在这篇文章初识网络中,我介绍了关于计算机网络的相关知识,以及在这两篇文章中Socket编程和Socket编程——tcp,介绍了使用套接字在两种协议下的网络间通信方式。本篇文章中我将会进一步介绍网络中网络协议的部分,而这将会从应用层开始。
1. 应用层协议以及序列化的引入
我们知道两台机器能够在网络上进行通信,主要的原因就是两台主机都遵守网络协议,而我们也知道网络协议本质上就是一种约定,体现到计算机中那就是,网络协议就是一个结构化的字段。
就比如我们现在在一个聊天软件上发消息,那么这个消息会携带三个内容:发出消息的用户昵称、发出消息的时间以及消息内容,那我们要将这个数据在网络上从一台主机发送到另一台主机这三个部分是一个一个的发吗?现在看似好像合理,确实可以一个一个的往过发,但是假如发送的消息很多呢?接收方如何知道哪个昵称对应哪个消息内容以及时间,所以在发送这三个内容时,必定是以整体发送的,在计算机中我们可以将这三个内容放在一个结构化字段中:
struct Message
{char nickname[128];char msg[1024];char time[128];
};
然后我们把这个结构体声明在服务端和客户端中,这样当一个服务端进行转发消息时,服务端和客户端都能知道接收到的消息该如何使用。这就是处在应用层的网络协议。
但是这样的作法还是具有局限性,对于上面的这个结构体,它不具有跨平台性,比如Linux和Windows下这个结构体可能大小不一样,或者直接就是服务端所使用的语言和客户端使用的语言不一样,这导致客户端就根本不认识这个结构体,那么当客户端接收到这么一个报文时,在应用层根本无法使用这个报文,所以我们建议在将这种结构化字段在网络上发送时以字符串(字节流)的方式发送数据比如这个结构体我们可以这样"nickname-msg-time"中间以横杠分割,字节流在任何平台上都是可以被正确识别的,现在我们只要规定这个字节流如何读取(也就是制定好协议),那么服务端和客户端就算是不同平台也能正常进行网络通信了。
上面这种将结构化字段转化为字节流的过程叫做序列化,将字节流再转变为结构化字段时,叫做反序列化。
将网络上传输的数据在用户层中变成结构化字段的原因是为了便于用户处理这些信息。
而真正在网络上传输需要将结构化字段进行序列化是为了便于网络传输,以及支持跨平台。
需要注意的是,在网络协议的其他层中操作系统发送网络数据仍然是固定大小的结构体,而它不需要进行序列化然后再进行网络传输的原因是那几层协议很长时间才会迭代一次,而应用层协议的迭代是很快的(比如我现在就要往Message结构体中添加头像字段),所以我们需要通过使用序列化结构化字段来让网络传输变得更方便。
现在我将会使用tcp协议的套接字实现一个简易版的计算器,来更好的认识应用层协议,以及会引入更加规范的应用层协议的制定方法。
2. 套接字接口的封装
在此之前,我先要对套接字接口进行封装以为了更方便的使用它们(对tcp协议相关接口)。
我们知道在tcp协议下使用套接字接口会使用到这些接口:
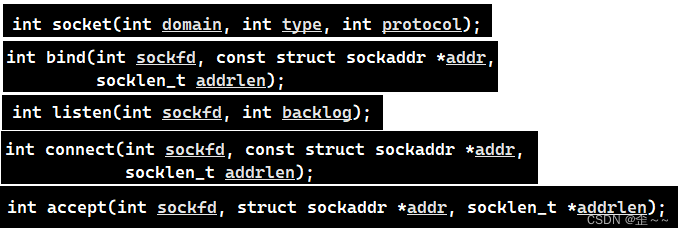
我们也知道在服务端进行bind时时需要固定IP的,只需要一个端口号,客户端不需要显式bind,客户端会在connect时进行bind随机端口。
所以我们可以对这些接口进行封装:
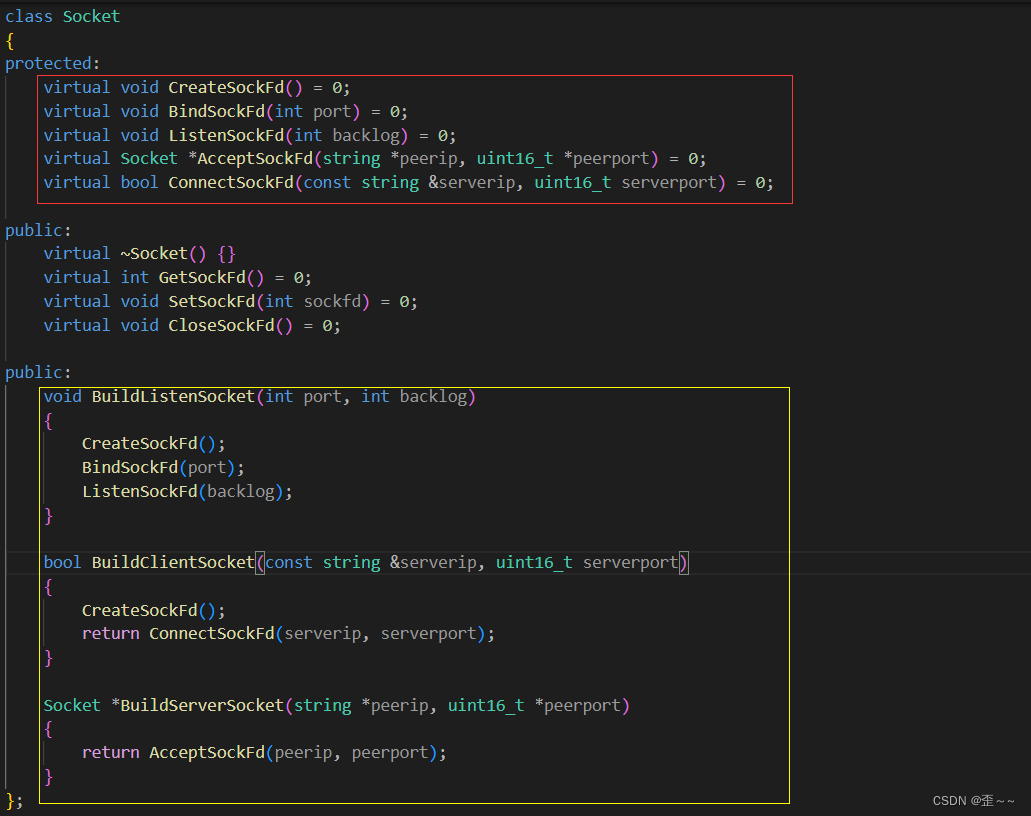
在这里我们定义了一个Socket类,是一个抽象类,而我们将tcp所使用的接口设置为纯虚函数,让子类来进行实现,以黄框中的函数作为骨架,让整体的执行逻辑不变,而只在底部对纯虚函数进行重写。这样的设计模式就是模板方法类:它在父类中定义了一个算法的框架,允许子类在不改变算法结构的情况下重新定义算法的某些特定步骤。
所以我们只需要继承这个抽象类然后对其中的纯虚函数进行重写来实现我们的tcp套接字就可以了:
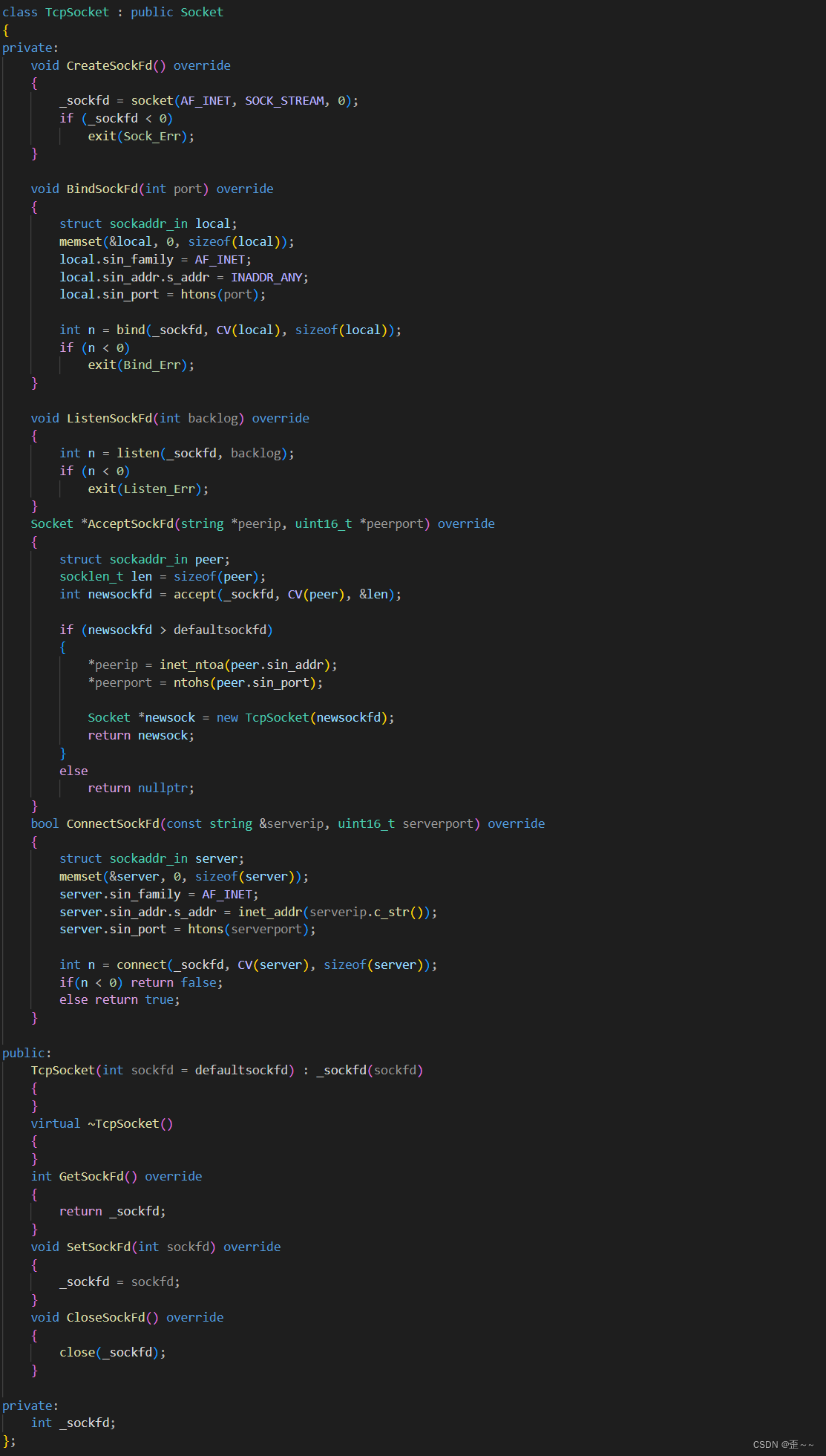
至此我们的tcp套接字接口就编写好了,接下来我们就可以开始构建服务端的服务了。
3. 服务端
作为使用tcp协议的服务端,我们应该有一个端口号和一个监听的socket文件:
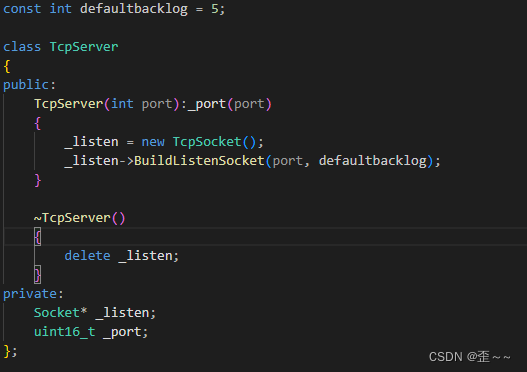
现在就是我们的服务的主要逻辑了:
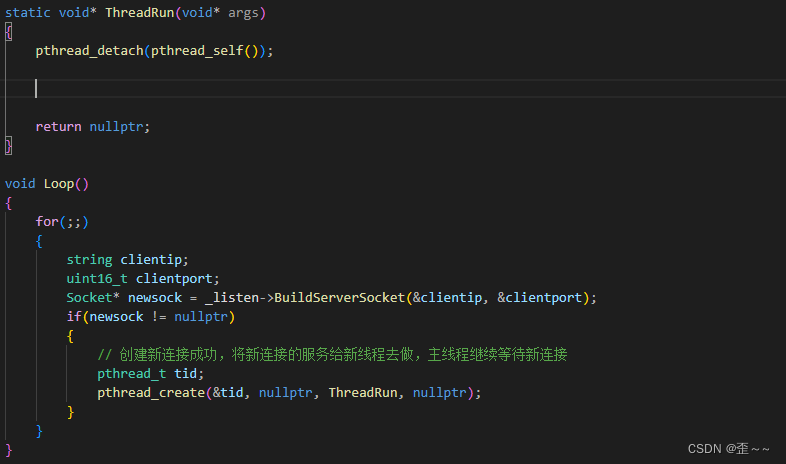
我们的新连接进入新线程之后,我们的连接中一定要有要执行的业务,那么这个业务我们想从TcpServer的外部也就是回调的方法,实现建立连接和提供给客户端服务进行解耦。而且提供服务我们的可执行业务一定要具备读写网络数据的能力,也就是得需要新连接的文件描述符,这里我们对文件描述符进行了封装所以我们这里需要将newsock传过去:
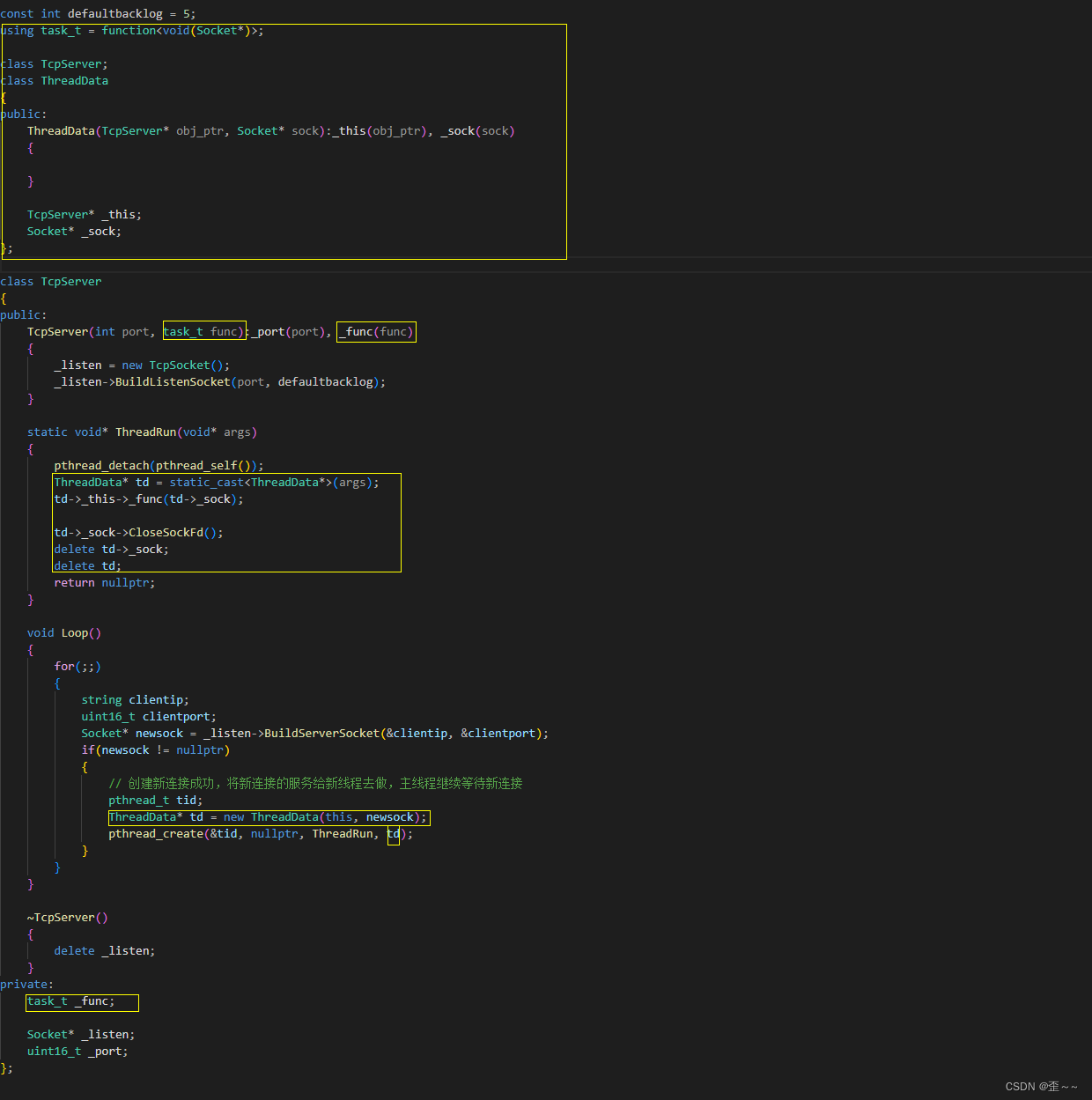
接下来我们就需要来编写服务端的主函数了:
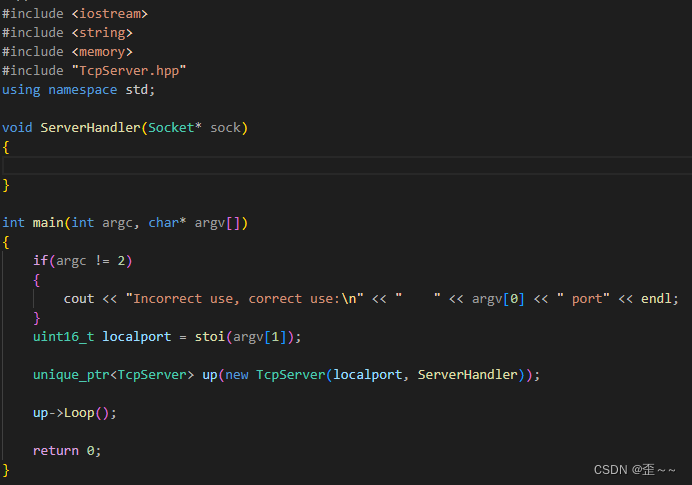
4. 业务编写
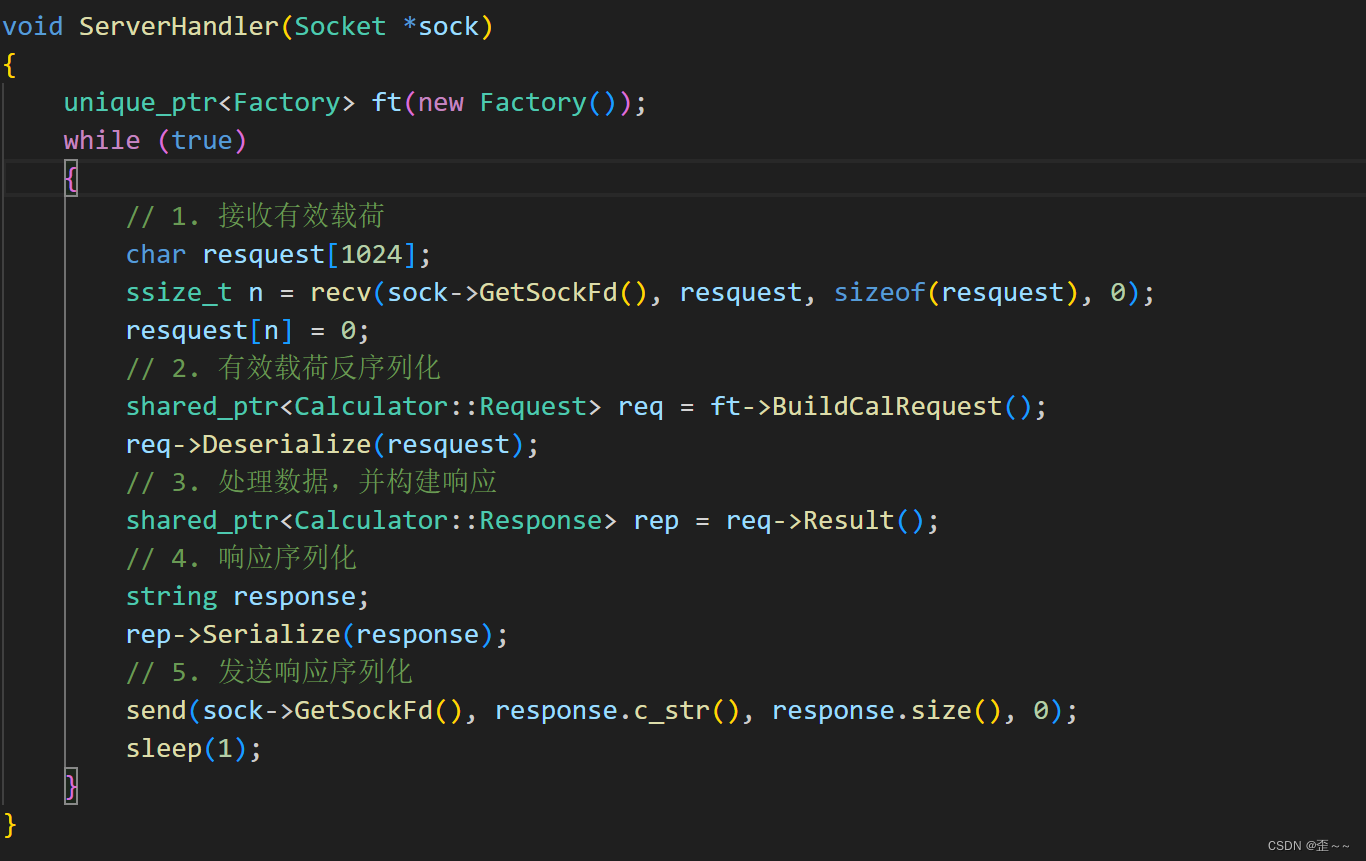
接下来就是我们的业务编写了,而我想写一个简单的计算器的功能,客户端通过传输服务端两个操作数和一个运算符,之后服务端进行运算以及给客户端发送运算的结果。
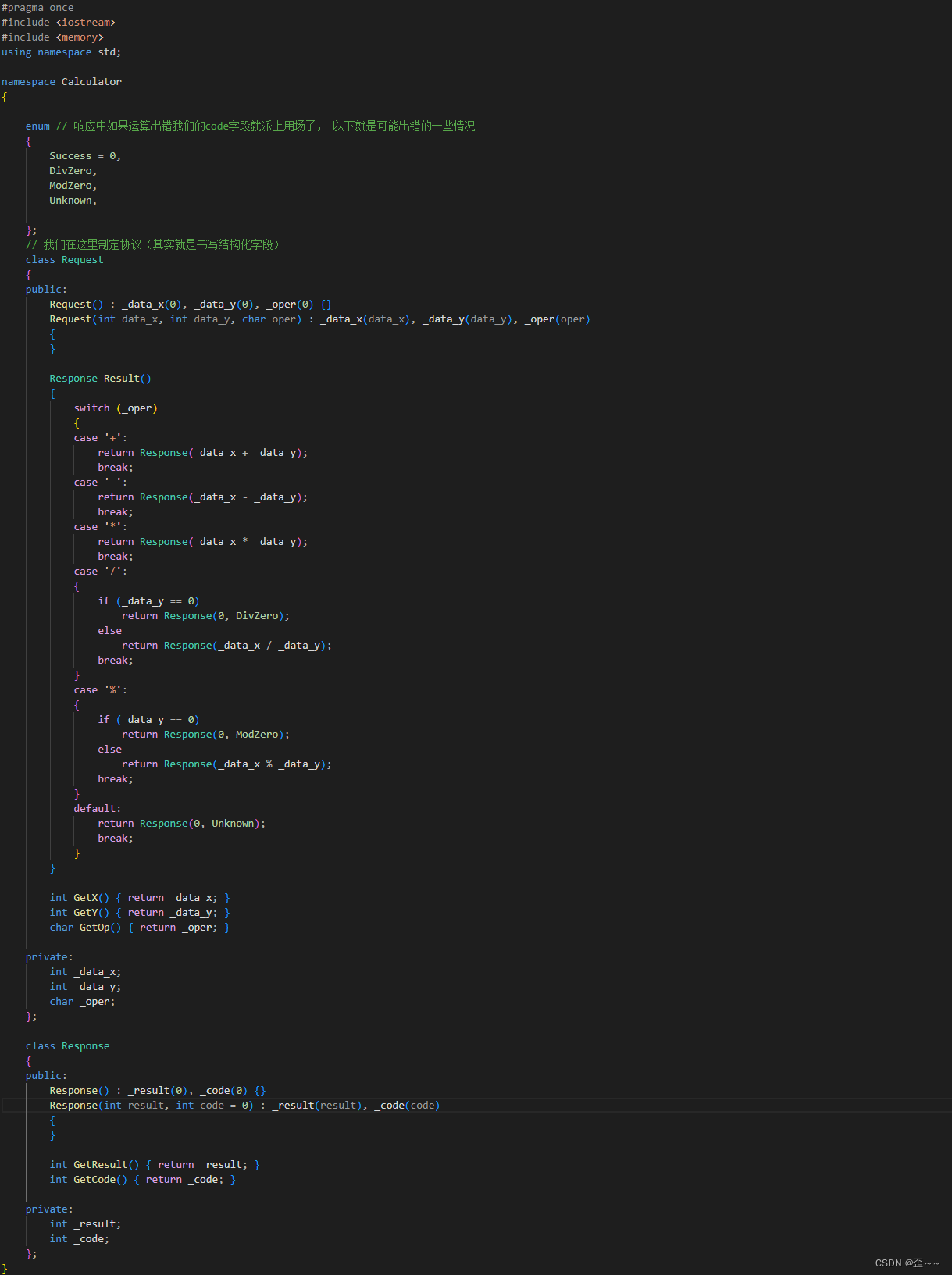
为了两端能够正常通信,我们就需要指定协议了,而前面也说过制定协议,其实就是对通信过程中的信息做结构化处理,让两端都能认识对方发过来的是什么,那么现在开始我们就来编写一个简单的具有请求和相应的计算器功能:
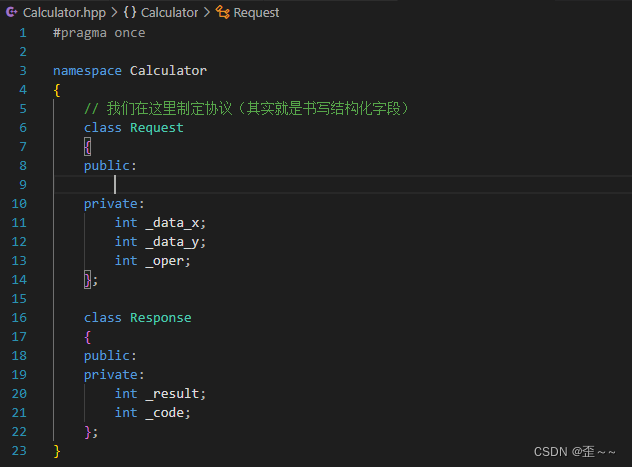
客户端发送请求,然后服务端接收到请求,对这个请求进行处理,最后响应回客户端:
5. 客户端
在开始进行通信之前,我们先进行客户端的简单的编写:
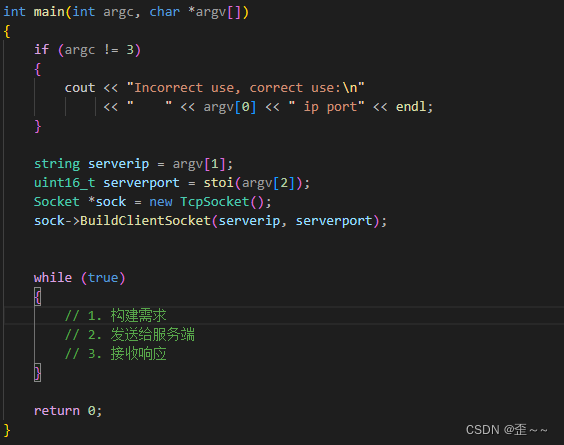
c. 正式开始编写业务逻辑
1). 直接传结构化字段
我们在上面已经制定了一个不太完善的协议,我们先使用直接传结构体的方式,进行网络上的请求和响应 :
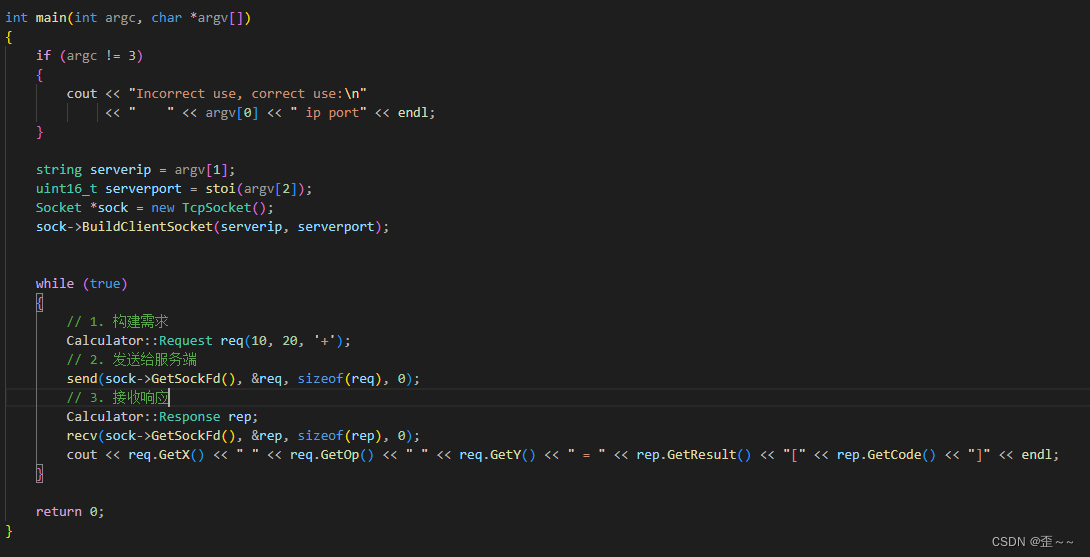
现在我们回到ServerHandler业务逻辑的编写:
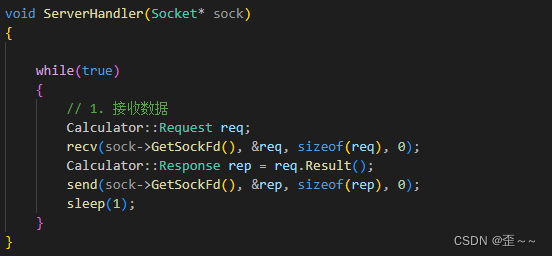
这样服务端和客户端就可以通信了。

但是直接传结构化字段正如开始所说,他是有缺陷的,用结构化字段来直接作为报文的话,服务器和客户端的应用场景就很局限,只要客户端进行了跨平台(例如使用其他语言)的话,这个客户端就不能使用了,就算能发给服务器信息,服务器也不认识他发过来的是什么,因为客户端方是根本不认识C++中的结构体的,所以我们就需要将我们要传输的结构化字段序列化。再规范点的话就将他变成一个报文。
2). 较为规范的应用层协议
上面我们简单的写了一个客户端和服务端进行网络通信以计算器为基本业务的代码,其中通信方式是双方共同认识计算器结构体,以此作为应用层协议。但是这样的传输方式是有问题的,首先就是使用场景太局限,除此之外我们还有其他的问题,在此之前我们需要再次认识tcp中面对字节流,以及tcp协议中的一些更为细节的知识:
tcp协议中的细节知识
我们知道当服务端和客户端使用tcp协议建立连接之后,双方都会有一个用来通信的socket文件描述符,其实我们的tcp协议的通信方式所对应的通信的文件描述符底层是这样的:
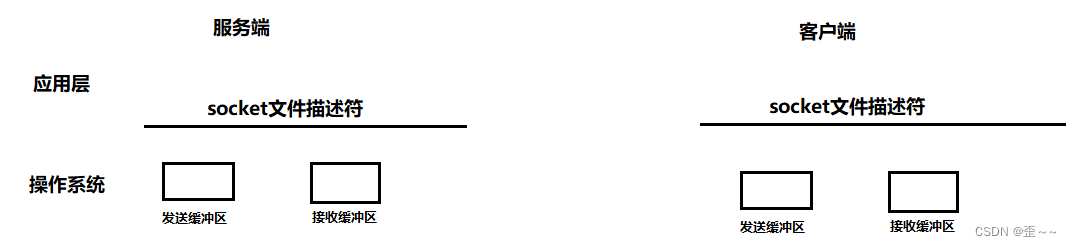
我们的socket文件描述符在操作系统中有着两个文件缓冲区,一个用来接收网络消息,一个用来发出网络消息,所以我们的服务端在应用层所使用的write和send是发送给了客户端吗?其实并不是,write和send是以拷贝的形式拷贝给了发送缓冲区,然后再由操作系统发送给客户端的接收缓冲区,在说得清楚点,就是tcp协议决定着发送缓冲区中的数据发送给客户端,这其中的决定包括什么时候发?发多少?发送过程出错了怎么办?这一切都由tcp协议来做决定。所以我们使用tcp协议进行通信的时候,本质上其实是操作系统间进行通信。
我们也知道tcp协议是面向字节流的一种通信方式,这就意味着我们发送缓冲区的内容有多少发送到了客户端的接收缓冲区中,我们是不确定的(这一般是由客户端接收缓冲区的容量有关),就比如我们现在在应用层使用send发送了一个"hello world",我们将这段内容实际上是拷贝到了本主机的发送缓冲区中,然后可能此时客户端的接收缓冲区中只能容纳五个字节了,这个时候我们的tcp协议在将自己的发送缓冲区中的内容发给客户端的时候就只能发过去个hello:
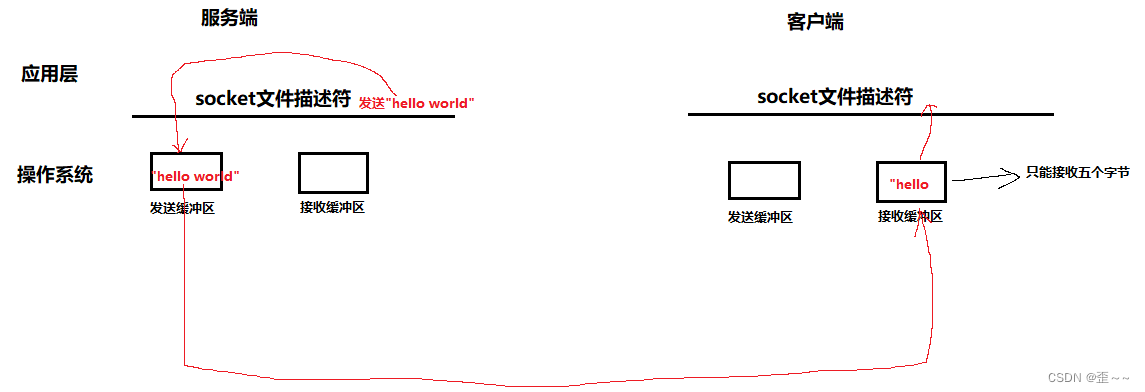
这个时候我们的客户端将这个不完整的数据读上去,那么就会导致数据发生错误,这假如要是我们的上面的计算器结构体的话,这就会直接读取错误。虽然在大部分情况下不会出现这种情况,但是这种情况我们能确定一定不会发生(主要是当前网络压力太小)。
又或者我们的服务端发送了两次hello world,而客户端在服务端第一次发送的时候第一时间没读,而是后来一起读的,这也会导致我们读取的数据错误。
我们发现在使用tcp协议通信时,通信的消息没有明显的 “边界感” 这就是面向字节流的特性。
而udp协议就不需要担心这样的问题,因为udp协议是面向数据报的,它发送数据时,要么不发送要么就全部发送过去,并且在对方未进行读取前,发送端是不能再次进行发送的,发送端会被阻塞。数据和数据之间具有明显的 “边界感” ,这就是面向数据报。
所以为了解决跨平台、数据间没有边界感等问题,我们就需要制定比完善的用户层协议。
所以接下来我们就来写一个比较规范的用户层协议。
序列化和反序列化
首先我们的两端传输的数据不再是结构化字段,而是具有一定格式的字节流也就是字符串,我们叫做序列化和反序列化,所以我们需要在计算器中的添加序列化和反序列化的功能:
我们要清楚我们要序列化的内容是有效载荷,要反序列化的内容也是有效载荷:
并且这里我们约定,请求序列化格式是:
// 中间用空格隔开// _data_x _oper _data_y


响应的序列化格式是
// 中间也是空格隔开// _result _code
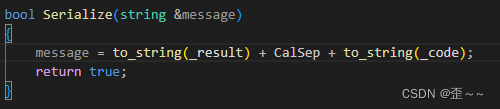
而我们请求反序列化代码如下:
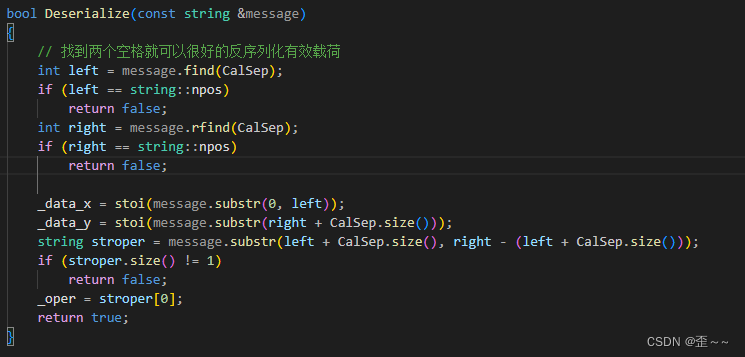
响应反序列化:
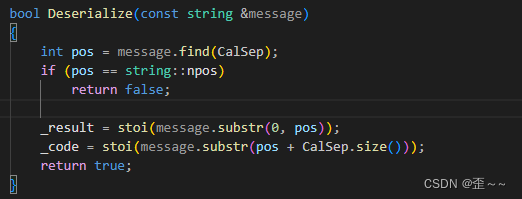
现在我们就可以直接使用一下这个序列化和反序列化的代码了,在这个时候我写了一个关于计算器中的对象的工厂模式:
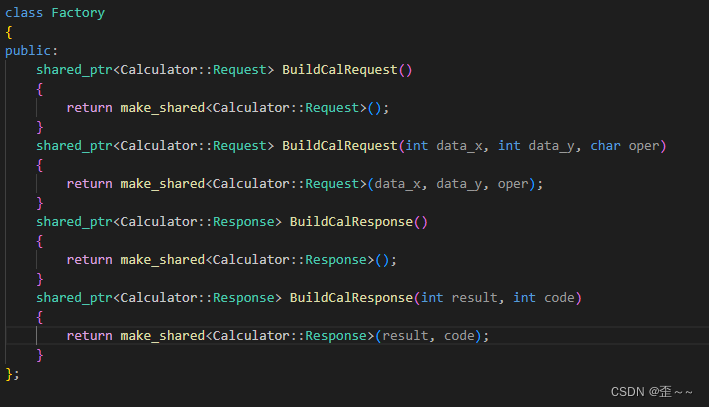
计算器请求中的Result函数也得修改:
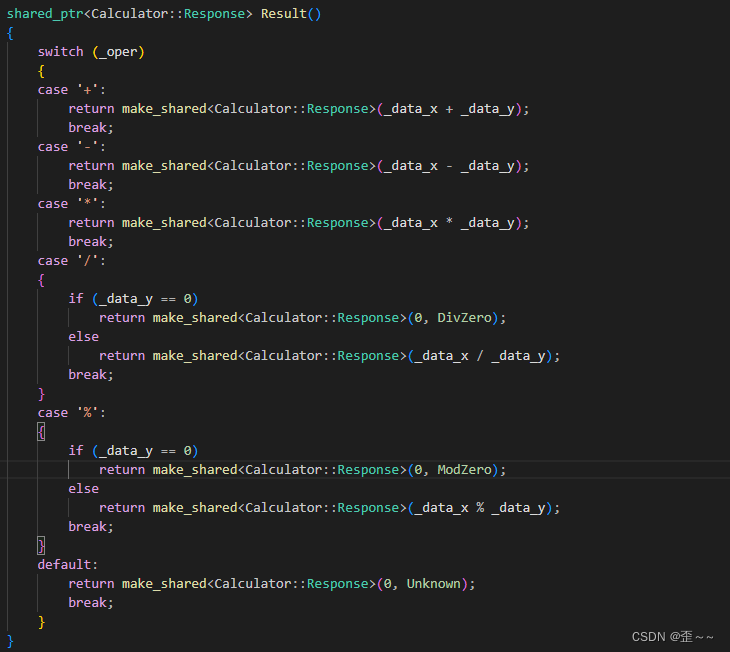
现在我们来使用一下这个序列和反序列化:
客户端
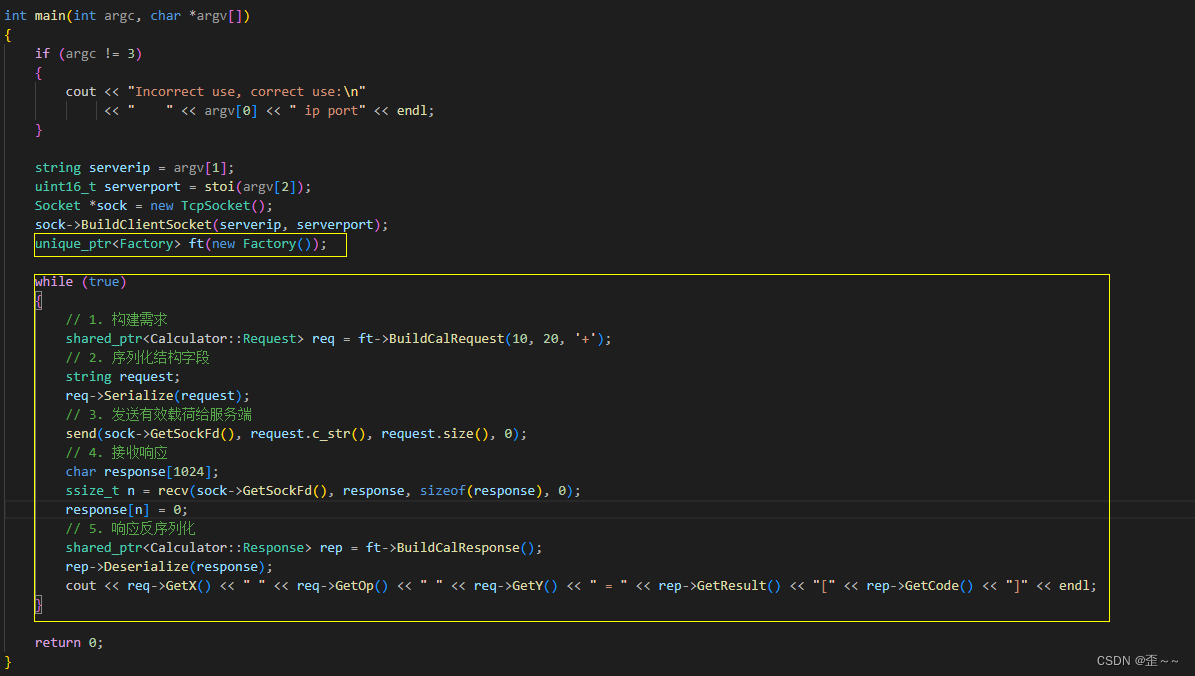
服务端:
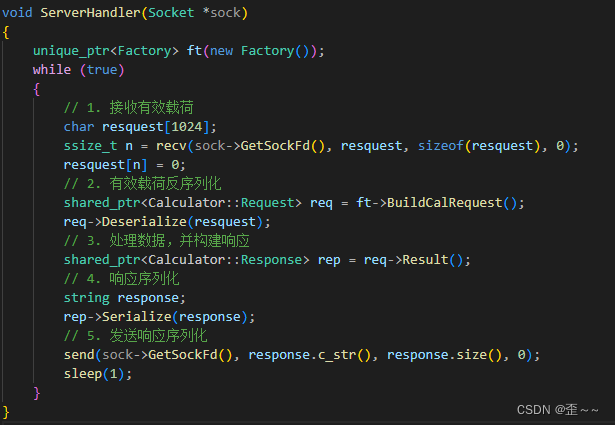

然后我们再将客户端的操作数等,使用随机数的方式来初始化操作数以及描述符:
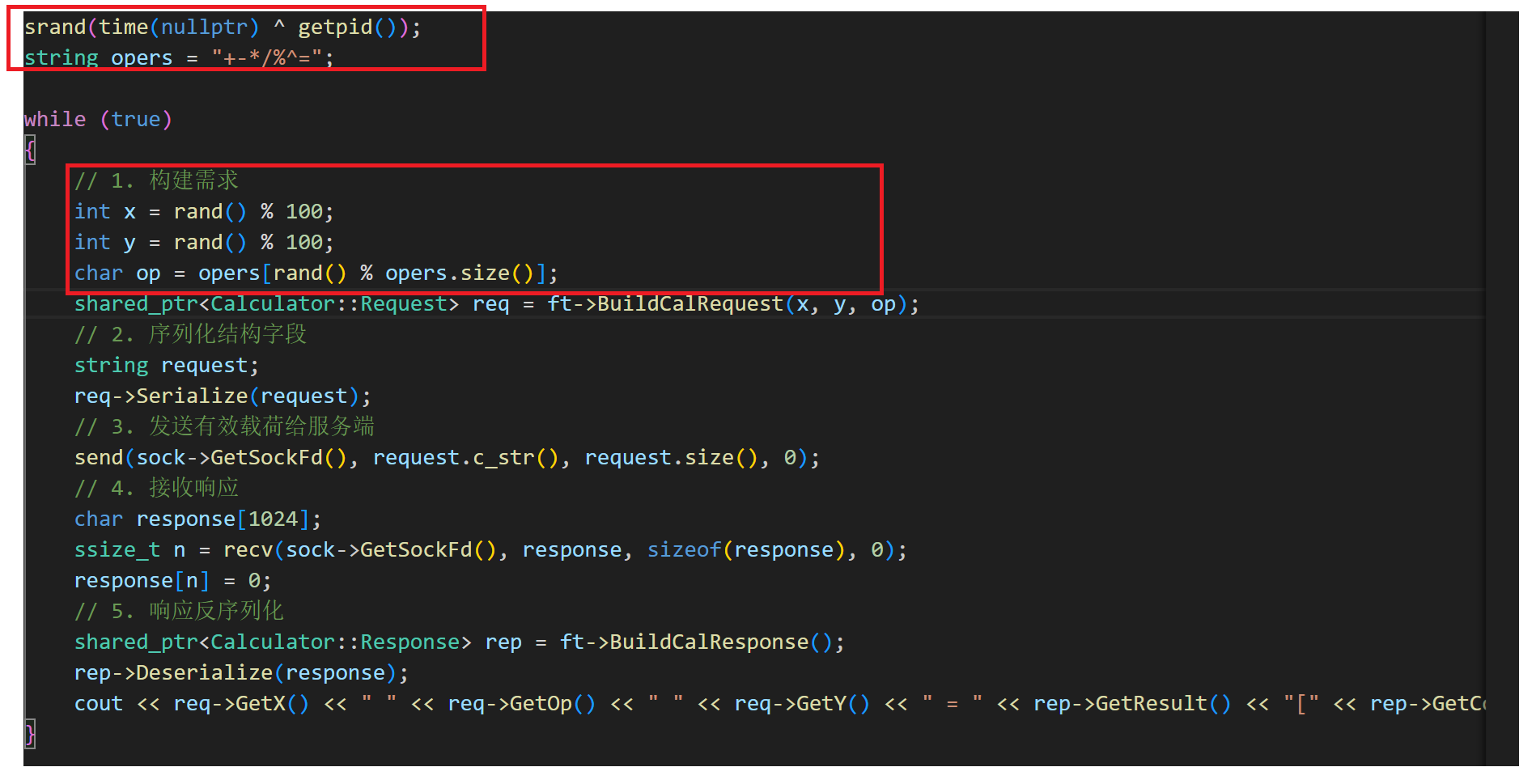
再来看效果:

但是,还有问题,我们现在只解决了结构化字段序列化可以跨平台的功能,但是我们仍无法保证我们两端收到的信息是独立的且完整的,也就是网络通信的数据还是没有边界感,而现在我们传的数据实际上还只能算作有效载荷,所以我们要将数据发送时,变成一个较为规范的报文。
报文
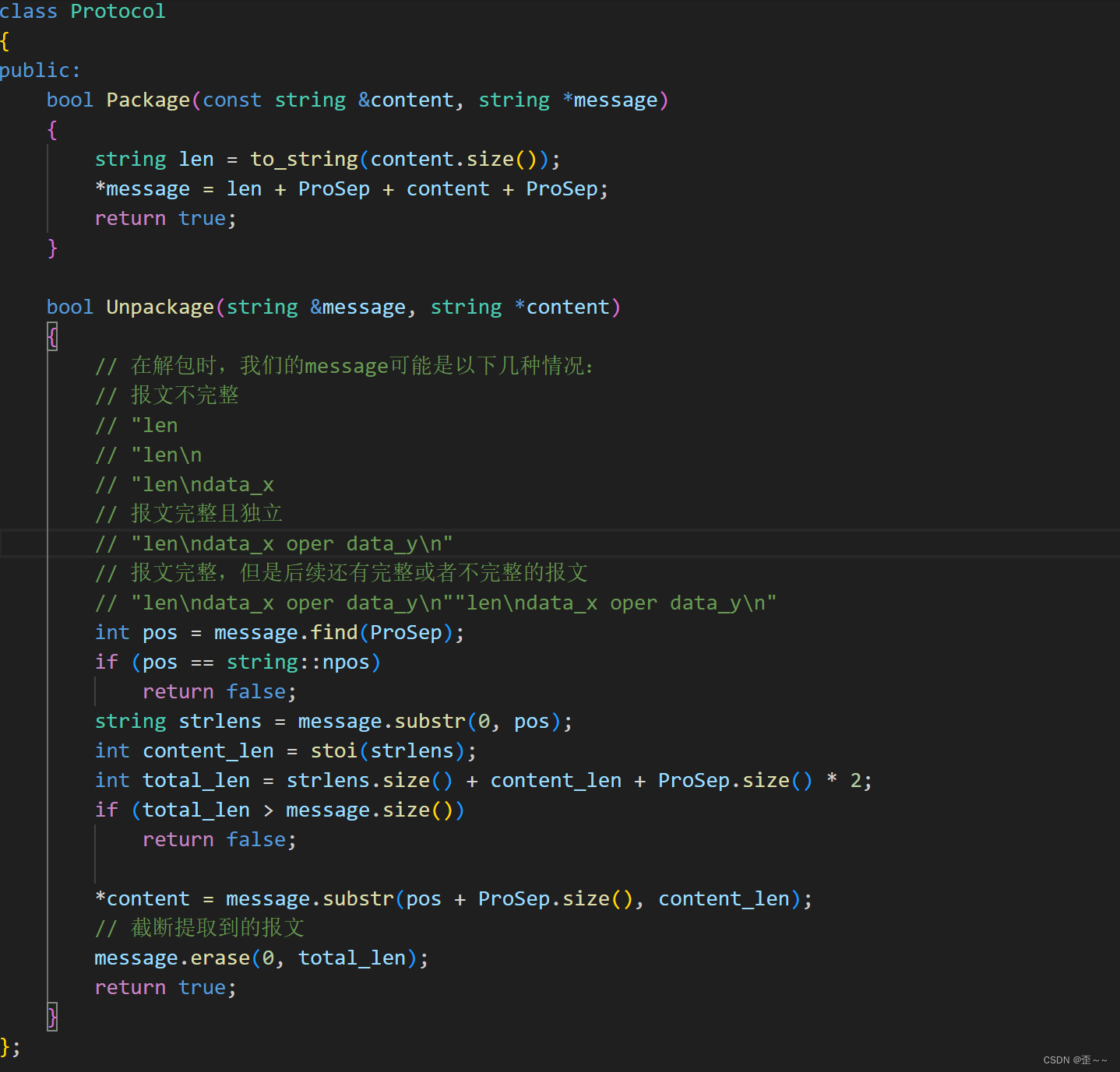
我们规定报文的格式是这样的:
// "len\n有效载荷\n"
也就是在有效载荷的前面添加一个字段len,这个字段用来表示有效载荷的长度,中间用特殊字符\n来隔开,因为我们能确保在读取这个报文的时候在len字段中一定是没有\n的存在的,它只有数字。其中len字段就是报文的自描述字段,这样规定的好处是,它不仅可以用来给计算器业务进行封装报头,它也可以给任意的有效载荷进行封装报头。
而有效载荷的后面的\n不属于有效载荷也不属于封装的报头,只是为了Debug方便。
那么现在我们就来编写对有效载荷进行封装以及对报文解包的代码:
在将这个模块 添加到我们的服务端和客户端时,我们需要对服务端的代码进行改造:
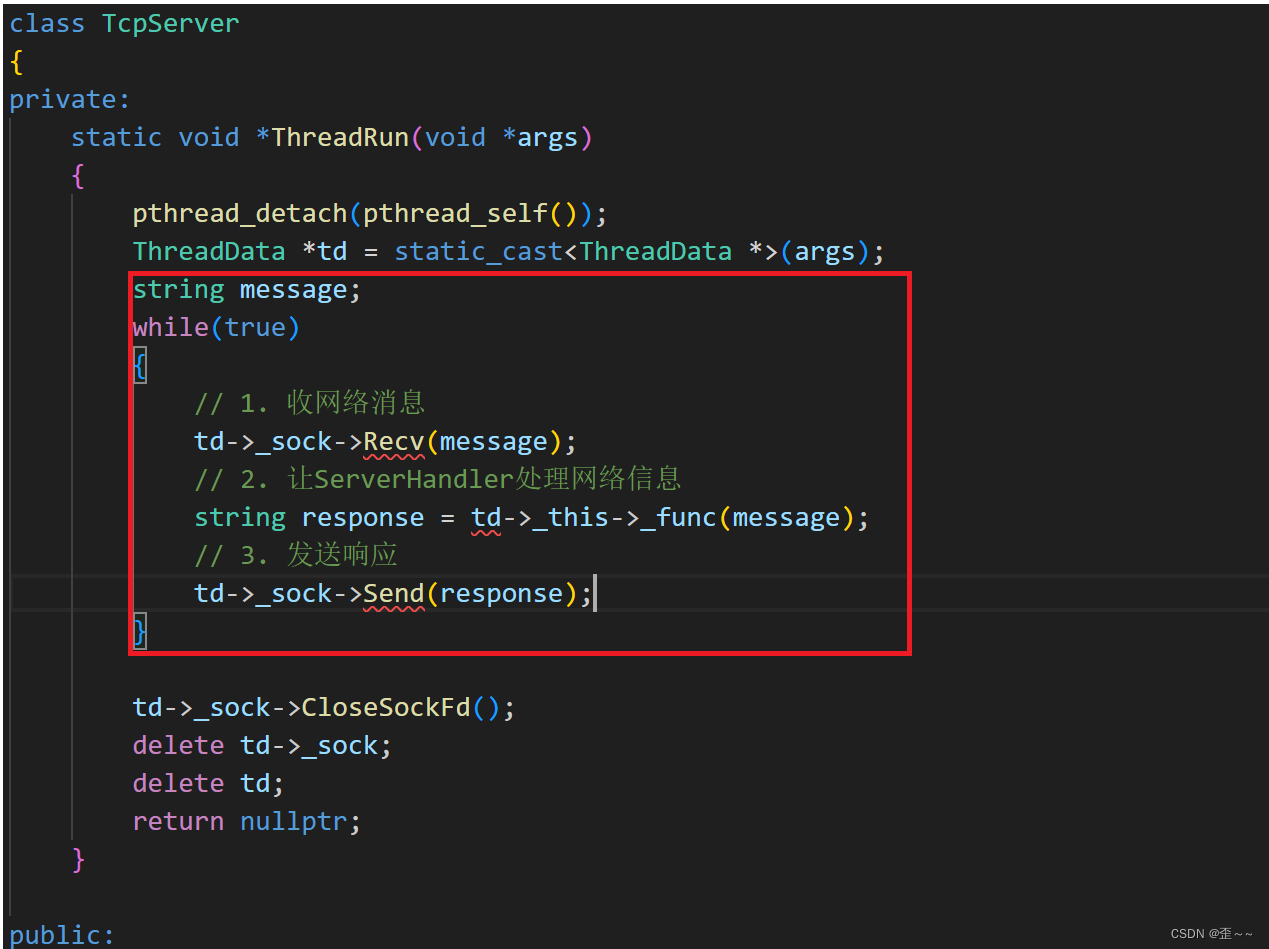
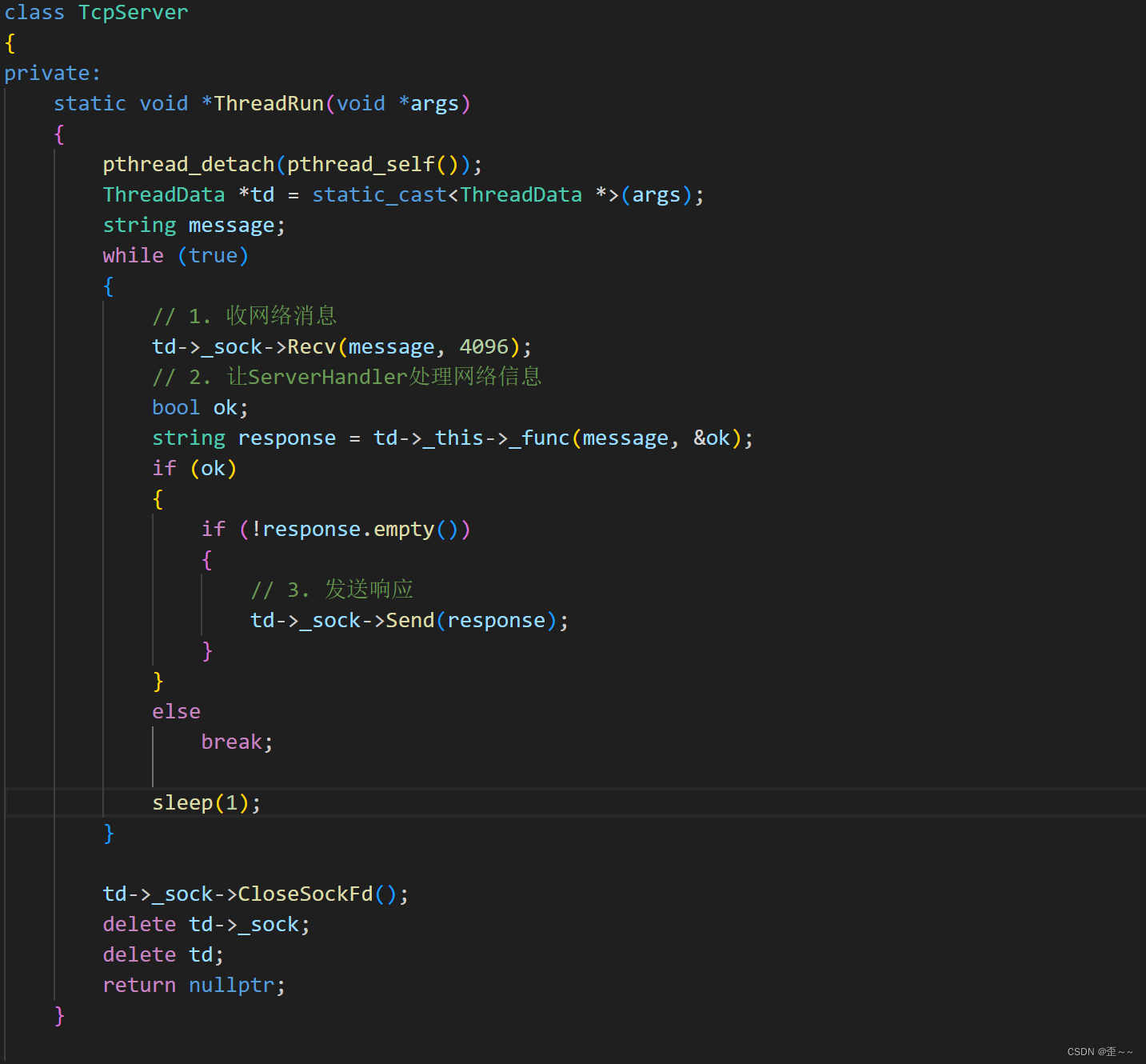
我们这段代码中它有两个功能,一个是收发网络信息的功能,一个是处理网络数据的功能,我们只想让它具有网络数据处理的功能,而将手收发网络数据的功能让外面的线程来做,所以:

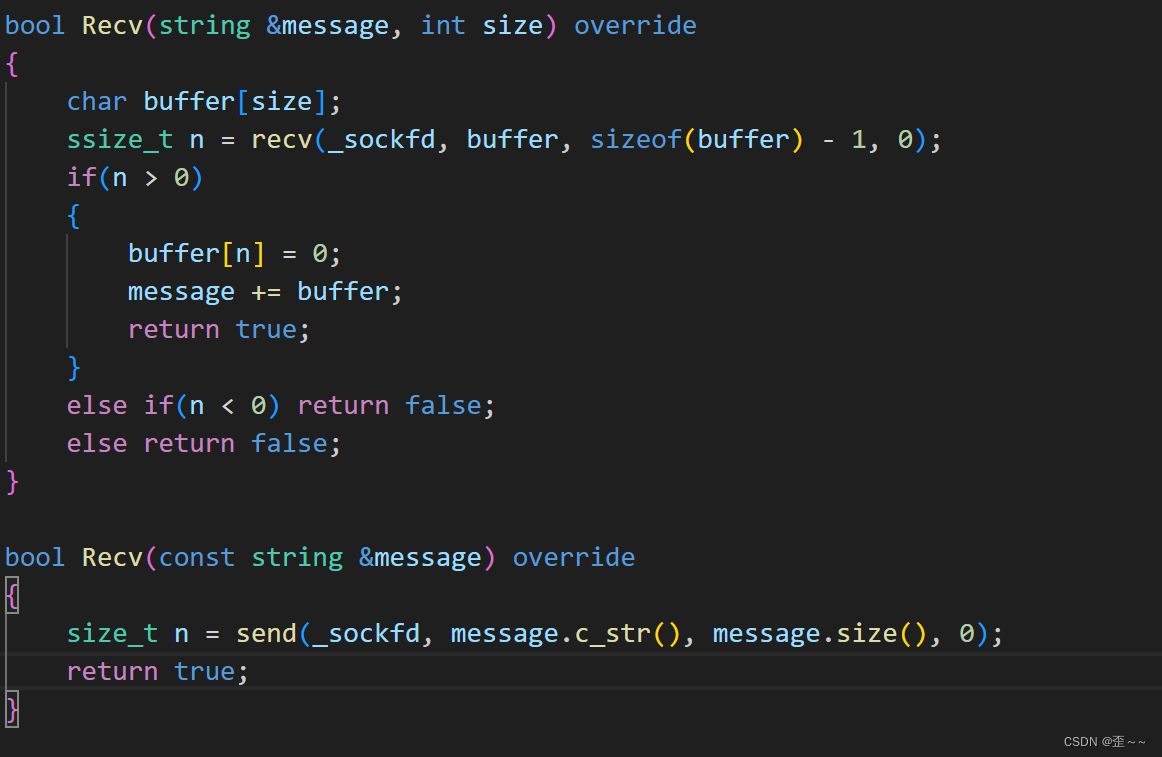
TcpSocket中封装并重写recv和send:
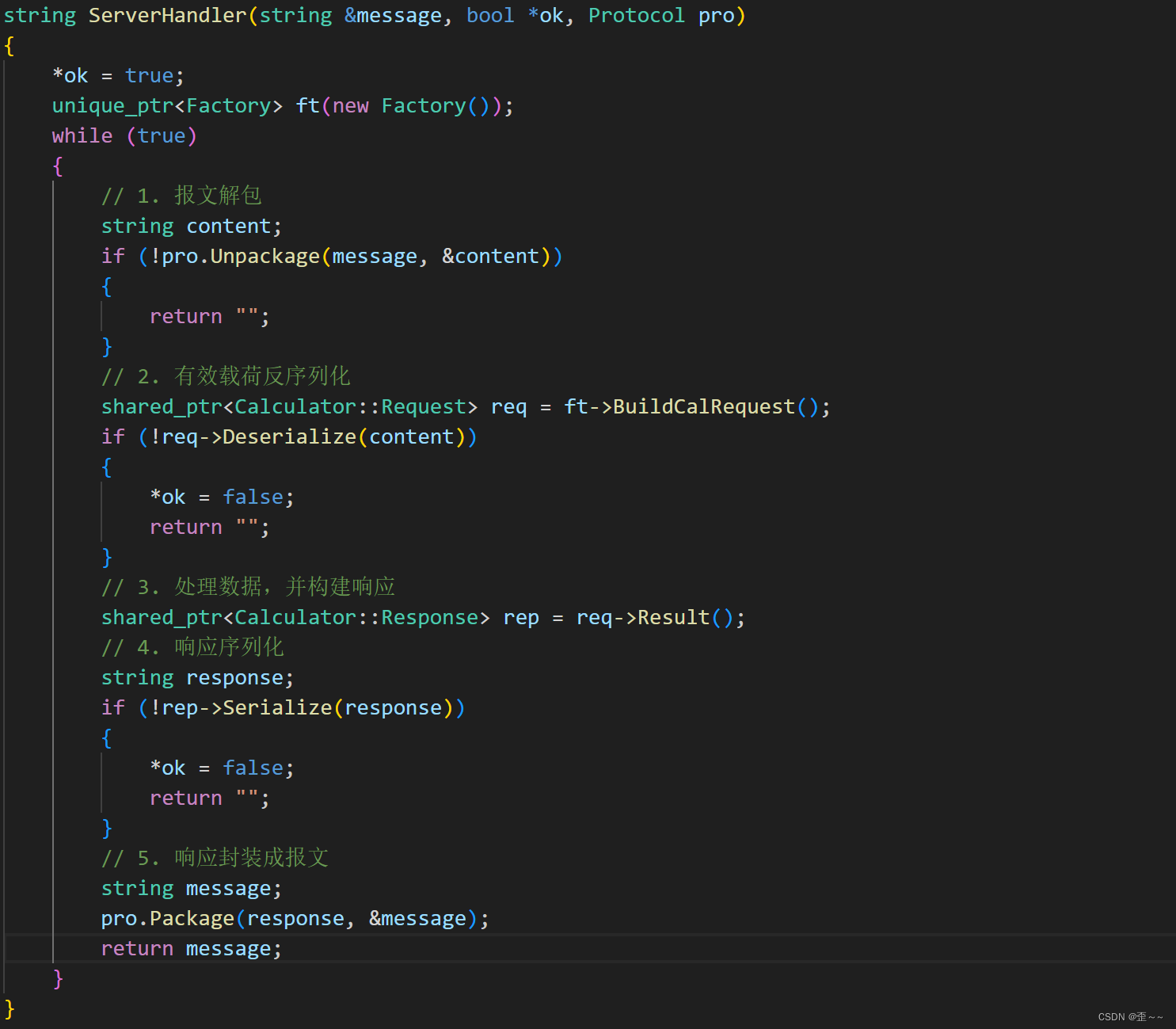
ServerHandler函数:

线程函数优化:
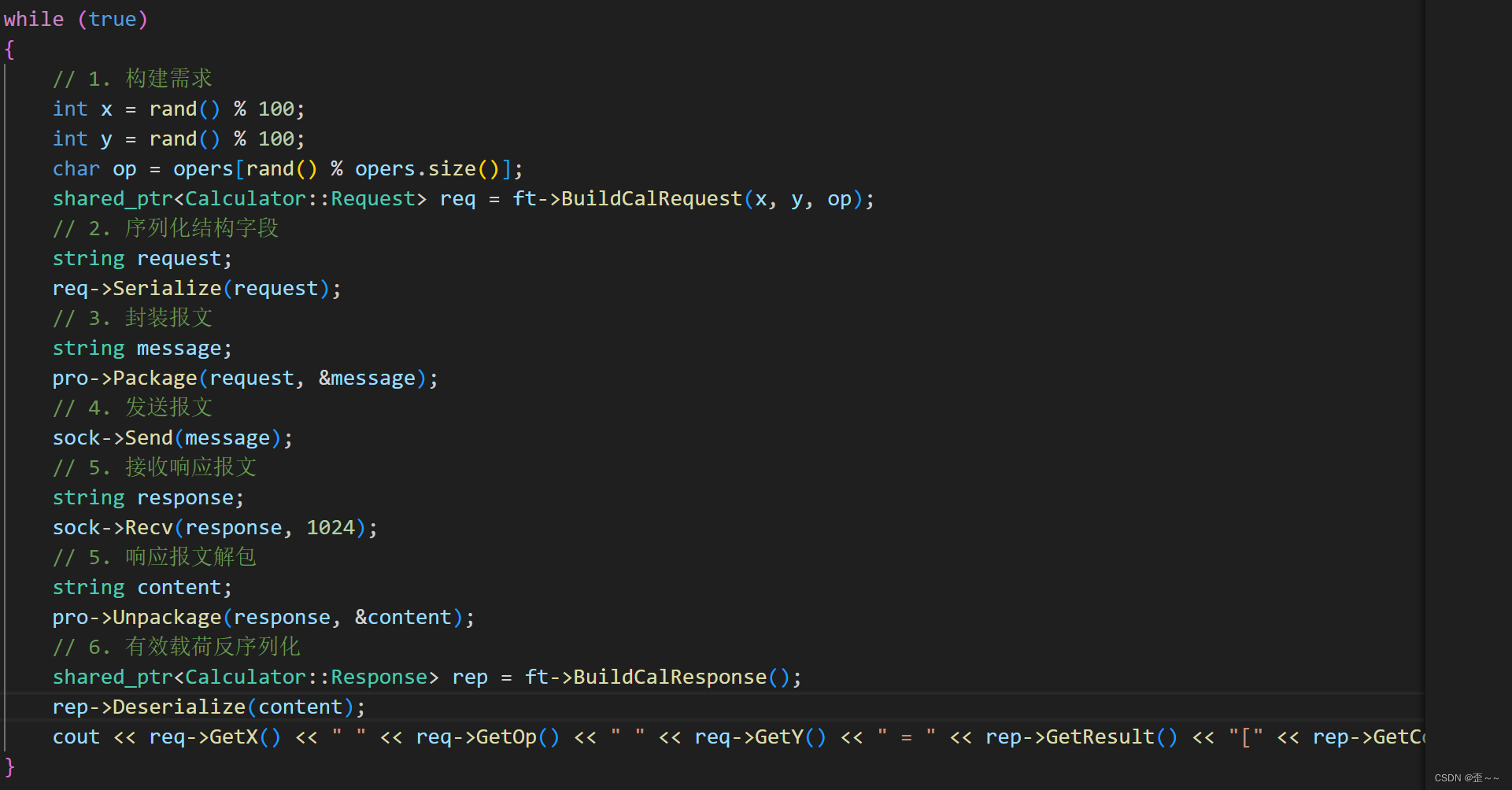
客户端代码:
运行结果:

可以看到,我们现在的代码仍然能够正确运行,并且网络间传输的数据格式较为规范。这就是一个比较规范的应用层协议。
6. 引入较为成熟的序列化方案
在上面的代码中,我们通过自定义应用层协议使得网络通信变得较为规范,其实现在已经有一批比较成熟的序列化方案,比如json、protobuf、xml等,而其中在客户端使用较多的就是json,protobuf较多的使用在服务端。而我们上面计算器的序列与反序列化我们可以使用json来编写:
计算器请求序列化与反序列化:
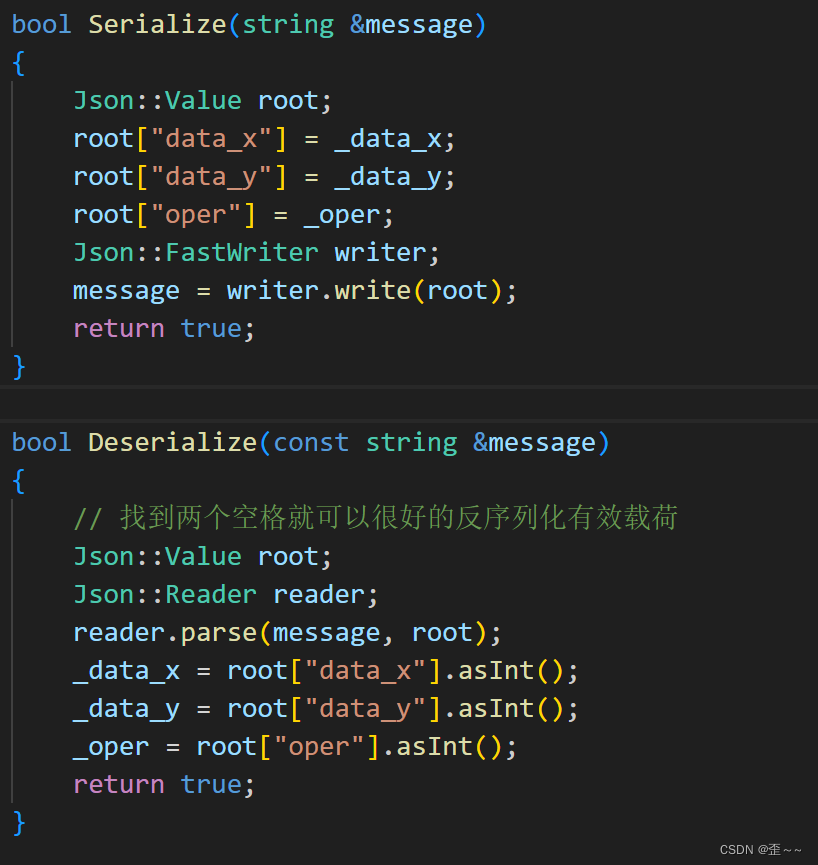
响应序列化和反序列化:

代码运行结果:
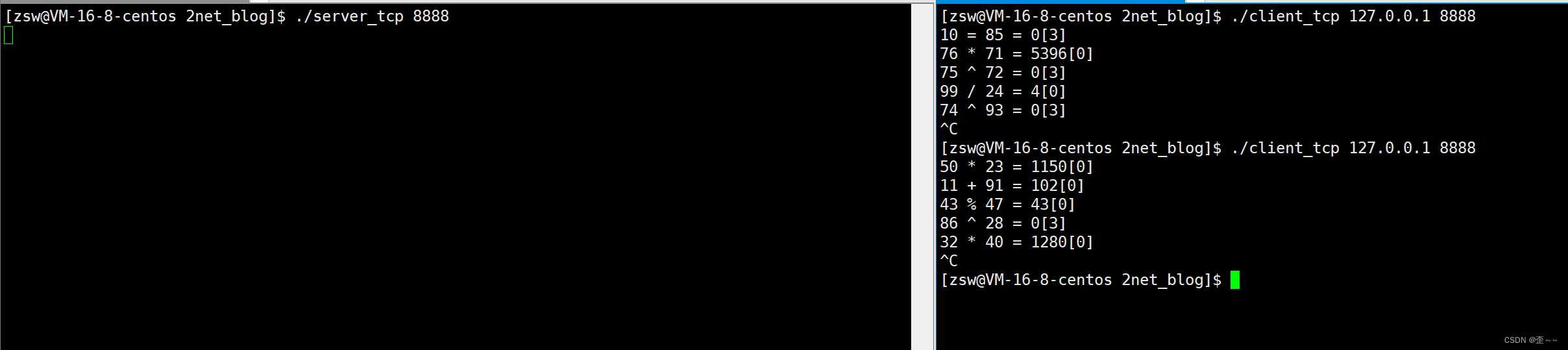
json可以通过键:值字符串的方式来存储你想要存储的结构化信息,最后用花括号把所有内容包含起来,键值对和键值对之间用逗号隔开,json也提供了类型的转换。
7. 网络协议
我曾在在这篇文章初识网络中介绍过,网络协议在实际编码过程中是四层协议,加硬件是五层协议,但是osi标准定制的网络协议是七层,而osi网络协议制定的非常完善:
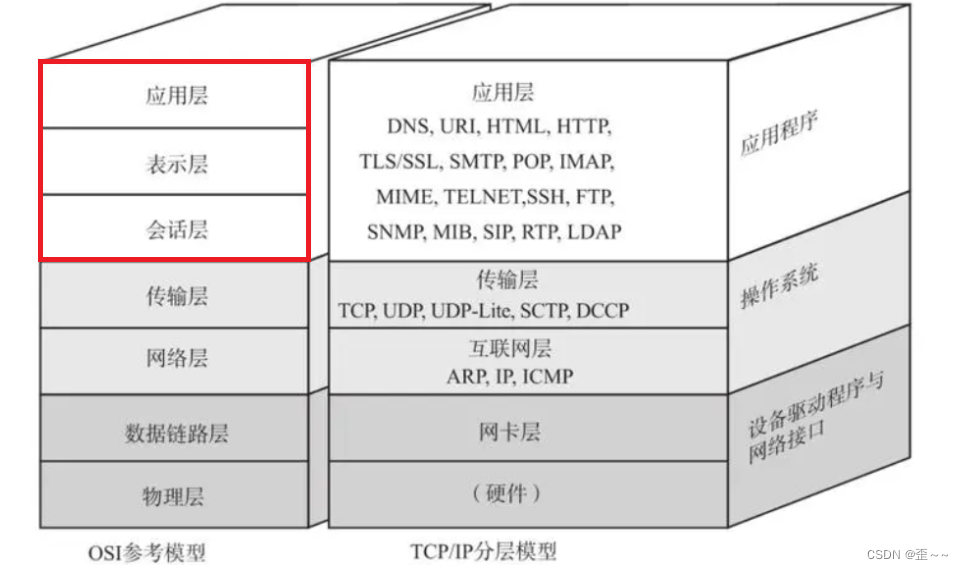
在实际的编码过程中网络协议被分为五层的原因就是,上面红框中的三个部分被统一成了应用层。
在osi标准中:
会话层。负责维护两个结点之间的传输连接,确保点到点传输不中断,以及管理数据交换
这不就是我们使用tcp协议建立新连接之后得到的文件描述符吗?我们的连接的建立和数据的发送和接受都由我们编写。
表示层。处理在两个通信系统中交换信息的表示方法,主要包括数据格式变换、数据加密与解密、数据压缩与恢复等功能。
这就是相当于我们的报头的封装以及结构化字段的序列化以及反序列化,也需要我们来实现。
应用层。直接向用户提供服务,完成用户希望在网络上完成的各种工作,如文件服务器、数据库服务、电子邮件等。
这不用多说,这本来就是我们应该实现的东西。
所以osi标准定制的是很完善的,只不过这三层都是由我们程序员来编写,所以实际开发过程中这三层就被归为了一层。
这就是关于网络协议中自定义应用层协议的全部内容。




![[1688]jsp工资投放管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目](https://img-blog.csdnimg.cn/direct/195fc40685b24f6dba108d6f0e9bcf71.png)