近期,OpenAI 在语音领域又带给我们惊喜,通过文本输入以及一段 15 秒的音频示例,可以生成既自然又与原声极为接近的语音。值得注意的是,即使是小模型,只需一个 15 秒的样本,也能创造出富有情感且逼真的声音。OpenAI 将这个语音引擎命名为 Voice Engine,近期 Voice Engine 预览版首次亮相。

除此之外,OpenAI还特别强调了语音引擎在支持非语言个体方面的独特能力。它能为这些个体提供个性化的、非机械化的声音,为那些有语言障碍或学习需求的人提供治疗和教育方面的帮助。
01 语音大模型需要什么样的数据?
1. 语音数据
语音数据是最重要的,而且是海量的语音数据。这些语音数据需要涵盖各种方言、口音、语调、语速和环境噪音,以确保语音大模型能够在多种情况下有效工作。
2. 语音转写文本数据
语音识别系统需要对应的文本数据来训练其识别算法。文本数据应与录音的语音内容相匹配,即语音转写文本。
3. 发音词典
这是一个将单词转换为音标(表示其发音)的字典,对于语音识别和语音合成都非常重要。
在语音识别领域,数据的质量直接影响到模型的识别准确率和泛化能力。高质量语音精标数据可以帮助语音大模型更好地学习和泛化到现实世界的各种场景。

02 语音大模型需要多语种多方言的精标数据
中国的语言环境呈现出一种独特而复杂的多样性,这种多样性不仅是语言本身的丰富性的体现,也是其深厚文化历史底蕴的一种反映。在普通话成为全国性官方语言的同时,各地的方言和地方口音依旧扎根于人们的日常生活中,它们携带着地域的特色和历史的印迹,为语音识别技术的发展带来了挑战。
为了构建能够有效识别这些不同语言变体的模型,就需要获取广泛而深入的数据,这意味着不仅要涉及北方的官话、南方的吴语、粤语、闽南语等主要方言,还要覆盖更多地区特色明显的小众方言。此外,不同年龄、性别和教育背景的人群也会展现出不同的语音特征,这也一定程度增加了数据获取的难度。
采集数据后就需要对语音数据的进行标注。语音数据的标注不仅仅是简单的文字转写,更包括对语速、语调、停顿以及口音的精确描述。只有这样,训练出的模型才能在实际应用中展现出对各种语音变体的高度敏感性和强大的识别能力,从而使语音大模型更好地适应中国复杂的语言环境,让科技更好地服务于社会和文化的多样性。
03 语音大模型的高质量数据在这里
近期,海天瑞声推出专为语音大模型定制的万人方言语音精标数据集。该数据集覆盖中国26个省份的29,954名方言发音人,从12到75岁的年龄段,总时长34,073小时,平均录音时长近60分钟,男女比例均衡。话题覆盖非常广泛,包括新闻、短信、车控、音乐、通用、地图、日常口语、家庭、健康、旅游、工作、社交、名人、天气等生活常见话题。此外,该数据集包含朗读文本和自由对话,用于提升语音大模型在中国方言方面的识别、生成等处理能力。
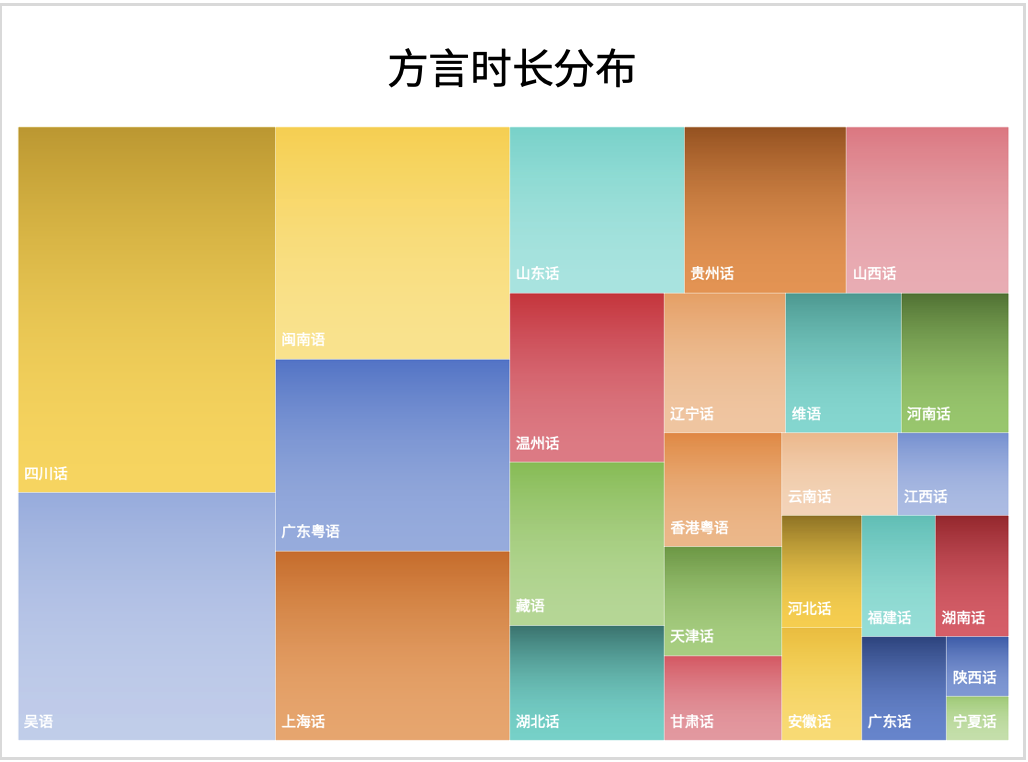
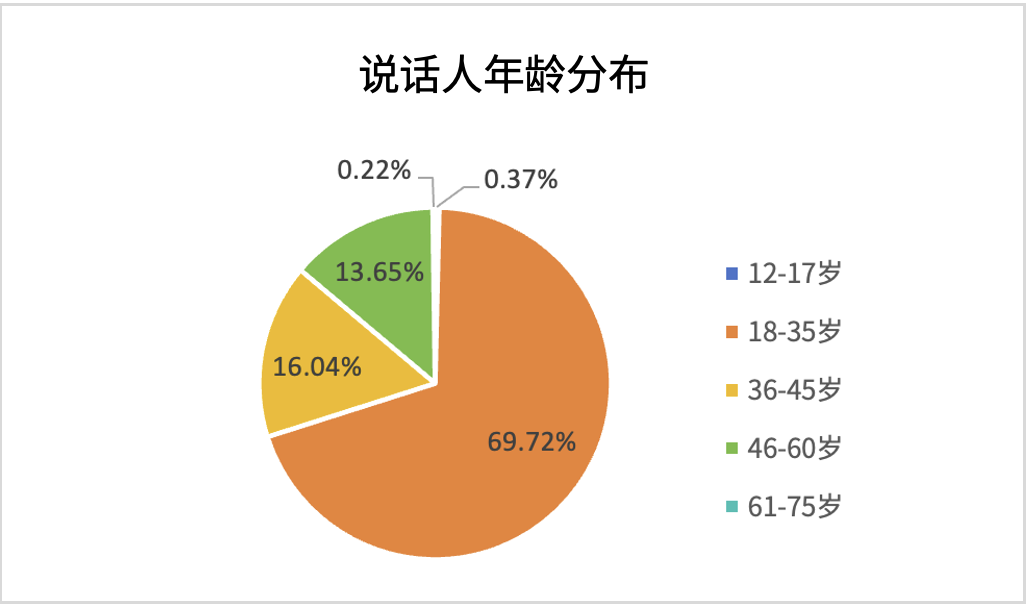
欢迎联系我们获取万人方言精标语音数据集样例
电话咨询:400-679-7787
邮件咨询:contact@dataoceanai.com