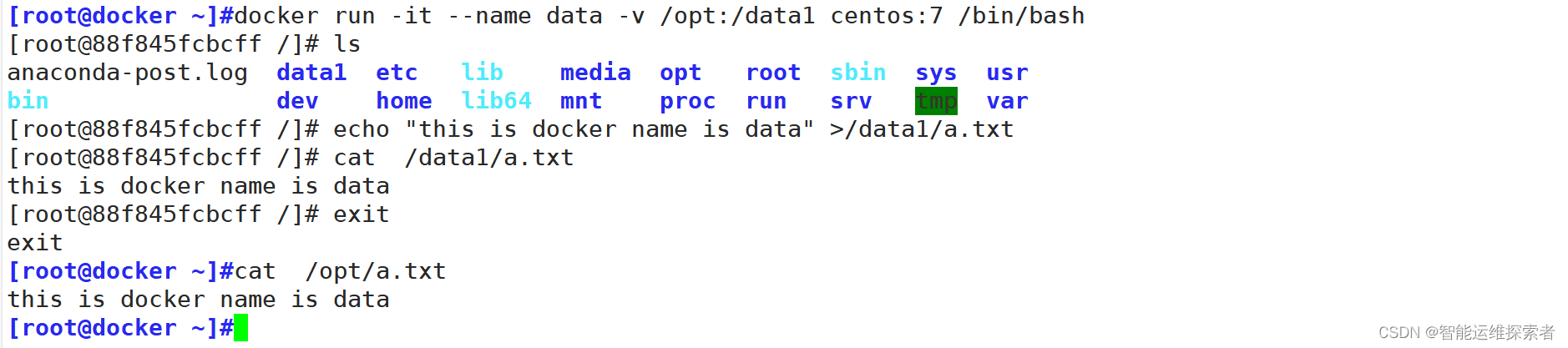
[root@docker ~]#docker run -it --name data -v /opt:/data1 centos:7 /bin/bash
#创建容器,并将宿主机的/opt目录挂载到容器的data1目录下
#-v 选项可以在容器内创建数据卷
[root@88f845fcbcff /]# ls
anaconda-post.log data1 etc lib media opt root sbin sys usr
bin dev home lib64 mnt proc run srv tmp var
[root@88f845fcbcff /]# echo "this is docker name is data" >/data1/a.txt
#输入内容
[root@88f845fcbcff /]# cat /data1/a.txt
this is docker name is data
[root@88f845fcbcff /]# exit
exit
[root@docker ~]#cat /opt/a.txt
this is docker name is data
#查看宿主机的内容与在容器中生成并写入的文件与内容是否一致
(二)数据卷容器
如果需要在容器之间共享一些数据,最简单的方法就是使用数据卷容器。数据卷容器是一个普通的容器,专门提供数据卷给其他容器挂载使用
- 数据卷容器是一种特殊的容器,主要用于存储数据,而不是运行应用程序。
- 其他容器可以与数据卷容器共享数据卷,即使数据卷容器本身不运行任何服务,数据仍然能够被其他容器访问。
- 通过--volumes-from 参数实现数据卷容器与目标容器之间的数据共享。
首先创建一个容器作为数据卷容器
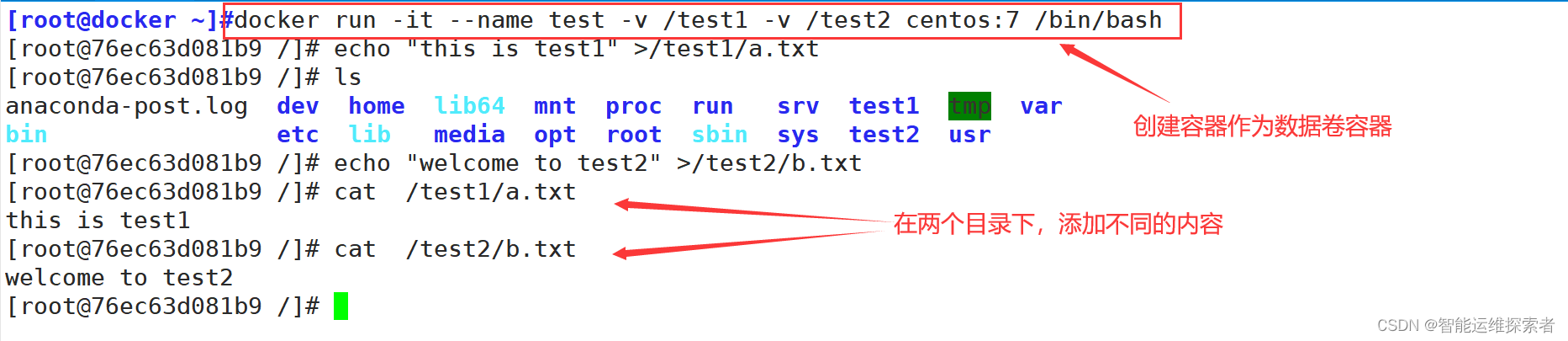
使用 --volumes-from 来挂载 test 容器中的数据卷到新的容器

四、容器互联
容器互联是通过容器的名称在容器间建立一条专门的网络通信隧道。简单点说,就是会在源容器和接收容器之间建立一条隧道,接收容器可以看到源容器指定的信息。
在早期版本的Docker中,容器间的互联主要是通过 --link 参数实现的,但在较新的Docker版本中,这一功能已被弱化,并推荐使用网络(networks)来进行容器间的通信。但是在生产环境中,较多企业以稳定为主,不会对docke进行版本迭代,所以还是需要使用link进行互联
首先创建一个新的容器,此容器为源容器,而后创建新的容器,并使用link语句去连接源容器
[root@docker ~]#docker run -itd -P --name link1 centos:7 /bin/bash
bdf4a7a69c9d703983ec6b557f0a9fea46f9c0d933cd120f36c8e250a5e08fd3
#创建新的容器。此容器为源容器
[root@docker ~]#docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bdf4a7a69c9d centos:7 "/bin/bash" 11 seconds ago Up 10 seconds link1[root@docker ~]#docker run -itd -P --name link2 --link link1:baidu centos:7 /bin/bash
1a96625f2f4d1ff7cdf92a5c79071c1d321fb0072773285c096091de43ee7f72
#创建容器2,自定义名称为link2
#--link 源容器名称:源容器别名
#此选项设置完毕后,该容器可以通过访问源容器的名称(link1)或自定义的别名(baidu),实现互联[root@docker ~]#docker exec -it link2 /bin/bash
[root@1a96625f2f4d /]# ping baidu
PING baidu (172.17.0.2) 56(84) bytes of data.
64 bytes from baidu (172.17.0.2): icmp_seq=1 ttl=64 time=0.544 ms
64 bytes from baidu (172.17.0.2): icmp_seq=2 ttl=64 time=0.344 ms
64 bytes from baidu (172.17.0.2): icmp_seq=3 ttl=64 time=0.180 ms
64 bytes from baidu (172.17.0.2): icmp_seq=4 ttl=64 time=0.280 ms
^C
--- baidu ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3026ms
rtt min/avg/max/mdev = 0.180/0.337/0.544/0.133 ms
[root@1a96625f2f4d /]# ping link1
PING baidu (172.17.0.2) 56(84) bytes of data.
64 bytes from baidu (172.17.0.2): icmp_seq=1 ttl=64 time=0.048 ms
64 bytes from baidu (172.17.0.2): icmp_seq=2 ttl=64 time=0.305 ms
64 bytes from baidu (172.17.0.2): icmp_seq=3 ttl=64 time=0.569 ms
^C
--- baidu ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2008ms
rtt min/avg/max/mdev = 0.048/0.307/0.569/0.213 ms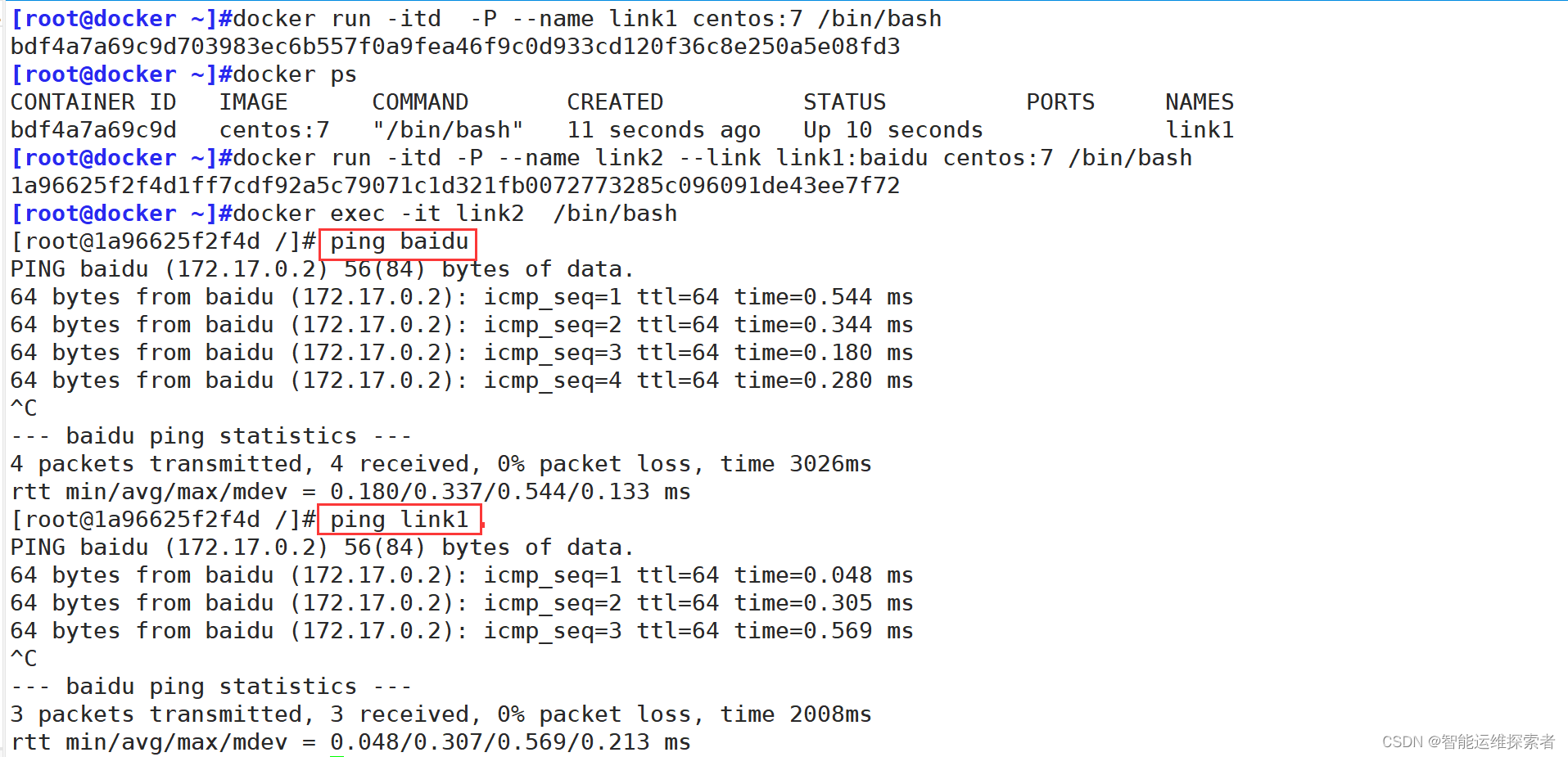
注意:虽然 --link 功能在早期Docker版本中非常有用,但在现代Docker实践中,更推荐使用自定义网络(custom networks)来实现容器间的通信和资源共享。若要采用网络的方式,可以创建一个网络并将两个容器都加入其中,这样它们就能直接通过各自的容器名进行通信,无需使用 --link 参数
五、Docker镜像的创建
创建镜像有三种方法,分别为基于已有镜像创建、基于本地模板创建以及基于Dockerfile创建。
(一)基于现有镜像创建
基于现有镜像创建就是通过修改基于镜像创建的容器,生成新的镜像
通过 docker commit 命令手动提交一个正在运行的容器的状态作为新的镜像,但这种做法缺乏可重复性和透明性
首先清空一下现有的容器:docker ps -a | awk 'NR>=2{print "docker rm -f "$1}' | bash
1.创建容器
首先基于现有镜像,创建一个容器,并在其中修改内容

2.导出容器为镜像
将修改后的容器提交为新的镜像,需要使用该容器的 ID 号创建新镜像

docker commit #用于将运行中的Docker容器的当前状态保存为一个新的镜像。-m "new" #添加提交信息,这里的信息是 "new",通常用来简述这次镜像变化的内容。-a "centos" #指定镜像的作者信息,这里设置的作者名为 "centos"。-p #生成过程中停止容器的运行3926d65691ed #这是待提交容器的ID,表示要将该容器的当前状态保存为镜像。centos:test #定义了新创建镜像的仓库名和标签(二)基于本地模板创建
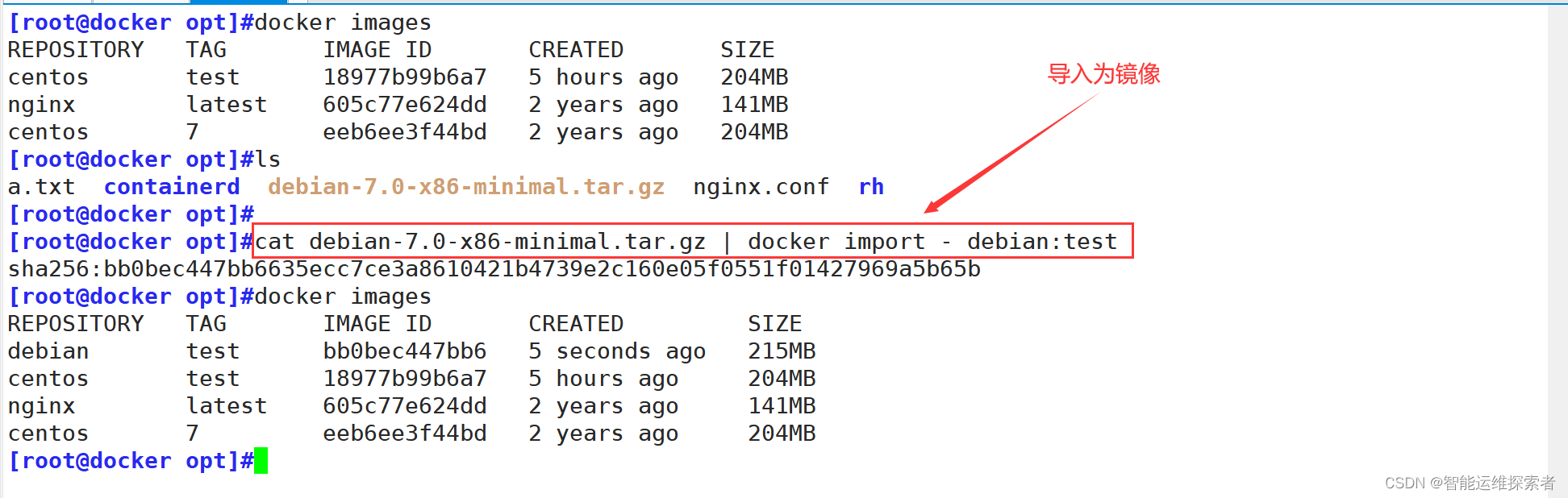
通过导入操作系统模板文件可以生成镜像,模板可以从 OPENVZ 开源项目下载
下载地址为:https://wiki.openvz.org/Download/template/precreated
可以使用wget命令下载,或者去网站下载
(三)基于Dockerfile 创建
1. 什么是Dockerfile
Dockerfile 是一个文本文件,其内包含了一条条的指令(Instruction),用于构建镜像。每一条指令构建一层镜像,因此每一条指令的内容,就是描述该层镜像应当如何构建。
- dockerfile 用于指示 docker image build 命令自动构建Image的源代码
- 是纯文本文件
2.为什么要使用Dockerfile
尽管Dockerhub已经提供了很多镜像文件,已经足够满足基础服务,但是这些镜像只是基础的系统环境,并没有符合自己在生产环境中的要求。比如nignx服务,自己的web界面,已经配置文件中的代理、负载均衡等信息,一旦开启新的环境还需要重新去配置。
Dockerfile可以解决这些问题,可以通过配置Dockerfile文件,执行一系列操作,比如将写好的访问页面文件,复制到nginx服务的站点目录下,重新生成新的镜像文件,那么,所有基于此镜像创建的容器,都默认可以访问到自定义的web界面,从而完成,访问页面,版本等迭代操作以及其它一些列操作
3.镜像加载原理
看一下镜像构图
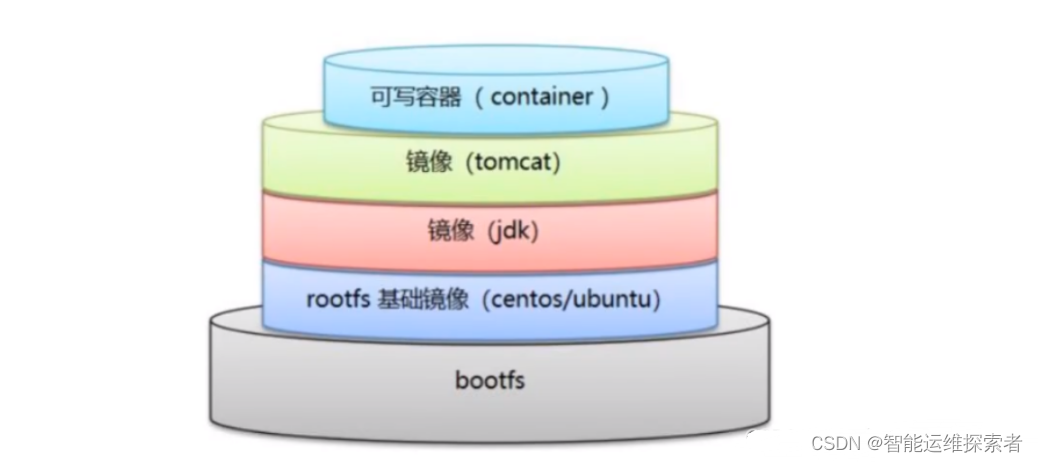
Docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统就是UnionFS。
bootfs主要包含bootloader和kernel,bootloader主要是引导加载kernel,Linux刚启动时会加载bootfs文件系统。
在Docker镜像的最底层是bootfs,这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。
rootfs,在bootfs之上。包含的就是典型Linux系统中的/dev,/proc,/bin,/etc等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,Centos等等
可以理解为,初始时内核环境中什么都没有,下载debian,此时就会生成一个基础镜像(rootfs),而后下载JDK又会在基础镜像上叠加一层镜像,形成一个新的基础镜像,也就是rootfs。此时的镜像环境为基础环境与JDK环境。再下载一个tomcat服务,又会在镜像上叠加一层镜像,依次类推。
但此时,每一层的镜像都是只读模式,不能进行写入操作,当基于镜像创建容器时,会将镜像实例化,系统会给一层或多层的rootfs之上赋予写的权限。
4.Docker工作原理
Docker镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在构建之后也不会被改变。
镜像的定制实际上就是定制每一层所添加的配置、文件。如果我们可以把每一层修改、安装、构建、操作的命令都写入一个脚本,用这个脚本来构建、定制镜像,那么镜像构建透明性的问题、体积的问题就都会解决。这个脚本就是 Dockerfile。
Dockerfile是一个文本文件,其内包含了一条条的指令(Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建。有了Dockerfile,当我们需要定制自己额外的需求时,只需在Dockerfile上添加或者修改指令,重新生成 image 即可, 省去了敲命令的麻烦。
除了手动生成Docker镜像之外,可以使用Dockerfile自动生成镜像。Dockerfile是由多条的指令组成的文件,其中每条指令对应 Linux 中的一条命令,Docker 程序将读取Dockerfile 中的指令生成指定镜像。
Dockerfile结构大致分为四个部分:基础镜像信息、维护者信息、镜像操作指令和容器启动时执行指令。Dockerfile每行支持一条指令,每条指令可携带多个参数,支持使用以“#“号开头的注释
5.Docker 镜像结构的分层
镜像不是一个单一的文件,而是有多层构成。容器其实是在镜像的最上面加了一层读写层,在运行容器里做的任何文件改动,都会写到这个读写层。如果删除了容器,也就删除了其最上面的读写层,文件改动也就丢失了。Docker使用存储驱动管理镜像每层内容及可读写层的容器层。
(1)Dockerfile 中的每个指令都会创建一个新的镜像层;
(2)镜像层将被缓存和复用;
(3)当Dockerfile 的指令修改了,复制的文件变化了,或者构建镜像时指定的变量不同了,对应的镜像层缓存就会失效;
(4)某一层的镜像缓存失效,它之后的镜像层缓存都会失效;
(5)镜像层是不可变的,如果在某一层中添加一个文件,然后在下一层中删除它,则镜像中依然会包含该文件,只是这个文件在 Docker 容器中不可见了。
6.Dokcerfile指令
| 指令 | 作用 | 语法结构 |
| FROM | 指定构建镜像的基础镜像,第一条指令必须为FROM 指令,每创建一个镜像就需要一条 FROM 指令 | FROM 镜像名称 |
| EXPOSE | 声明容器希望暴露的端口,但并不真正打开端口,容器运行时需要通过 -p 参数映射到宿主机。 | EXPOSE 端口号 |
| RUN | 执行命令并创建一个新的镜像层,通常用于安装软件包或修改系统设置 | RUN ["executable", "param1", "param2"] |
| CMD | 指定容器启动时默认执行的命令,可以被 docker run 命令的命令行参数覆盖.如果在docker run时指定了命令或者镜像中有ENTRYPOINT,那么CMD就会被覆盖。 CMD 可以为 ENTRYPOINT 指令提供默认参数。 | CMD ["cp" ,"-rf",“*”] |
| ENTRYPOINT | 类似于CMD,但不可被 docker run 的命令行参数覆盖,通常用于定义始终运行的应用程序入口点 | ENTRYPOINT ["executable", "param1", "param2"] |
| ADD | 从构建上下文目录复制新文件、存档文件(并自动解压)或从URL下载文件到镜像内部 | ADD src dest |
| ARG | 定义在构建时使用的变量 | ARG variable_name[=default_value] |
| COPY | 从构建上下文复制文件或目录到镜像内部 | COPY src dest |
| HEALTHCHECK | 定义容器健康状况检查命令 | HEALTHCHECK [OPTIONS] CMD command |
| MAINTAINER | 说明新镜像的维护人信息 | MAINTAINER 自定义信息 |
| ONBUILD | 定义触发器,当以此镜像为基础镜像构建其他镜像时,这些触发器会在子镜像构建过程中执行 | ONBUILD [INSTRUCTION] |
| ENV | 设置环境变量,可在Dockerfile中后续指令或容器运行时使用 | ENV key value |
| SHELL | 指定用于RUN、CMD和ENTRYPOINT指令的默认shell | SHELL ["executable", "param1", "param2"] |
| STOPSIGNAL | 指定停止容器时发送的信号。 | STOPSIGNAL signal |
| USER | 设置运行镜像时的默认用户身份。 | USER user[:group] |
| VOLUME | 创建数据卷,用于持久化存储数据,即使容器停止也不会丢失数据。 | VOLUME ["/data", ...] |
| WORKDIR | 设置镜像内部的工作目录,后续的RUN、CMD、COPY、ENTRYPOINT等指令都会在这个目录下执行。 | WORKDIR /path/to/workdir |
注释:
使用ADD指令将源文件复制到镜像中,源文件要与 Dockerfile 位于相同目录中,或者是一个 URL
有如下注意事项:
1、如果源路径是个文件,且目标路径是以 / 结尾, 则docker会把目标路径当作一个目录,会把源文件拷贝到该目录下。
如果目标路径不存在,则会自动创建目标路径。
/home/ky26/zhaichen.txt /home/ky26/
2、如果源路径是个文件,且目标路径是不以 / 结尾,则docker会把目标路径当作一个文件。
如果目标路径不存在,会以目标路径为名创建一个文件,内容同源文件;
如果目标文件是个存在的文件,会用源文件覆盖它,当然只是内容覆盖,文件名还是目标文件名。
如果目标文件实际是个存在的目录,则会源文件拷贝到该目录下。 注意,这种情况下,最好显示的以 / 结尾,以避免混淆。
3、如果源路径是个目录,且目标路径不存在,则docker会自动以目标路径创建一个目录,把源路径目录下的文件拷贝进来。
如果目标路径是个已经存在的目录,则docker会把源路径目录下的文件拷贝到该目录下。
4、如果源文件是个归档文件(压缩文件),则docker会自动帮解压。
URL下载和解压特性不能一起使用。任何压缩文件通过URL拷贝,都不会自动解压。
7.用Dockerfile文件生成镜像
创建Docker镜像主要通过编写Dockerfile文件以及使用 docker build 命令实现
在编写 Dockerfile 时,有严格的格式需要遵循:
●第一行必须使用 FROM 指令指明所基于的镜像名称;
●之后使用 MAINTAINER 指令说明维护该镜像的用户信息;
●然后是镜像操作相关指令,如 RUN 指令。每运行一条指令,都会给基础镜像添加新的一层。
●最后使用 CMD 指令指定启动容器时要运行的命令操作。
首先建立项目目录
mkdir -p /data/httpd/;cd /data/httpd

编写Dockerfile文件,并生成镜像
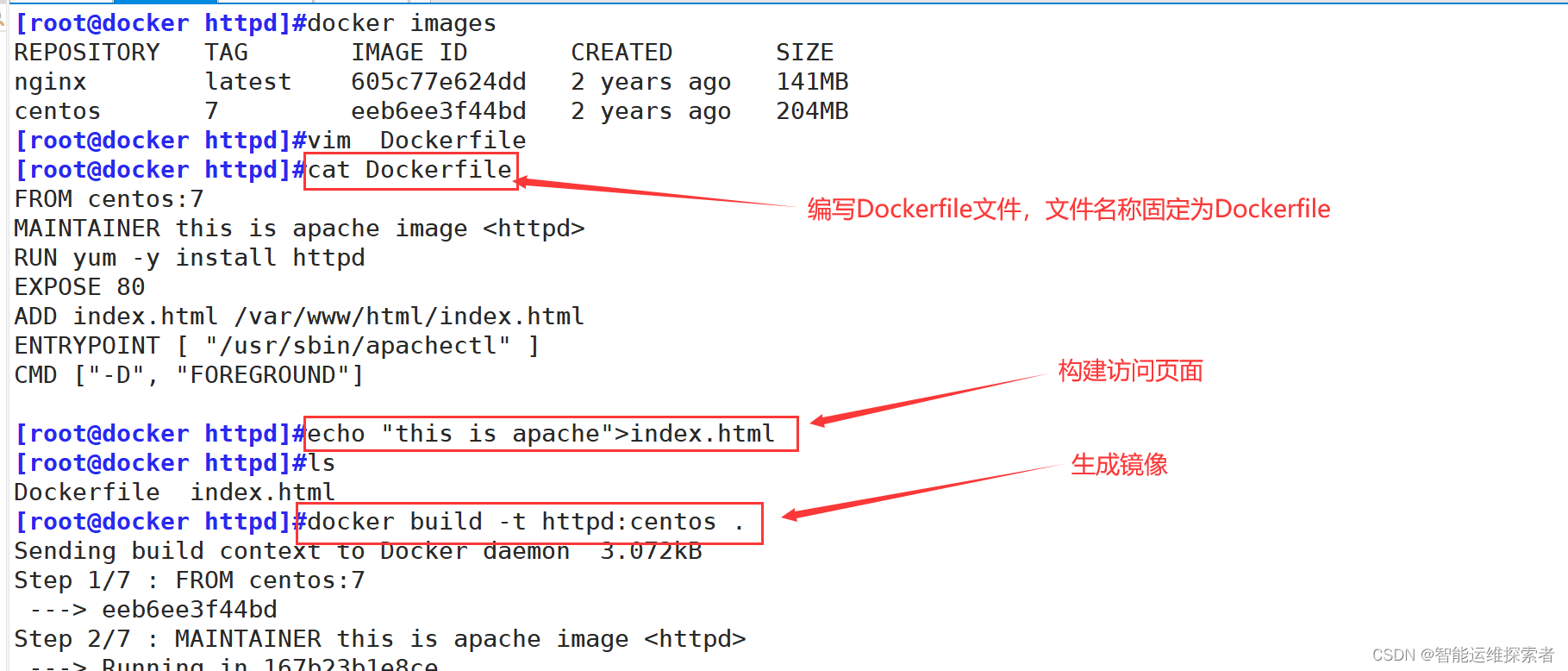
FROM centos:7
#定义了构建镜像的基础镜像为CentOS 7版本。MAINTAINER this is apache image <httpd>
#这个指令在旧版Docker中用来指定镜像的维护者及其联系方式
#新版Dockerfile中建议使用 LABEL maintainer="this is apache image <hmj>" 的形式RUN yum -y install httpd
##安装Apache HTTP服务器软件包到镜像中。EXPOSE 80
#声明该容器在运行时将会监听80端口,意味着容器内的HTTP服务对外提供服务的端口是80。
#但请注意,这并不会自动映射到宿主机端口,映射操作需要在运行容器时通过 -p 参数完成。ADD index.html /var/www/html/index.html
#将名为index.html的文件从Dockerfile所在目录复制到镜像内部的 /var/www/html/ 目录下ENTRYPOINT [ "/usr/sbin/apachectl" ]
#设置容器启动时执行的程序入口点为Apache的控制脚本/usr/sbin/apachectl。
#ENTRYPOINT通常不会被 docker run 后面的命令覆盖,除非用户在执行容器时使用--entrypoint参数。#CMD ["-D", "FOREGROUND"]:
设置容器启动时的默认命令参数,这里指示Apache在前台运行(即守护进程模式)整个Dockerfile编译完成后,会生成一个包含Apache HTTP服务器且配置为直接运行Apache并监
听80端口的自定义镜像。当运行基于此镜像的容器时,容器内会自动启动Apache服务并提供web服务运行完生成镜像的命令后,可以先查看镜像
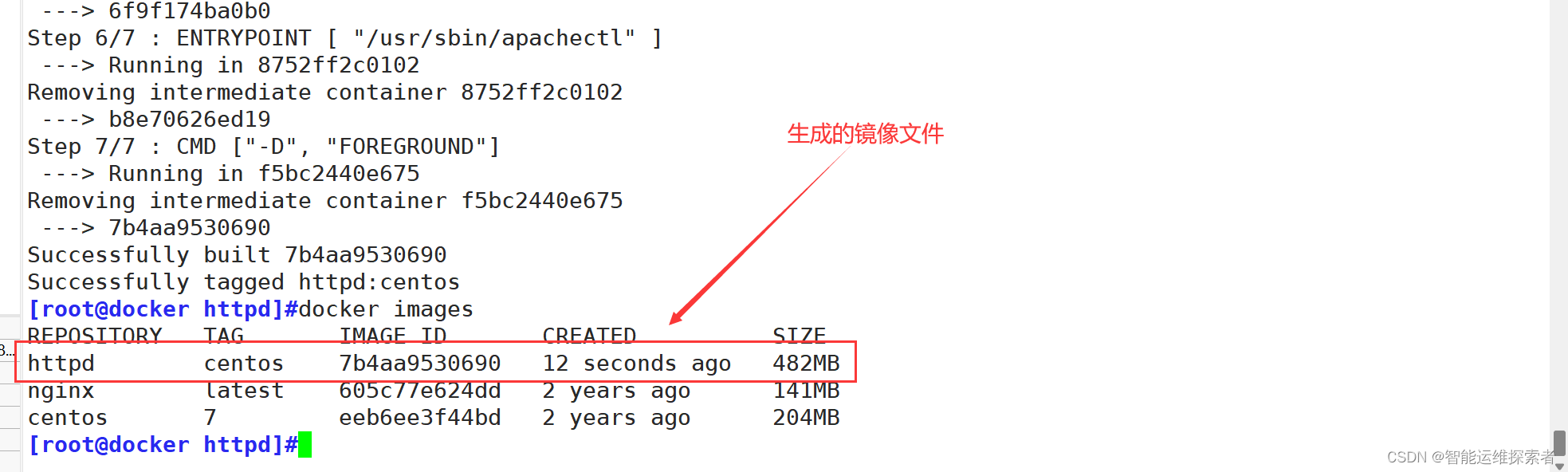
使用该镜像创建容器,并进行查看
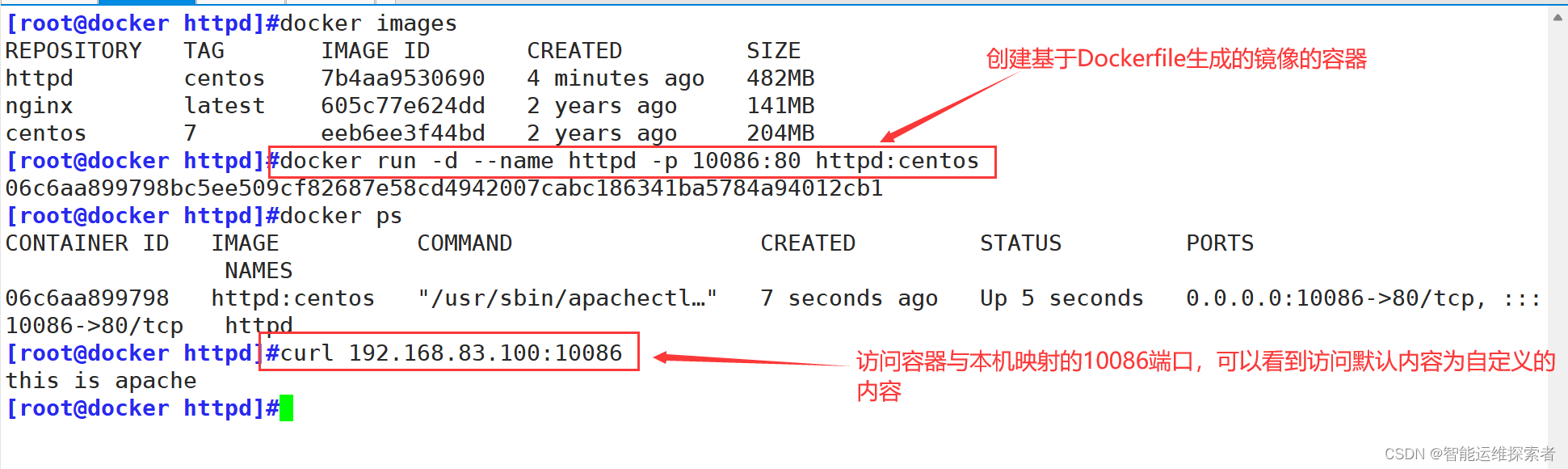
########如果有网络报错提示########
[Warning] IPv4 forwarding is disabled. Networking will not work.
解决方法:
vim /etc/sysctl.conf
net.ipv4.ip_forward=1
sysctl -p
systemctl restart network
systemctl restart docker