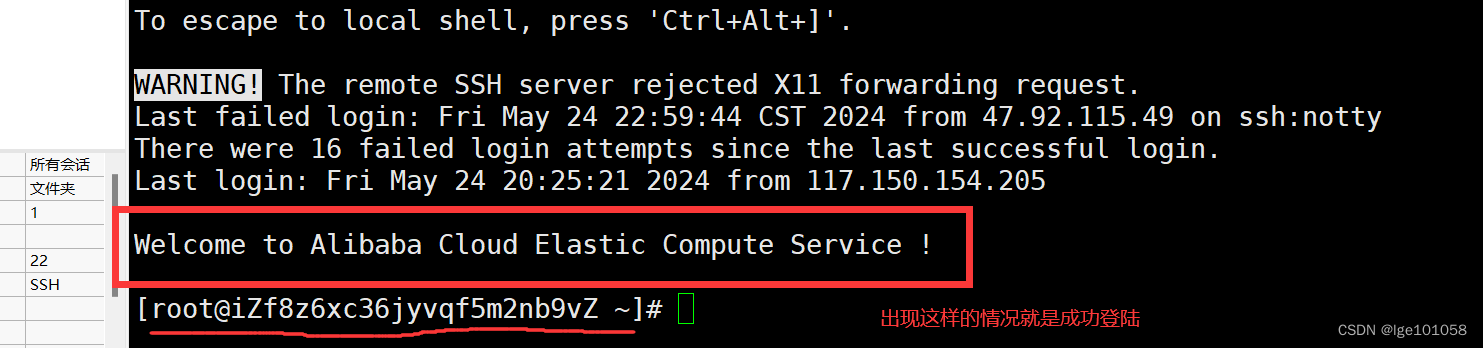
框架、模型、数据集准备
1.llama-factory部署
# 克隆仓库
git clone https://github.com/hiyouga/LLaMA-Factory.git
# 创建虚拟环境
conda create --name llama_factory python=3.10
# 激活虚拟环境
conda activate llama_factory
# 安装依赖
cd LLaMA-Factory
pip install -r requirements.txt
2.接下来是下载 LLM,可以选择自己常用的 LLM,包括 ChatGLM,BaiChuan,QWen,LLaMA 等,这里我们下载 Baichuan2-13B-Chat模型进行演示:
git lfs install
git clone https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat在LLaMA-Factory项目中,单显卡可以用命令或web页面训练,多显卡只能用用命令的方式
web页面方式
启动 LLaMA Factory 的 WebUI 页面
CUDA_VISIBLE_DEVICES=0 python src/webui.py如果报错:Traceback (most recent call last):
File "/home/bingxing2/ailab/group/ai4agr/wzf/LLM/frame/LLaMA-Factory/src/webui.py", line 13, in <module>
main()
File "/home/bingxing2/ailab/group/ai4agr/wzf/LLM/frame/LLaMA-Factory/src/webui.py", line 9, in main
create_ui().queue().launch(share=gradio_share, server_name=server_name, inbrowser=True)
File "/home/bingxing2/ailab/scxlab0069/.conda/envs/llama_factory/lib/python3.10/site-packages/gradio/blocks.py", line 2375, in launch
raise ValueError(
ValueError: When localhost is not accessible, a shareable link must be created. Please set share=True or check your proxy settings to allow access to localhost.解决办法:
unset http_proxy
unset https_proxy
启动后的界面如下所示:
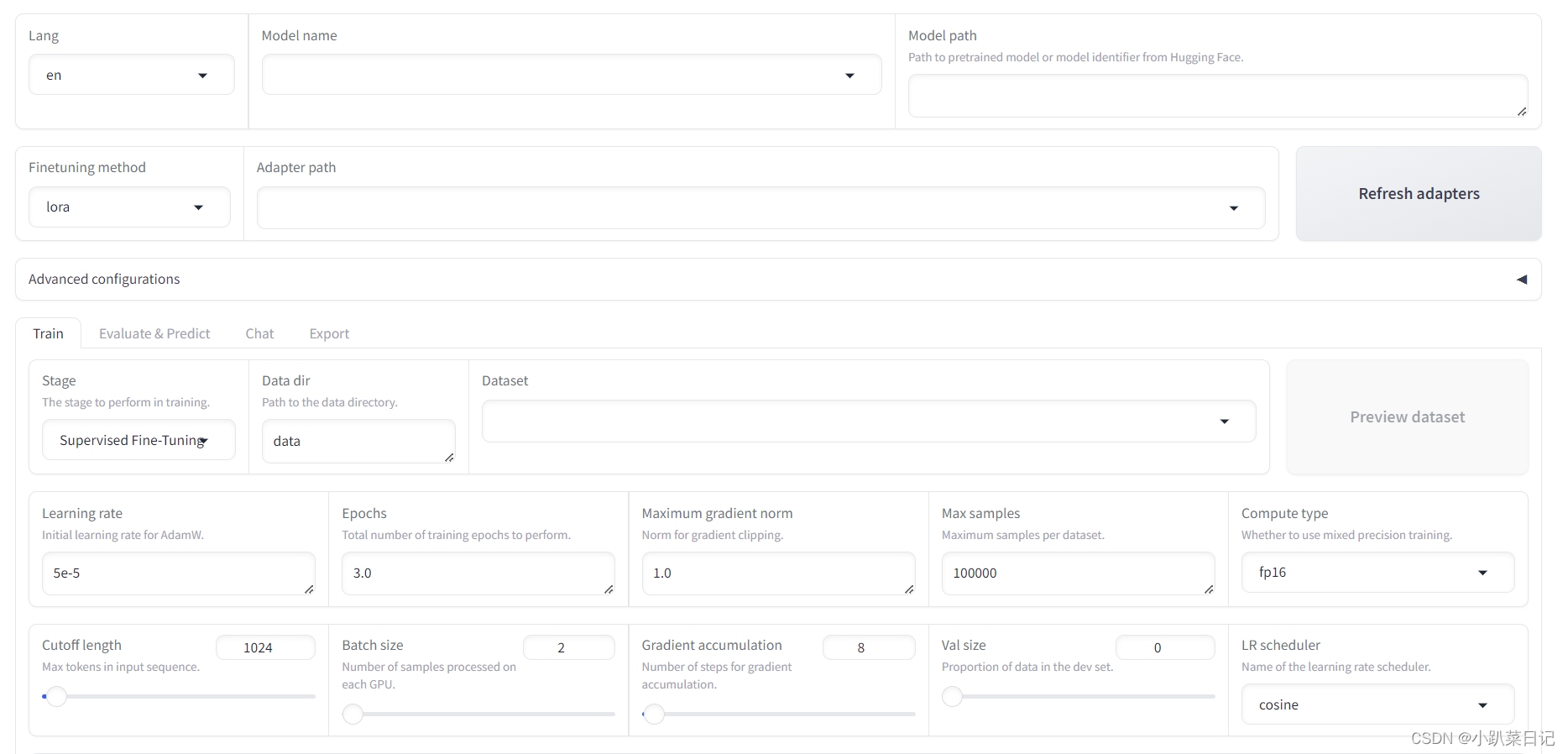
界面分上下两部分,上半部分是模型训练的基本配置,有如下参数:
- 模型名称:可以使用常用的模型,包括 ChatGLM,BaiChuan,QWen,LLaMA 等,我们根据下载的模型选择Baichuan2-13B-Chat。
- 模型路径:输入框填写我们之前下载的 Baichuan 模型的地址。
微调方法有三种:
- full:将整个模型都进行微调。
- freeze:将模型的大部分参数冻结,只对部分参数进行微调。
- lora:将模型的部分参数冻结,只对部分参数进行微调,但只在特定的层上进行微调。
模型断点(适配器):在未开始微调前为空,微调一次后可以点击刷新断点(适配器)按钮,会得到之前微调过的断点(适配器)。
高级设置可以不用管,使用默认值即可。
下半部分是一个页签窗口,分为Train、Evaluate、Chat、Export四个页签,微调先看Train界面,有如下参数:
训练阶段:选择训练阶段,分为预训练(Pre-Training)、指令监督微调(Supervised Fine-Tuning)、奖励模型训练(Reward Modeling)、PPO 、DPO 五种,这里我们选择指令监督微调(Supervised Fine-Tuning)。
- Pre-Training:在该阶段,模型会在一个大型数据集上进行预训练,学习基本的语义和概念。
- Supervised Fine-Tuning:在该阶段,模型会在一个带标签的数据集上进行微调,以提高对特定任务的准确性。
- Reward Modeling:在该阶段,模型会学习如何从环境中获得奖励,以便在未来做出更好的决策。
- PPO Training:在该阶段,模型会使用策略梯度方法进行训练,以提高在环境中的表现。
- DPO Training:在该阶段,模型会使用深度强化学习方法进行训练,以提高在环境中的表现。
数据路径:指训练集数据文件所在的路径,这里的路径默认指的是 LLaMA Factory 目录下的文件夹路径,默认是data目录。
数据集:这里可以选择数据路径中的数据集文件,这里我们选择identity数据集,这个数据集是用来调教 LLM 回答诸如你是谁、你由谁制造这类问题的,里面的数据比较少只有 90 条左右。在微调前我们需要先修改这个文件中的内容,将里面的<NAME>和<AUTHOR>替换成我们的 AI 机器人名称和公司名称。选择了数据集后,可以点击右边的预览数据集按钮来查看数据集的前面几行的内容。
如果采用自行准备的数据集,要在 LLaMA Factory目录下data目录下的dataset_info.json添加新新数据集信息。
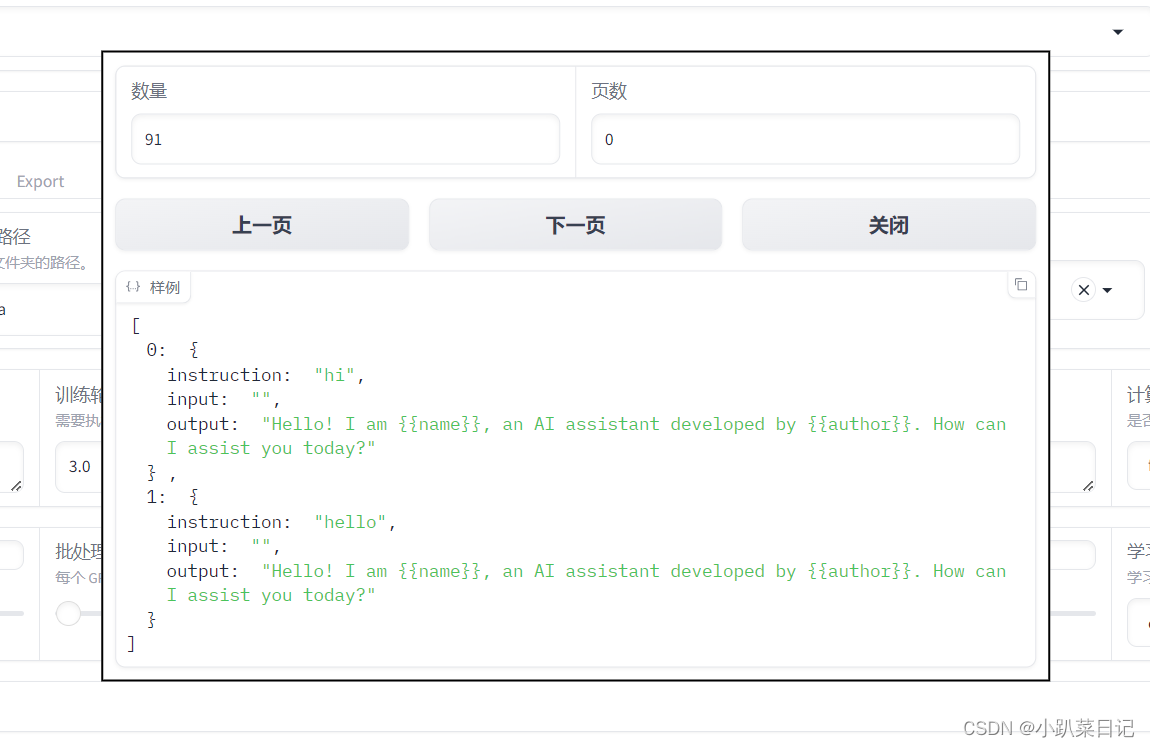
替换后

学习率:学习率越大,模型的学习速度越快,但是学习率太大的话,可能会导致模型在寻找最优解时跳过最优解,学习率太小的话,模型学习速度会很慢,所以这个参数需要根据实际情况进行调整,这里我们使用默认值5e-5。
训练轮数:训练轮数越多,模型的学习效果越好,但是训练轮数太多的话,模型的训练时间会很长,因为我们的训练数据比较少,所以要适当增加训练轮数,这里将值设置为30。默认3.0
最大样本数:每个数据集最多使用的样本数,因为我们的数据量很少只有 90条,所以用默认值就可以了。默认10000
计算类型:这里的fp16 和 bf16 是指数字的数据表示格式,主要用于深度学习训练和推理过程中,以节省内存和加速计算,这里我们选择bf16。默认fp16
学习率调节器:有以下选项可以选择,这里我们选择默认值cosine。
- linear(线性): 随着训练的进行,学习率将以线性方式减少。
- cosine(余弦): 这是根据余弦函数来减少学习率的。在训练开始时,学习率较高,然后逐渐降低并在训练结束时达到最低值。
- cosine_with_restarts(带重启的余弦): 和余弦策略类似,但是在一段时间后会重新启动学习率,并多次这样做。
- polynomial(多项式): 学习率会根据一个多项式函数来减少,可以设定多项式的次数。
- constant(常数): 学习率始终保持不变。
- constant_with_warmup(带预热的常数): 开始时,学习率会慢慢上升到一个固定值,然后保持这个值。
- inverse_sqrt(反平方根): 学习率会随着训练的进行按照反平方根的方式减少。
- reduce_lr_on_plateau(在平台上减少学习率): 当模型的进展停滞时(例如,验证误差不再下降),学习率会自动减少。
梯度累积和最大梯度范数:这两个参数通常可以一起使用,以保证在微调大型语言模型时,能够有效地处理大规模数据,同时保证模型训练的稳定性。梯度累积允许在有限的硬件资源上处理更大的数据集,而最大梯度范数则可以防止梯度爆炸,保证模型训练的稳定性,这里我们使用默认值即可。梯度累积默认8,最大梯度范数1.0
断点名称:默认是用时间戳作为断点名称,可以自己修改。
其他参数使用默认值即可。
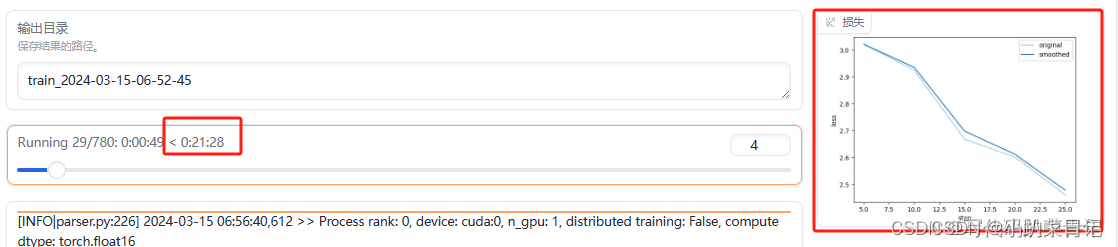
参数设置完后点击预览命令按钮可以查看本次微调的命令,确认无误后点击开始按钮就开始微调了,因为数据量比较少,大概几分钟微调就完成了。在界面的右下方还可以看到微调过程中损失函数曲线,损失函数的值越低,模型的预测效果通常越好
后端界面

前端界面
4.模型试用
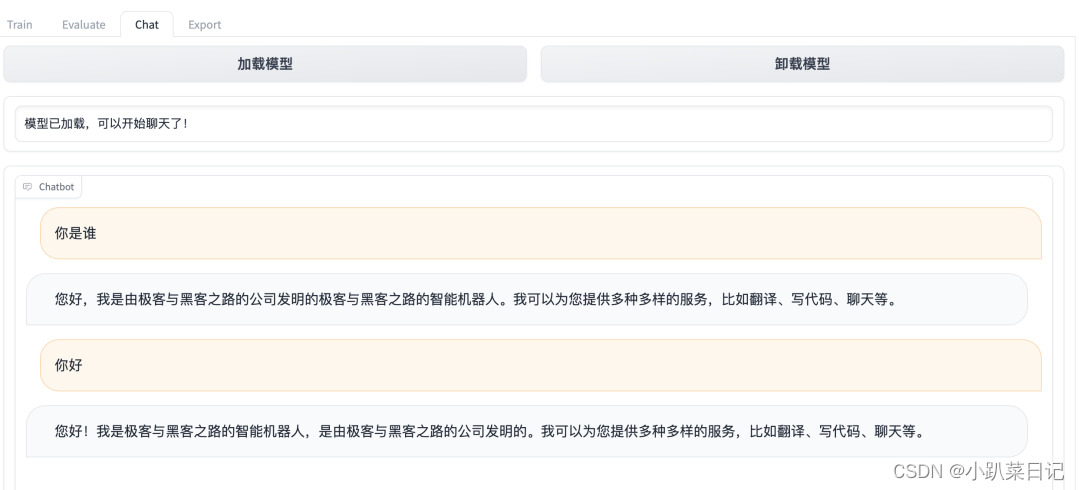
微调完成后,进入Chat页签对微调模型进行试用。首先点击页面上的刷新适配器按钮,然后选择我们最近微调的断点名称,再点击加载模型按钮,等待加载完成后就可以进行对话了,输入微调数据集中的问题,然后来看看微调后的 LLM 的回答吧。
如果觉得微调的模型没有问题,就可以将模型导出并正式使用了,点击Export页签,在导出目录中输入导出的文件夹地址。一般模型文件会比较大,右边的最大分块大小参数用来将模型文件按照大小进行切分,默认是10GB,比如模型文件有 15G,那么切分后就变成 2 个文件,1 个 10G,1 个 5G。设置完成后点击开始导出按钮即可,等导出完成后,就可以在对应目录下看到导出的模型文件了

指令方式
命令运行的脚本地址:LLaMA-Factory/examples/README_zh.md
训练指令
1.预训练指令
CUDA_VISIBLE_DEVICES=0 python src/train.py \--stage pt \ # Pre——Training预训练模式--model_name_or_path path_to_llama_model \ # 模型地址--do_train \ # 表示进行训练--dataset wiki_demo \ # 使用的数据集--finetuning_type lora \ # 微调的方法--lora_target W_pack \ # LoRA作用模块:Baichuan为W_pack--output_dir path_to_pt_checkpoint \ # 断点保存:保存模型断点的位置--overwrite_cache \ # 表示是否覆盖缓存文件--per_device_train_batch_size 4 \ # 批处理大小:每块 GPU 上处理的样本数量--gradient_accumulation_steps 4 \ # 梯度累积:梯度累积的步数(节省显存的方法)--lr_scheduler_type cosine \ # 学习率调节器:采用的学习率调节器名称--logging_steps 10 \ # 日志间隔:每两次日志输出间的更新步数--save_steps 1000 \ # 保存间隔:每两次断点保存间的更新步数--learning_rate 5e-5 \ # 学习率:AdamW优化器的初始学习率--num_train_epochs 3.0 \ # 训练轮数:需要执行的训练总轮数--plot_loss \ # 绘制损失函数图--fp16 # 计算类型:是否启用fp16或bf16混合精度训练如果报错:
File "/home/bingxing2/ailab/scxlab0069/.conda/envs/llama_factory/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_implreturn self._call_impl(*args, **kwargs)File "/home/bingxing2/ailab/scxlab0069/.conda/envs/llama_factory/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1541, in _call_implreturn forward_call(*args, **kwargs)File "/home/bingxing2/ailab/scxlab0069/.conda/envs/llama_factory/lib/python3.10/site-packages/torch/nn/modules/loss.py", line 1185, in forwardreturn F.cross_entropy(input, target, weight=self.weight,File "/home/bingxing2/ailab/scxlab0069/.conda/envs/llama_factory/lib/python3.10/site-packages/torch/nn/functional.py", line 3086, in cross_entropyreturn torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
RuntimeError: "nll_loss_out_frame" not implemented for 'Half'解决办法:把fp16改成bf16
2.指令监督微调(已跑通)
CUDA_VISIBLE_DEVICES=0 python src/train.py \--stage sft \--model_name_or_path path_to_llama_model \--do_train \--dataset alpaca_gpt4_zh \ --template default \ # 提示模板:构建提示词时使用的模板 --finetuning_type lora \--lora_target W_pack \--output_dir path_to_sft_checkpoint \--overwrite_cache \--per_device_train_batch_size 4 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 5e-5 \--num_train_epochs 3.0 \--plot_loss \--fp163训练奖励模型+PPO
CUDA_VISIBLE_DEVICES=0 python src/train.py \--stage rm \--model_name_or_path path_to_llama_model \--do_train \--dataset comparison_gpt4_zh \ # 奖励模型训练数据集--template default \--finetuning_type lora \--lora_target W_pack \--resume_lora_training False \ # 接着上次的LoRA权重训练或创建一个新的LoRA权重--checkpoint_dir path_to_sft_checkpoint \ # 指令微调模型的断点--output_dir path_to_rm_checkpoint \ # 奖励模型的输出位置--per_device_train_batch_size 2 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 1e-6 \--num_train_epochs 1.0 \--plot_loss \--fp16PPO训练(PPO训练需要先进行上一步RM的训练,然后导入微调后模型和RM进行训练输出)
CUDA_VISIBLE_DEVICES=0 python src/train.py \--stage ppo \--model_name_or_path path_to_llama_model \--do_train \--dataset alpaca_gpt4_zh \--template default \--finetuning_type lora \--lora_target W_pack \--resume_lora_training False \--checkpoint_dir path_to_sft_checkpoint \ # 加载指令微调的断点模型--reward_model path_to_rm_checkpoint \ # 奖励模型的断点路径--output_dir path_to_ppo_checkpoint \ # ppo训练的断点输出位置--per_device_train_batch_size 2 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 1e-5 \--num_train_epochs 1.0 \--plot_loss4.DPO训练
(不需要先训练RM,直接导入微调模型进行DPO训练)
CUDA_VISIBLE_DEVICES=0 python src/train.py \--stage dpo \--model_name_or_path path_to_llama_model \--do_train \--dataset comparison_gpt4_zh \--template default \--finetuning_type lora \--lora_target W_pack \--resume_lora_training False \--checkpoint_dir path_to_sft_checkpoint \--output_dir path_to_dpo_checkpoint \--per_device_train_batch_size 2 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 1e-5 \--num_train_epochs 1.0 \--plot_loss \--fp16
- 大规模无监督语言模型(LMs)虽然可以学习广泛的世界知识和一些推理技能,但由于其训练的完全无监督性,因此实现对其行为的精确控制是困难的。现有的获得这种可控性的方法是收集人工对模型生成相对质量的标签,并且通过人类反馈强化学习(RLHF)对无监督的 LM 进行微调,以使其与人类偏好相一致。然而,RLHF 是一个复杂且经常不太稳定的过程,它首先拟合一个反应人类偏好的奖励模型,然后通过强化学习对大型无监督 LM 进行微调以最大化评估奖励,并避免与原始模型相差太远。
- 在本文中,我们使用奖励函数和最优策略间的映射,展示了约束奖励最大化问题完全可以通过单阶段策略训练进行优化 ,从本质上解决了人类偏好数据上的分类问题。我们提出的这个算法称为直接偏好优化(Direct Preference Optimization,DPO)。它具有稳定性、高性能和计算轻量级的特点,不需要拟合奖励模型,不需要在微调时从 LM 中采样,也不需要大量的超参调节。我们的实验表明了 DPO 可以微调 LMs 以对齐人类偏好,甚至比现有方法更好。值得注意的是,用 DPO 进行微调在控制生成结果的情感以及改善摘要和单轮对话的响应质量方面表现出更好的能力,同时在实现和训练时的难度大大降低。
模型评估
CUDA_VISIBLE_DEVICES=0 python src/evaluate.py \--model_name_or_path path_to_llama_model \ # base模型--finetuning_type lora \ --checkpoint_dir path_to_checkpoint \ # 训练好的检查点--template vanilla \ # 模板类型--task ceval \ # 任务类型--split validation \ # 指定数据集的划分--lang zh \--n_shot 5 \ # few-shot 学习的示例数--batch_size 4 # 评估时的批量大小模型预测
CUDA_VISIBLE_DEVICES=0 python src/train.py \--model_name_or_path path_to_llama_model \ # base模型--do_predict \ # 执行预测任务--dataset alpaca_gpt4_zh \--template default \--finetuning_type lora \--checkpoint_dir path_to_checkpoint \ # 训练好的检查点--output_dir path_to_predict_result \--per_device_eval_batch_size 8 \--max_samples 100 \ # 最大样本数:每个数据集最多使用的样本数--predict_with_generate # 使用生成模式进行预测微调训练后生成的文件夹path_to_sft_checkpoint中包括:
- checkpoint-xxx 间隔固定step生成的模型断点
- runs 文件夹用于tensorboard可视化训练过程
- lora adapter模型、配置
- 分词器脚本、配置、模型
- 训练日志
- loss曲线

参考:用通俗易懂的方式讲解大模型:一个强大的 LLM 微调工具 LLaMA Factory_llama-factory-CSDN博客
从零开始的LLaMA-Factory的指令增量微调_llamafactory微调-CSDN博客
LLaMA-Factory参数的解答(命令,单卡,预训练)_llama-factory单机多卡-CSDN博客
Llama-Factory的baichuan2微调-CSDN博客



![[datawhale202405]从零手搓大模型实战:TinyAgent](https://img-blog.csdnimg.cn/direct/efa861cd0ff240b2bc3a421e97300d86.png)