🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
💫个人格言: "如无必要,勿增实体"

文章目录
- Adaboost: 强化弱学习器的自适应提升方法
- 引言
- Adaboost基础概念
- 弱学习器与强学习器
- Adaboost核心思想
- Adaboost算法流程
- 1. 初始化样本权重
- 2. 迭代训练弱学习器
- 3. 组合弱学习器
- 4. 停止准则
- Adaboost的关键特性
- 应用场景
- 实现步骤简述
- 结语
Adaboost: 强化弱学习器的自适应提升方法
引言
在机器学习领域,集成学习是一种通过结合多个弱模型以构建更强大预测模型的技术。Adaptive Boosting,简称Adaboost,是集成学习中的一种经典算法,由Yoav Freund和Robert Schapire于1996年提出。Adaboost通过迭代方式,自适应地调整数据样本的权重,使得每个后续的弱学习器更加关注前序学习器表现不佳的样本,以此逐步提高整体预测性能。本文将深入探讨Adaboost的工作原理、算法流程、关键特性、优势及应用场景,并简要介绍其实现步骤。

Adaboost基础概念
弱学习器与强学习器
- 弱学习器:指那些仅比随机猜测略好一点的学习算法,如决策树的浅层版本。
- 强学习器:通过组合多个弱学习器,达到超越任何单个弱学习器性能的算法。
Adaboost核心思想
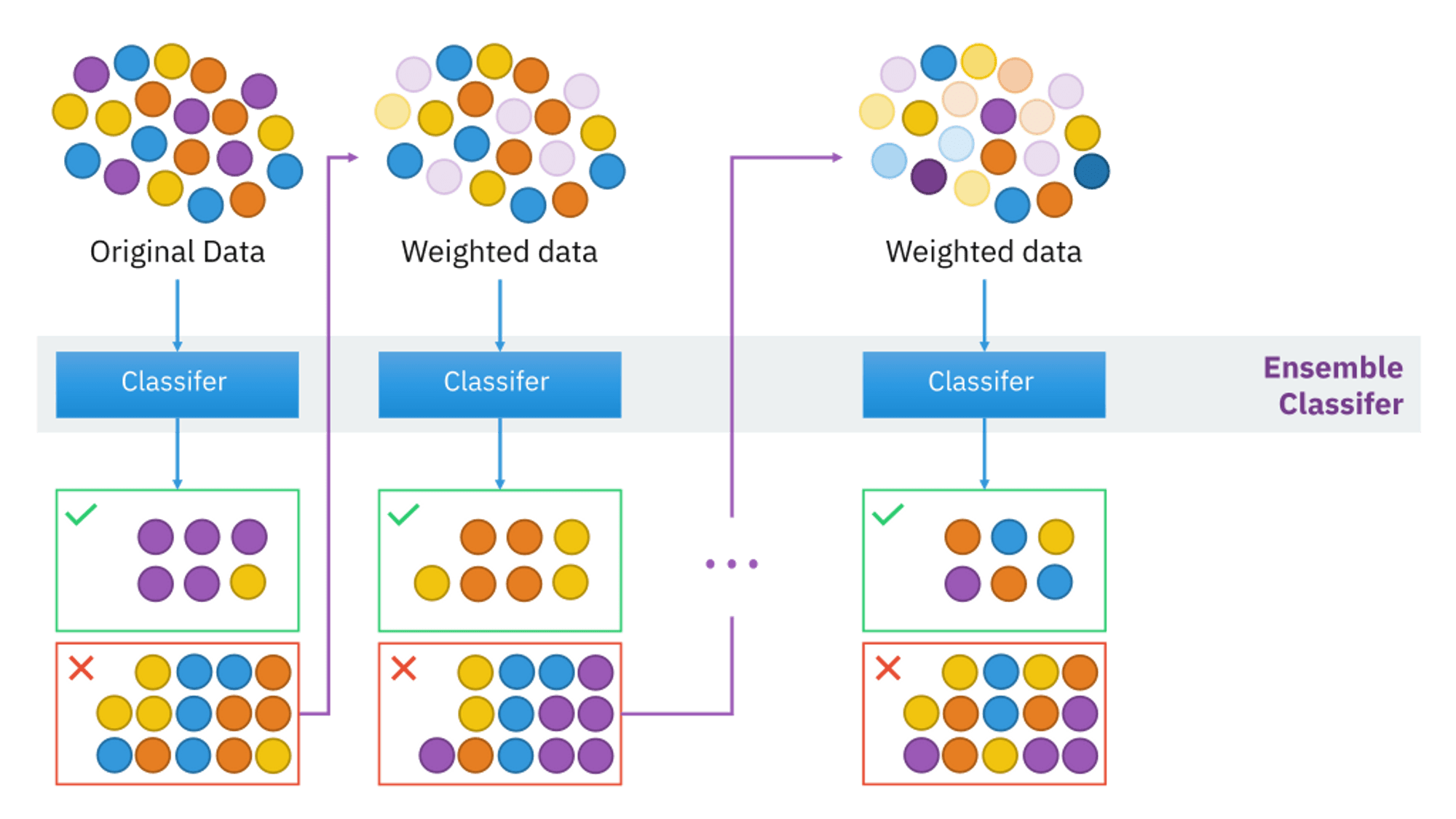
Adaboost的核心思想是通过改变训练数据的权重分布来不断聚焦于那些难以被正确分类的样本。每一轮迭代中,算法会根据上一轮的错误率调整样本的权重,使得错误分类的样本在下一轮中获得更高的权重,从而引导新生成的弱学习器重点关注这些“困难”样本。
Adaboost算法流程
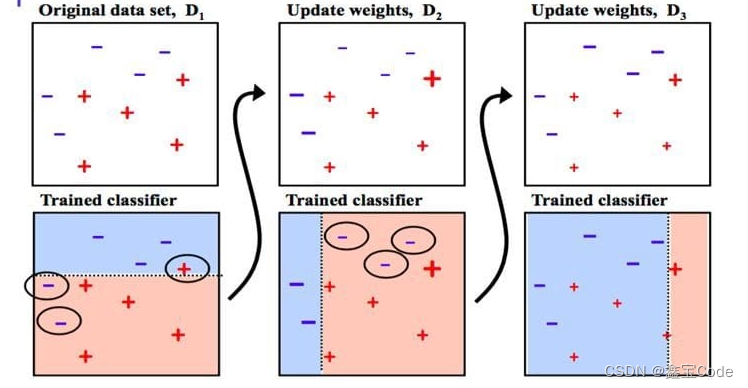
Adaboost算法可以分为以下几个步骤:
1. 初始化样本权重
- 所有训练样本初始权重相等,通常设为 w i ( 1 ) = 1 N w_i^{(1)} = \frac{1}{N} wi(1)=N1,其中 N N N 是样本总数。
2. 迭代训练弱学习器
对于每一轮 t = 1 , 2 , . . . , T t=1,2,...,T t=1,2,...,T:
- 使用当前样本权重分布训练弱学习器 h t h_t ht。弱学习器的目标是最小化加权错误率 ϵ t = ∑ i = 1 N w i ( t ) I ( y i ≠ h t ( x i ) ) \epsilon_t = \sum_{i=1}^{N} w_i^{(t)} I(y_i \neq h_t(x_i)) ϵt=∑i=1Nwi(t)I(yi=ht(xi)),其中 I I I是指示函数,当条件满足时返回1,否则返回0。
- 计算弱学习器的权重 α t = 1 2 ln ( 1 − ϵ t ϵ t ) \alpha_t = \frac{1}{2} \ln\left(\frac{1-\epsilon_t}{\epsilon_t}\right) αt=21ln(ϵt1−ϵt),反映了该学习器的重要性。
- 更新样本权重:对分类正确的样本减小其权重,错误分类的样本增加其权重。具体为 w i ( t + 1 ) = w i ( t ) exp ( − α t y i h t ( x i ) ) w_i^{(t+1)} = w_i^{(t)} \exp(-\alpha_t y_i h_t(x_i)) wi(t+1)=wi(t)exp(−αtyiht(xi)),然后重新归一化以确保所有权重之和为1。
3. 组合弱学习器
经过T轮迭代后,最终的强学习器为所有弱学习器的加权投票结果: H ( x ) = sign ( ∑ t = 1 T α t h t ( x ) ) H(x) = \text{sign}\left(\sum_{t=1}^{T} \alpha_t h_t(x)\right) H(x)=sign(∑t=1Tαtht(x))。
4. 停止准则
设定最大迭代次数 T T T作为停止条件,或直到达到预定的性能阈值。
Adaboost的关键特性
- 自适应性:自动调整数据权重,使算法能够专注于较难分类的样本。
- 弱学习器的多样性:由于每一轮学习器都针对不同的样本分布进行训练,这促进了弱学习器之间的多样性,有助于提升整体模型的泛化能力。
- 异常值鲁棒性:通过调整权重,Adaboost能够减少异常值对模型的影响。
- 过拟合控制:随着迭代增加,若学习器对新数据不再提供显著增益,则权重更新趋于平缓,自然停止学习过程,有助于防止过拟合。
应用场景
Adaboost因其高效和灵活,在多种机器学习任务中展现出广泛的应用潜力,包括但不限于:
- 分类问题:如手写数字识别、医学图像诊断。
- 异常检测:通过构建正常行为的强分类器,识别偏离此模型的行为。
- 特征选择:在预处理阶段,Adaboost可用于评估特征重要性,辅助筛选最有效的特征集。
实现步骤简述
实现Adaboost算法主要包括以下Python伪代码:
# 初始化
weights = np.ones(N) / N
alphas = []
models = []# 迭代T轮
for t in range(T):# 使用当前权重训练弱学习器model = train_weak_learner(X, y, weights)models.append(model)# 计算加权错误率errors = compute_errors(model.predict(X), y)weighted_error = np.sum(weights[errors != 0])# 计算弱学习器权重alpha = 0.5 * np.log((1 - weighted_error) / weighted_error)alphas.append(alpha)# 更新样本权重Z = np.sum(weights * np.exp(-alpha * y * errors))weights *= np.exp(-alpha * y * errors) / Z# 构建最终强学习器
def predict(X):scores = np.sum([alpha * model.predict(X) for alpha, model in zip(alphas, models)], axis=0)return np.sign(scores)结语
Adaboost算法以其独特的方式展示了如何通过集成弱学习器来构建出强大且鲁棒的预测模型。它不仅在理论上优雅,在实践中也极其有效,成为机器学习领域的一个基石。随着技术的发展,Adaboost及其变体在复杂数据集上的应用持续扩展,持续推动着人工智能的进步。理解并掌握Adaboost的工作机制,对于每一位致力于机器学习研究和应用的开发者来说,都是不可或缺的。