前言:
我们知道OSI模型上层分为应用层、会话层和表示层,我们接下来要讲的是主流的应用层协议HTTP,为什么需要这个协议呢,因为在应用层由于操作系统的不同、开发人员使用的语言类型不同,当我们在传输结构化数据时,会导致端到端之间有差异。为了抹去这种差异,我们需要对用户、开发人员使用的应用层进行协议的定制……

在讲HTTP协议之前,我们知道“协议”是一种约定,“协议”是客户端、服务器定制的一种标准,“协议”的本质是一种结构化数据。那么HTTP协议本质上也是一种结构化数据,是客户端、服务器的一种对于多种场景的通用标准!!!
该博客相关代码可以看:Linux_code: 存放Linux中的代码 - Gitee.com
1.初识HTTP协议
1.1.浅谈URL
如图:为最基本的http协议网址(URL)

而当我在写这篇博客时的https协议网址为:

我们在之前的学习中知道访问服务器需要ip地址和端口号才能正确的访问,而在如图的协议中我们并没有看到对应服务器的位置和开放的端口号。
在http协议中服务器网址可以通过DNS协议转化为ip地址,而http方案名默认对应端口号80,https默认对应端口号443.
在解决了进行客户端、服务器访问的定位问题,我们知道当前主流的网络通信是基于socket套接字的,而socket本质上就是客户端进程和服务器进程进行通信。
即---通信的行为本质上就是进程间进行IO:
- 获取资源(从服务器获取图片、视频、音频、文段等资源)
- 上传数据(客户端向服务器上传数据)
结合生活也是很容易被接受的,比如我们刷视频时,这些视频加载到我们手机是通过我们手机的客户端向服务器发送请求,服务器接收请求,发送回应。
具体来说:今天我在抖音上刷到一个小姐姐,主观上你打开的抖音APP,这时就是你的抖音APP客户端向服务器发送获取视频的请求,服务端接收到请求时,会在服务器地址下的文件系统中给你载入视频文件,并作为回应发送给你,这时你就开开心心地刷着小姐姐视频了。
讲到这里我们也可以理解为什么http协议中会出现“带层次的文件路径”,因为资源的获取本质就是客户端发送请求,服务器在自己的文件系统中找到对应资源传输给客户端。
1.2.UrlEncode和UrlDecode
在我们之前协议的学习时,我们会定制一些特殊字符来对协议有效载荷进行分割,在http协议中诸如:?\.,/=+-这类特殊字符都需要被进行URL重新编码。
在该图中我们我们分别进行三次搜索,观察wd=(即输入word=),我们发现特殊字符变成了%拼接16进制,用来防止http协议用来进行分割的字符和有效载荷中的特殊字符冲突。
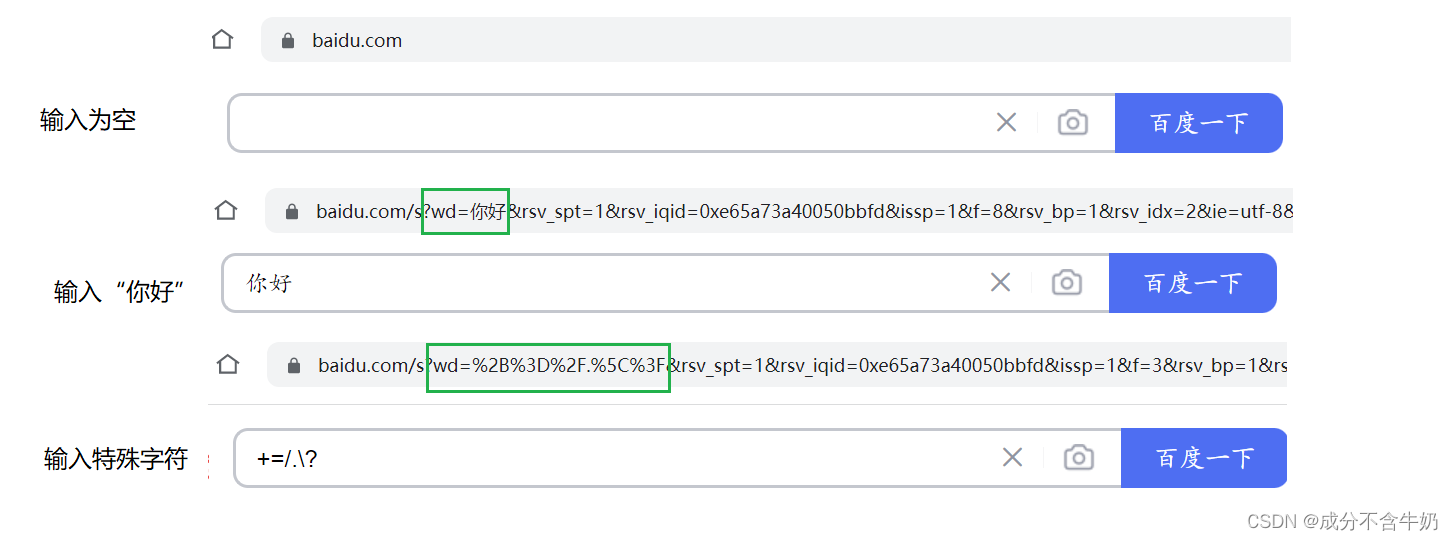
这里只显示了客户端encode后在服务器上显示的内容,也就是将特殊字符转为有效载荷对应的字符串形式的字节流。而decode即是encode的相反过程,即服务器端读取到客户端内容……
2.HTTP协议格式
2.1.HTTP协议组成
回到协议本身,HTTP作为一个协议,本身的构成就为:协议的报头和有效载荷。那么在客户端、服务端在应用层通过HTTP协议进行交互时,一定需要解决这两个问题:
- 如何将字符串形式的字节流打包成报文
- 如何将报文解析除去报头保留有效载荷
因此我们需要学习HTTP协议格式,了解HTTP协议的实现原理:
HTTP请求报文!
HTTP响应报文!
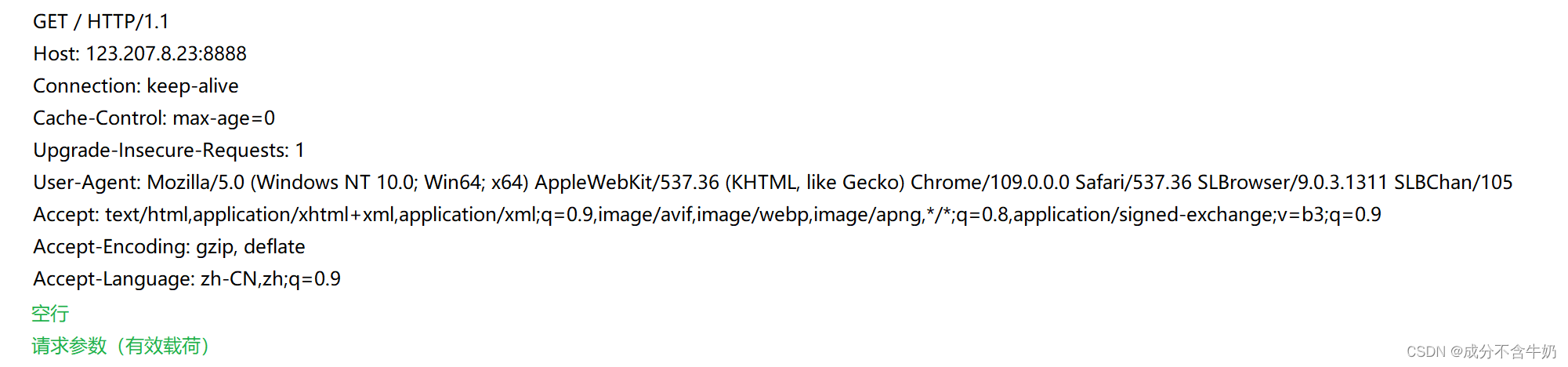

我们将请求返回的报文进行解析,分成4部分,前两部分为请求(响应行)和请求头(响应头)一般key-value形式的参数,第三部分为空行,最后部分为有效载荷。
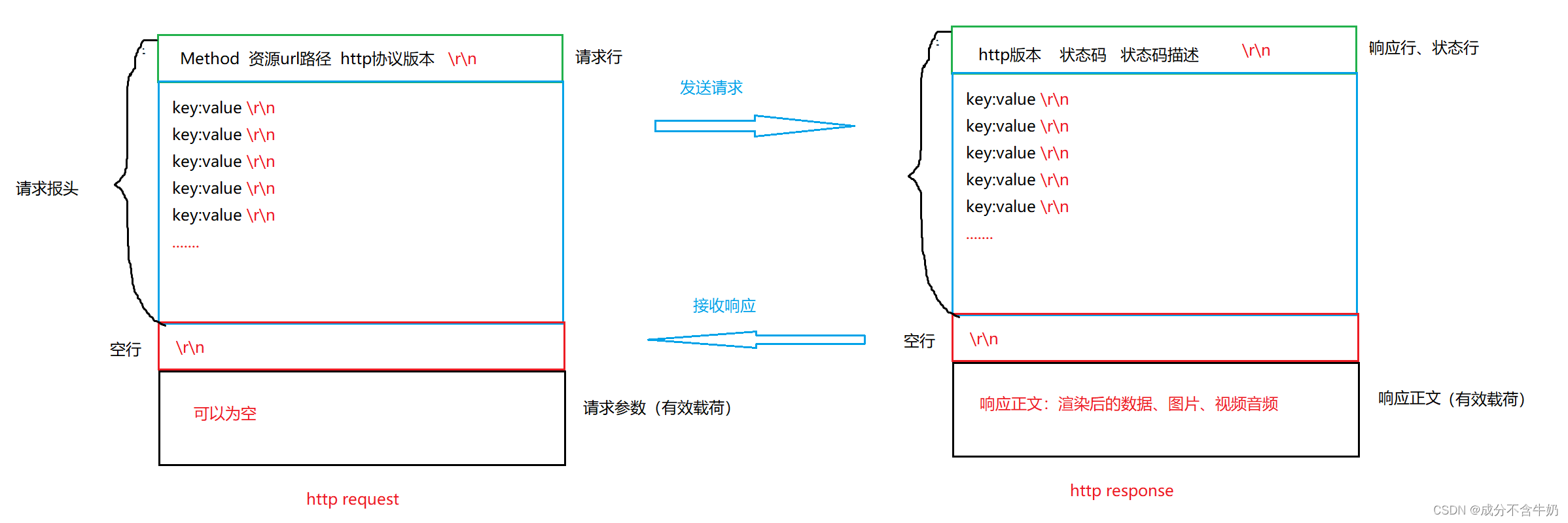 再回到我们协议需要解决的两个问题,我们已经知道来报文的结构,解决流程就很明显了:
再回到我们协议需要解决的两个问题,我们已经知道来报文的结构,解决流程就很明显了:
首先HTTP传输的数据虽然由于\r\n以多行的形式体现在显示器上,但是HTTP协议也是基于TCP的传输,最终也是以一行字节流的形式从端到端,那么当我们对报头中的这些数据做行区分呢时通过\r\n,而对报头和有效载荷则通过空行来进行解析即可。
值得注意的是:http协议的报头=请求行+请求头,另外我们当有效载荷不为空时,请求头中会维护有效载荷的正文类型content-type和正文长度content-length,当解析HTTP协议时访问到该字段就需要解析有效载荷……
2.2.解析HTTP协议
2.2.1.资源URL路径
从上图中我们能看出URL路径默认为 / 即web根目录,那什么是web根目录呢?
web根目录:对应着服务器制定的路径,可以通过这个路径找到存放着所有http资源。
而当url默认为/时,http会自动绑接这个根目录默认指向index.html首页。而这个url最终指向的是服务器对应的文件系统下的某一个资源(文本、视频、音频……),但是我们传送给
2.2.2.请求方法
上网这个行为底层体现在:
- 用户向服务器获取资源,对应请求行中的GET方法
- 用户向服务器传输数据,POST方法,也可以通过GET方法传输参数
GET方法
GET方法可以通过URL传输参数向服务器传输数据进而向服务器获取数据,也可以直接请求向服务器获取数据。
这一句话如何解释呢?接下来我们通过html的表单组件来体会一下:
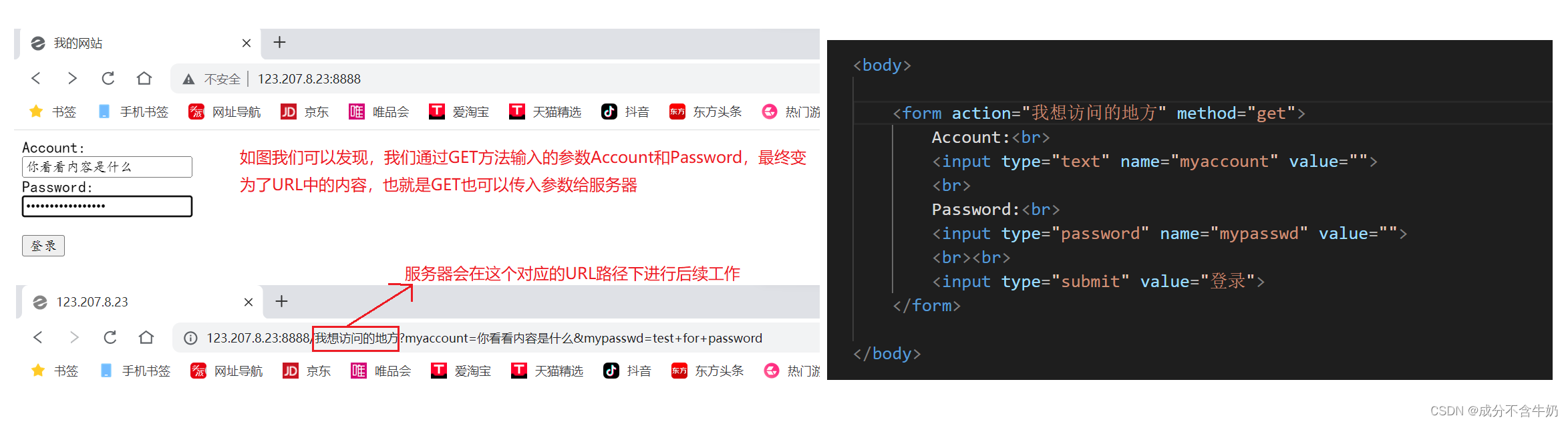
- 如图我们发现GET方法通过往URL中插入参数可以实现向服务器传输参数,当服务器获取到URL时可以进行分析,获取到参数Account和Password,即服务器通过URL进行参数提取。
- 当我们通过GET获取这个资源时,因为实验结果并不是特别容易展示出来,我们这里就不对当次的结果做出具体的展示,值得一提的是获取到的资源(服务器响应的资源)是图中的表单代码。
我们这里的逻辑是:通过表单输入账号和密码,我们在日常使用网络时,输入账号密码时,会跳转到对应页面,本质上就是后端读取到GET方法传入的参数Account和Password,然后fork创建子进程,再通过进程间替换,将参数传给新进程,进入与该账号对应的页面处。服务器返回的内容是对应页面的渲染信息。
当我们输入参数,本质上就是输入参数给浏览器,接着浏览器通过当前页面的html代码进行分析,然后把相应模块进行拼接形成字节流后传输到服务器中。
POST方法
POST方法往请求正文部分写入参数,传给服务器
一般来说一个GET请求没有请求正文,而POST请求则需要在正文参数中传入你想要提供给服务器的参数。读取POST对应的参数,需要解析HTTP协议中的请求头的content-length
GET和POST比较
- GET方法通过URL传递参数,POST通过请求正文传递参数
- GET方法传参会受URL字节数限制,而POST参数没有限制
- GET的私密性较差,POST私密性较好(这两个方法均不安全,未加密!!!)
其他的请求行方法

2.2.3. 状态码

状态码一般是后端开发人员自己设置的,对应着开发遇到的一些情况。
这里特殊讲解一下307临时重定向,使用这个状态码时,需要定义location,并且以K-V形式插入进请求头中,即string s = "Location: www.baidu.com"; 接着插入我们的请求头中。
307临时重定向用来实现页面的跳转,引导用户跳转到目标网页

HTTP状态码对照表,HTML常用字符查询表,html特殊字符对照表_TendCode
2.2.4.cookie和session
我们知道http是一个无连接、无状态的链接协议,即在若干次客户端和服务端进行交互时,每一次交互都是独立的,也就是不知道其他时候进行的交换内容是什么?
当我们购买了哔哩哔哩的大会员,我们想要看大会员的内容,就需要登录上我们大会员的账号才能访问到这一块资源。因为http是无连接、无状态的链接协议,这就会导致我们上一次输入账号密码看的资源看完后,我们看下一个资源时,需要再次进行登录账号密码。
显然这样子是不合理的,这时http协议就在请求头和响应头中添加了cookie模块,保存我们交互的一些特定信息。
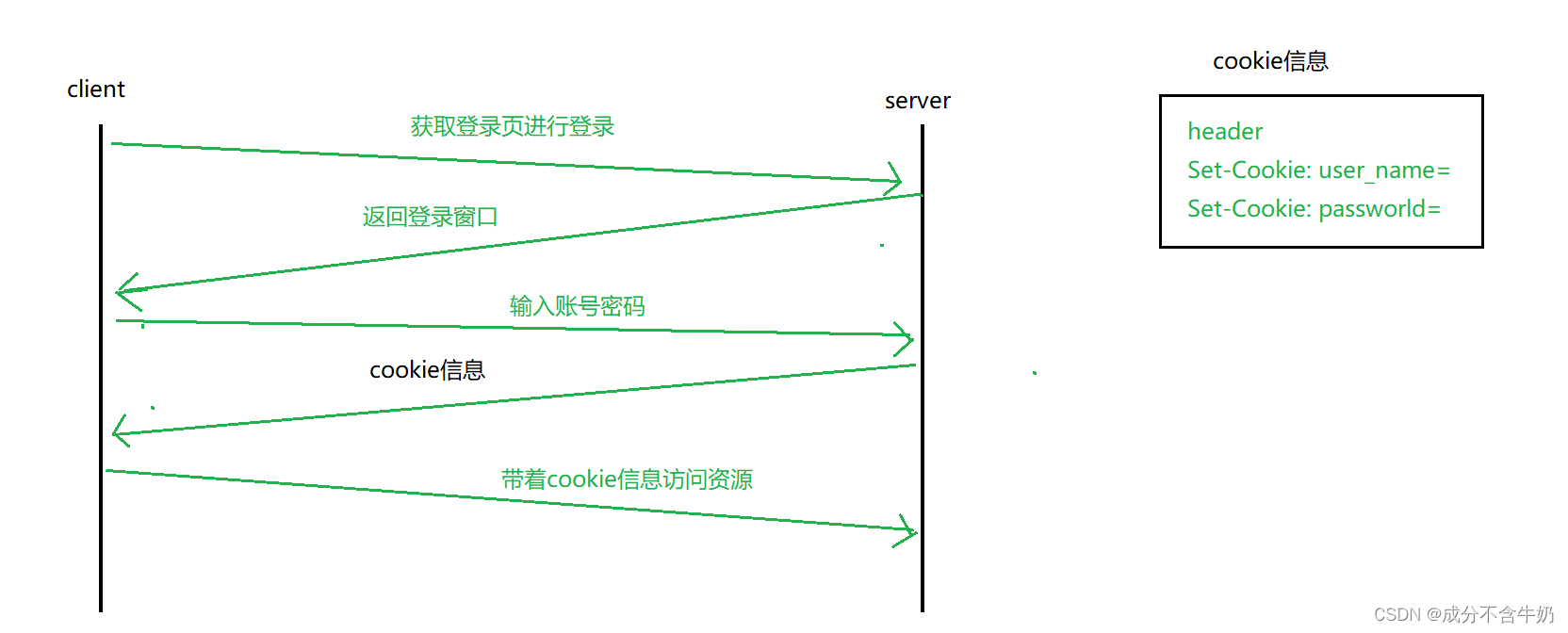
而cookie分为文件级别和内存级别,也可以设置失效时间。
在上面这种情况中cookie信息中存放着个人的私密信息,如果单纯地按照上图的这种cookie交互,当电脑中木马后,木马程序会读取到这些cookie信息,这样就导致个人数据泄漏……那么我们如何解决这个问题呢?于是我们添加一个session结构体来存放Cookie的信息

然而这样的结构也无法防止cookie信息被盗取,但是保证了cookie信息内的数据不被非法获取,但是仍然能够捕获我们的cookie在异地进行操作,这时就需要浏览器对异常的cookie信息进行各种策略,让被异常使用的cookie失效。
那么这时服务器可以通过唯一的session_id对应的session进行操作来关闭掉异常cookie的使用。另外在这里我们也能看出来,服务端对用户登录进行管理的本质就是对session这个结构体进行增删查改
2.2.5.常见Header
| Content-Type: | 数据类型(text/html等) |
| Content-Length: | Body的长度 |
| Host: | 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上; |
| User-Agent: | 声明用户的操作系统和浏览器版本信息; |
| referer: | 当前页面是从哪个页面跳转过来的; |
| location: | 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问; |
| Cookie: | 用于在客户端存储少量信息. 通常用于实现会话(session)的功能; |
讲到这里我们HTTP协议的学习就基本结束了,但是如今主流的浏览器用的是HTTPS协议,这个协议添加了加密的模块,保证了数据的安全,关于HTTPS协议的学习我们在下一篇博客见!