文章目录
- 哈希概念
- 哈希冲突
- 哈希函数
- 闭散列
- 闭散列实现
- 开散列
- 开散列实现
- 字符串Hash函数
哈希概念
因为,顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,
因此在查找一个元素时,必须要经过关键码的多次比较。
顺序查找时间复杂度为O(N),平衡树中为树的高度即O(logN)
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立
一一映射的关系,那么在查找时通过该函数可以很快找到该元素
- 插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放 - 搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置
取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,
构造出来的结构称为哈希表
集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小。
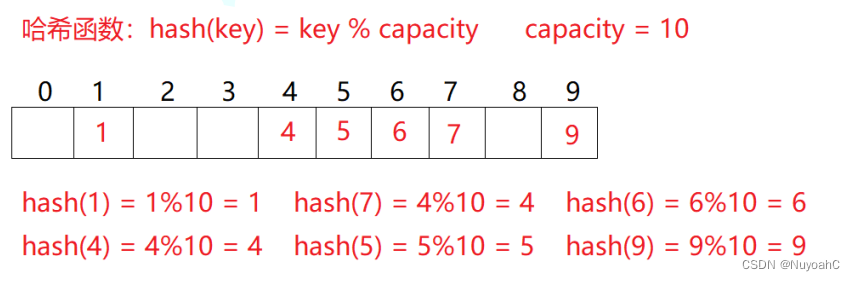
如果按照上述方式插入14会发生什么???
发现4这个位置已0经被占用了,
再映射到这个位置明显是不对的,
这就是所谓的哈希冲突。
哈希冲突
不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突。
哈希冲突如何处理呢?
哈希函数
哈希冲突的一个原因可能是:
哈希函数设计不够合理

但是无论如何设计哈希函数,
都不能完全保证不同的值映射到同一位置,
所以有了闭散列和开散列两种处理方法
闭散列
也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去,对于上述例子添加14后,14就会被放在下标为8的位置
如何寻找下一个空位置呢?
- 线性探测
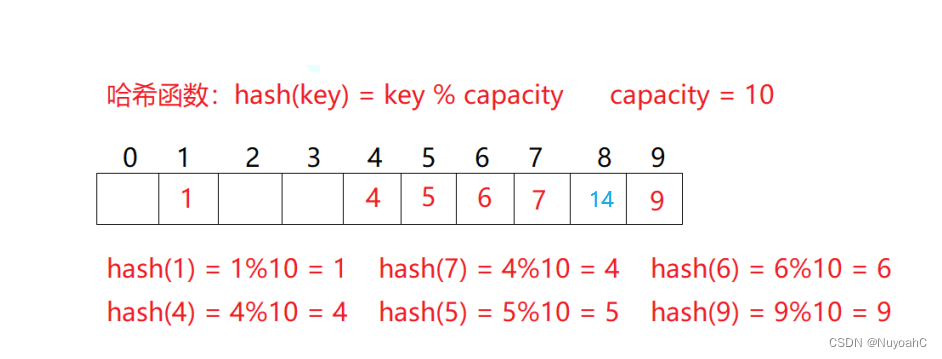
删除操作
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索;
哈希表中的元素如果只是原生数据类型,我们将4删除后,再查找4是找不到的,但是此时去查找14也会找不到,因为14本来应该映射到4位置,但是由于哈希冲突跑到了8位置.
如何解决呢?
给每一个位置加上一个状态枚举分别代表此位置是空,被删除还是有数
// EMPTY空, EXIST有元素, DELETE删除
enum State {EMPTY, EXIST, DELETE};
闭散列实现
enum State
{EMPTY, // 空EXIST, // 存在DELETE // 删除
};template <class K, class V>
struct HashData
{pair<K, V> _kv;State _state;HashData(const pair<K, V> &kv = make_pair(0, 0)): _kv(kv), _state(EMPTY){}
};template <class K>
struct HashFunc
{size_t operator()(const K &key){return key;}
};
// 模版特化
template <>
struct HashFunc<string>
{size_t operator()(const string &key){// BKDR Hash思想size_t hash = 0;for (size_t i = 0; i < key.size(); ++i){hash *= 131;hash += key[i]; // 转成整形}return hash;}
};template <class K, class V, class Hash = HashFunc<K>>
class HashTable
{
private:vector<HashData<K, V>> _table; // HashData的封装size_t _size = 0; // 存储的关键字的个数
};bool Insert(const pair<K, V> &kv)
{if (_table.size() == 0 || 10 * _size / _table.size() >= 7) // 扩容{size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;HashTable<K, V> newHT;newHT._table.resize(newSize);// 旧表的数据映射到新表for (auto e : _table){if (e._state == EXIST){newHT.insert(e._kv);}}_table.swap(newHT._table);}size_t index = kv.first % _table.size();// 线性探测while (_table[index]._state == EXIST){index++;index %= _table.size(); // 过大会重新回到起点}_table[index]._kv = kv;_table[index]._state = EXIST;_size++;return true;
}HashData<K, V> *Find(const K &key)
{if (_table.size() == 0)return nullptr;size_t index = key % _table.size(); // string类不能取模,需要一个仿函数HashFuncsize_t start = index;while (_table[index]._state != EMPTY){if (_table[index]._kv.first == key && _table[index]._state == EXIST)return &_table[index];index++;index %= _table.size();if (index == start) // 全是DELETE时,必要时会breakbreak;}return nullptr;
}bool Erase(const K &key)
{HashData<K, V> *ret = Find(key);if (ret){ret->_state = DELETE;--_size;return true;}return false;
}开散列
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
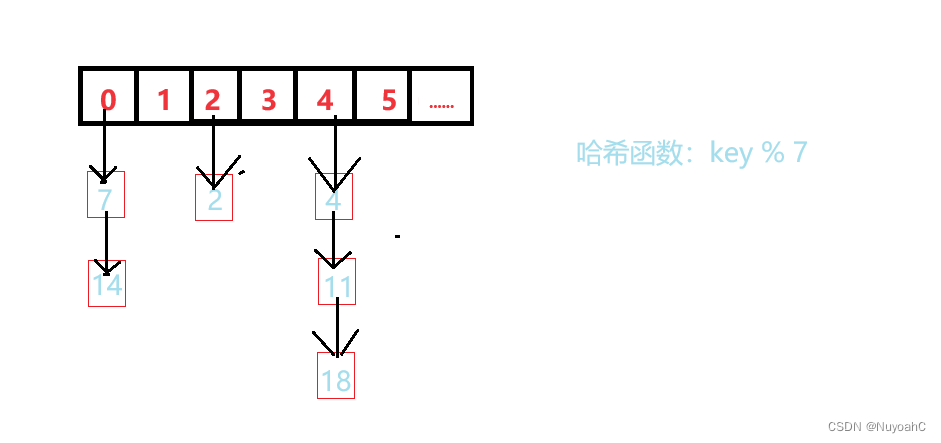
哈希桶其实是一个链表指针,其中每个桶中存放的都是发生哈希冲突的数据。

开散列实现
//HashFunc<int>
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//HashFunc<string>
template<>
struct HashFunc<string>
{size_t operator()(const string& key){// BKDRsize_t hash = 0;for (auto e : key){hash *= 31;hash += e;}cout << key << ":" << hash << endl;return hash;}
};template <class K, class V>
struct HashNode
{HashNode *_next;pair<K, V> _kv;HashNode(const pair<K, V> &kv): _kv(kv), _next(nullptr){}
};template <class K, class V, class Hash = HashFunc<K>>
class HashTable
{typedef HashNode<K, V> Node;public:HashTable(){_tables.resize(10);}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node *cur = _tables[i];while (cur){Node *next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}bool Insert(const pair<K, V> &kv){if (Find(kv.first))return false;// 负载因子最大到1if (_n == _tables.size()){size_t newSize = _tables.size() * 2;HashTable<K, V> newHT;newHT._tables.resize(newSize);// 遍历旧表for (size_t i = 0; i < _tables.size(); i++){Node *cur = _tables[i];while (cur){newHT.Insert(cur->_kv);cur = cur->_next;}}_tables.swap(newHT._tables);}size_t hashi = kv.first % _tables.size();Node *newnode = new Node(kv);// 头插newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}Node *Find(const K &key){Hash hf;size_t hashi = hf(key) % _tables.size();Node *cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return NULL;}bool Erase(const K &key){Hash hf;size_t hashi = hf(key) % _tables.size();Node *prev = nullptr;Node *cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node *> _tables;size_t _n = 0;
};
字符串Hash函数
当我们对key取模的时候如果模的不是整形那我们无法处理,这时我们使用一种字符串Hash函数将其转化为整形,例如string,如下
template<>
struct HashFunc<string>
{size_t operator()(const string& key){// BKDRsize_t hash = 0;for (auto e : key){hash *= 31;hash += e;}cout << key << ":" << hash << endl;return hash;}
};
最后,提供一篇字符串Hash函数的文章
字符串Hash函数