1. Redis持久化
Redis为什么需要持久化?因为Redis的数据我们都知道是存放在内存中的,那么每次关闭或者机器断电,我们的数据旧丢失了。
因此,Redis如果想要被别人使用,这个问题就需要解决,怎么解决呢?就是说我们的数据要同步到磁盘,只有同步到磁盘中了,数据才不会丢失,然后我们启动的时候,内存从磁盘里再加载数据,这样就既能满足基于内存的操作,保证性能,同时也尽可能的防止了数据的丢失。
那么Redis做持久化的方式有哪些呢? RDB和AOF
1.1 RDB
RDB是Redis默认的持久化方案,当满足一定条件的时候,会把当前内存中的数据写入磁盘,生成一个快照文件dump.rdb(默认)
可配置RDB文件的文件名与路径:
# The filename where to dump the DBdbfilename dump . rdb //dunmp.rdb 文件名dir . / // 文件路径
那么RDB什么时候会触发呢?
- 自动触发
- 配置触发
save 900 1 900 s 检查一次,至少有 1 个 key 被修改就触发save 300 10 300 s 检查一次,至少有 10 个 key 被修改就触发save 60 10000 60 s 检查一次,至少有 10000 个 key 被修改
- shutdown正常关闭;
任何组件,在正常关闭的时候,都会去完成该完成的事情,比如 Mysql中的Redolog 持久化 正常关闭的时候也会去持久化。
- flushall指令触发
数据清空指令会触发 RDB 操作,并且是触发一个空的 RDB 文件,所以, 如果在没有开启其他的持久化的时候,flushall 是可以删库跑路的,在 生产环境慎用。
- 手工触发
- save 主线程去进行备份,备份期间不会去处理其它的指令,其它指令必须等待
- bgsave 子线程去进行备份,其它指令正常执行
操作实例演示:
a.我们首先添加一份数据并且备份到RDB
redis > set k1 1redis > set k2 2redis > set k3 3
b.查看数据是否存在
redis > keys *
c.进行shutdown操作触发RDB快照
redis> shutdown
d.对现有RDB数据进行备份cp
redis > cp dump . rdb dump . rdb . bak
e 启动redis
redis > src / redis - server & redis . conf
发现数据都还在
f. 现在模拟数据丢失
redis > flushall
g. 停服务器再启动
redis > shutdownredis > src / redis - server & redis . conf
h. 此时发现数据已经丢失,现在就要从我们备份的数据恢复,先关闭
redis> shutdown
i.删除原RDB备份数据
redis > rm dump . rdb
j 将备份数据改名为bump.rdb
mv dump.rdb.bak dump.rdb
k. 重启服务
src / redis - server & redis . conf
我们发现数据已经恢复
思考:我们的数据是怎么备份到RDB中的呢?
1. 新起子线程,子线程会将当前 Redis 的数据写入一个临时文件2. 当临时文件写完成后,会替换旧的 RDB 文件。当 Redis 启动的时候,如果只开启了 RDB 持久化,会从 RDB 文件中加载数据。
RDB的优势:
1. 是个非常紧凑型的文件,非常适合备份与灾难恢复。2. 最大限度的提升了性能,会 fork 一个子进程,父进程永远不会产于磁盘IO或者类似操作。3. 更快的重启。
简单总结一句话,RDB恢复与备份都非常的快
RDB的不足
1.数据安全性不是很高,因为是根据配置的时间来备份,假如每5分钟备份 一次,也会有5分钟数据的丢失
2. 经常 fork 子进程,所以比较耗 CPU ,对 CPU 不是很友好。
1.2 AOF
由于RDB的数据可靠性非常低,所以Redis又提供了另外一种持久化方案: Append Only File 简称 AOF
AOF默认是关闭的,你可以在配置文件中进行开启 (追加文件,即每次更改的命令都会附加到我的AOF文件中)
appendonly no // 默认关闭,可以进行开启# The name of the append only file ( default : "appendonly.aof" )appendfilename "appendonly.aof" //AOF 文件名
1.2.1同步机制
# appendfsync always 表示每次写入都执行 fsync( 刷新 ) 函数 性能会非常非常慢 但是非常安全appendfsync everysec 每秒执行一次 fsync 函数 可能丢失 1s 的数据# appendfsync no 由操作系统保证数据同步到磁盘,速度最快 你的数据只需要交给操作系统就行
1.2.2 重写机制
由于AOF是追加的形式,所以文件会越来越大,越大的话,数据加载越慢。所以我们需要对AOF文件进行重写。
那么什么是重写呢?
比如 我们的 incr 指令,假如我们 incr 了 100 次,现在数据是 100 ,但是我们的aof 文件中会有 100 条 incr 指令,但是我们发现这个 100 条指令用处不大,假如我们能把最新的内存里的数据保存下来的话。所以,重写就是做了这么一件事情,把当前内存的数据重写下来,然后把之前的追加的文件删除。
重写流程(Redis7之前)
1. Redis fork 一个子进程,在一个临时文件中写入新的 AOF (当前内存的数据生成的新的AOF )2. 那么在写入新的 AOF 的时候,主进程还会有指令进入,那么主进程会在内存缓存区中累计新的指令 (但是同时也会写在旧的AOF 文件中,就算重写失败,也不会导致AOF 损坏或者数据丢失)3. 如果子进程重写完成,父进程会收到完成信号,并且把内存缓存中的指令追加到新的AOF 文件中4. 替换旧的 AOF 文件 ,并且将新的指令附加到重写好的 AOF 文件中。
什么时候进行重写(根据配置)
# 重写触发机制auto - aof - rewrite - percentage 100auto - aof - rewrite - min - size 64 mb 就算达到了第一个百分比的大小,也必须大于 64 M
说明:在aof文件小于64mb的时候不进行重写,当到达64mb的时候,就重写一次。重写后的aof文件可能是40mb.上面配置了auto-aof-rewrite-percentage为100,即aof文件到了80mb的时候进行重写
1.2.3 AOF的优势与不足
优势
1. 安全性高,就算默认的持久化同步机制,也最多只会导致 1s 丢失。2.AOF 由于某些原因,比如磁盘满了等导致追加失败,也能通过 redischeck-aof 工具来修复 ./redis-check-aof --fix append3. 格式都是追加的日志,所以可读性更高
不足
1. 数据集一般比 RDB 大2. 持久化跟数据加载比 RDB 更慢3. 在 7.0 之前,重写的时候,因为重写的时候,新的指令会缓存在内存区,所以会导致大量的内存使用4. 并且重写期间,会跟磁盘进行 2 次 IO ,一个是写入老的 AOF 文件,一个 是写入新的AOF 文件
2.Redis集群
2.1 Redis主从
为什么要有主从?
1. 故障恢复 主挂了或者数据丢失了,我从还会有数据冗余2. 负载均衡,流量分发 我们可以主写,从库读,减少单实例的读写压力3. 高可用 我们等下讲的集群 等等,都是基于主从去实现的
安装教程后续会单独出文章
我们现在已经安装了一个主从,先看下基本信息
主:
127.0 . 0.1 : 6379 > info replication# Replicationrole : master // 角色connected_slaves : 1 // 从节点数量slave0 : ip = 192.168 . 8.127 , port = 6379 , state = online , offset = 78899 , lag = 1 // 从节点的信息 状态 偏移量master_replid : 04f4969 ab63ce124e870fa1e4920942a5b3448e7//# master 启动时生成的 40 位 16 进制的随机字符串,用来标识 master 节点master_replid2 : 0000000000000000000000000000000000000000master_repl_offset : 78899 //mater 已写入的偏移量second_repl_offset : - 1repl_backlog_active : 1repl_backlog_size : 1048576 // 缓冲区大小repl_backlog_first_byte_offset : 1repl_backlog_histlen : 78899 // 缓冲区的数据已有大小(是个环形,跟RedoLog一样会覆盖)
从:
127.0.0.1:6379> info replication
# Replicationrole : slave // 角色master_host : 192.168 . 8.129 // 主节点 IPmaster_port : 6379 // 主节点端口master_link_status : up // 连接状态 up 是正常同步连接状态 down 表示复制端口master_last_io_seconds_ago : 1 // 主库多少秒没有发送数据到从库 0-10master_sync_in_progress : 0 // 是否正在跟主服务同步slave_repl_offset : 163 // 从节点偏移量slave_priority : 100 // 选举时成为主节点的优先级 越大优先级越高 0不会成为主节点slave_read_only : 1 // 是否为只读从库 如果不是只读,则能自己进行数据写入,默认是只读connected_slaves : 0 // 连接的从库实例master_replid : 04f4969 ab63ce124e870fa1e4920942a5b3448e7//master 启动时生成的 40 位 16 进制的随机字符串,用来标识 master 节点master_replid2 : 0000000000000000000000000000000000000000//slave 切换 master 之后,会生成了自己的 master 标识,之前的 master 节点的标识存到了master_replid2 的位置master_repl_offset : 163 // 已写入偏移量second_repl_offset : - 1repl_backlog_active : 1repl_backlog_size : 1048576 // 复制积压的缓存区大小repl_backlog_first_byte_offset : 1repl_backlog_histlen : 163
2.1.1 主从数据同步
我们发现,我们的信息中,有个slave_read_only,如果是1代表只读。也就是默认,当然也可以配置成写,但是写的数据不会同步到主库,需要自己去保证数据的一致性,可能从库写的数据会被主库的数据操作覆盖。出现从库set一个值后,获取到的是主库覆盖的数据。
举例:
127.0 . 0.1 : 6379 > set k1 2 // 从库设置 k1 2
127.0.0.1:6379> set k1 3 //主库设置k1为3 并且会同步到从库
127.0.0.1:6379> get k1
"3" // 从库得到的是主库设置的值
思考: 我们主库的数据是怎么同步到从库的呢?同步过程是怎么样的?或者主从数据是怎么保证一致性的。
a.建立连接
当首次成为主节点的从节点时,执行 replicaof ip port 命令的时候就会保存主服务器的IP 与端口并且与主服务器建立连接,接收主节点返回的命令判断主节点是否有密码 如果有 进行权限校验保证主从之前保存了各自的信息,并正常连接。
b.slave发起同步master数据指令
在slave的serverCron方法调用replicationCron方法,里面会发起跟master的数据同步
run_with_period ( 1000 ) replicationCron ();
b.1 全量同步
1. master 服务器收到 slave 的命令后( psync ),判断 slave 传给我的master_replid 是否跟我的 replid 一致,如果不一致或者传的是个空的,那么就需要全量同步。2. slave 首次关联 master ,从主同步数据, slave 肯定是没有主的 replid, 所以需要进行全量同步。3. 进行全量同步3.1. master开始执行 bgsave ,生成一个 RDB 文件,并且把 RDB 文件传输给我们的slave ,同时把 master 的 replid 以及 offerset ( master 的数据进度,处理完命令后,都会写入自身的offerset )3.2. slave接收到 rdb 文件后,清空 slave 自己内存中的数据,然后用 rdb来加载数据,这样保证了slave 拿到的数据是 master 生成 rdb 时候的最新数据。3.3. 由于 master 生成 RDB 文件是用的 bgsave 生成,所以,在生成文件的时候,是可以接收新的指令的。那么这些指令,我们需要找一个地方保存,等到slave 加载完 RDB 文件以后要同步给 slave 。3.2.1. 在master 生成 rdb 文件期间,会接收新的指令,这些新的指令会保存在一个内存区间,这个内存区间就是replication_buffer 。3.2.2. 这个空间不能太小,如果太小,为了数据安全,会关闭跟从库的网络连接。再次连接得重新全量同步,但是问题还在,会导致无限的在同步
replication_buffer大小的设置
client - output - buffer - limit replica 256 mb 64 mb 60 256 mb 硬性限制,大于 256M 断开连接64 mb 60 软限制 超过 64M 并且超过了 60s 还没进行同步 内存数据就会断开连接
b.2 增量同步
为什么需要增量同步?
这是因为每个节点都会保存数据的偏移量,那么就有可能出现slave跟master网络断开一小会,然后发起数据同步的场景,如图所示:
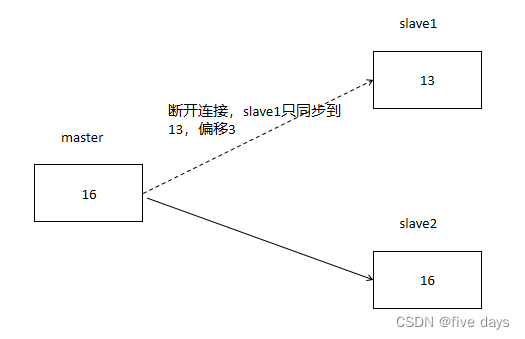
slave1由于网络断开了,偏移量跟master相差了3.
那么当slave1重新跟master连接后,同样的会去跟master连接触发数据同步。但是这个时候还需不需要全量同步了?我们肯定是尽可能的减少全量同步。
所以,当master收到slave的指令时:
1. 判断 slave1 传给我的 master_replid 是否跟 master 的 replid 一致,由于之前已经连接过保过了master 的 replid ,满足条件。2. 所以我希望只同步断开连接后没有同步到的数据,必须,我 slave1 只差 了3 的数据。那么我需要找到这个 3 的数据。所以 master 中有个另外的积压缓(replication_backlog_buffer )。我们也不可能无限制的往里面写数据, replication_backlog_buffer 的数据是会覆盖的。3. 所以,我们 slave1 跟 master 相差的 3 条数据可能会被覆盖,如果覆盖了,触发全量,如果没有覆盖,即能找到相差的3 条数据。增量即可。
replication_backlog_buffer的配置
# The bigger the replication backlog , the longer thetime the replica can be 复制积压越大,复制副本的时间越长# disconnected and later be able to perform a partialresynchronization . 已断开连接,稍后可以执行部分重新同步。## The backlog is only allocated once there is at leasta replica connected . 只有在至少连接了一个副本后,才会分配积压工 作。## repl - backlog - size 1 mb
b.3 指令同步
master写入的指令,异步同步给slave,如果有slave,写入replication_backlog
_buffer
整体主从数据同步流程图: Redis主从同步策略| ProcessOn免费在线作图,在线流程图,在线思维导图
2.2 Sentinel哨兵
主从,虽然解决了比如负载、数据备份等问题。但是我们发现如果master挂了,slave不会直接升级为主,必须手动把slave升级为主。这样肯定人为维护的成本比较高。所以我们希望能有一个技术帮我们实现这样的需求,于是就有了哨兵集群。
什么是哨兵集群?
Redis sentinel 在不适用 Cluster 集群的时候,为 Redis 提供了高可用性。并且提供了监测、通知、自动故障转移、配置提供等功能。监控 :能够监控我的 Redis 各实例是否正常工作通知 :如果 Redis 的实例出现问题,能够通知给其他实例以及 sentinel自动故障转移 :当我的 master 宕机, slave 可以自动升级为 master配置提供 : sentinel 可以提供 Redis 的 master 实例地址,那么客户端只需要跟sentinel 进行连接, master 挂了后会提供新的 master
其实sentinel是独立于Redis服务的单独的服务,并且它们之间是相互通信的。
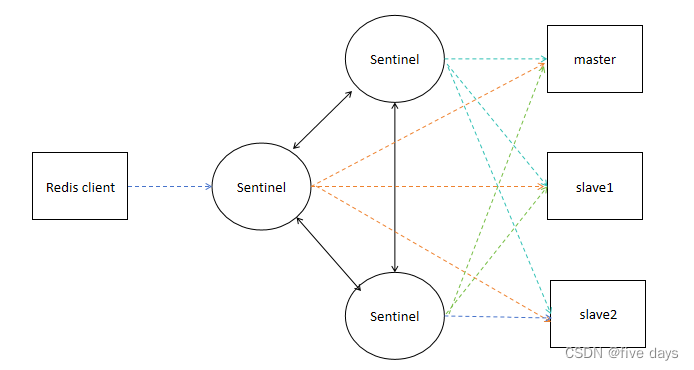
2.2.1 哨兵故障转移流程
我们的哨兵到底是怎么去发现我们的master挂了的呢?挂了后让slave变成Master的整个流程是咋样的呢?
a。发现master故障
1. 当我们某个 sentinel 跟 master 通信时(默认 1s 发送 ping ),发现我在 一定时间内(down-after-milliseconds ) 没有收到 master 的有效的回复。这个时候这个sentinel 就会人为 master 是不可用,但是有多个sentinel,它现在只有 1个人觉得宕机了,这个时候不会触发故障转移,只会标记一个状态,这个状态就是 SDOWN ( Subjectively Down condition ),也就是我们讲的主观下线2. SDOWN 时,不会触发故障转移,会去询问其他的 sentinel ,其他的sentinel是否能连上 master ,如果超过 Quorum( 法定人数 ) 的 sentinel 都认为master 不可用,都标记 SDOWN 状态,这个时候, master 可能就真的是down 了。那么就会将 master 标为 ODOWN ( Objectively Down condition 客观下线)
b. 进行故障转移
1. 当状态为 ODWON 的时候,我们就需要去触发故障转移,但是有这么多 的sentinel ,我们需要选一个 sentinel 去做故障转移这件事情,并且这 个sentinel 在做故障转移的时候,其他 sentinel 不能进行故障转移2. 所以,我们需要选举一个 sentinel 来做这件事情 : 其中这个选举过程有 2个因素。2.1 Quorum 如果小于等于一半,那么必须超过半数的 sentinel 授权,你才能去做故障迁移,比如5 台 sentinel ,你配置的 Quorum=2 ,那么选举的时候必须有3 ( 5 台的一半以上)人同意2.2. Quorum如果大于一半,那么必须 Quorum 的 sentinel 授权,故障迁移才能启动。
c.选哪个slave来变成master
1. 与 master 的断开连接时间如果 slave 与主服务器断开的连接时间超过主服务器配置的超时时间 (down-after-milliseconds )的十倍,被认为不适合成为 master 。直接去除资格2. 优先级配置 replica-priority , replica-priority 越小,优先级越高,但是配置为0的时候,永远没有资格升为 master3. 已复制的偏移量比较 slave 的赋值的数据偏移量,数据最新的优先升级为 master4. Run ID (每个实例启动都会有个 Run ID )通过 info server 可以查看。
2.2.2 Sentinel导致的数据一致性问题
官方建议配置至少3个sentinel
原因如下:
1. 如果只有 1 个 sentinel 实例,则这个实例挂了就不能保证 sentinel 的高可用性。2. 如果,我配置了 2 个 sentinel ,分别在 127 跟128.n并且我配置的quorum=1 ;就可能发生2.1.sentinel2检测到 master 不可用,因为 127 跟 128 网络断开,这个时候会触发主观下线,同时,sentinel2 只能连接到 1 个 sentinel ,也满足半数以上原则(只有1 个 sentinel2 )2.2.sentinel2开启故障转移,将 128 的 slave 升级为 master, 就出现了 2 个master,这个情况也叫作脑裂。并且客户端会连接到 2 个 master 。 (客户端连的是sentinel 集群,所以 sentinel1 连到 127.sentinel2 连到 128 )2.3 2 个 master 都会写入数据,当网络恢复后, 127 会变成从, 127 的数据会从 128 去拿取,这个时候 127 的数据就会丢失
2.2.3 脑裂问题
脑裂问题其实就是我会有2个master,client会从不同的master写数据,从而在master恢复的时候会导致数据丢失。
所以只要发生分区容错性,不管多少节点都会出现,比如3个节点。
初始 129 是 master, 假如 129 网络断开,跟 127.128 连接断开后, 128sentinel发起故障转移。发现 sentinel 的个数超过一半,能够发起故障 转移。将128 升级为 master ,导致 128.129 同时 2 个 master 并可用
解决方案:
在Redis.cfgt文件中有2个配置:
min - replicas - to - write 1 至少有 1 个从节点同步到我主节点的数据,但是由于是异步同步,所以是最终一致性 不会确保有数据写入min - replicas - max - lag 10 判断上面 1 个的延迟时间必须小于等于 10s
按上述场景
129由于没有slave同步,不满足我配置的要求,不能进行数据写入。尽量减少数据一致性问题。
思考,为什么部署奇数台?一因为4跟3 能容许挂掉的机器数量是一样的,都是1台
2.3 Redis Cluster
我们发现sentinel提供了比如监控、自动故障转移、客户端配置等高可用的方案,但是没有分片功能。
何为分片:就是我希望把数据分别到不同的节点。这样如果某些节点异常,其它数据能正常提供服务,跟我们微服务的思想很相似。
所以我们cluster就提供了这样的解决方案
1. 多个节点之间的数据拆分,也就是我们的数据分片2. 当某些节点遇到故障的时候,其他的节点还能继续服务。
2.3.1 hash slot(虚拟槽)
那么如何进行分片?分片要做的事情就是把不同的数据放到不同的实例里面去。就相当于我们分表,不同的数据放到不同的表里。
普通取模问题
取模 直接取模实例数,得到 key 的 hash 值,取模实例数,假如实例是 3 ,那么取模后得到0-2 的值,每个值代表一个实例。但是这种取模有一个问题,假如我做了实例的扩容与缩容,那么全部数据要进行迁移。假如我之前是 3 台,扩容到 4 台,那么所有的数据都必须重新 rehash 。所以, Redis 里面提出了一个 Hash 槽,也叫作虚拟槽的概念。什么是虚拟槽,其实就是虚拟节点。Redis cluster 中有 16384 个虚拟槽
我们的key会跟槽对应,怎么对应?
根据key通过CRC16取模16383得到一个0到16383的值,计算公式:slot=CRC16(key)&16383,得到的值,就代表这个key在哪个虚拟槽。
举例:
假如set k1 1 :CRC16 ( k1 ) & 16383 = 11901set k2 1 :CRC16 ( k2 ) & 16383 = 10set k3 1 :CRC16 ( k3 ) & 16383 = 6666那么我们 k1 对应的槽是 11901 k2 对应的槽是 10 k3 对应的槽是 6666
key跟槽的关系是根据key算出来的,后续不能变动。
如果想把相关keu放入一个虚拟槽,也就是一个实例节点,我们可以采用{},那么就只会根据{}里面的内容计算hash槽!
比如: zsc{18}跟james{18}就会在一个虚拟槽
那么key怎么去放到我们的真实节点?
master1 0-5460 虚拟槽master2 5461-10922 虚拟槽master3 10923-16383 虚拟槽
我们知道,k1的虚拟槽是10001,所以放到master3,依次类推,k2放到master1,k3放到mster2
从节点的数据全部来源于主,所以k1放入master3的从,以此对应。
127.0.0.1:6380> cluster nodes 查看当前节点的虚拟槽信息这样,每次节点的扩容与缩容,只需要改变节点跟虚拟槽的关系即可,不需要全部变动。
3. 总结
redis是内存型数据库,因此每次机器关机都会清理内存,因此,要想保证redis的可用性,就需要持久化技术,redis持久化分为RDB快照和AOF追加两种形式; 但是为了高可用,流量的分发以及为了应对redis挂了之后的可用性,引入了主从,主从之间就又设计到了数据的全量同步和增量同步;随后,为了更进一步的将主从切换智能化,提出了sentinel哨兵模式,可用监控主的状态,采用一定的策略,保证主挂了以后从可以升级为主;最后是为了更进一步提升redis的高可用,采用集群的方案,将redis数据分布到不同的节点进行管理。