1.简介
JDK1.5之前,由于那个版本尚未退出专门运行在并发环境下的集合,对于List类型,我明只能选择Vector或者Stack这种老古董,但是它们效率太低(全部的增删改方法均被synchronized修饰着,那个时候的synchronized由于还没有经过长期充分的优化,性能很低下):
而JDK1.5之后引入了java.utl.concurrent包,其中提供了很多适用于并发环境的集合,而在这其中,List的对应的唯一实现就是CopyOnWriteArrayList!
2.基本原理
在大多数业务场景中,读操作往往是远大于写操作的,而Vector、Stack不管是读还是写都要进行加锁,对于读的情况加锁不仅是毫无意义的(读读状态下),而且还会大大降低了读的效率。因此,CopyOnWriteArrayList实现了读读、读写共存,写写互斥,从而大幅度提升读写性能。
CopyOnWriteArrayList是通过Copy-On-Write(写时复制,简称COW)这一技术实现了上面的目标。
写时复制:
当多个调用者需要访问同一份资源时,如果它们发出的都是读操作,那么它们将共享同一份原始资源,一旦有某个调用者发出写操作,系统将自动为其拷贝一份原始资源的副本供其使用,后续该调用者的写操作均发生在该资源副本上面,其他的资源调用者不受影响。

具体实现思路为:
- 对于增删改操作:先拷贝一份原始数组,然后在这个原始数组的副本上进行增删改操作,操作完再赋值回去。
- 对于读操作:流程与普通读操作一致,但是与
Vector、Stack不同,这个操作不加锁。
写时复制的缺点:
- 内存占用:由于写操作需要触发资源拷贝,一旦原始资源大小较为庞大,则拷贝的过程可能会导致内存资源不足。
- 写操作开销大:写之前需要拷贝原始资源,然后修改后再替换掉原始资源,整个过程要比普通写操作开销大。
- 存在数据一致性问题:在写操作结束后 - 替换掉原始资源之前的这段时间内,可能会出现数据不一致的情况。
3.源码分析
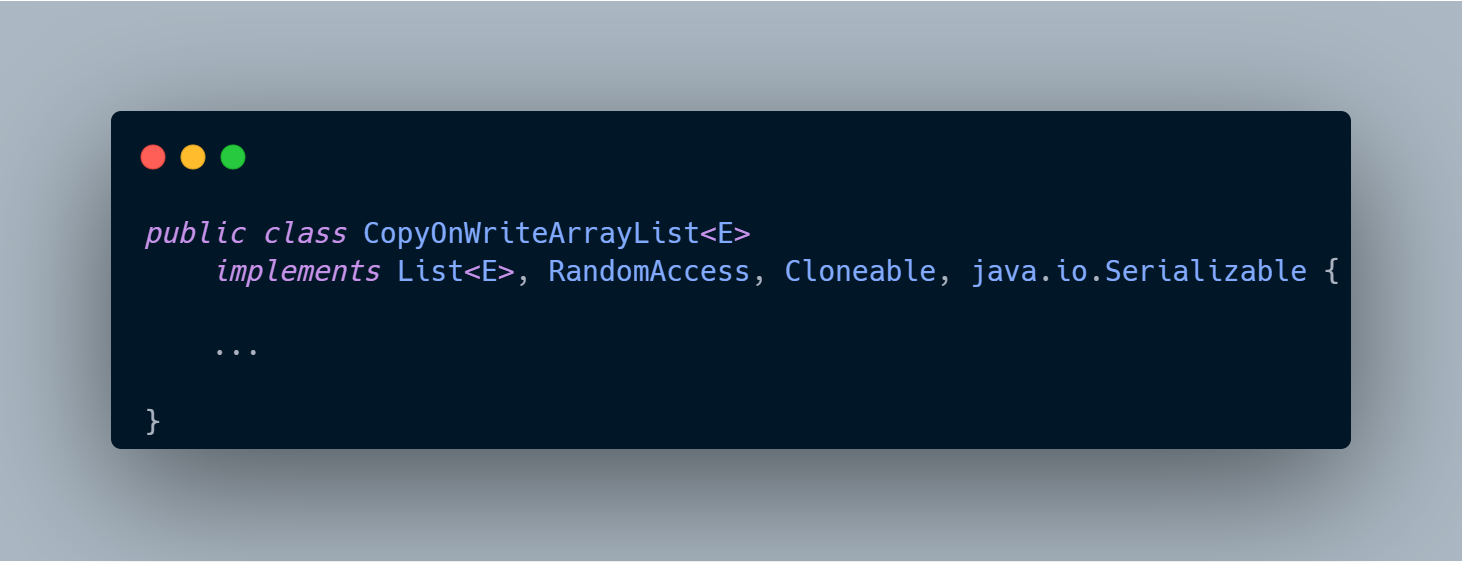
3.1 类定义
 ")
")
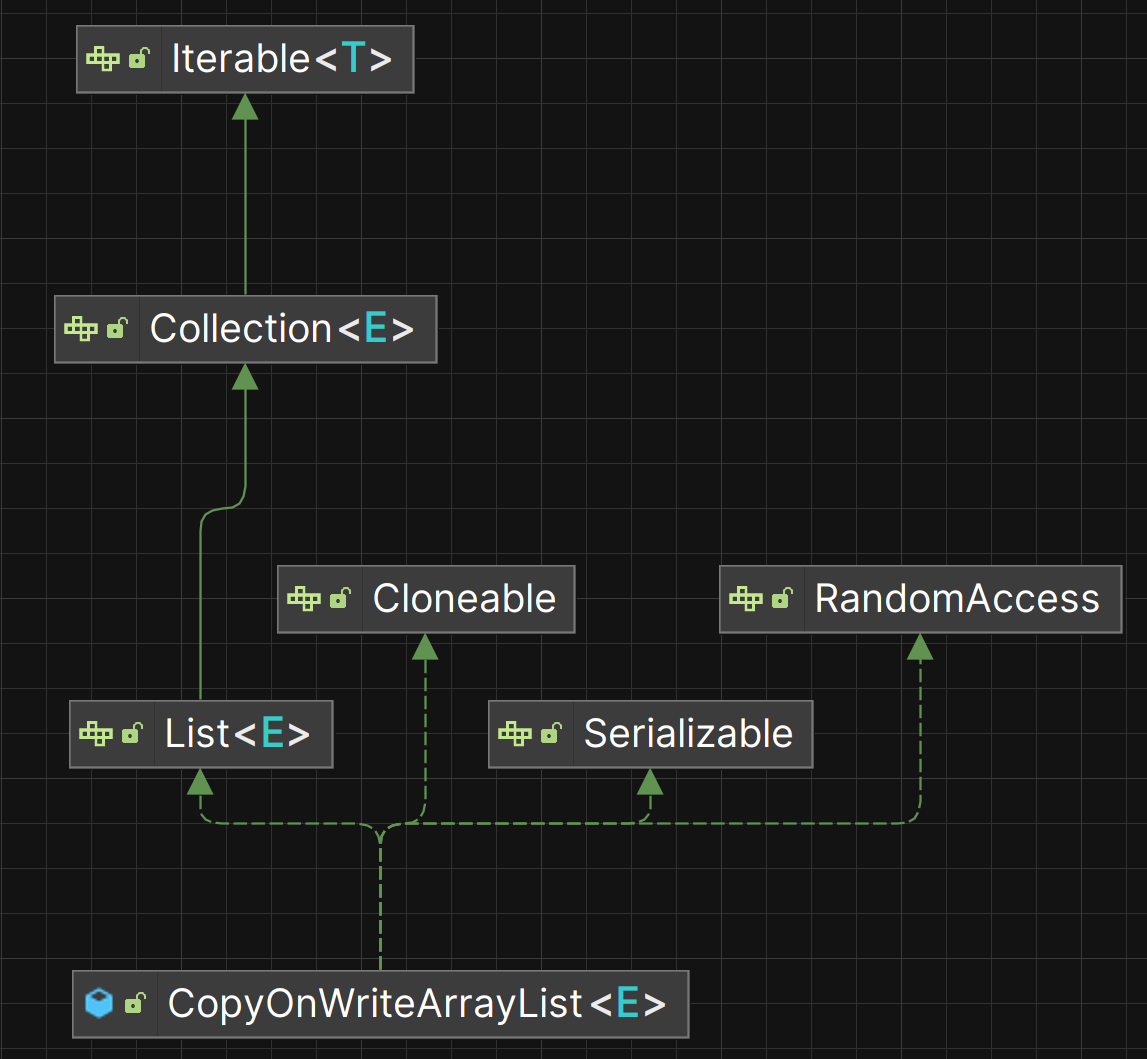
CopyOnWriteArrayList实现了以下接口:
- List:说明它属于链表的一种,操作与链表基本保持一致。
- RandomAccess:支持随机访问/下标访问,也暗示了它的低层数据结构很有可能是数组!
- Cloneable:通过重写
clone方法实现了对象的深/浅拷贝。 - Serializable:可序列化,即 可将该对象转换为字节流以实现持久化存储或网络传输。
 ")
")
3.2 初始化
 ")
")
 ")
")
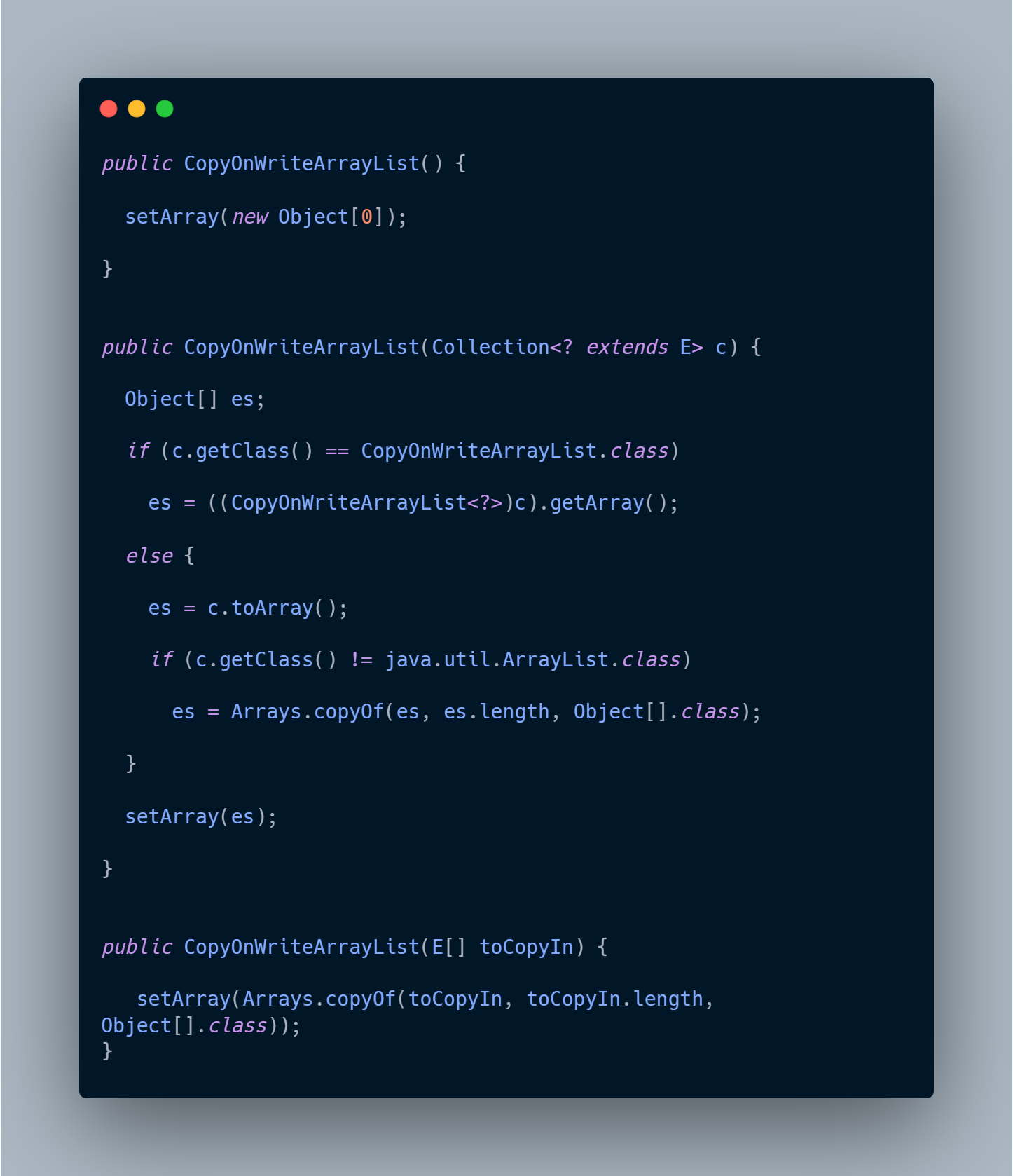
这里,我们仅先介绍一下中间的构造方法:
- 首先它先判断了传入的集合是否与它类型一致,都是
CopyOnWriteArrayList,如果是的话,那直接通过getArray方法获取其内部的数组并赋值即可。 - 如果类型不一致,则调用集合的
toArray方法获取其内部的元素集合转换后得到的数组,然后判断该数组的类型是否为Object[].class,如果是的话,则直接赋值;否则需要通过调用Arrays.copyOf方法,将该元素由原来的数组复制到新创建的Object数组中之后,再去将该新创建的Object数组赋值给elements字段。
这里说明一下,为什么调用
toArray方法拿到集合元素构成的数组之后不直接赋值,并且elements字段是Object[]类型,不应该存在赋不了值的情况,这是为什么呢?
首先我们看到,这里的赋值都是将数组的引用直接赋值给elements字段的,而ArrayList的目标是尽可能地使内部的elements类型是Object[],哪怕它存储的元素不是Object类型。因为可能会存在这种情况,就是你指定ArrayList的泛型为类A,而初始化时,你传入了类A的子类B构成的集合,如果没有上面的操作的话,它是可以被成功复制给elements字段的,那后续如果我再往里面添加类A的对象时,就会报错。而集合的toArray方法没有被final修饰,是可以被重写的,而由方法重写的规则我们可知,我们完全可以在重写的toArray方法中返回一个泛型子类构成的数组!因此,上面的检查并转换的操作是很有必要的。
3.3 add
这里,由于CopyOnWriteArrayList中重载了多个add方法:
所以这里以add(int index, E element)以小见大,进行讲解:
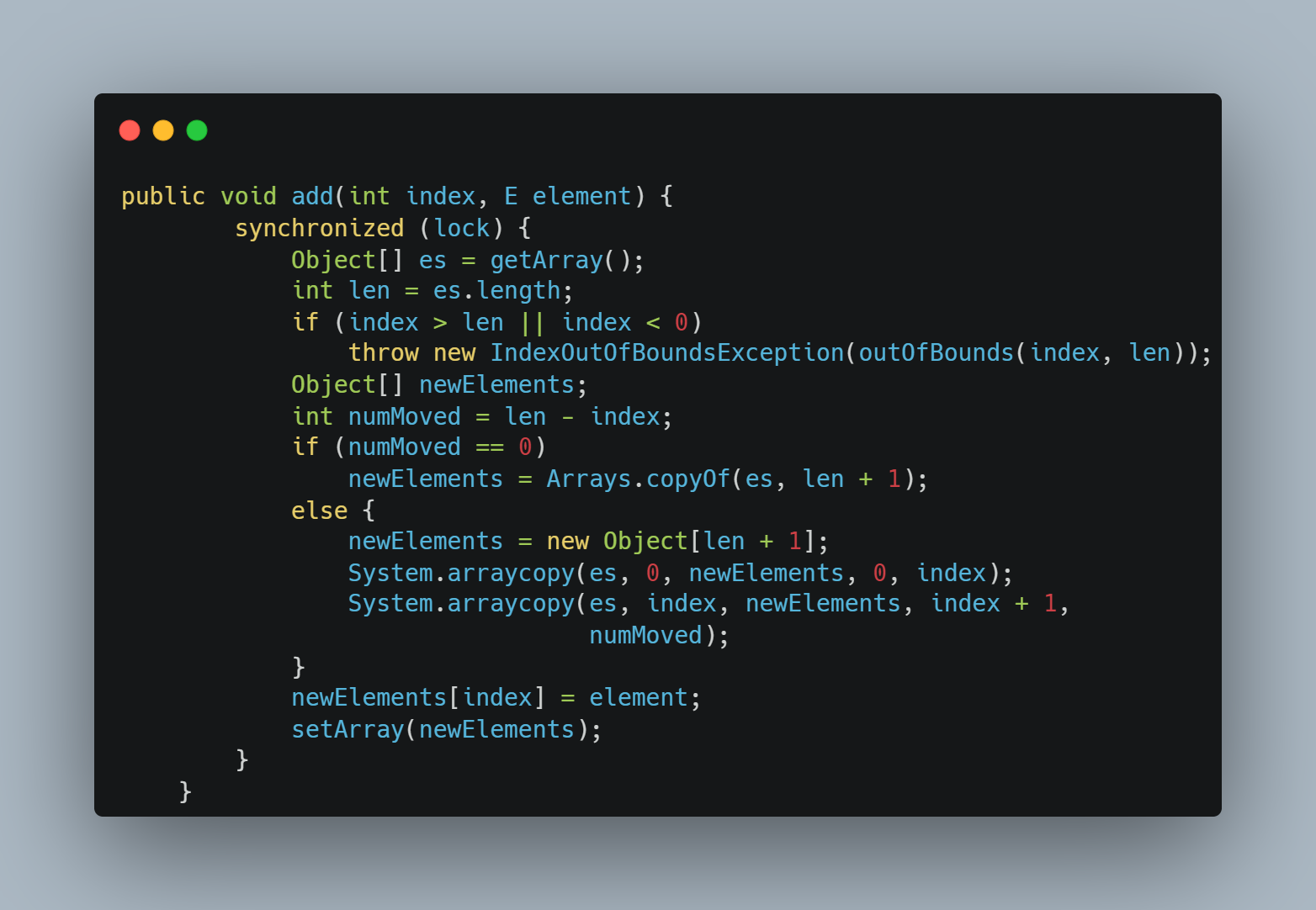 方法源码(JDK17)")
方法源码(JDK17)")
执行流程
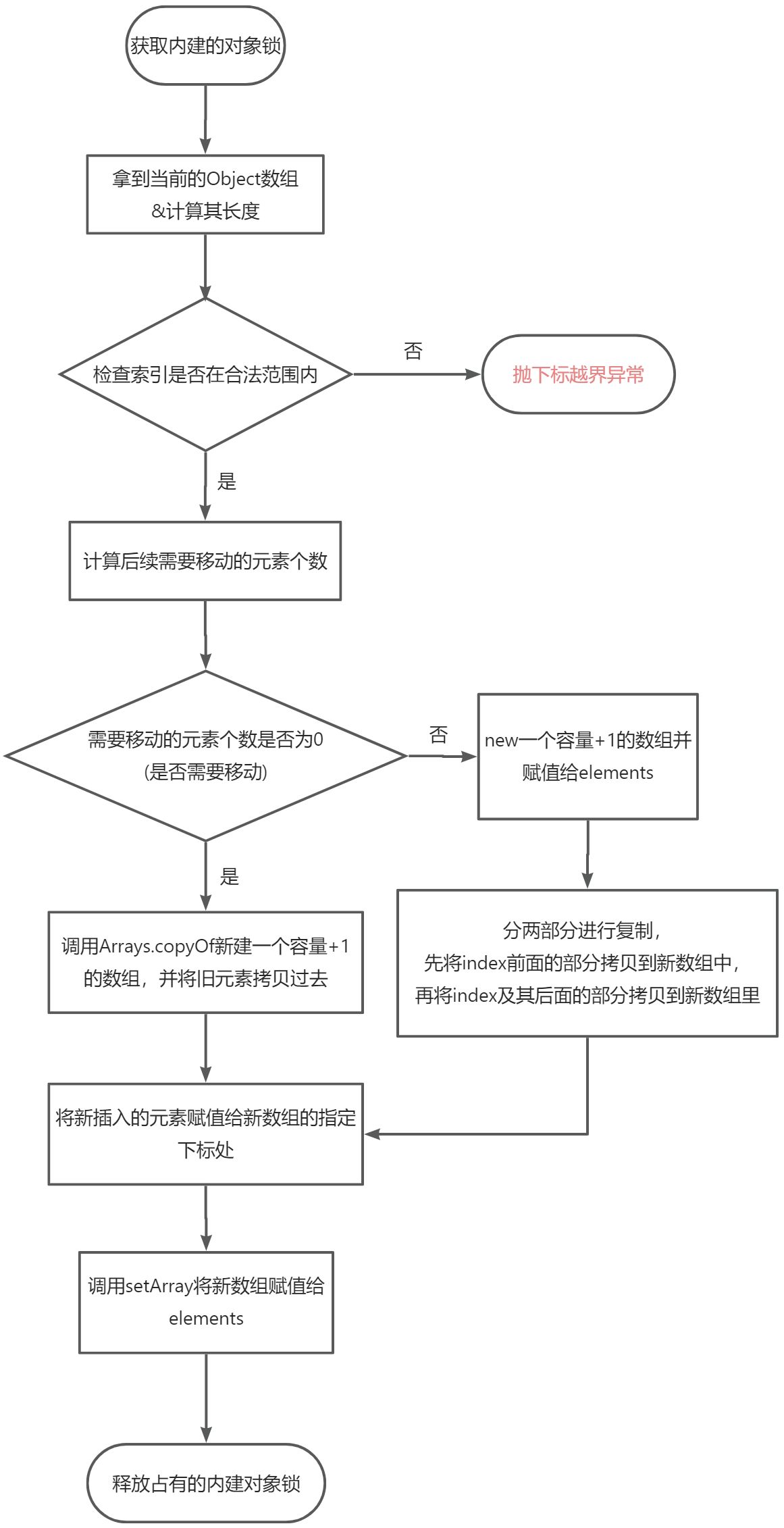
评估
- 可以发现,我们是在获取锁之后再去执行添加操作,这根除了并发性问题。
- 添加的基本过程是
拷贝数组 -> 添加元素到新数组 -> 将新数组重新赋值给elements,这正式写时复制策略的体现。 - 由于添加过程涉及到数组的拷贝,因此空间复杂度为O(n)。
CopyOnWriteArrayList没有扩容操作,因此每次数组的扩容都是+1的形式,这意味着几乎每次add操作都要走一遍数组扩容的流程。尽管如此,但值得注意的是,CopyOnWriteArrayList数组的拷贝均调用的是系统基本的指令,因此性能依旧是杠杠的(前提是你的数据量不能过于庞大)。
3.4 get
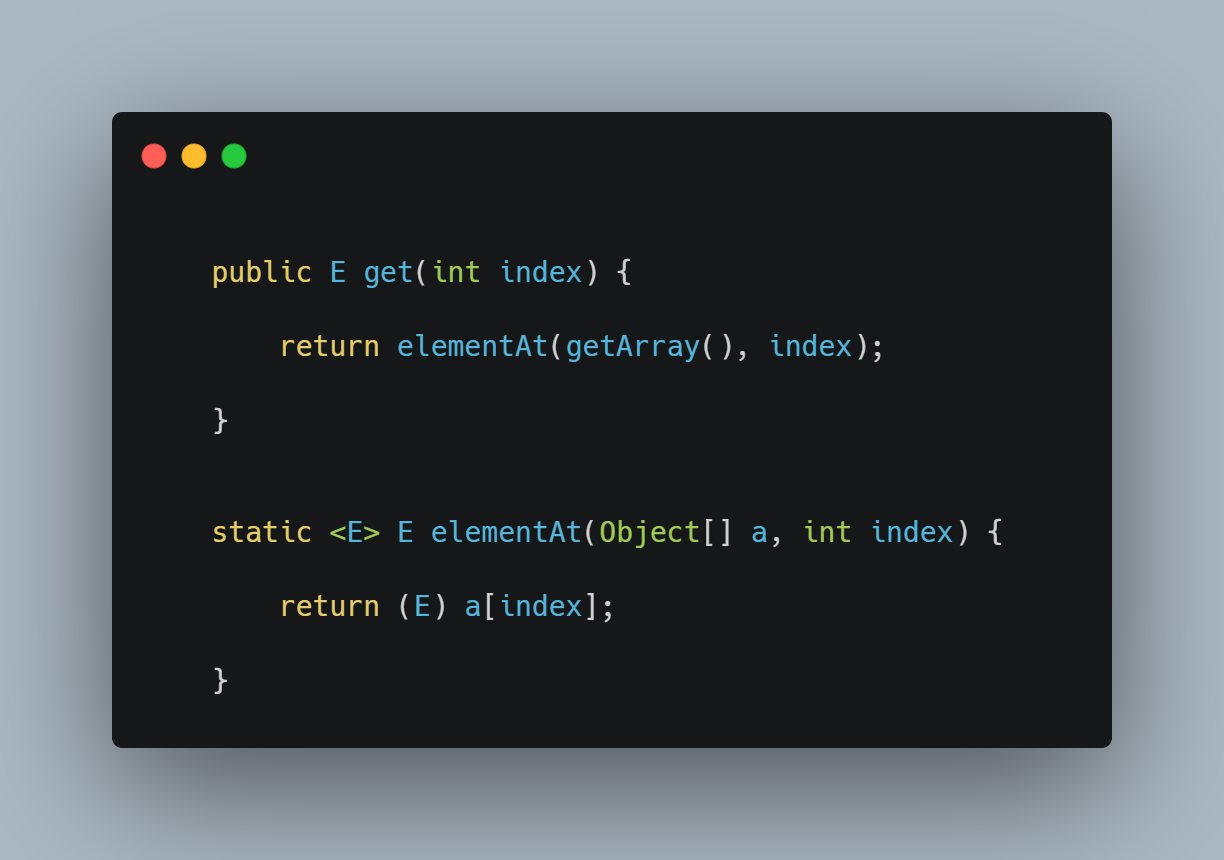 方法源码(JDK17)")
方法源码(JDK17)")
执行流程
先获取到元素数组的引用,然后直接获取指定下标的元素。
评估
- 读的过程可能会出现数据不一致的情况(写操作已在副本上执行完成,但副本尚未赋值给elements的期间)。
- 读过程不加锁。
3.5 remove
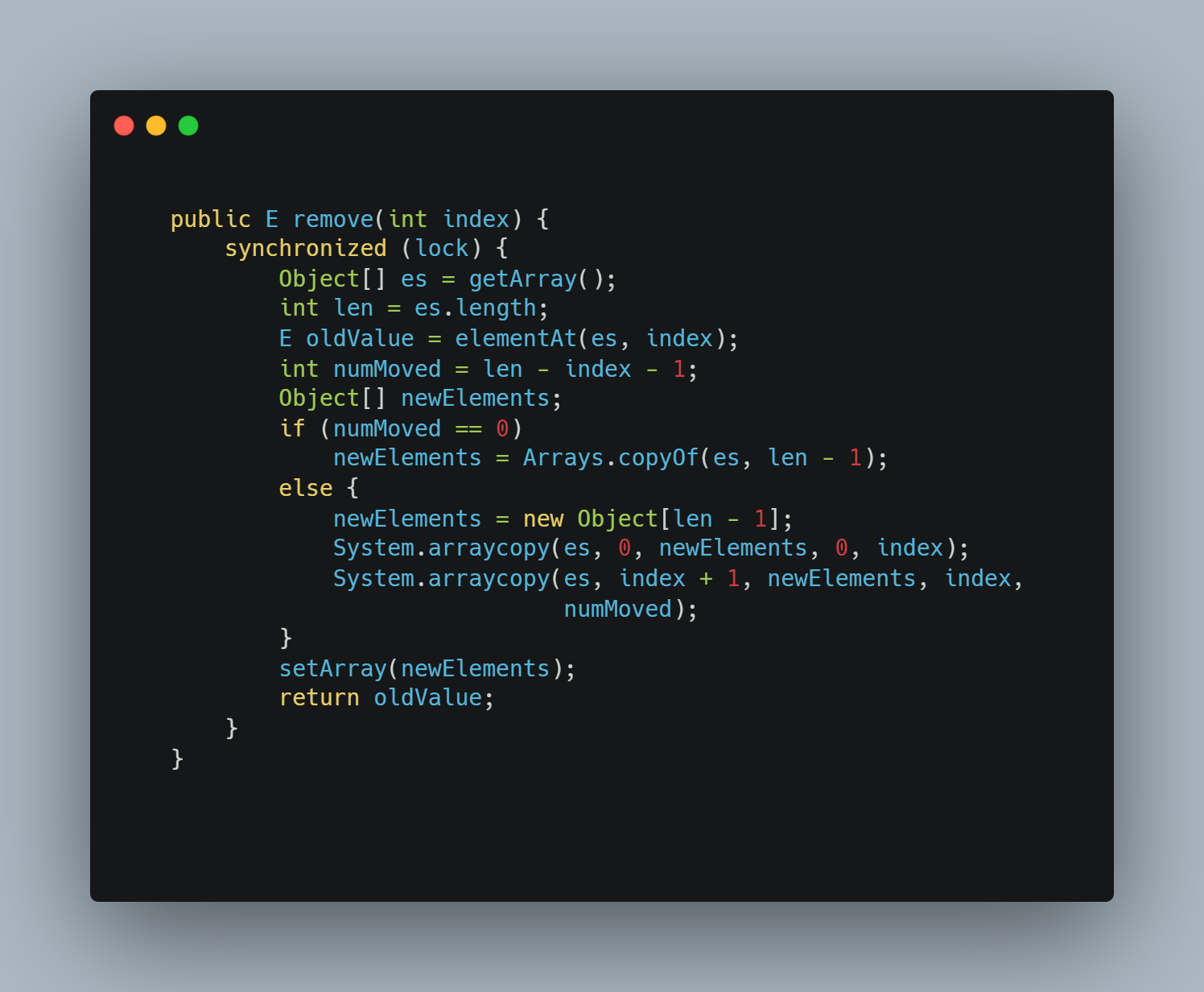 方法源码(JDK17)")
方法源码(JDK17)")
执行流程
与add过程几乎一模一样,无非就是数组拷贝的参数调整了一下。
计算需要移动的元素个数这里,之所以-1是因为len-index得到的是从index位置起到末尾的元素个数,也就是这里面包含了待删除的那个元素,因此需要-1排除掉它。
3.6 size
 方法源码(JDK17)")
方法源码(JDK17)")
评估
因为CopyOnWriteArrayList的使用的全过程中,其内部的Object数组的都是充盈的(从其构造函数以及后面的增删改操作中就可以看出),即不存在空隙,因此数组的长度即为元素的个数。
3.6 contains
 方法源码(JDK17)")
方法源码(JDK17)")
执行流程
根据待检索元素是不是为null分情况进行全数组遍历。
参考文档
CopyOnWriteArrayList 源码分析