前言
首先这里已经正式步入数据结构的知识,之前我们已经讲解了链表的使用,接下来我们需要的就是大量的练习,熟练掌握数据结构。下面的题型我们选择的都是链表的经典题型,面试题型,包含快慢指针,数形结合,链表的证明题型,链表的熟练使用。并且会由简单到相对复杂来进行讲解计算。
面试题:返回倒数第k个节点(简单)
面试题 02.02. 返回倒数第 k 个节点 - 力扣(LeetCode)
https://leetcode.cn/problems/kth-node-from-end-of-list-lcci/description/
这一题是很简单的当做试手题
题目
题目分析
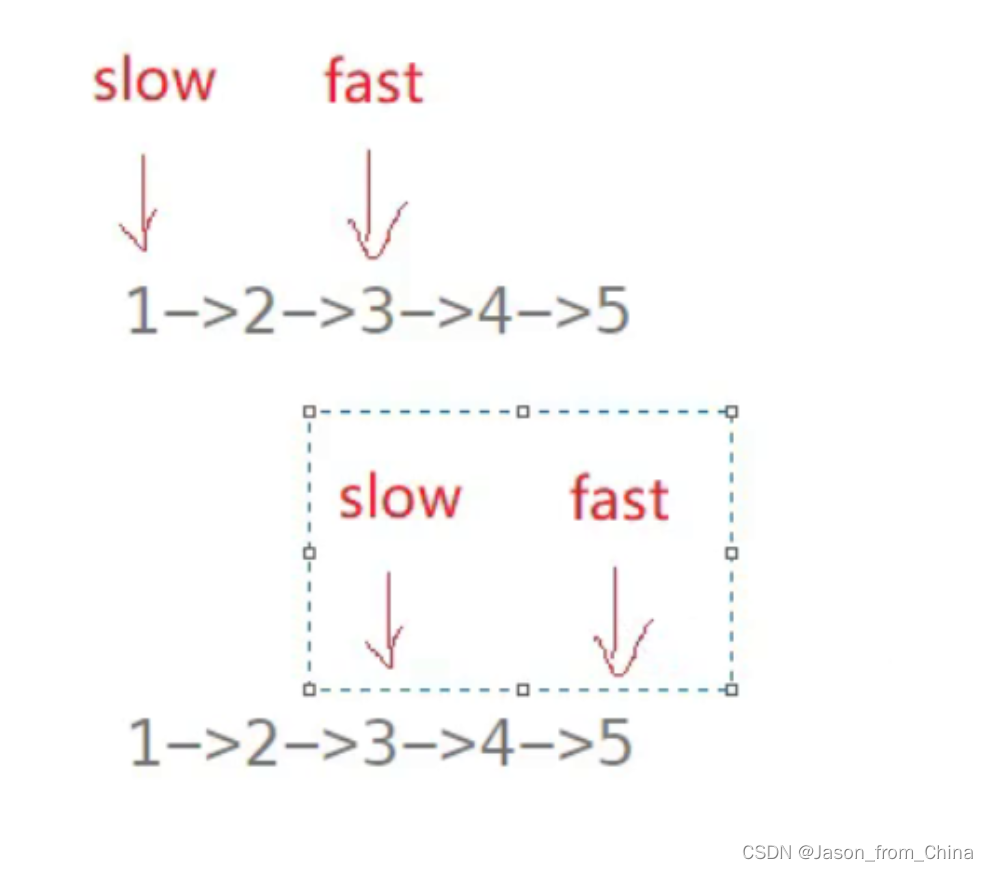
1,这里的思路是利用快慢指针来进行解决
2,这里如果我们需要的是,倒数第2个节点的情况下,我们可以让快指针先移动两次
3,之后再同步进行移动,当快指针指向null的时候,说明慢指针此时指向需要的数值
4,这里需要注意的是,最后的返回值是数值->val,不是地址
代码
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode; int kthToLast(struct ListNode* head, int k) {ListNode* FAST=head;ListNode* SLOW=head;while(k--){FAST=FAST->next;}while(FAST){SLOW=SLOW->next;FAST=FAST->next;}return SLOW->val;}

链表回文
链表的回文结构_牛客题霸_牛客网 (nowcoder.com)
题目
解决思路
1,先找中间节点
2,然会进行逆置
3,最后进行对比
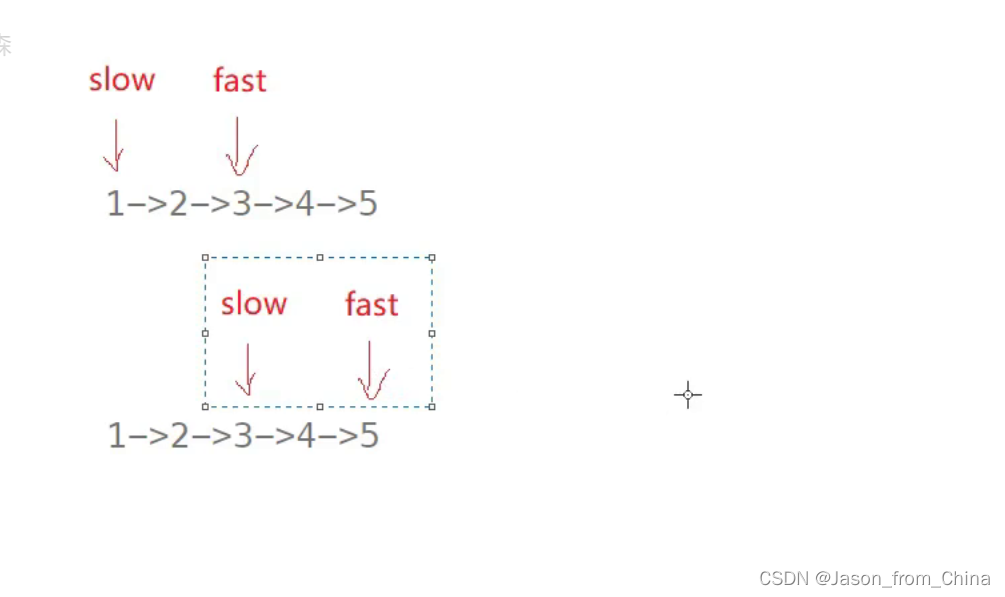
1,找到中间节点
这个我们采取快慢指针,来找到中间节点
快慢指针是一种常用的技巧,用于在链表或数组中找到中间节点、检测循环或者解决其他问题。快慢指针通常包括两个指针,一个快指针和一个慢指针。快指针每次移动两个节点,而慢指针每次移动一个节点。当快指针到达链表的末尾时,慢指针将指向链表的中间节点。
下面是快慢指针在链表中找到中间节点的步骤:
1. 初始化两个指针,快指针(fast)和慢指针(slow),都指向链表的头节点。
2. 在每次迭代中,将快指针向前移动两个节点,将慢指针向前移动一个节点。
3. 当快指针到达链表的末尾(即快指针为NULL或者快指针的下一个节点为NULL)时,慢指针将指向链表的中间节点。
如果链表的长度是奇数,慢指针将指向中间的节点;如果链表的长度是偶数,慢指针将指向中间两个节点的第一个节点。
下面是一个使用快慢指针在链表中找到中间节点的示例代码:```c ListNode* FindMid(ListNode* head) {if (head == NULL || head->next == NULL) {return head; // 链表为空或只有一个节点时,中间节点就是头节点}ListNode* slow = head;ListNode* fast = head;while (fast != NULL && fast->next != NULL) {slow = slow->next; // 慢指针前进一步fast = fast->next->next; // 快指针前进两步}return slow; // 慢指针指向中间节点 } ```在这个示例中,当快指针到达链表的末尾时,慢指针将指向链表的中间节点。如果链表有偶数个节点,慢指针将指向第二个中间节点。如果需要找到第一个中间节点,可以在循环结束后将慢指针再向前移动一个节点。
这里的判断条件看清楚,都是对快指针的判断,因为快慢指针涉及的是奇偶数
while (fast != NULL && fast->next != NULL)
2,然会进行逆置
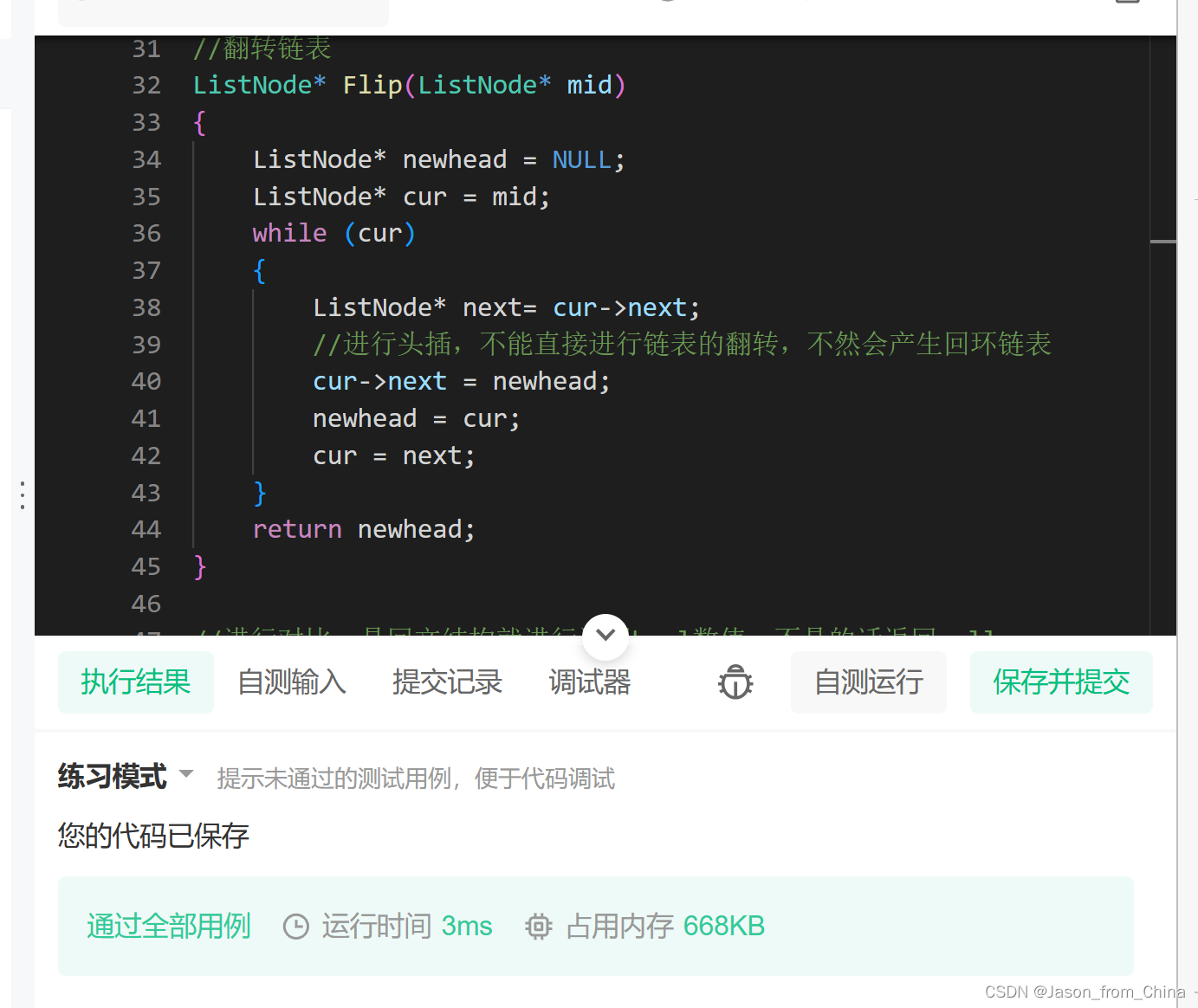
逆置这里,不能直接进行逆置,直接进行逆置的情况下,容易导致循环节点,所以需要修改一下,也就是创建一个指针指向头结点
单链表逆置(这里还是有点难度的)
也称为链表翻转,是将链表中的元素顺序颠倒的过程。在单链表中,每个节点都有一个指向下一个节点的指针。逆置链表意味着改变每个节点的指向,使其指向前一个节点,而不是下一个节点。
链表逆置的常用方法是使用头插法。头插法是一种常用的链表操作技巧,用于在链表的头部插入新节点。在链表逆置过程中,我们可以从头开始遍历原始链表,并将每个节点作为新链表的头节点插入。
以下是单链表逆置的步骤:
1. 初始化两个指针,一个指向原始链表的头节点(current),另一个指向新链表的头部(newHead),初始时新链表为空。
2. 遍历原始链表:
a. 使用临时指针(next)保存当前节点的下一个节点。
b. 将当前节点的下一个节点指向新链表的头部(newHead),实现头插法。
c. 更新新链表的头部为当前节点。
d. 将当前节点移动到下一个节点(即临时指针指向的节点)。
3. 当原始链表遍历完毕后,新链表即为逆置后的链表。
下面是一个使用头插法逆置单链表的示例代码:ListNode* Reverse(ListNode* head) {ListNode* newHead = NULL; // 新链表的头部ListNode* current = head; // 当前遍历的节点while (current != NULL) {ListNode* next = current->next; // 保存下一个节点current->next = newHead; // 将当前节点的下一个节点指向新链表的头部newHead = current; // 更新新链表的头部为当前节点current = next; // 移动当前节点到下一个节点}return newHead; // 返回新链表的头部 }在这个示例中,`Reverse` 函数接受一个链表的头节点 `head` 作为参数,并返回逆置后的链表的头节点 `newHead`。通过头插法,原始链表中的每个节点都被逆序插入到新链表的头部,从而实现了链表的逆置。
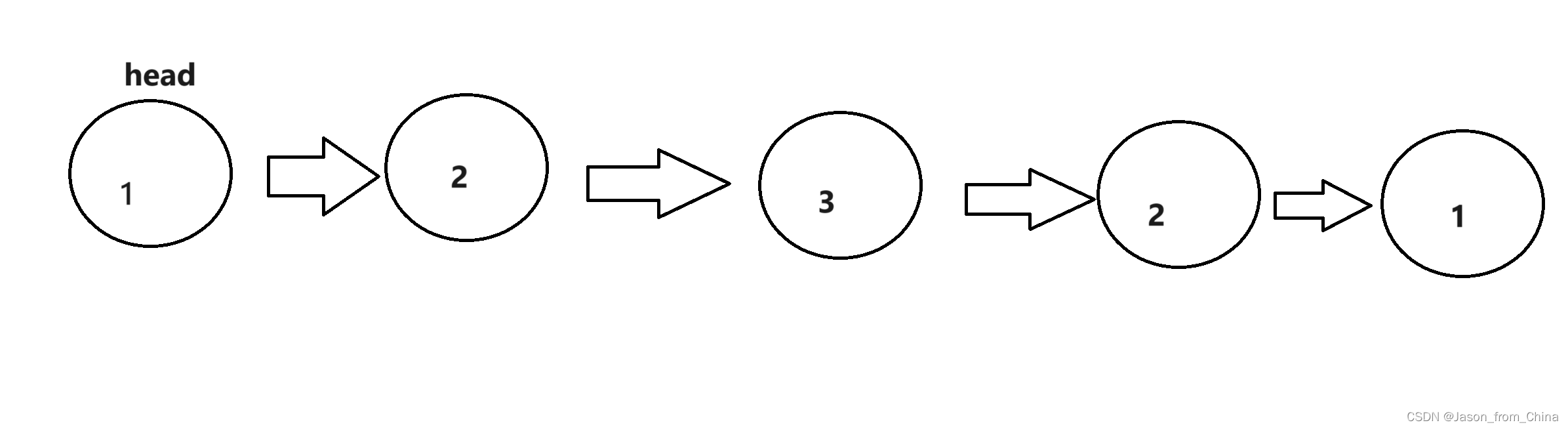
图解
1,首先这里是一个环回链表,我们已经找到了中间节点
2,此时我们设置好变量
3,我们进行逆置的行动
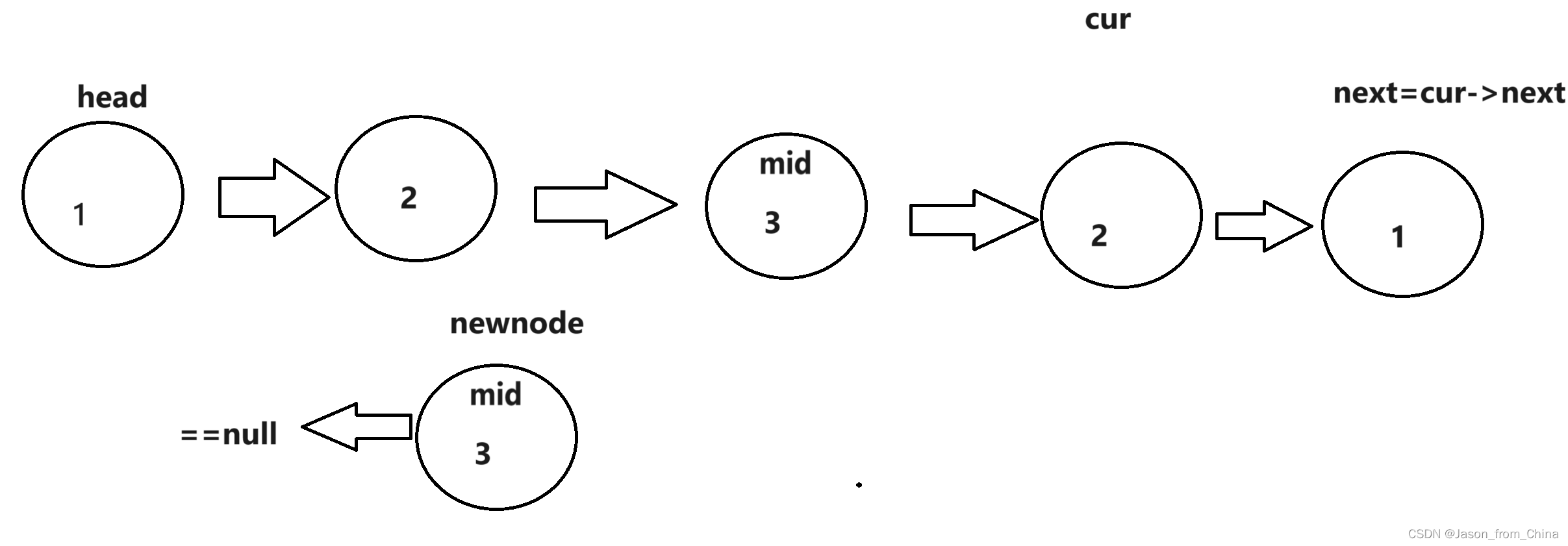
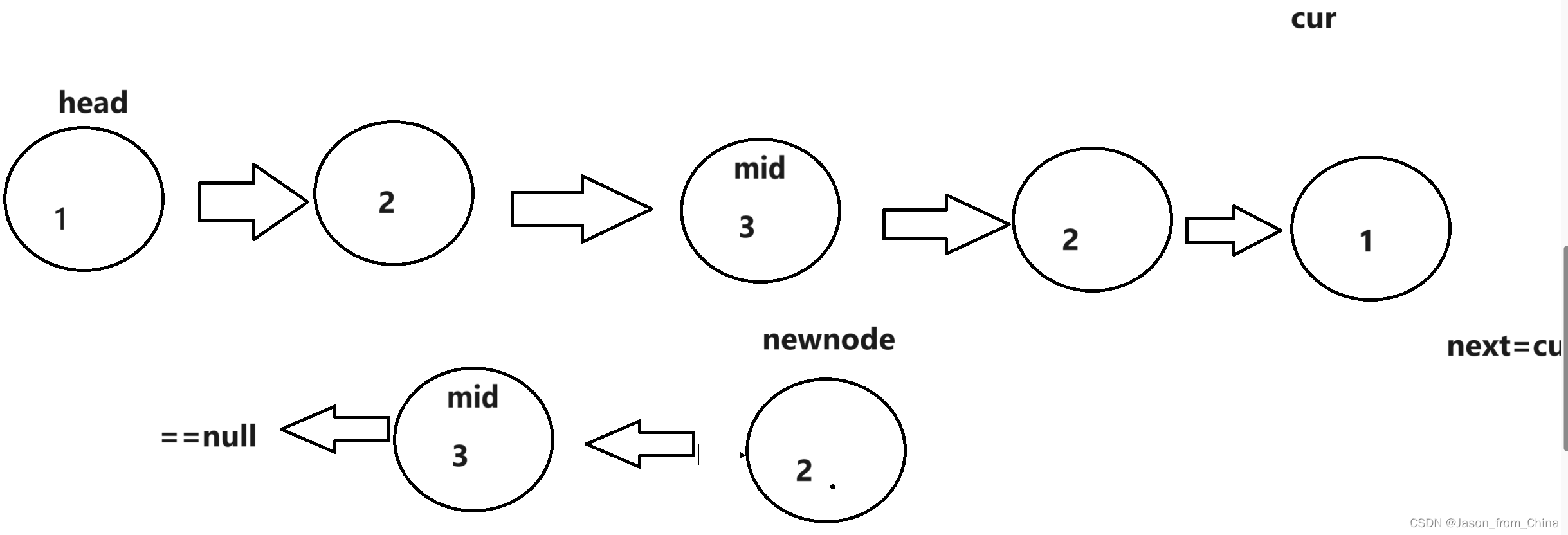
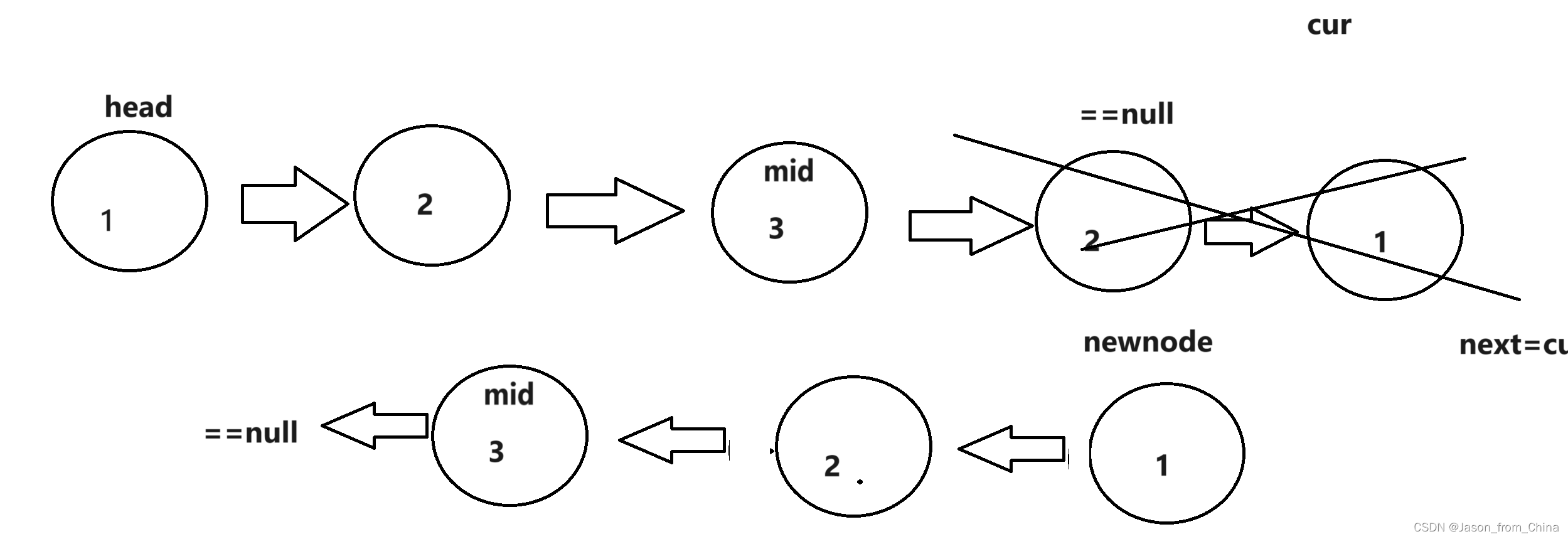
我们不能直接进行逆置,这样的话会导致最后进行对比的时候,产生循环所以我们需要让中间数值的下一个节点指向null,然后再进行下面节点的转化
3,最后进行对比
也就是,
代码
/* struct ListNode {int val;struct ListNode *next;ListNode(int x) : val(x), next(NULL) {} };*/ //进行重命名 #include <cstddef> class PalindromeList { public: typedef struct ListNode ListNode; //找到中间节点 ListNode* FindMid(ListNode* head) {if(head == NULL || head->next == NULL){return head;}ListNode*slow =head;ListNode*fast =head;//这里的判断判断全部都是奇偶数while(fast && fast->next){slow=slow->next;fast=fast->next->next;}//返回中间节点return slow; }//翻转链表 ListNode* Flip(ListNode* mid) {ListNode* newhead = NULL;ListNode* cur = mid;while (cur) {ListNode* next= cur->next;//进行头插,不能直接进行链表的翻转,不然会产生回环链表cur->next = newhead;newhead = cur;cur = next;}return newhead; }//进行对比,是回文结构就进行返回bool数值,不是的话返回null bool chkPalindrome(ListNode* A) {ListNode*mid= FindMid(A);ListNode*title=Flip(mid);while(A && title){if(A->val != title->val){return false;}A = A->next;title = title->next;}return true; }};



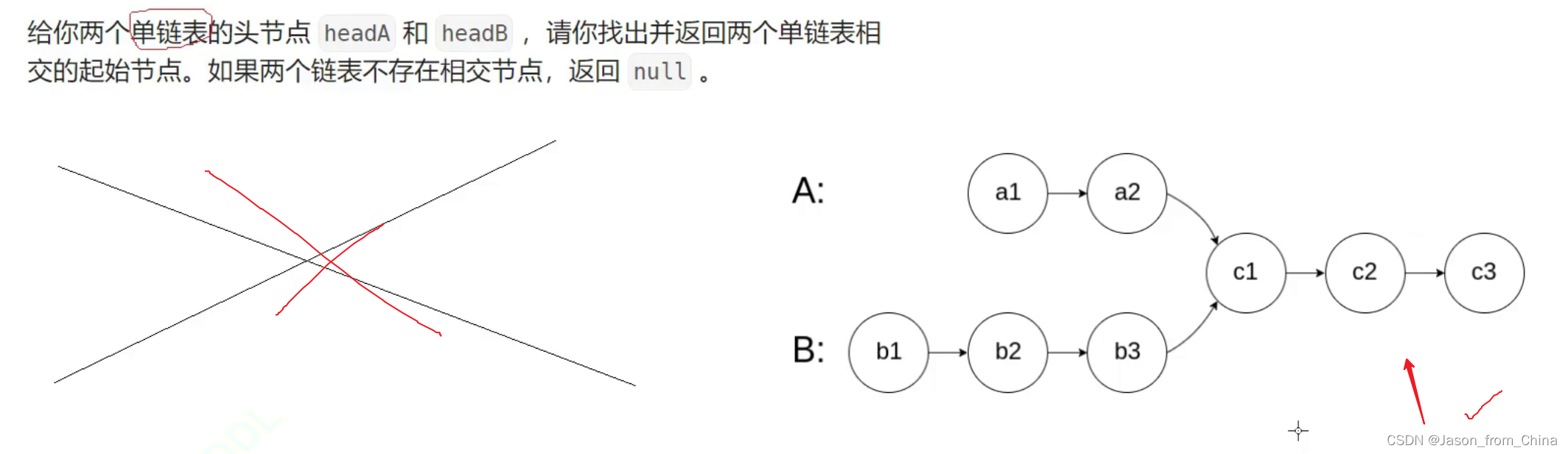
相交链表
160. 相交链表 - 力扣(LeetCode)
题目
解决思路
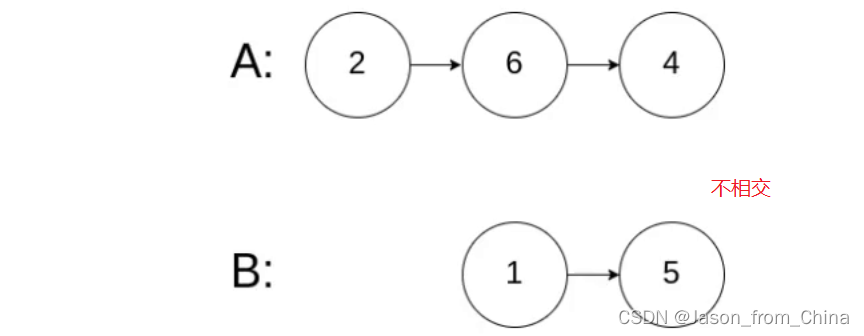
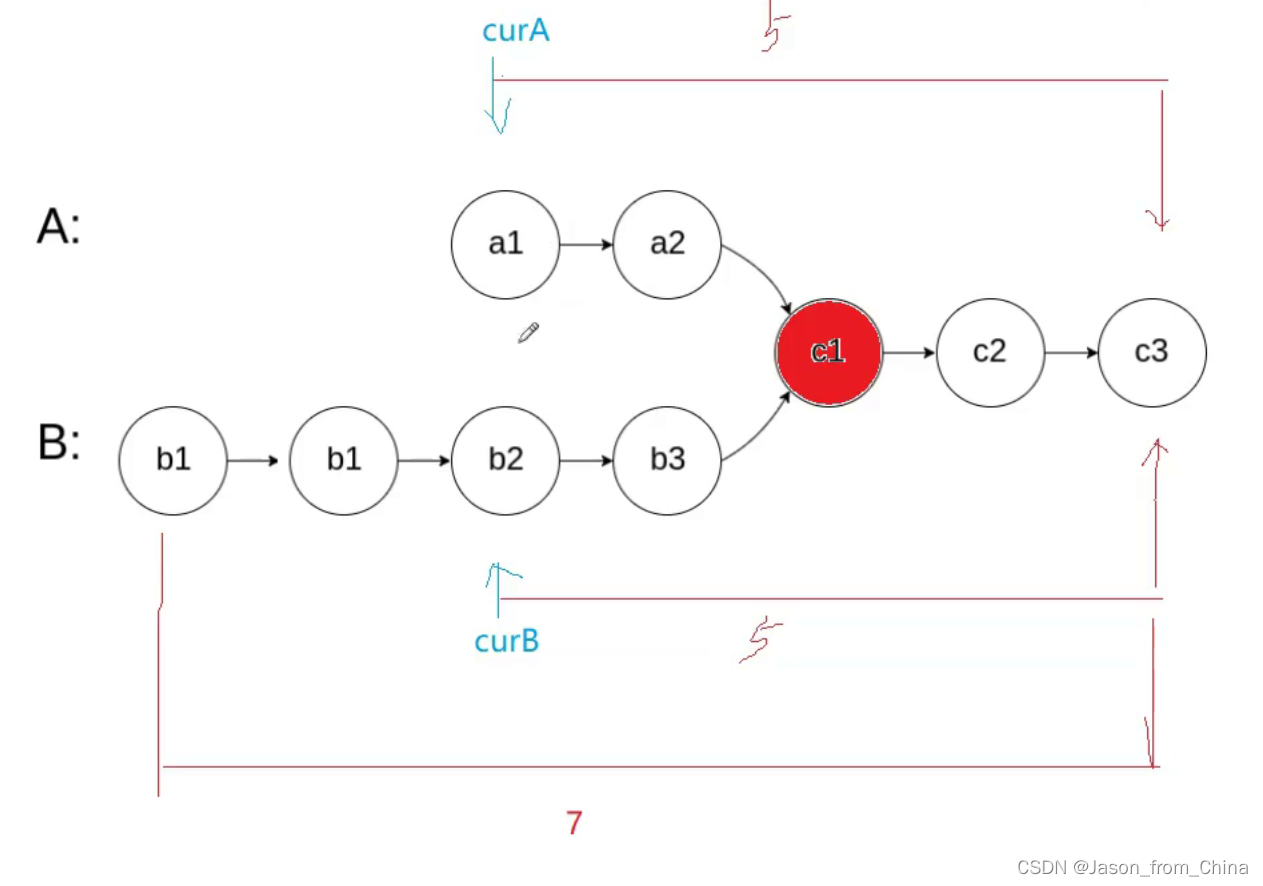
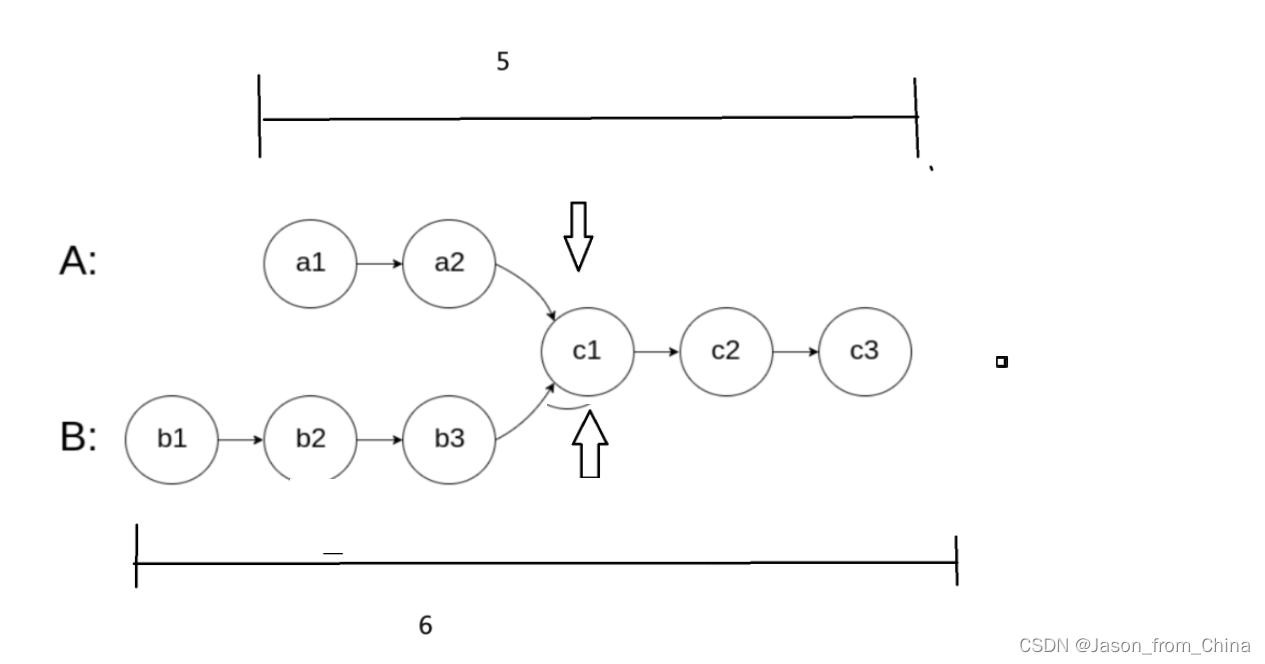
1,找到相交的点
相交链表的关键也就是找到相交的点,所以我们需要首先判断有没有相交的节点,没有相交的节点结束返回NULL,有相交的节点继续,此时我们已经算出各自的链表的长度(一次循环)
2,算出长度差值
3,遍历找到节点
最后一步两个节点同时移动,当两个节点的地址等于的时候,此时也就是找到了相交的节点
代码
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/ typedef struct ListNode ListNode; ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {//这里的起始节点是1,因为链表场赌博是从1开始计算的int contA = 1;int contB = 1;//进行判断,是不是有相同的尾结点ListNode*cureA = headA;ListNode*cureB = headB;while(cureA){cureA = cureA->next;//计算A链表的长度contA++;}while(cureB){cureB = cureB->next;//计算B链表的长度contB++;}if(cureA != cureB){return NULL;}//假设法,假设A长//长的先走,直到指向的位置是平行的if(contA > contB){int contsame = contA-contB;while(contsame--){headA = headA->next;}}else{int contsame = contB-contA;while(contsame--){headB = headB->next;}}//找到交点while(headA){if(headA == headB){return headA;}headA = headA->next;headB = headB->next;}return NULL; }

随机链表的复制
138. 随机链表的复制 - 力扣(LeetCode)
题目
给你一个长度为
n的链表,每个节点包含一个额外增加的随机指针random,该指针可以指向链表中的任何节点或空节点。构造这个链表的 深拷贝。 深拷贝应该正好由
n个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的next指针和random指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。例如,如果原链表中有
X和Y两个节点,其中X.random --> Y。那么在复制链表中对应的两个节点x和y,同样有x.random --> y。返回复制链表的头节点。
用一个由
n个节点组成的链表来表示输入/输出中的链表。每个节点用一个[val, random_index]表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。你的代码 只 接受原链表的头节点
head作为传入参数。
解题思路和图解
我们看见这个题目的时候首先就是看不懂,有点懵的。其实这都是我们想复杂了、这里你不能来回去追求random指向的节点的哪里,只需要直接进行拷贝就可以
步骤1(考察链表的创建,赋值):
- 首先我们需要复制链表节点
- 然后我们把赋值的节点里面是数值val放到复制的节点里面,这里是不需要赋值next的,因为你只需要直接进行插入就可以,形成新的长的链表。
- 一边复制一边把节点插入到原链表里面形成一个
步骤2(考察链表的逻辑关系):
- 此时我们复制val到链表里面并没有复制random也就是随机节点,所以这里我们需要复制随机节点
- 首先我们判断这个节点里面的random指向的节点是不是NULL,如果是NULL也就是说明指向空,也就是最后一个节点
- 如果不是NULL ,也就是说明,这个节点指向的下一个节点不是NUILL,此时我们需要注意,这里的关键点来了。我们需要让拷贝节点里面的random的地址是原链表的random指向的下一个节点,也就是random的->next,这样我们就达到我们不需要进行指向,直接就把地址拷贝过来。
步骤3(考察链表的插入):
- 最后一步,很简单,只需要把链表拷贝的节点和原链表分开
- 最后返回新链表的头结点
代码
/*** Definition for a Node.* struct Node {* int val;* struct Node *next;* struct Node *random;* };*///这里进行重命名一下,后期使用的时候不需要一直写struct typedef struct Node Node; Node* copyRandomList(Node* head) {//创建节点,复制节点,插入节点Node* cur = head;while(cur){//创建节点,并且进行检验Node* copy = (Node*)malloc(sizeof(Node));if(copy == NULL){perror("copyRandomList:copy:error");exit(1);}//复制数值copy->val = cur->val;//插入链表(这一步,两个不能交换)copy->next = cur->next;cur->next = copy;//遍历cur = copy->next;}//复制random节点cur = head;//cur一移动了重新指向头结点while(cur){Node* copy = cur->next;//找到copy拷贝节点,这里必须是循环里面的,因为每次都需要改变位置if(cur->random == NULL){copy->random = NULL;}else{copy->random = cur->random->next;}//遍历cur = copy->next;}//取出需要的节点,返回头结点cur = head;//cur一移动了重新指向头结点Node* copyhead = NULL;Node* copytile = NULL;//创建头结点和尾结点,不创建哨兵位了while(cur){//这一步已经完成循环移动了,我们只需要每次移动cur就可以完成整体的移动Node* copy = cur->next; Node* pure = copy->next;if(copytile == NULL){copyhead = copytile = copy;}else{//进行尾插copytile->next = copy;copytile = copytile->next;}cur = pure;}//返回新链表头结点return copyhead; }
环形链表(是否成环)(简单)(证明题)
141. 环形链表 - 力扣(LeetCode)
题目
解题思路
1,我们把判断问题,用快慢指针搞成追击问题
代码
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*///如果链表中存在环 ,则返回 true 。 否则,返回 false 。 typedef struct ListNode ListNode; bool hasCycle(struct ListNode *head) {//快慢指针来解决ListNode* slow = head;ListNode* fast = head; while(fast && fast->next){slow = slow->next;fast = fast->next->next;if(fast == slow){return true;}}return false; }1,为什么一定会相遇,有没有可能错过,永远追不上?请证明(面试题)
一定会相遇
证明:已知这里是一次走两步
所以我们按照快指针一次两步进行推算
已知是快慢指针,所以我们已经从判断问题,变成了追击问题,
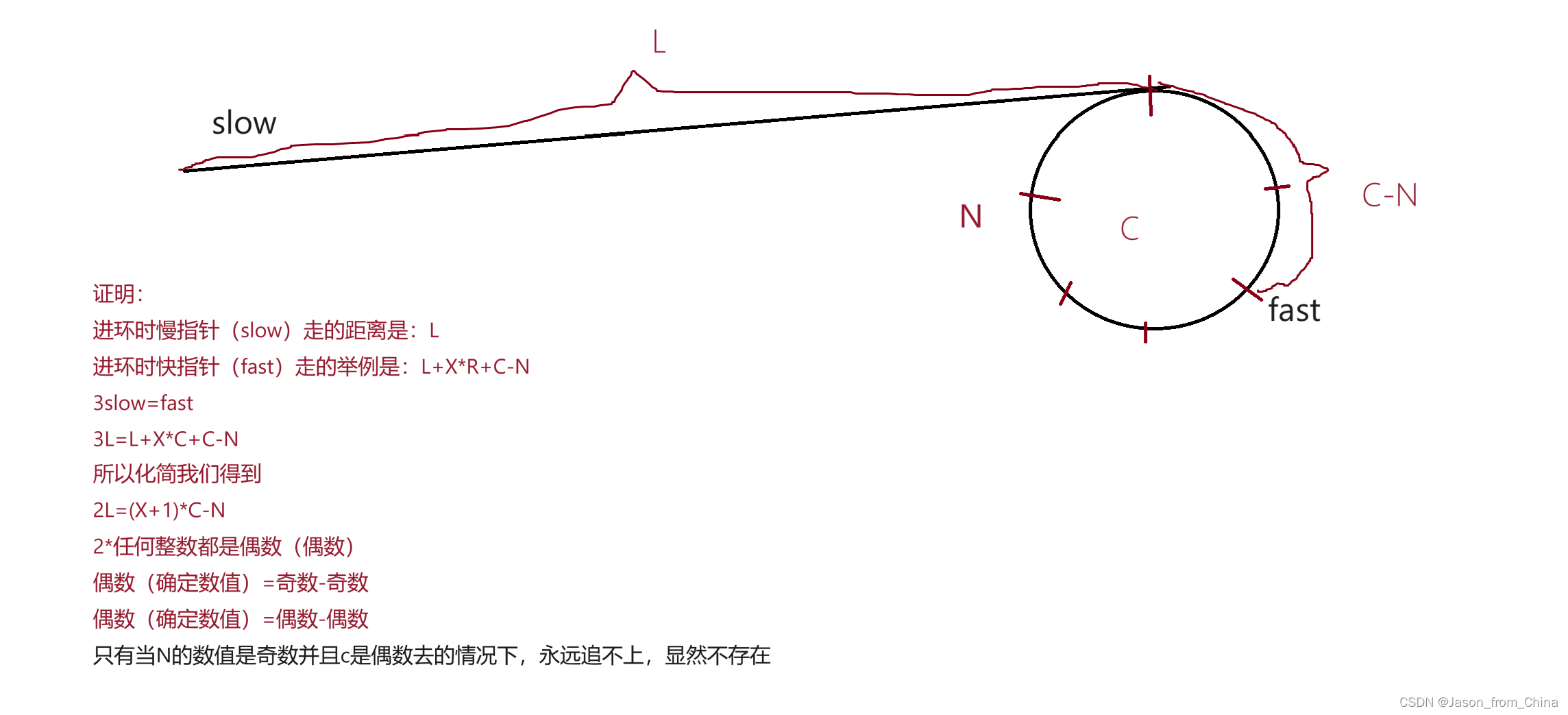
2,slow一次走一步,fast一次走3,4,5,6,n步行不行,为什么,请证明
证明:这里我们需要假设是快指针一次走三步
那此时说明3slow==fast
也就是三倍距离
所以我们进行证明
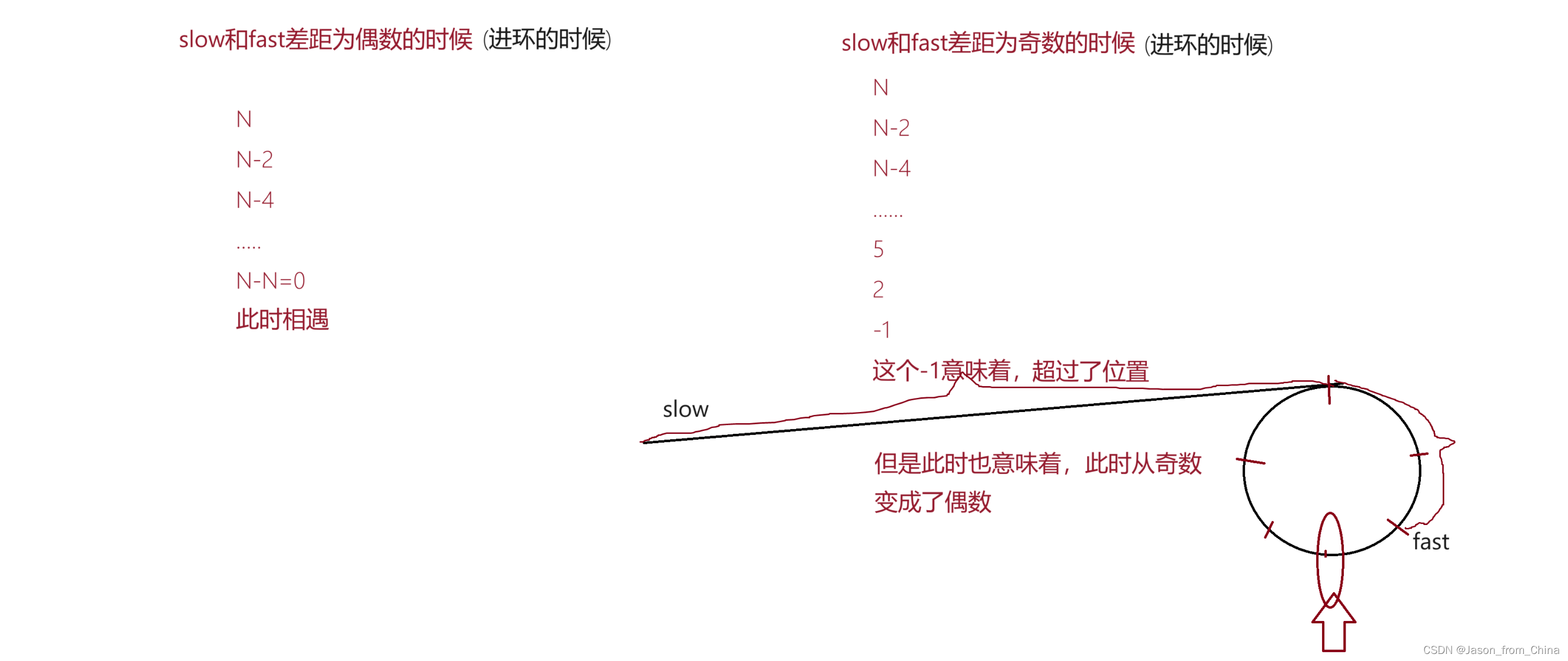
那么此时有两种可能性
第一种也就是当差距为偶数的时候
第二种也就是当差距为奇数的时候
因为进环之后开始追击,所以我们开始-数值
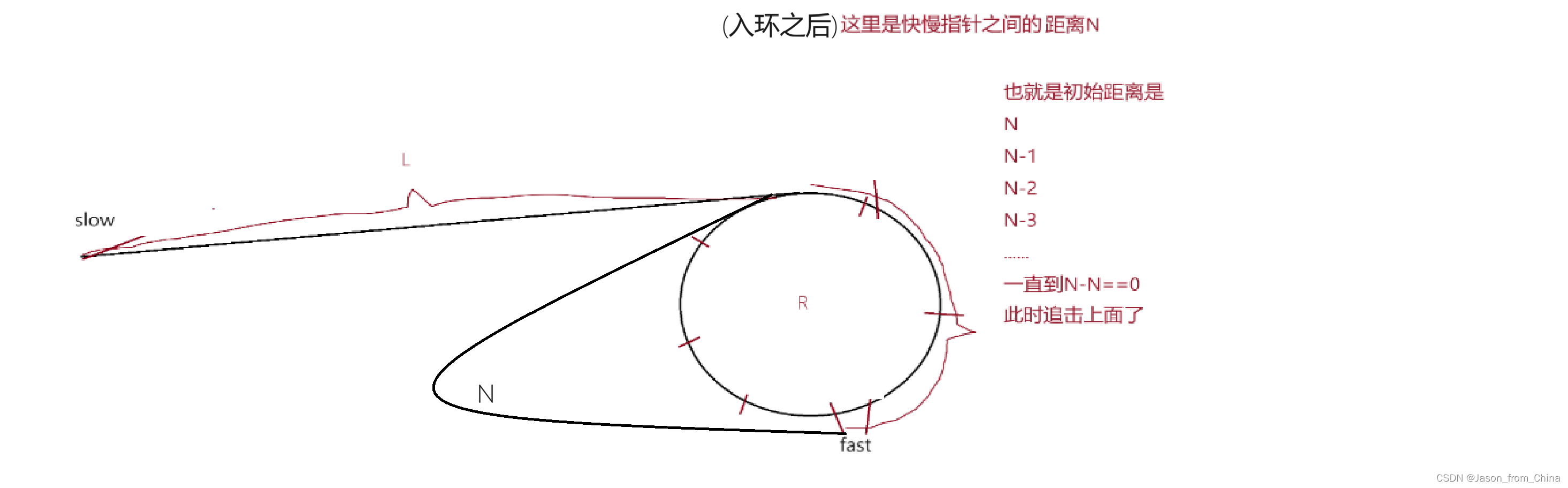
是否存在追不上的情况(证明)
什么情况下会追不上,也就是当第一次循环没有追上,第二次-1依旧是奇数没有追上,那么此时存在追不上的情况,但是这种情况是否存在?接下来我们进行证明。


环形链表(成环的相交的节点在哪)(中等)(证明题)
142. 环形链表 II - 力扣(LeetCode)
题目
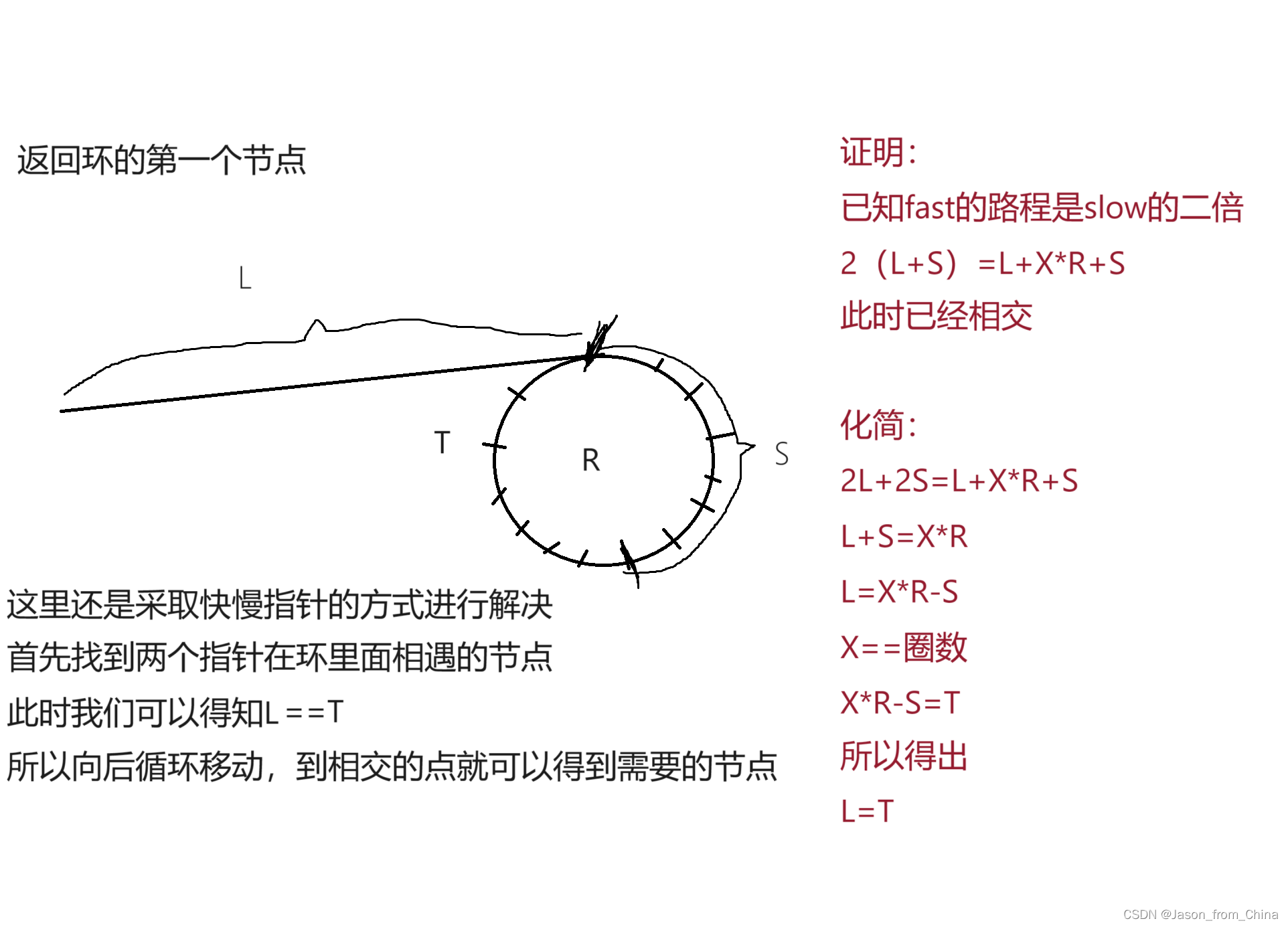
解题思路(证明一下)
这里的关键点在于你需要证明L==T
然后就可以解题
代码
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode; ListNode *detectCycle(ListNode *head) {ListNode* fast = head;ListNode* slow = head;while(fast && fast->next){fast = fast->next->next;slow = slow->next;if(fast == slow){ListNode* cur = head;ListNode* meet = slow;while(cur != meet){cur = cur->next;meet = meet->next;}return meet;}}return NULL; }

顺序表和链表之间区别
顺序表和链表是两种基本的数据结构,它们在存储方式和操作特性上有所不同:
1. **存储方式**:
- **顺序表**:顺序表是连续的内存空间,元素按顺序依次存放。每个元素的地址可以通过首元素地址加上偏移量来直接计算。
- **链表**:链表中的元素可以分散地存储在内存中,每个元素(节点)包含数据和指向下一个节点的指针。链表的存储是非连续的,节点间通过指针连接。
2. **元素访问**:
- **顺序表**:可以直接通过索引快速访问任何一个元素,时间复杂度为O(1)。
- **链表**:访问特定节点需要从头节点开始,按顺序遍历,时间复杂度为O(n)。
3. **插入和删除操作**:
- **顺序表**:插入或删除元素时,可能需要移动大量元素以保持连续性,时间复杂度为O(n)。
- **链表**:插入或删除元素只需改变指针,时间复杂度为O(1)(但查找插入位置或删除节点仍需O(n))。
4. **空间利用**:
- **顺序表**:需要预先分配固定大小的内存空间,可能会造成空间浪费。
- **链表**:动态分配内存,更灵活地利用空间。
5. **内存分配**:
- **顺序表**:通常在栈上或通过malloc一次性分配。
- **链表**:节点在堆上动态分配,通过指针链接。
6. **适用场景**:
- **顺序表**:适用于频繁随机访问元素的场合。
- **链表**:适用于频繁插入和删除元素的场合。
两者各有优势,选择哪种数据结构取决于具体应用场景和需求。在实际应用中,还会根据需要衍生出多种链表的变体,如双向链表、循环链表等,以适应不同的应用场景。
原地扩容和异地扩容
原地扩容(In-place expansion)和异地扩容(Out-of-place expansion)通常是指在数据结构或存储系统中对容量进行扩展的两种方式。
1. **原地扩容(In-place expansion)**:
- 这种方式通常指的是在原有的空间内进行扩容,不需要移动数据到新的位置。
- 例子包括:在数组或内存池中,当需要更多空间时,可以在原有内存地址后追加更多的空间。这种方式可能涉及到复杂的内存管理,因为可能需要重新分配更大的连续内存块,并移动原有数据到新位置。
2. **异地扩容(Out-of-place expansion)**:
- 异地扩容则是将数据移动到一个新的、更大的空间中,通常是创建一个新的数据结构或存储空间,然后将旧数据复制或迁移到新空间。
- 例子包括:在链表结构中,可以通过创建新的节点并在新节点中存储更多的数据来实现扩容。在文件系统中,可能需要将文件从一个分区移动到另一个更大的分区。
在具体的技术应用中,原地扩容和异地扩容有其各自的优缺点:
- 原地扩容可能更高效,因为它不需要复制大量数据到新的位置,但可能涉及到复杂的内存管理和潜在的内存碎片问题。
- 异地扩容可能更简单实现,因为它通常涉及到创建新的资源,但数据迁移过程可能会耗费较多时间和资源。
选择哪种扩容方式取决于具体的应用场景、资源限制以及对性能的要求。在设计数据结构和系统时,通常会根据实际需求来决定最合适的扩容策略。原地扩容和异地扩容
原地扩容
异地扩容
这里不要释放 不管是原地还是异地
如果是原地扩容说明是原来的地址
如果是异地扩容,则不需要手动释放,会主动释放


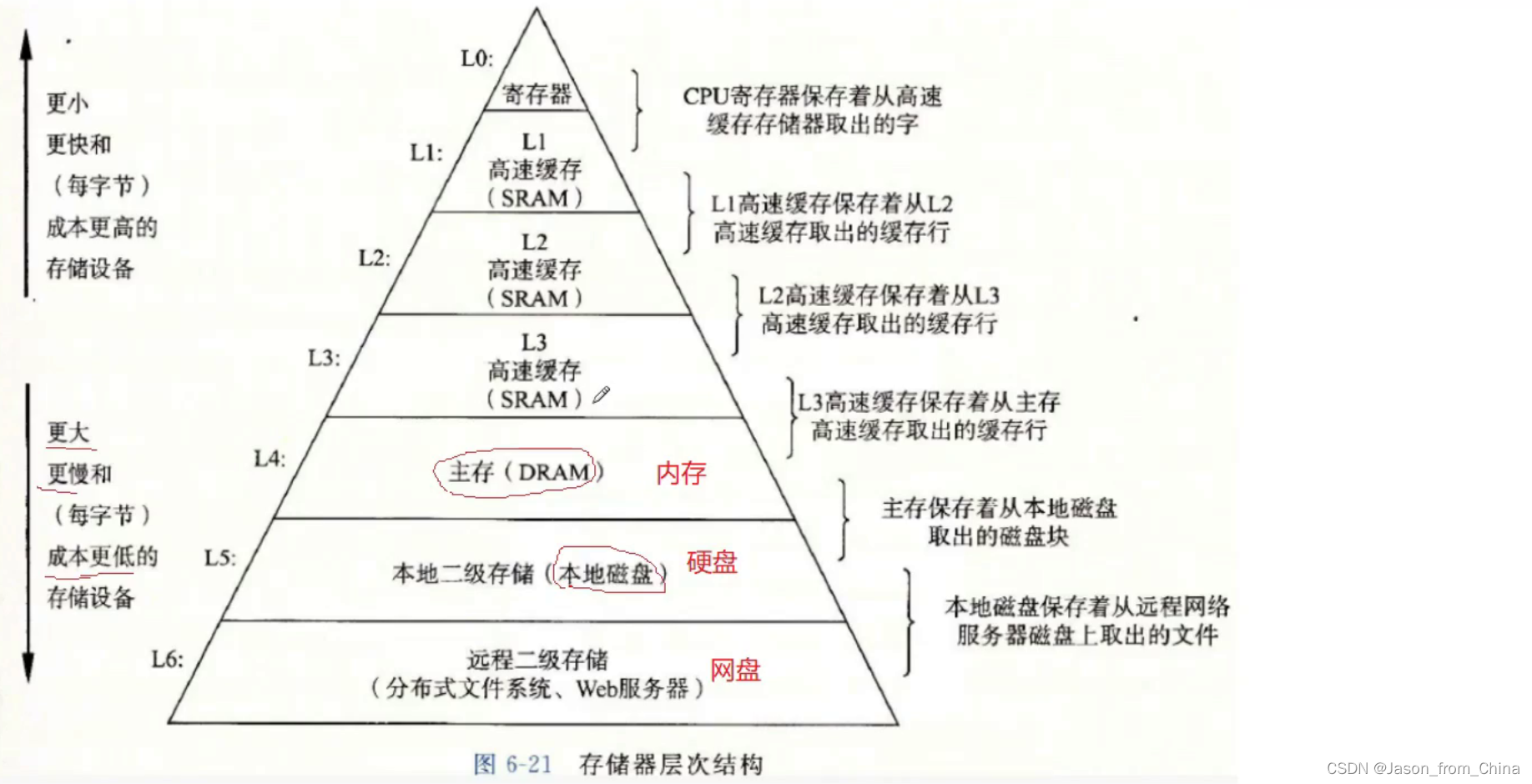
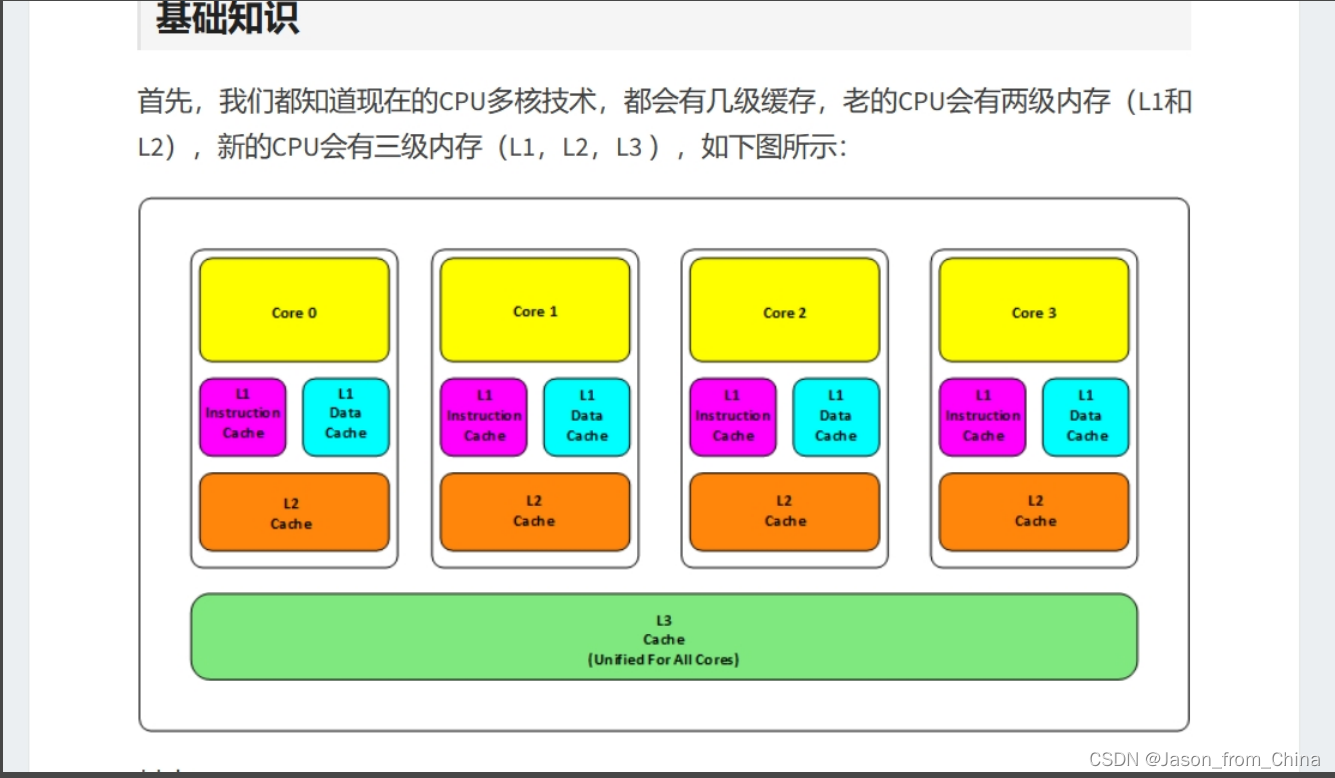
计算机的存储体系
存在内存里面的时候 不通电是不行的 这里是临时存储的
内存的存储速度比硬盘快
这里是越往下越便宜
eax寄存器
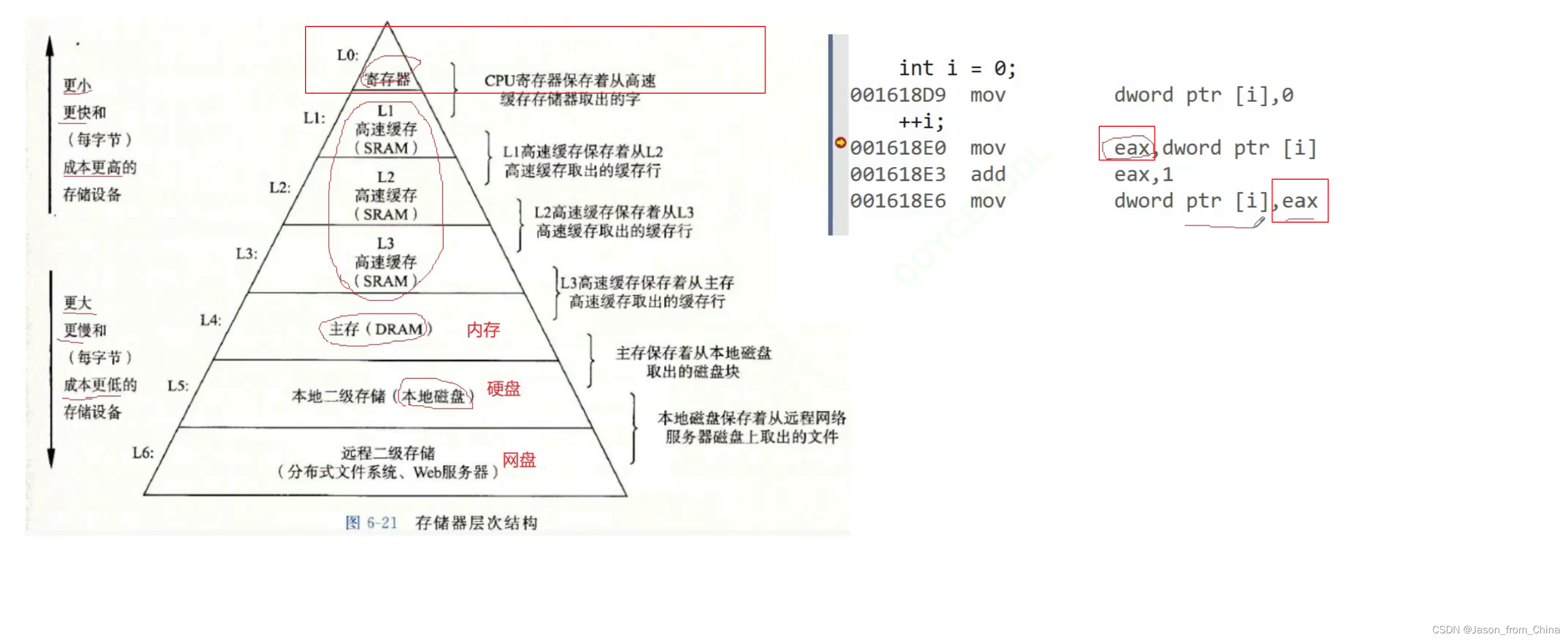
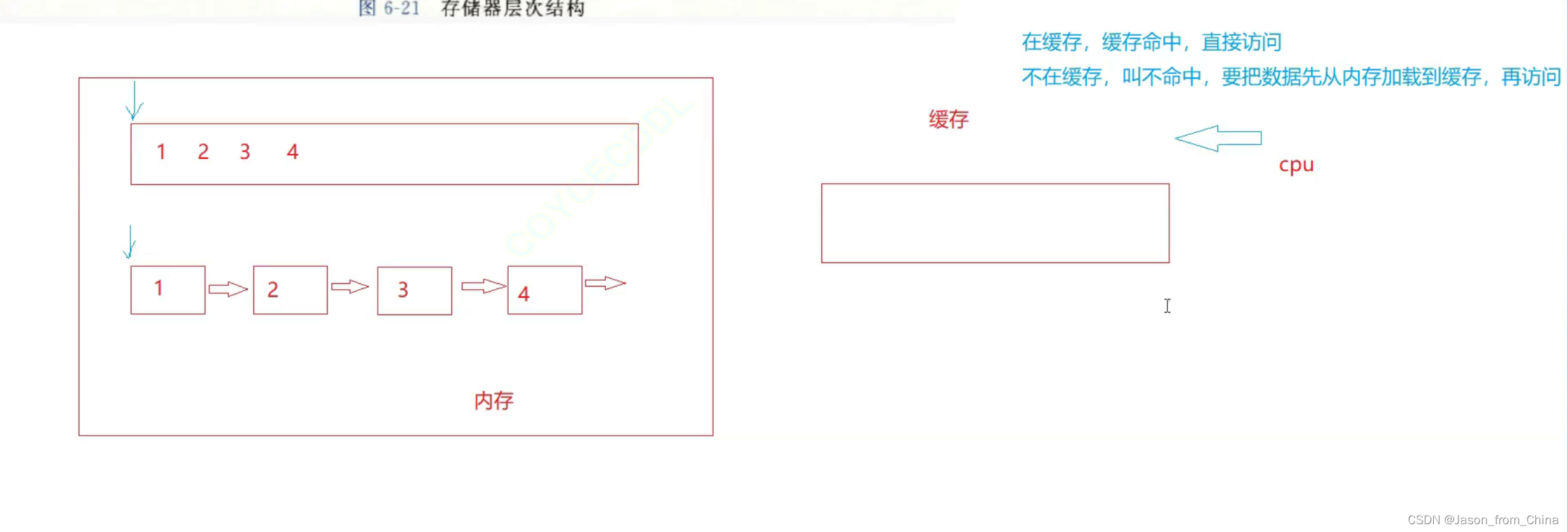
cpu是不会直接访问内存的
因为觉得太慢了
所以一般加载到缓存再访问
然后进行访问
与程序员相关的CPU缓存知识 | 酷 壳 - CoolShell





![[单机]成吉思汗3_GM工具_VM虚拟机](https://img-blog.csdnimg.cn/img_convert/ee9be78a18d7d5bc082500017469ba5b.webp?x-oss-process=image/format,png)