目录
1 文本相似度评估
2 代码
2.1 load_dataset 方法
2.2 AutoTokenizer、AutoModelForSequenceClassification
1 文本相似度评估
对两个文本拼接起来,然后作为一个样本喂给模型,作为一个二分类的任务;

数据处理的方式以及训练的基本流程与上文相似。
2 代码
- 数据预处理,把需要对比的文本放置一起,作为一个样本; tokenizer: 输入的语句是两个。分类标签的类型必须是 int,不能是其他的类型;
- 加载模型。
- 输出结果;
2.1 load_dataset 方法
datasets是抱抱脸开发的一个数据集python库,可以很方便的从Hugging Face Hub里下载数据,也可很方便的从本地加载数据集,本文主要对load_dataset方法的使用进行详细说明。
def load_dataset(
path: str,
name: Optional[str] = None,
data_dir: Optional[str] = None,
data_files: Union[Dict, List] = None,
split: Optional[Union[str, Split]] = None,
cache_dir: Optional[str] = None,
features: Optional[Features] = None,
download_config: Optional[DownloadConfig] = None,
download_mode: Optional[GenerateMode] = None,
ignore_verifications: bool = False,
save_infos: bool = False,
script_version: Optional[Union[str, Version]] = None,
**config_kwargs,
) -> Union[DatasetDict, Dataset]:path:参数path表示数据集的名字或者路径。可以是如下几种形式(每种形式的使用方式后面会详细说明)
数据集的名字,比如imdb、glue
数据集文件格式,比如json、csv、parquet、txt
数据集目录中的处理数据集的脚本(.py)文件,比如“glue/glue.py”
name:参数name表示数据集中的子数据集,当一个数据集包含多个数据集时,就需要这个参数,比如glue数据集下就包含"sst2"、“cola”、"qqp"等多个子数据集,此时就需要指定name来表示加载哪一个子数据集
data_dir:数据集所在的目录
data_files:数据集文件
cache_dir:构建的数据集缓存目录,方便下次快速加载。
2.2 AutoTokenizer、AutoModelForSequenceClassification
| 类名称 | 介绍 |
| AutoTokenizer | AutoTokenizer 是 Hugging Face Transformers 库中的一个类,用于自动选择适合特定预训练模型的 tokenizer。该类可以根据指定的模型名称或路径,自动选择对应的 tokenizer 类型,无需手动指定。这样可以方便地在不同的预训练模型之间切换,而无需更改代码中的 tokenizer 类型。 |
| AutoModelForSequenceClassification | AutoModelForSequenceClassification 是 Hugging Face Transformers 库中的一个类,用于自动选择适合特定预训练模型的用于序列分类任务的模型。这个类会根据指定的模型名称或路径自动选择对应的模型类型,无需手动指定。这样可以方便地在不同的预训练模型之间切换,而无需更改代码中的模型类型。 |
| Trainer | Trainer 是 Hugging Face Transformers 库中用于训练和评估模型的高级 API。它提供了一个简单而强大的接口,用于管理训练循环、验证循环、日志记录、保存模型等任务。使用 Trainer 可以方便地训练和微调预训练模型,同时还支持分布式训练和混合精度训练等功能。 |
| TrainingArguments | TrainingArguments 是 Hugging Face Transformers 库中用于配置训练参数的类。通过 TrainingArguments 类,可以指定训练过程中的各种参数,如训练轮数、学习率、批次大小、日志路径、模型保存路径等。这些参数可以帮助控制训练过程的行为,并对训练过程进行定制。 |
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset,load_from_disk
import traceback
from sklearn.model_selection import train_test_split#dataset = load_dataset("json", data_files="../data/train_pair_1w.json", split="train")
dataset = load_dataset("csv", data_files="/Users/user/studyFile/2024/nlp/text_similar/data/Chinese_Text_Similarity.csv", split="train")datasets = dataset.train_test_split(test_size=0.2,shuffle=True)import torchtokenizer = AutoTokenizer.from_pretrained("../chinese_macbert_base")
def process_function(examples):tokenized_examples = tokenizer(examples["sentence1"], examples["sentence2"], max_length=128, truncation=True)# 注意int(label)tokenized_examples["labels"] = [int(label) for label in examples["label"]]return tokenized_examplestokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
#tokenized_datasets# 创建模型
from transformers import BertForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("../chinese_macbert_base")import evaluate
acc_metric = evaluate.load("./metric_accuracy.py")
f1_metirc = evaluate.load("./metric_f1.py")
#
# acc_metric = evaluate.load("accuracy")
# f1_metirc = evaluate.load("f1")
def eval_metric(eval_predict):predictions, labels = eval_predict#print(predictions,labels)predictions = predictions.argmax(axis=-1)#predictions = [int(p > 0.5) for p in predictions]labels = [int(l) for l in labels]# predictions = predictions.argmax(axis=-1)acc = acc_metric.compute(predictions=predictions, references=labels)f1 = f1_metirc.compute(predictions=predictions, references=labels)acc.update(f1)return acc
train_args = TrainingArguments(output_dir="./cross_model", # 输出文件夹per_device_train_batch_size=32, # 训练时的batch_sizeper_device_eval_batch_size=32, # 验证时的batch_sizelogging_steps=10, # log 打印的频率evaluation_strategy="epoch", # 评估策略save_strategy="epoch", # 保存策略save_total_limit=3, # 最大保存数learning_rate=2e-5, # 学习率weight_decay=0.01, # weight_decaymetric_for_best_model="f1", # 设定评估指标load_best_model_at_end=True) # 训练完成后加载最优模型
train_args
from transformers import DataCollatorWithPadding
trainer = Trainer(model=model, args=train_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"], data_collator=DataCollatorWithPadding(tokenizer=tokenizer),compute_metrics=eval_metric)
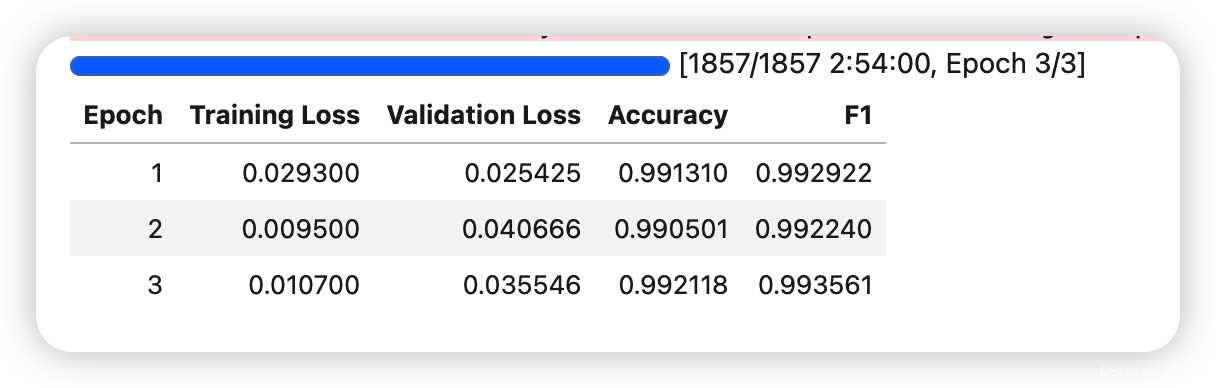
trainer.train()