一点点 cv 经验 1:cv方向、模型评估、输入尺寸、目标检测器设计
- cv 方向
- Pytorch
- 数据集划分
- 模型评估
- 误差=偏差+方差+噪声
- 输入尺寸
- 方法一:让数据适应模型
- 方法二:修改模型适应数据
- 方法三:划分Patch,分别处理
- 目标检测器结构设计思路
- 从哪几个方面分析目标检测器
- YOLO 系列
- Anchor-Based
cv 方向
cv 各个方向:https://github.com/amusi/Computer-Vision-Tasks-Survey
CV的研究大致分为以下几个方向:
二维:
- 图像:图像分类、图像分割、目标检测、人脸识别、文字识别、姿态估计、异常检测、图像检索、图像增强、风格迁移、图像生成等等
- 视频:视频分类、目标跟踪、重识别、行为识别、视频目标分割、视频内容分析
三维:
- 三维目标检测、位姿估计
- 点云生成
- 深度估计
- 三维重建:物、场景、人
- 视觉重定位
- 视觉SLAM
Pytorch
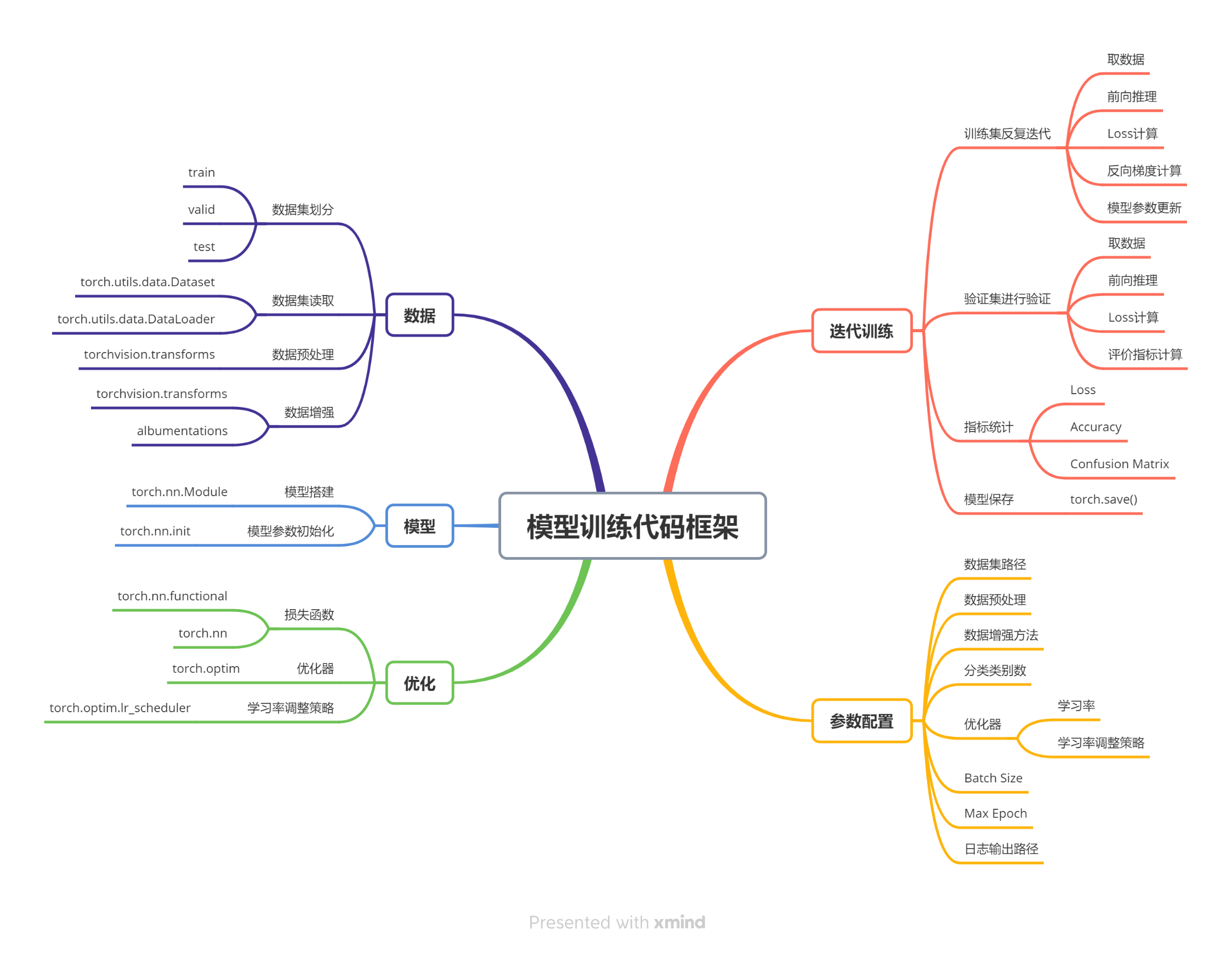
数据集划分
import os # 导入 os 模块,用于处理文件和目录路径
import random # 导入 random 模块,用于随机化数据
import shutil # 导入 shutil 模块,用于文件操作,例如复制文件# 定义函数:将图像列表复制到指定子目录下
def copy_file(img_list, target_dir, setname="train"): # 没有提供setname参数选择,那么函数将使用默认值“train”img_dir = os.path.join(target_dir, setname) # 目标子目录路径os.makedirs(img_dir, exist_ok=True) # 创建目标子目录for p in img_list: # 遍历图像列表shutil.copy(p, img_dir) # 复制图像到目标子目录print(f"{setname} dataset: copy {len(img_list)} images to {img_dir}") # 打印复制信息# 主程序入口
if __name__ == "__main__":# 指定花朵图像所在的目录img_dir = r"E:\data\flowers_data\jpg"# 获取指定目录下所有图像文件的路径列表img_list = [os.path.join(img_dir, name) for name in os.listdir(img_dir)]random.seed(10086) # 设置随机种子,以确保每次运行时随机结果的一致性random.shuffle(img_list) # 随机打乱图像路径列表# 定义训练集和验证集所占比例train_ratio = 0.8valid_ratio = 0.2# 计算总图像数量和训练集图像数量num_img = len(img_list)num_train = int(num_img * train_ratio)num_valid = num_img - num_train# 获取训练集和验证集图像路径列表train_list = img_list[: num_train]valid_list = img_list[num_train: ]# 获取花朵图像目录的父目录作为目标目录target_dir = os.path.abspath(os.path.dirname(img_dir))# 将训练集图像复制到新的 train 子目录下copy_file(train_list, target_dir, "train")# 将验证集图像复制到新的 valid 子目录下copy_file(valid_list, target_dir, "valid")
列表生成器作用:
这两行代码的作用是获取指定目录下所有图像文件的路径列表。
假设你有一个目录结构如下:
E:
└── data└── flowers_data└── jpg├── flower1.jpg├── flower2.jpg├── flower3.jpg└── ...
其中,E:\data\flowers_data\jpg 是存放花朵图像的目录,里面有很多花朵的图片文件,比如flower1.jpg、flower2.jpg等。
那么这两行代码做的事情就是:
img_dir = r"E:\data\flowers_data\jpg":将花朵图像所在的目录路径存储在变量img_dir中。img_list = [os.path.join(img_dir, name) for name in os.listdir(img_dir)]:os.listdir(img_dir):获取目录img_dir下的所有文件名列表,比如['flower1.jpg', 'flower2.jpg', 'flower3.jpg', ...]。os.path.join(img_dir, name):将目录路径img_dir与每个文件名name拼接起来,形成完整的文件路径,比如'E:\data\flowers_data\jpg\flower1.jpg'。- 最终,
img_list中存储的就是所有花朵图像的完整文件路径列表,例如['E:\data\flowers_data\jpg\flower1.jpg', 'E:\data\flowers_data\jpg\flower2.jpg', ...]。
这样,img_list就包含了目标目录下所有花朵图像的文件路径。
怎么调用:
这个代码的作用是将一个目录中的图像分成训练集和验证集,并将它们复制到新的目录中的子目录中。
你可以按照以下步骤来使用这个代码:
-
准备数据:
- 确保你有一组花朵图像,这些图像应该存储在一个目录中(在这个例子中是
E:\data\flowers_data\jpg)。
- 确保你有一组花朵图像,这些图像应该存储在一个目录中(在这个例子中是
-
保存代码:
- 将代码保存为一个Python文件,比如
split_data.py。
- 将代码保存为一个Python文件,比如
-
运行代码:
- 在命令行或终端中,进入到存放代码的目录。
- 执行代码:
python split_data.py。
-
查看结果:
- 运行完代码后,会在原始图像目录的父目录中生成两个子目录:
train和valid。 train目录中包含80%的训练集图像,valid目录中包含20%的验证集图像。
- 运行完代码后,会在原始图像目录的父目录中生成两个子目录:
确保在运行代码之前,你已经安装了Python,并且已经安装了用到的shutil、os和random模块。
模型评估
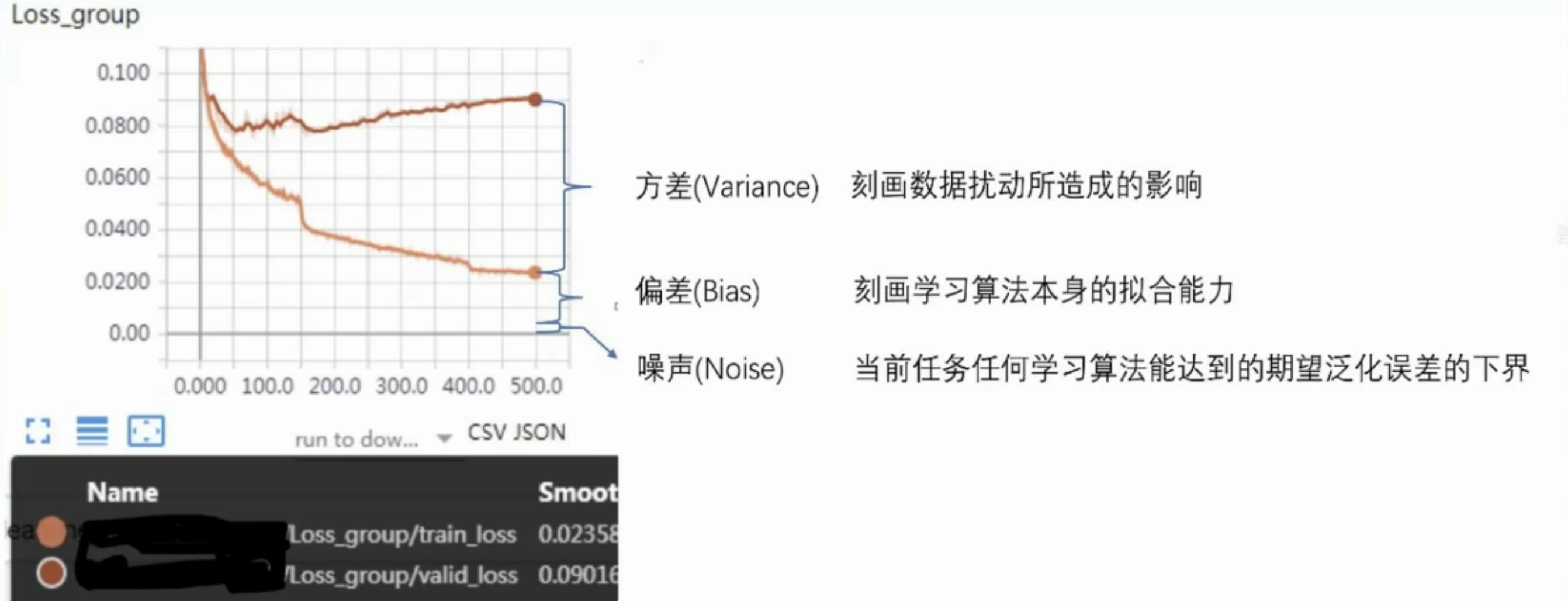
误差=偏差+方差+噪声
假设我们正在使用YOLO算法来检测图像中的交通标志。我们有一个包含交通标志及其位置标注的数据集。我们将误差分解为偏差、方差和噪声,来解释模型的表现。
-
偏差(Bias):
假设我们选择了一个简单的YOLO模型,它只有少量的卷积层和池化层,无法很好地捕捉交通标志的复杂形状和背景。由于模型过于简单,它可能会错过一些交通标志,导致在训练集和测试集上都无法很好地检测到交通标志。这种情况下,偏差会很高,表明模型的拟合能力不足。 -
方差(Variance):
假设我们选择了一个非常复杂的YOLO模型,它有很多卷积层和池化层,以及大量的参数。这个模型在训练集上表现非常好,可以准确地检测到交通标志。然而,由于模型过于复杂,它对训练集中的数据点非常敏感。如果我们稍微改变训练集中的一些图像,可能会导致模型产生很大的变化。因此,模型在训练集和测试集上的性能差异很大,方差会很高。 -
噪声(Noise):
假设我们的数据集中存在一些图像质量较差、光照不足或者遮挡的情况,这些因素会影响模型的检测性能。即使我们使用最好的模型,也无法完全消除这些影响。噪声表示模型在当前任务上任何学习算法所能达到的期望泛化误差的下界。
偏差表示模型的拟合能力,方差表示模型对数据的敏感性,噪声表示数据的不确定性。
通过误差分解,我们可以更好地理解模型在训练和测试过程中的表现,从而选择合适的模型和优化策略。
输入尺寸
在处理机器学习和特别是计算机视觉问题时,输入尺寸的管理是一个重要的方面,因为模型通常要求所有输入数据具有一致的尺寸。
方法一:让数据适应模型
这种方法涉及调整数据以匹配模型的预设输入要求。
例如,如果你使用的模型设计为接收 256x256 像素的图像,你需要将所有输入图像调整为这个尺寸。
这通常通过以下技术实现:
- 缩放:改变图像的尺寸以匹配模型的输入尺寸。
- 裁剪:从原始图像中裁剪出符合模型输入尺寸的部分。
- 填充:如果原始图像比需要的尺寸小,可以在图像周围添加像素(通常是黑色或白色)以达到所需的尺寸。
这种方法的优点是实现简单,可以直接使用预训练模型而无需修改模型架构。
缺点是可能会引入几何变形或丢失信息,特别是当原始图像的宽高比与模型所需的宽高比不一致时。
在实践中,有一些模型会固定输入尺寸,而一些模型则可以接受变化的输入尺寸。
模型固定输入尺寸的情况:
-
传统的卷积神经网络(例如VGG、ResNet):
- 这些经典的卷积神经网络通常在设计时会固定输入尺寸,例如224x224像素。这样做的好处是可以更轻松地设计网络结构,并且在训练和推理过程中的计算量是确定的。
-
一些定制的网络架构:
- 有些特定任务或特定领域的网络架构可能会要求固定的输入尺寸,这是因为网络的设计与输入尺寸有关。
模型灵活接受不同输入尺寸的情况:
-
YOLO(You Only Look Once)目标检测算法:
- YOLO算法是一种可以处理任意尺寸的图像的目标检测算法。它将输入图像分成网格,并在每个网格上预测目标的边界框和类别。因此,YOLO不需要固定的输入尺寸,可以处理各种尺寸的图像。
-
FCN(Fully Convolutional Network)语义分割网络:
- FCN是一种用于图像分割的网络,可以接受任意尺寸的输入图像,并输出相同尺寸的语义分割结果。这种网络通过使用卷积和反卷积操作来实现对变尺寸输入图像的处理。
-
深度变换器网络(Spatial Transformer Network,STN):
- STN是一种可以对输入图像进行空间变换的网络,可以处理不同尺寸和角度的输入图像,并生成相应的变换后图像。
总的来说,有些模型需要固定的输入尺寸,而有些模型则可以接受不同尺寸的输入。
对于需要固定输入尺寸的模型,需要在训练和推理过程中将所有输入图像调整为相同的尺寸;而对于可以接受不同尺寸的模型,可以灵活处理不同大小的输入图像。
方法二:修改模型适应数据
这种方法涉及修改模型的架构以适应不同尺寸的输入数据。
这通常意味着使用更灵活的网络结构,例如全卷积网络,它们能够处理任意尺寸的输入。例如:
- 调整网络层:修改模型的第一层或其他层,使其能够接受不同尺寸的输入。
- 使用自适应池化层:使用自适应池化(如自适应平均池化或自适应最大池化)来保证网络的输出尺寸独立于输入尺寸。
修改模型使之适应不同的输入尺寸可以使模型更加灵活,不再受限于特定的输入尺寸。然而,这可能需要较深的技术知识来调整网络结构,且有时候可能导致训练效率降低。
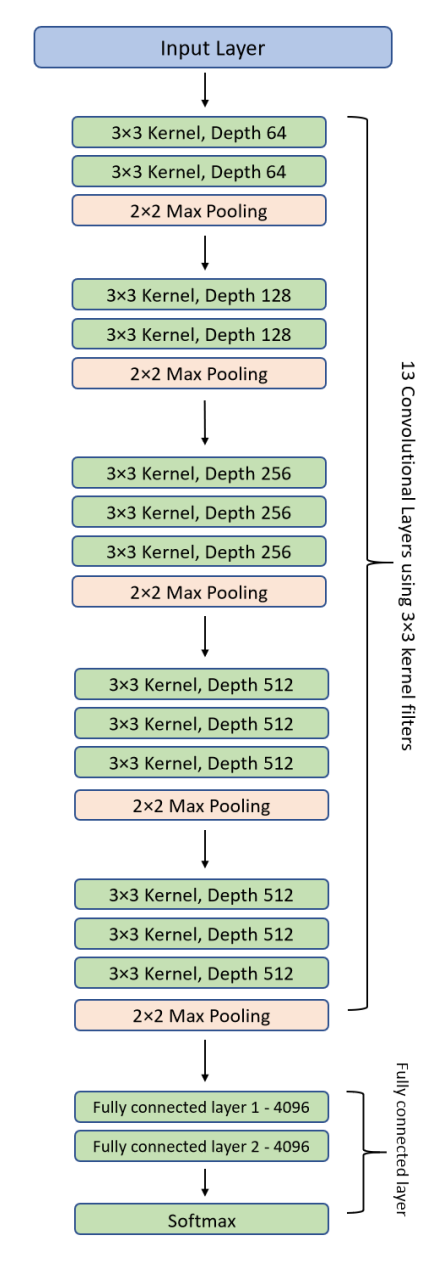
在提供的图像中,模型架构包括多个卷积层、池化层和全连接层。
这是一个经典的卷积神经网络,通常用于图像识别任务。
五种方法,我们可以对此模型进行修改,以适应不同的输入尺寸需求。这些修改分别影响模型的接受输入尺寸和特征提取的能力:
- 删除一个Pooling层,使224x224变为可接收112x112
- 删除一个Pooling层(比如2x2 Max Pooling),减少了图像尺寸下降的速度。这样模型可以在更小的输入尺寸(如112x112)上运行而不会太快减小特征图的维度,保留更多的特征信息。
- 增加一个Pooling层,使224x224变为可接收448x448
- 增加一个Pooling层可以使网络在处理更大尺寸的输入图像(如448x448)时,快速减小特征图的尺寸,以避免在网络深层中处理过大的数据量。
- 卷积步长stride=2 的,改为stride=1,使输入可变为112x112
- 当卷积层的步长从2改为1时,特征图的尺寸下降速度减慢。这样,较小的输入尺寸(如112x112)也能够在网络中保持足够的特征图尺寸,避免在深层中特征图尺寸过小。
- 卷积步长stride=1 的,改为stride=2,使输入可变为448x448
- 相反地,增加卷积层的步长可以加快特征图的尺寸下降。这样,在处理较大尺寸的输入(如448x448)时,可以避免特征图在网络深层中过大,有助于减少计算量和内存消耗。
- 使用全局平均池化(GAP)
- 引入全局平均池化层可以替换传统的全连接层,它会计算每个特征图的平均值形成一个固定大小的特征向量。这种方法的优势在于它使得网络可以处理任意尺寸的输入图像,因为无论输入图像的尺寸如何变化,全局平均池化输出的维度总是固定的。
这些修改使模型更加灵活,能够适应不同尺寸的输入,同时也影响模型的计算效率和特征提取能力。通过这样的调整,可以根据实际应用需求定制模型,优化其性能和资源使用效率。
方法三:划分Patch,分别处理
在某些应用中,尤其是图像尺寸非常大(如遥感影像或数字病理图像)时,可以将大图像划分为较小的片段(Patch),然后分别处理这些片段。例如:
- 图像分割:将大尺寸图像分割为多个较小的图像块,每个块符合模型的输入尺寸。
- 独立处理:对每个图像块独立应用模型,然后可能需要合并这些模型的输出以得到最终结果。
这种方法使得处理大尺寸图像变得可行,特别是当图像太大而无法直接输入到网络中时。这种方法的挑战在于如何有效地合并或解释这些独立处理块的结果,以确保整体结果的连贯性和准确性。
通过上述不同的方法,可以有效地管理和处理不同尺寸的输入数据,以满足特定模型的需求或优化模型性能。
目标检测器结构设计思路
目标检测,其目标是识别图像或视频中的物体,并确定它们的位置。这个任务通常包括两个子任务:分类和回归。
-
分类:这意味着识别图像中的物体属于哪一类别。例如,在一张道路场景的图像中,分类任务可能是识别汽车、行人、自行车等。
-
回归:这涉及确定物体的位置,通常是通过边界框来表示。边界框是一个矩形,用于描述物体在图像中的位置和大小。回归任务的目标是预测这些边界框的位置和尺寸,使其紧密地包围物体。
以YOLO(You Only Look Once)为例,它是一种流行的目标检测算法之一。
YOLO使用单个神经网络模型来同时执行分类和回归任务。
它将输入图像分成网格,并为每个网格预测边界框和类别。
这样,YOLO可以在一次前向传播中快速而准确地检测图像中的物体,因此它在实时应用中具有很高的性能。
目标检测(对一块区域分类+回归)算法设计:
- 需要自己构造样本;
- 需要自己为构造的样本分配标签;
- 除了分类任务外, 还有一个额外的回归任务。
- 反映在损失函数上, 除了分类损失函数外, 还应有一个额外的回归损失函数。
这种最简目标检测器(YOLO V1)将目标检测任务转换为滑窗区域的分类任务。
-
转换为分类任务:传统的目标检测任务涉及检测图像中的物体并定位它们。而这种方法则将目标检测任务简化为对图像中每个滑窗区域进行分类。滑窗是指图像上以固定大小和步长滑动的小方块区域。
-
使用分类模型的 Backbone:为了实现这个目标,可以直接使用一个预训练的图像分类模型的主干网络(backbone),如VGG、ResNet等。这样可以利用图像分类任务中已经学到的特征来帮助分类滑窗区域中是否包含目标物体。
-
构造分类损失函数:针对每个滑窗区域,构造分类损失函数来衡量模型对该区域的分类准确性。这个损失函数通常使用交叉熵损失函数来衡量模型对图像中目标物体的分类准确性。
-
每个滑窗区域作为一个样本:每个滑窗区域都被视为一个样本,并且被送入网络进行分类。因此,图像中的每个滑窗都会生成一个类别预测结果。
-
输出为M×N个向量:与传统的图像分类任务不同,网络的输出不再是一个单一的向量,而是包含了M×N个向量,每个向量对应一个滑窗区域的分类结果。
举个例子,假设我们有一张图像,大小为300×300像素。
我们选择一个大小为50×50像素的滑窗,并使用步长为10像素来滑动图像。
这样,我们就可以得到大约20×20=400个滑窗区域。
然后,我们将每个滑窗区域作为一个样本,送入预训练的分类模型进行分类。
最终,我们会得到400个分类结果,每个结果指示该滑窗区域是否包含目标物体。
从哪几个方面分析目标检测器
- Backbone:提取图像特征
- Neck:对特征图进行多尺度特征融合,并把这些特征传递给head层
- Head(分类分支、 回归分支):负责执行具体的任务,如分类、目标检测和图像分割等。通过输入经过Neck处理过的特征,产生最终的输出,从而实现模型的预测和分类任务.
- Anchor的选取方式
- 正负样本的分配方式
- 损失函数: 分类损失、 回归损失
从主干网络中得到特征图,每个位置都得到一个分类和回归的预测,有密集预测的问题,会漏掉部分目标。
一阶段目标检测算法(YOLO)都有这种问题,后来还有俩阶段目标检测算法,再加一个head层,俩个head,一个粗调,一个精调,更慢但效果更好。
YOLO 系列
v1:在图上做各个局部做卷积得到特征图,在特征图上寻找物体和具体位置
v2:v1特征图都是正方形框,但实际物体长的都不是正正方方,改进了预测框的自定义形状,如不同比例的长方形
v3:v2在处理图像有很多层,层越深感受野越大,最后一层输出层,就越适合大目标检测
那小目标咋办,v3打算分类处理,引入多个输出层,越前面的输出层适合小目标,中间的输出层适合中目标,最后一个输出层适合大目标。
v4:把别的论文中,最新的好用模块,改到Yolo中,反正视觉算法都是要提特征的,这种思想一直在持续,导致Yolo特别适合水论文,满大街都是各种Yolo论文
v5:从个人论文到团队项目,在不断维护,适合做项目
v6:略。
v7:推理加速,原先的Yolo加了很多分支结构,互相等导致速度变慢,训练时候可以不管用,但推理阶段你得合并,如卷积和bn层合并,配合gpu优化11补零凑出33卷积,多卷积核分支合并。
v8:v5团队续作,适合工程项目。做了一个集成,不仅能做检测,还能搞分割,分类,追踪,姿态估计,只需要改输出头,如分割只需要把最后一个输出层改一下
v9:v4 v7作者续作,v9解决神经网络因为链式结构的层层传播导致的信息丢失,那就开更短的辅助支路,解决浅层神经网络信息丢失问题。
v10:解决冗余预测问题和提高模型效率与准确度的策略。
首先,通过持续双重分配策略,包括双重标签分配和一致匹配度量,解决了后处理中的冗余预测问题,消除了对NMS的需求。
其次,在模型架构方面,通过轻量级分类头、空间-通道解耦下采样和rank引导block设计等方法提高了效率;同时,采用大核卷积和部分自注意力模块增强了模型的准确度。
这些改进使得模型在保持高效率的同时,在训练和推理过程中都能取得更优异的性能表现。
假设我们有一个YOLO模型用于物体检测,但在后处理过程中存在冗余预测问题,导致输出结果中有大量的重叠框。
想通过改进后处理步骤来解决这个问题,并同时提高模型的效率和准确度。
首先,引入了持续双重分配策略。
在训练过程中,为每个目标物体分配两个标签:一个主要标签和一个次要标签。
这样,模型在学习时可以得到更丰富和更和谐的监督信号。
在推理过程中,使用一致匹配度量来对预测结果进行过滤,而不是传统的非极大值抑制(NMS)方法。这消除了对NMS的需求,提高了推理的效率,并保持了竞争性的性能水平。
其次,对模型架构进行了全面的优化。
设计了轻量级分类头,减少了计算冗余。
同时,采用了空间-通道解耦下采样和rank引导block设计,进一步提高了模型的计算效率。
为了增强模型的准确度,我们引入了大核卷积和部分自注意力模块,以提高模型的感知能力和性能表现。