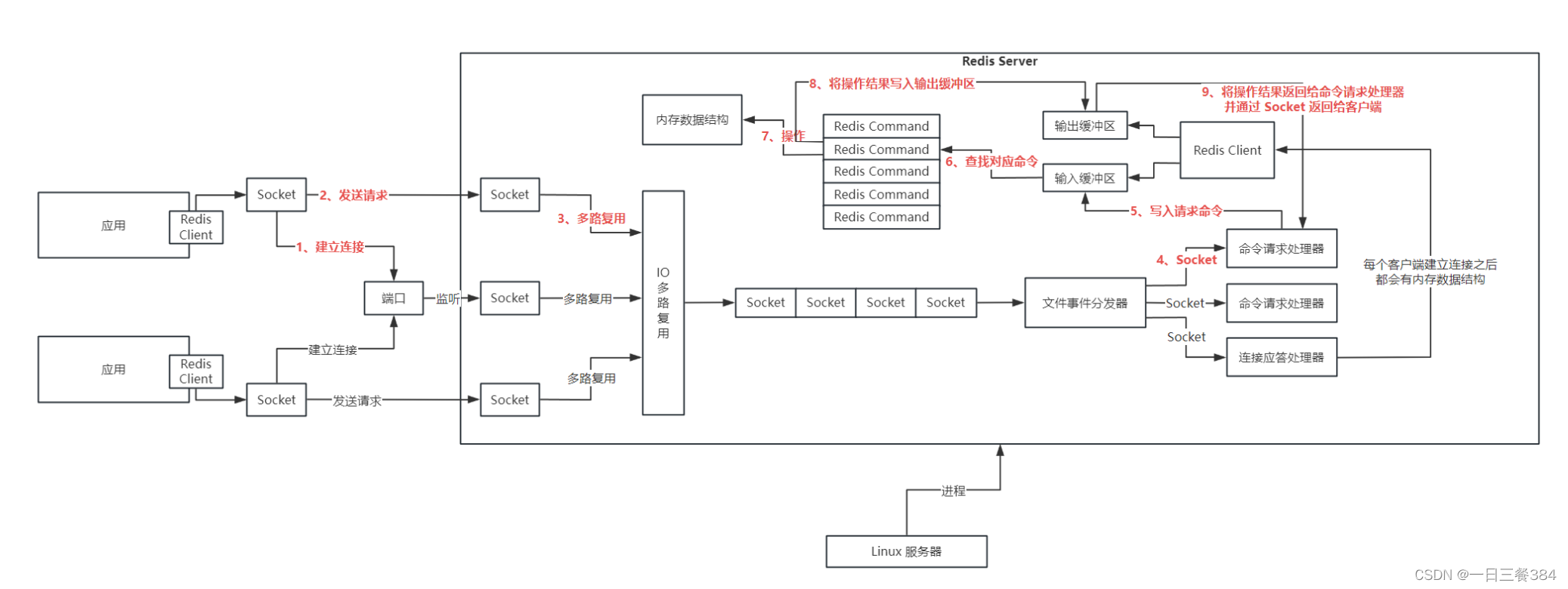
阿里开源黑白图片上色算法DDColor的部署与测试并将模型转onnx后用c++推理
文章目录
- 阿里开源黑白图片上色算法DDColor的部署与测试并将模型转onnx后用c++推理
- 简介
- 环境部署
- 下载源码
- 安装环境
- 下载模型
- 测试一下
- 看看效果
- 模型转onnx
- 测试一下生成的onnx模型
- 看看效果
- C++ 推理
简介
DDColor是一种基于深度学习的图像上色技术,它利用卷积神经网络(CNN)对黑白图像进行上色处理。该模型通常包含一个编码器和一个解码器,编码器提取图像的特征,解码器则根据这些特征生成颜色。DDColor模型能够处理多种类型的图像,并生成自然且逼真的颜色效果。它在图像编辑、电影后期制作以及历史照片修复等领域有广泛的应用。
环境部署
下载源码
git clone https://github.com/piddnad/DDColor.git
安装环境
conda create -n ddcolor python=3.9
conda activate ddcolor
pip install -r requirements.txt
python3 setup.py develop
pip install modelscope
pip install onnx
pip install onnxruntime
下载模型
这里下载
或者运行下面的脚本下载:
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('damo/cv_ddcolor_image-colorization', cache_dir='./modelscope')
print('model assets saved to %s'%model_dir)
#模型会被下载到modelscope/damo/cv_ddcolor_image-colorization/pytorch_model.pt
测试一下
import argparse
import cv2
import numpy as np
import os
from tqdm import tqdm
import torch
from basicsr.archs.ddcolor_arch import DDColor
import torch.nn.functional as Fclass ImageColorizationPipeline(object):def __init__(self, model_path, input_size=256, model_size='large'):self.input_size = input_sizeif torch.cuda.is_available():self.device = torch.device('cuda')else:self.device = torch.device('cpu')if model_size == 'tiny':self.encoder_name = 'convnext-t'else:self.encoder_name = 'convnext-l'self.decoder_type = "MultiScaleColorDecoder"if self.decoder_type == 'MultiScaleColorDecoder':self.model = DDColor(encoder_name=self.encoder_name,decoder_name='MultiScaleColorDecoder',input_size=[self.input_size, self.input_size],num_output_channels=2,last_norm='Spectral',do_normalize=False,num_queries=100,num_scales=3,dec_layers=9,).to(self.device)else:self.model = DDColor(encoder_name=self.encoder_name,decoder_name='SingleColorDecoder',input_size=[self.input_size, self.input_size],num_output_channels=2,last_norm='Spectral',do_normalize=False,num_queries=256,).to(self.device)self.model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu'))['params'],strict=False)self.model.eval()@torch.no_grad()def process(self, img):self.height, self.width = img.shape[:2]# print(self.width, self.height)# if self.width * self.height < 100000:# self.input_size = 256img = (img / 255.0).astype(np.float32)orig_l = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)[:, :, :1] # (h, w, 1)# resize rgb image -> lab -> get grey -> rgbimg = cv2.resize(img, (self.input_size, self.input_size))img_l = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)[:, :, :1]img_gray_lab = np.concatenate((img_l, np.zeros_like(img_l), np.zeros_like(img_l)), axis=-1)img_gray_rgb = cv2.cvtColor(img_gray_lab, cv2.COLOR_LAB2RGB)tensor_gray_rgb = torch.from_numpy(img_gray_rgb.transpose((2, 0, 1))).float().unsqueeze(0).to(self.device)# (1, 2, self.height, self.width)output_ab = self.model(tensor_gray_rgb).cpu()# resize ab -> concat original l -> rgboutput_ab_resize = F.interpolate(output_ab, size=(self.height, self.width))[0].float().numpy().transpose(1, 2, 0)output_lab = np.concatenate((orig_l, output_ab_resize), axis=-1)output_bgr = cv2.cvtColor(output_lab, cv2.COLOR_LAB2BGR)output_img = (output_bgr * 255.0).round().astype(np.uint8)return output_imgdef main():parser = argparse.ArgumentParser()parser.add_argument('--model_path', type=str,default='pretrain/net_g_200000.pth')parser.add_argument('--input_size', type=int,default=512, help='input size for model')parser.add_argument('--model_size', type=str,default='large', help='ddcolor model size')args = parser.parse_args()colorizer = ImageColorizationPipeline(model_path=args.model_path, input_size=args.input_size, model_size=args.model_size)img = cv2.imread("./down.jpg")image_out = colorizer.process(img)cv2.imwrite("./downout.jpg", image_out)if __name__ == '__main__':main()python test.py --model_path=./modelscope/damo/cv_ddcolor_image-colorization/pytorch_model.pt
看看效果


效果看起来非常的nice!
模型转onnx
import argparse
import cv2
import numpy as np
import os
from tqdm import tqdm
import torch
from basicsr.archs.ddcolor_arch import DDColor
import torch.nn.functional as Fclass ImageColorizationPipeline(object):def __init__(self, model_path, input_size=256, model_size='large'):self.input_size = input_sizeif torch.cuda.is_available():self.device = torch.device('cuda')else:self.device = torch.device('cpu')if model_size == 'tiny':self.encoder_name = 'convnext-t'else:self.encoder_name = 'convnext-l'self.decoder_type = "MultiScaleColorDecoder"if self.decoder_type == 'MultiScaleColorDecoder':self.model = DDColor(encoder_name=self.encoder_name,decoder_name='MultiScaleColorDecoder',input_size=[self.input_size, self.input_size],num_output_channels=2,last_norm='Spectral',do_normalize=False,num_queries=100,num_scales=3,dec_layers=9,).to(self.device)else:self.model = DDColor(encoder_name=self.encoder_name,decoder_name='SingleColorDecoder',input_size=[self.input_size, self.input_size],num_output_channels=2,last_norm='Spectral',do_normalize=False,num_queries=256,).to(self.device)print(model_path)self.model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu'))['params'],strict=False)self.model.eval()@torch.no_grad()def process(self, img):self.height, self.width = img.shape[:2]# print(self.width, self.height)# if self.width * self.height < 100000:# self.input_size = 256img = (img / 255.0).astype(np.float32)orig_l = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)[:, :, :1] # (h, w, 1)# resize rgb image -> lab -> get grey -> rgbimg = cv2.resize(img, (self.input_size, self.input_size))img_l = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)[:, :, :1]img_gray_lab = np.concatenate((img_l, np.zeros_like(img_l), np.zeros_like(img_l)), axis=-1)img_gray_rgb = cv2.cvtColor(img_gray_lab, cv2.COLOR_LAB2RGB)tensor_gray_rgb = torch.from_numpy(img_gray_rgb.transpose((2, 0, 1))).float().unsqueeze(0).to(self.device)output_ab = self.model(tensor_gray_rgb).cpu() # (1, 2, self.height, self.width)# resize ab -> concat original l -> rgboutput_ab_resize = F.interpolate(output_ab, size=(self.height, self.width))[0].float().numpy().transpose(1, 2, 0)output_lab = np.concatenate((orig_l, output_ab_resize), axis=-1)output_bgr = cv2.cvtColor(output_lab, cv2.COLOR_LAB2BGR)output_img = (output_bgr * 255.0).round().astype(np.uint8) return output_img@torch.no_grad()def expirt_onnx(self, img):self.height, self.width = img.shape[:2]img = (img / 255.0).astype(np.float32)orig_l = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)[:, :, :1] # (h, w, 1)# resize rgb image -> lab -> get grey -> rgbimg = cv2.resize(img, (self.input_size, self.input_size))img_l = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)[:, :, :1]img_gray_lab = np.concatenate((img_l, np.zeros_like(img_l), np.zeros_like(img_l)), axis=-1)img_gray_rgb = cv2.cvtColor(img_gray_lab, cv2.COLOR_LAB2RGB)tensor_gray_rgb = torch.from_numpy(img_gray_rgb.transpose((2, 0, 1))).float().unsqueeze(0).to(self.device)mymodel = self.model.to('cpu')tensor_gray_rgb = tensor_gray_rgb.to('cpu')onnx_save_path = "color.onnx"torch.onnx.export(mymodel, # 要导出的模型tensor_gray_rgb, # 模型的输入onnx_save_path, # 导出的文件路径export_params=True, # 是否将训练参数导出opset_version=12, # 导出的ONNX的操作集版本do_constant_folding=True, # 是否执行常量折叠优化input_names=['input'], # 输入张量的名称output_names=['output'], # 输出张量的名称dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}})returndef main():parser = argparse.ArgumentParser()parser.add_argument('--model_path', type=str, default='pretrain/net_g_200000.pth')parser.add_argument('--input_size', type=int, default=512, help='input size for model')parser.add_argument('--model_size', type=str, default='large', help='ddcolor model size')args = parser.parse_args()colorizer = ImageColorizationPipeline(model_path=args.model_path, input_size=args.input_size, model_size=args.model_size)img = cv2.imread("./down.jpg")image_out = colorizer.expirt_onnx(img)# image_out = colorizer.process(img)# cv2.imwrite("./downout.jpg", image_out)if __name__ == '__main__':main()python model2onnx.py --model_path=./modelscope/damo/cv_ddcolor_image-colorization/pytorch_model.pt
测试一下生成的onnx模型
import onnxruntime
import cv2
import numpy as npdef colorize_image(input_image_path, output_image_path, model_path):input_image = cv2.imread(input_image_path)img = (input_image / 255.0).astype(np.float32)orig_l = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)[:, :, :1] # (h, w, 1)img = cv2.resize(img, (512, 512))img_l = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)[:, :, :1]img_gray_lab = np.concatenate((img_l, np.zeros_like(img_l), np.zeros_like(img_l)), axis=-1)input_blob = cv2.cvtColor(img_gray_lab, cv2.COLOR_LAB2RGB)# Change data layout from HWC to CHWinput_blob = np.transpose(input_blob, (2, 0, 1))input_blob = np.expand_dims(input_blob, axis=0) # Add batch dimension# Initialize ONNX Runtime Inference Sessionsession = onnxruntime.InferenceSession(model_path)# Perform inferenceoutput_blob = session.run(None, {'input': input_blob})[0]# Post-process the outputoutput_blob = np.squeeze(output_blob) # Remove batch dimension# Separate ab channels# Change data layout from CHW to HWCoutput_ab = output_blob.transpose((1, 2, 0))# Resize to match input image sizeoutput_ab = cv2.resize(output_ab, (input_image.shape[1], input_image.shape[0]))output_lab = np.concatenate((orig_l, output_ab), axis=-1)# Convert LAB to BGRoutput_bgr = cv2.cvtColor(output_lab, cv2.COLOR_LAB2BGR)output_bgr = output_bgr*255# Save the colorized imagecv2.imwrite(output_image_path, output_bgr)# Define paths
input_image_path = 'down.jpg'
output_image_path = 'downout2.jpg'
model_path = 'color.onnx'# Perform colorization
colorize_image(input_image_path, output_image_path, model_path)python testonnx.py
看看效果

嗯,模型没有问题,下面开始用c++推理
C++ 推理
#pragma once
#include <iostream>
#include <assert.h>
#include <vector>
#include <onnxruntime_cxx_api.h>
#include <opencv2/opencv.hpp>namespace LIANGBAIKAI_BASE_MODEL_NAME
{class ONNX_DDcolor{public:ONNX_DDcolor() : session(nullptr){};virtual ~ONNX_DDcolor() = default;/*初始化* @param model_path 模型* @param gpu_id 选择用那块GPU*/void Init(const char *model_path, int gpu_id = 0){env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, "ONNX_DDcolor");Ort::SessionOptions session_options;// 使用五个线程执行op,提升速度session_options.SetIntraOpNumThreads(5);session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);if (gpu_id >= 0){OrtCUDAProviderOptions cuda_option;cuda_option.device_id = gpu_id;session_options.AppendExecutionProvider_CUDA(cuda_option);}session = Ort::Session(env, model_path, session_options);return;}/**执行模型推理* @param src : 输入图* @param inputid : 输入id* @param outputid : 输出的id* @return 输出结果图*/cv::Mat Run(cv::Mat src, unsigned inputid = 0, unsigned outputid = 0, bool show_log = false){cv::Mat img;src.convertTo(img, CV_32FC3, 1.0/255.0);// 拷贝图片并将图片由 BGR 转为 LAB,分离出L通道cv::Mat orig_lab;cv::cvtColor(img, orig_lab, cv::COLOR_BGR2Lab);cv::Mat orig_l = orig_lab.clone();cv::extractChannel(orig_lab, orig_l, 0); // 分离出 L 通道cv::resize(img, img, cv::Size(512, 512));//将图片由RGB转为Lab,然后将ab通道用同尺寸的0矩阵代替,最后再将图片转回rgbcv::Mat img_lab;cv::cvtColor(img, img_lab, cv::COLOR_BGR2Lab);std::vector<cv::Mat> lab_planes;cv::split(img_lab, lab_planes);cv::Mat img_gray_lab = cv::Mat::zeros(img_lab.rows, img_lab.cols, CV_32FC3);std::vector<cv::Mat> img_channels = {lab_planes[0], cv::Mat::zeros(img_lab.rows, img_lab.cols, CV_32F), cv::Mat::zeros(img_lab.rows, img_lab.cols, CV_32F)};cv::merge(img_channels, img_gray_lab);// Convert LAB to RGBcv::Mat input_blob;cv::cvtColor(img_gray_lab, input_blob, cv::COLOR_Lab2RGB);//将input_blob送入神经网络输入,进行推理int64_t H = input_blob.rows;int64_t W = input_blob.cols;cv::Mat blob;cv::dnn::blobFromImage(input_blob, blob, 1.0 , cv::Size(W, H), cv::Scalar(0, 0, 0), false, true);// 创建tensorsize_t input_tensor_size = blob.total();std::vector<float> input_tensor_values(input_tensor_size);// overwrite input dimsstd::vector<int64_t> input_node_dims = GetInputOrOutputShape("input", inputid, show_log);input_node_dims[0] = 1;input_node_dims[2] = W;input_node_dims[3] = H;for (size_t i = 0; i < input_tensor_size; ++i){input_tensor_values[i] = blob.at<float>(i);// std::cout <<" " << input_tensor_values[i] ;}// std::cout << std::endl;// 查看输入的shapeif (show_log){std::cout << "shape:";for (auto &i : input_node_dims){std::cout << " " << i;}std::cout << std::endl;std::cout << "input_tensor_size: " << input_tensor_size << std::endl;}auto memory_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);auto input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_tensor_values.data(), input_tensor_size, input_node_dims.data(), input_node_dims.size());std::string input_name = GetInputOrOutputName("input", inputid, show_log);std::string output_name = GetInputOrOutputName("output", outputid, show_log);const char *inputname[] = {input_name.c_str()}; // 输入节点名const char *outputname[] = {output_name.c_str()}; // 输出节点名std::vector<Ort::Value> output_tensor = session.Run(Ort::RunOptions{nullptr}, inputname, &input_tensor, 1, outputname, 1);if (show_log){// 显示有几个输出的结果std::cout << "output_tensor_size: " << output_tensor.size() << std::endl;}// 获取output的shapeOrt::TensorTypeAndShapeInfo shape_info = output_tensor[0].GetTensorTypeAndShapeInfo();// 获取output的dimsize_t dim_count = shape_info.GetDimensionsCount();if (show_log){std::cout << dim_count << std::endl;}auto shape = shape_info.GetShape();if (show_log){// 显示输出的shape信息std::cout << "shape: ";for (auto &i : shape){std::cout << i << " ";}std::cout << std::endl;}// 取output数据float *f = output_tensor[0].GetTensorMutableData<float>();int output_width = shape[2];int output_height = shape[3];int size_pic = output_width * output_height;cv::Mat fin_img;std::vector<cv::Mat> abChannels(2);abChannels[0] = cv::Mat(output_height, output_width, CV_32FC1, f);abChannels[1] = cv::Mat(output_height, output_width, CV_32FC1, f + size_pic);merge(abChannels, fin_img);cv::Mat output_ab;cv::resize(fin_img, output_ab, cv::Size(src.cols, src.rows));// Concatenate L and ab channelsstd::vector<cv::Mat> output_channels = {orig_l, output_ab};cv::Mat output_lab;cv::merge(output_channels, output_lab);// Convert LAB to BGRcv::Mat output_bgr;cv::cvtColor(output_lab, output_bgr, cv::COLOR_Lab2BGR);output_bgr.convertTo(output_bgr, CV_8UC3, 255);return output_bgr;}private:/*获取模型的inputname 或者 outputname* @param input_or_output 选择要获取的是input还是output* @param id 选择要返回的是第几个name* @param show_log 是否打印信息* @return 返回name*/std::string GetInputOrOutputName(std::string input_or_output = "input", unsigned id = 0, bool show_log = false){size_t num_input_nodes = session.GetInputCount();size_t num_output_nodes = session.GetOutputCount();if (show_log){// 显示模型有几个输入几个输出std::cout << "num_input_nodes:" << num_input_nodes << std::endl;std::cout << "num_output_nodes:" << num_output_nodes << std::endl;}std::vector<const char *> input_node_names(num_input_nodes);std::vector<const char *> output_node_names(num_output_nodes);Ort::AllocatorWithDefaultOptions allocator;std::string name;if (input_or_output == "input"){Ort::AllocatedStringPtr input_name_Ptr = session.GetInputNameAllocated(id, allocator);name = input_name_Ptr.get();}else{auto output_name_Ptr = session.GetOutputNameAllocated(id, allocator);name = output_name_Ptr.get();}if (show_log){std::cout << "name:" << name << std::endl;}return name;}/*获取模型的input或者output的shape信息* @param input_or_output 选择要获取的是input还是output* @param id 选择要返回的是第几个shape* @param show_log 是否打印信息* @return 返回shape信息*/std::vector<int64_t> GetInputOrOutputShape(std::string input_or_output = "input", unsigned id = 0, bool show_log = false){std::vector<int64_t> shape;if (input_or_output == "input"){Ort::TypeInfo type_info = session.GetInputTypeInfo(id);auto tensor_info = type_info.GetTensorTypeAndShapeInfo();// 得到输入节点的数据类型ONNXTensorElementDataType type = tensor_info.GetElementType();if (show_log){std::cout << "input_type: " << type << std::endl;}shape = tensor_info.GetShape();if (show_log){std::cout << "intput shape:";for (auto &i : shape){std::cout << " " << i;}std::cout << std::endl;}}else{Ort::TypeInfo type_info_out = session.GetOutputTypeInfo(id);auto tensor_info_out = type_info_out.GetTensorTypeAndShapeInfo();// 得到输出节点的数据类型ONNXTensorElementDataType type_out = tensor_info_out.GetElementType();if (show_log){std::cout << "output type: " << type_out << std::endl;}// 得到输出节点的输入维度 std::vector<int64_t>shape = tensor_info_out.GetShape();if (show_log){std::cout << "output shape:";for (auto &i : shape){std::cout << " " << i;}std::cout << std::endl;}}return shape;}mutable Ort::Session session;Ort::Env env; };}
测试没有问题,成功!


![[iOS]组件化开发](https://img-blog.csdnimg.cn/direct/f37a3b1d57174d01ae104218fa1b11d3.png)