尽管LLMs如ChatGPT在撰写电子邮件等任务上能够提供帮助,它们在理解和与GUIs交互方面存在挑战,这限制了它们在提高自动化水平方面的潜力。数字世界中的自主代理是许多现代人梦寐以求的理想助手。这些代理能够根据用户输入的任务描述自动完成如在线预订票务、进行网络搜索、管理文件和创建PowerPoint演示文稿等任务。然而,目前基于纯语言的代理在真实场景中的潜力相当有限,因为大多数应用程序通过GUI与人交互,而GUI通常缺乏标准的API进行交互,且重要信息(包括图标、图像、图表和空间关系)难以直接用文字表达。
为了克服这些限制,研究者们提出了基于视觉语言模型(Visual Language Models,简称VLMs)的代理。与仅依赖文本输入(如HTML或OCR结果)不同,基于VLM的代理可以直接感知视觉GUI信号。由于GUI是为人类用户设计的,只要VLM达到人类级别的视觉理解能力,基于VLM的代理就能像人类一样有效地执行任务。此外,VLM还能够执行如极快速阅读和编程等通常超出大多数人类用户能力范围的技能,这扩展了基于VLM的代理的潜力。
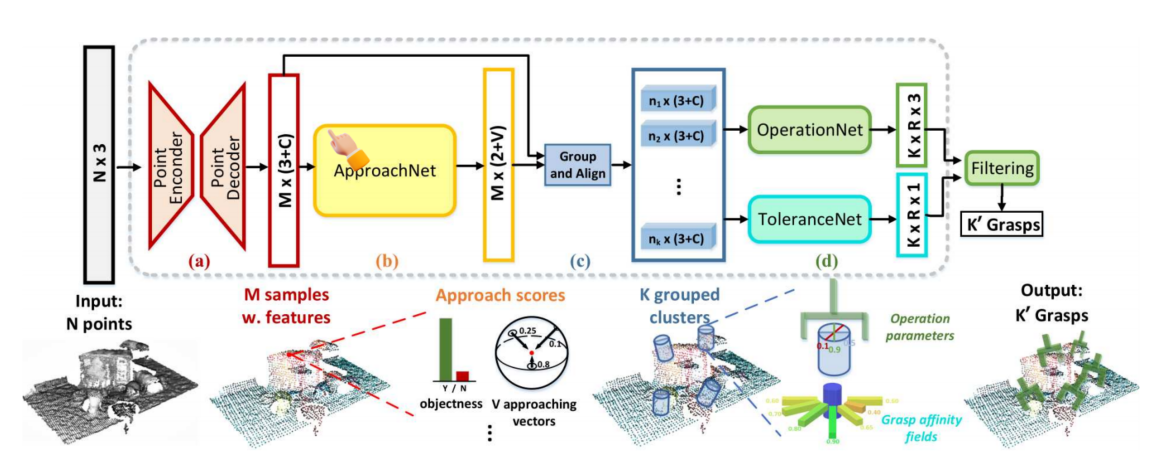
CogAgent,是一个专门用于GUI理解和导航的18亿参数的视觉语言模型(VLM)。专为理解和导航图形用户界面(GUI)而设计。

- 参数规模:CogAgent拥有18亿参数,这使得它能够捕捉和学习复杂的视觉和语言特征,从而更准确地理解和解释GUI元素。
- 双分辨率图像编码器:
- 低分辨率图像编码器:用于处理较小尺寸的图像(例如224×224像素),这有助于模型快速捕捉图像的基本布局和对象。
- 高分辨率图像编码器:设计用于处理高达1120×1120分辨率的图像,这使得模型能够识别和理解细小的GUI元素,如小图标、文本和复杂的图表。
- 输入分辨率:支持高分辨率输入是CogAgent的关键特性之一。高分辨率图像使得模型能够更好地解析GUI中的细微视觉细节,这对于执行精确的GUI任务至关重要。
- 视觉和语言的整合:CogAgent通过视觉语言解码器将视觉特征与文本特征结合起来,这使得模型不仅能够识别图像内容,还能够理解与图像内容相关的语言上下文。
- 交叉注意力机制:CogAgent采用了交叉注意力(cross-attention)机制,这是一种神经网络技术,允许模型在处理视觉信息时同时考虑相关的语言信息,反之亦然。
- 计算效率:为了处理高分辨率图像带来的计算挑战,CogAgent设计了一个高分辨率交叉模块,它通过减小隐藏层的大小和使用跨注意力机制来降低计算成本。
对CogAgent预训练和微调过程如下:
- 预训练阶段:
- CogAgent的预训练阶段专注于构建一个能够理解图形用户界面(GUI)的模型。为此,研究者们收集了大规模的GUI图像和光学字符识别(OCR)数据集。
- 预训练数据集包含了合成渲染的文本图像、自然场景中的文本图像以及学术文档等,这些数据通过不同的图像增强技术进行预处理,以提高模型对文本的识别能力。
- 此外,预训练还包括视觉定位任务,即模型需要识别图像中的文本和对象,并理解它们之间的关系,这对于理解GUI结构至关重要。
- 预训练的目的是让模型掌握对各种尺寸、方向和字体的文本的识别能力,以及对图像中对象的定位能力,从而为后续的微调阶段打下坚实的基础。
- 微调阶段:
- 微调是对预训练模型进行的进一步训练,目的是让模型更好地适应特定的任务。在CogAgent的情况下,微调涉及将模型应用于具体的GUI任务,如网页浏览、应用操作等。
- 微调数据集包含了从真实世界的智能手机和电脑应用中收集的截图,这些截图被人工标注了潜在的任务和操作方法。
- 通过微调,CogAgent能够学习到如何根据给定的任务描述和历史操作来预测用户界面中的下一个动作,例如点击某个按钮或输入文本。
- 微调过程不冻结模型的所有参数,而是允许它们根据特定任务的数据进行更新,从而使模型的性能在这些任务上得到优化。
为了全面评估CogAgent的性能,研究者们在多个视觉问答(VQA)基准测试中对其进行了测试。这些测试覆盖了通用VQA和文本丰富的VQA两大类,旨在衡量模型在处理视觉场景中嵌入文本的图像上的能力。CogAgent在包括VQAv2、OK-VQA、TextVQA、ST-VQA、ChartQA、InfoVQA和DocVQA在内的八个VQA基准测试中进行了评估。结果显示,CogAgent在通用VQA类别的两个数据集上均达到了最先进的一般性结果,同时在文本丰富的VQA类别中的五个基准测试中的四个上取得了最佳成绩,显著超过了其他一般性模型,并且在某些情况下甚至超过了特定任务的模型。

CogAgent在零样本测试中也展现了卓越的性能。在MM-Vet和POPE数据集上,CogAgent在处理复杂任务和抵抗幻觉方面的表现超过了其他现有模型。在MM-Vet数据集上,CogAgent的得分为52.8,比最接近的竞争对手LLaVA-1.5高出16.5分。在POPE数据集的对抗性评估中,CogAgent获得了85.9分,显示出其在处理幻觉方面的优越能力。

在GUI导航任务上,CogAgent在Mind2Web和AITW数据集上的表现尤为突出。Mind2Web是一个针对Web代理的数据集,包含来自不同网站的2000多个任务。CogAgent在跨网站、跨域和跨任务的测试子集上均取得了显著的性能提升,超过了LLaMA2-70B模型。在AITW数据集上,CogAgent在预测Android设备上的用户行为方面也取得了最先进的性能,这表明CogAgent能够有效地理解和操作智能手机界面。
在Mind2Web数据集上评估了CogAgent,这是一个针对Web代理的数据集,包含来自137个真实世界网站的2000多个开放式任务。
CogAgent在跨网站、跨域和跨任务的三个子集上均取得了显著的性能提升,超过了LLaMA2-70B模型11.6%、4.7%和6.6%。
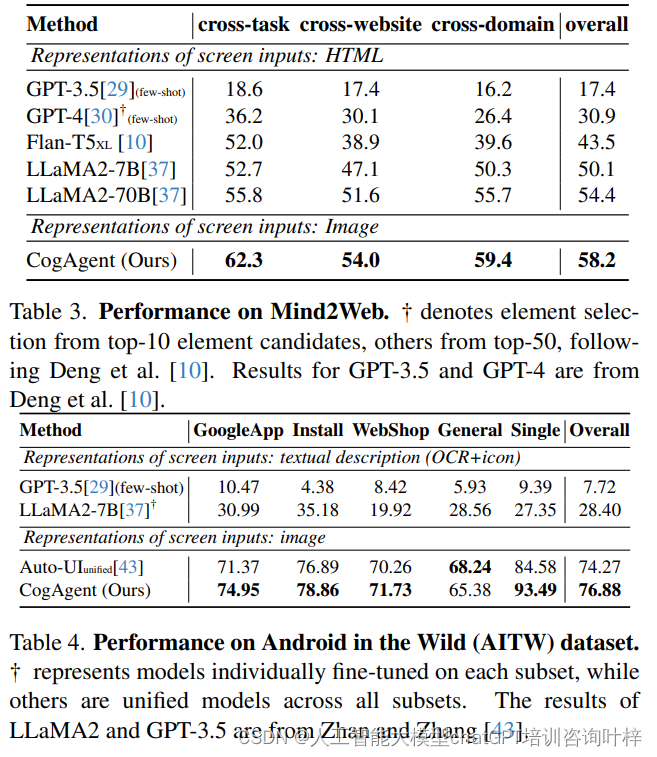
使用Android in the Wild (AITW)数据集评估了模型在多样化的智能手机界面和任务上的性能,这是一个包含715k操作集数的大型数据集。
CogAgent在所有测试集上均取得了最先进的性能,与基于语言的方法相比,模型在整体性能上提高了2.61%。
CogAgent的模型和代码将被开源,以促进基于VLM的AI代理的未来研究和应用。基于VLM的代理通过其视觉和语言的综合处理能力,为与GUI的自然交互提供了新的可能性,并且在自动化和增强人机交互体验方面展现出巨大的潜力。
论文链接:
https://arxiv.org/pdf/2312.08914.pdf
GitHub项目地址(含开源模型、网页版Demo):
https://github.com/THUDM/CogVLM