前言
本文主要介绍 mysql 的几大特性之几,如:双写缓冲和插入缓存。
双写缓冲
基本概念
双写缓冲(doublewrite buffer)是MySQL/InnoDB中用于支持原子页面更新的一种机制。在传统的数据库系统中,为了保证数据的一致性和可恢复性,通常需要进行冗余写入操作。这种冗余写入通过在原始数据写入后,再将这些数据写入一个额外的缓冲区来实现,从而确保即使在发生故障的情况下也能从备份数据中恢复。
核心就是通过备份数据页的方式保证数据的可靠性、一致性
然而,这种冗余写入操作会对数据库性能产生负面影响,并且增加了存储设备的写入流量,尤其是在使用基于闪存的SSD作为存储介质时。随着非易失性内存(NVM)技术的发展,如PCM和STT-MRAM,它们提供了低延迟、高带宽、非易失性和高容量等特点,为改善数据库事务处理提供了新的可能性。
在最新的研究中,提出了一种名为LSBM的日志结构化缓冲管理器,该管理器利用NVM技术来高效地原子更新页面。LSBM通过异地更新页面来实现原子性,并进行页面缓冲以提高性能。此外,LSBM还能够动态回收缓冲页面,以减少对存储的写入流量。通过在NVDIMM上实现LSBM并将其移植到MySQL/InnoDB中,实验结果表明LSBM不仅提高了数据库性能,还减少了在线事务处理(OLTP)工作负载上的写入流量。
因此,对于使用MySQL/InnoDB的数据库系统来说,考虑采用基于NVM的LSBM可以有效地优化双写缓冲机制,既保持了数据的一致性和可恢复性,又显著提升了数据库的整体性能和存储效率。
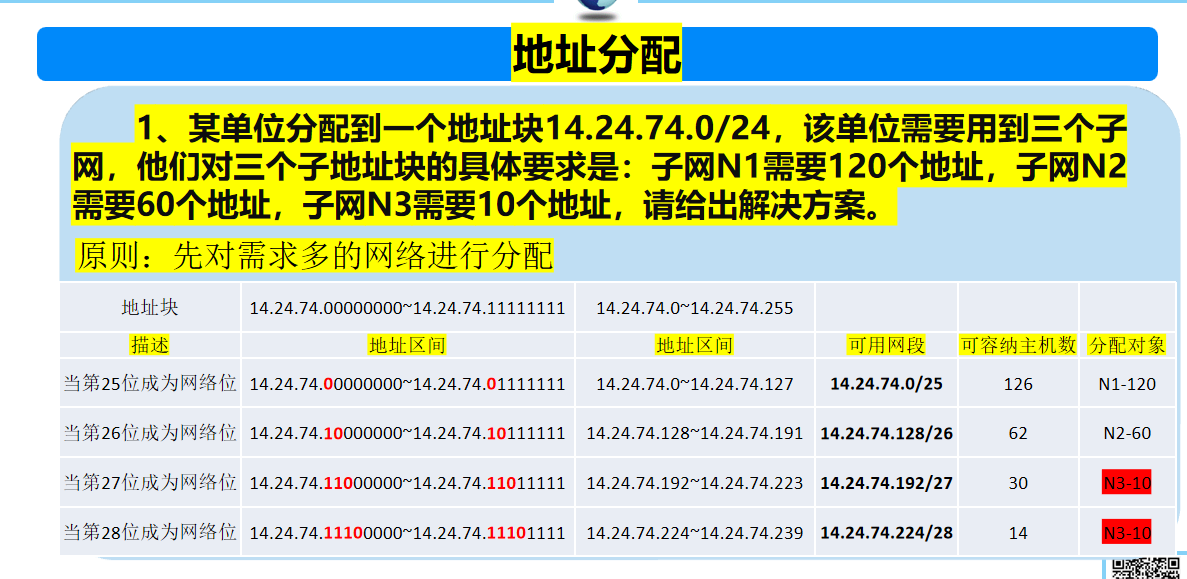
结构
-
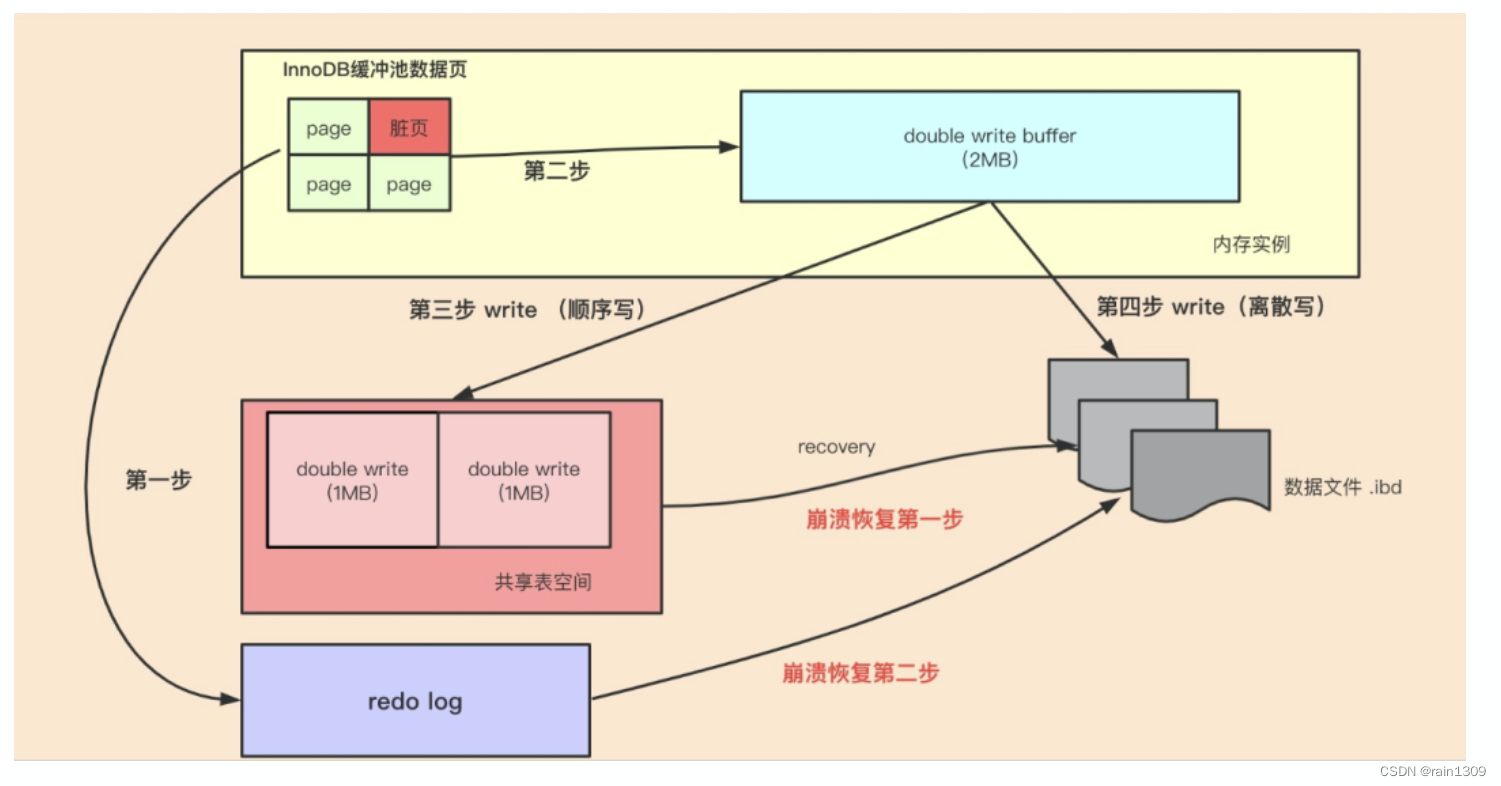
在内存结构中,Doublewrite Buffer由128个页(Page)构成,大小是2MB。这些页在内存中以Doublewrite Buffer的形式存在。
-
在磁盘结构中,Doublewrite Buffer在系统表空间上是128个页(2个区,extend1和extend2),大小也是2MB。这些页在磁盘上以Doublewrite File的形式存在。
工作流程
- 写操作触发: 当执行INSERT、UPDATE或DELETE等写操作时,MySQL首先将数据写入双写缓冲区。
- 同步到Doublewrite File: Doublewrite Buffer 的内存中的数据页会刷写到Doublewrite Buffer的磁盘上,分两次写入磁盘共享表空间中(连续存储,顺序写,性能很高),每次写1MB
- 实际数据写入: 一旦Doublewrite File中的数据被确认已经写入磁盘,MySQL就可以将这些数据写入实际的数据文件中
- 恢复机制: 如果在写操作过程中发生故障,MySQL可以从Doublewrite File中恢复数据。由于Doublewrite File中的数据是完整的,因此可以用来修复损坏的数据文件,确保数据的完整性和一致性。
为什么需要双写缓冲
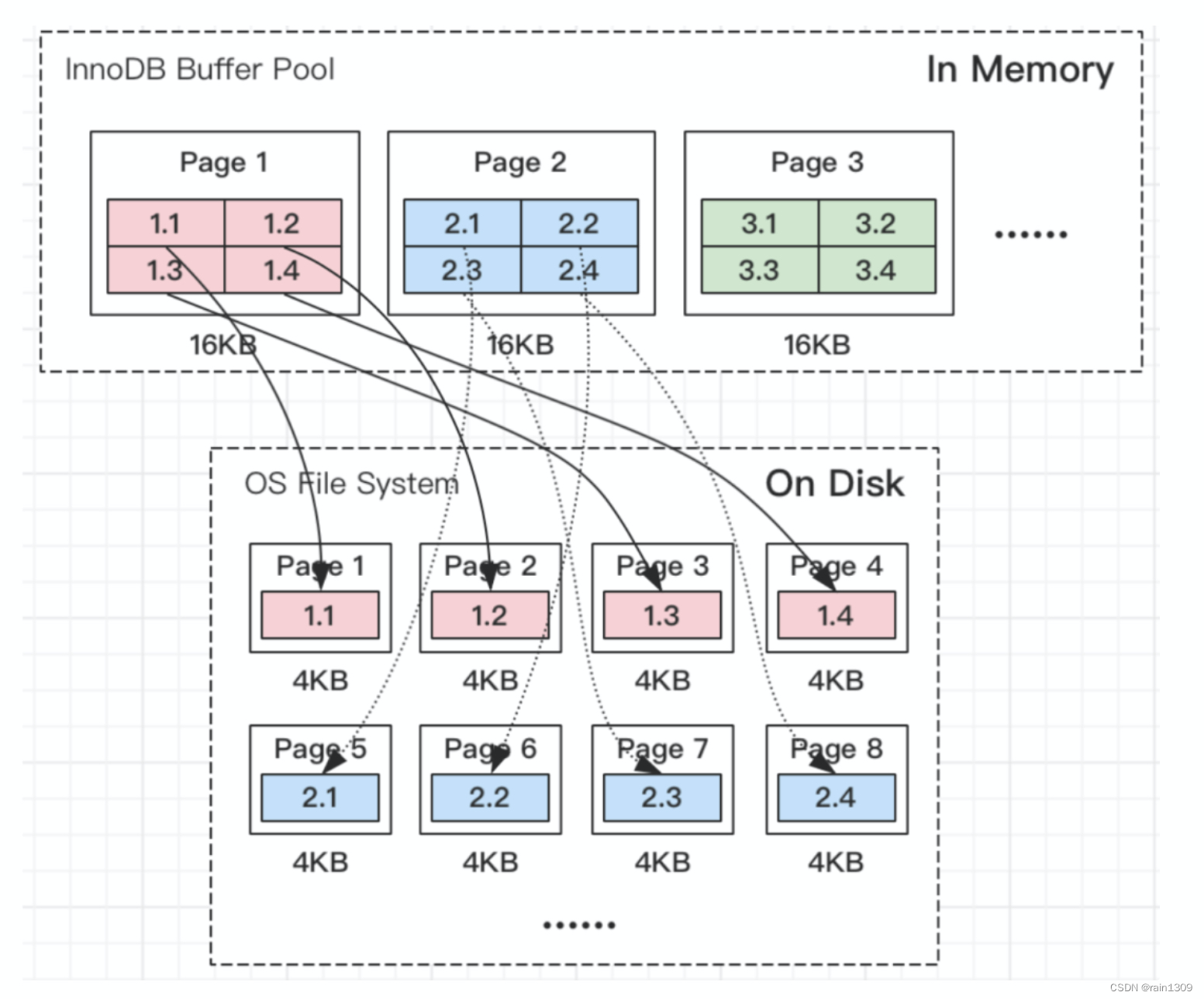
常见的服务器一般都是Linux操作系统,Linux文件系统页(OS Page)的大小默认是4KB。而MySQL的页(Page)大小默认是16KB。MySQL程序是跑在Linux操作系统上的,需要跟操作系统交互,所以MySQL中一页数据刷到磁盘,要写4个文件系统里的页。
需要注意的是,这个操作并非原子操作,比如我操作系统写到第二个页的时候,Linux机器断电了,这时候就会出现问题了。造成”页数据损坏“。并且这种”页数据损坏“靠 redo日志是无法修复的。
重做日志中记录的是对页的物理操作,而不是页面的全量记录,而如果发生partial page write(部分页写入)问题时,出现问题的是未修改过的数据,此时重做日志(Redo Log)无能为力。写doublewrite buffer成功了,这个问题就不用担心了
插入缓冲
基本概念
MySQL的insert buffer是InnoDB存储引擎的一个重要特性,主要用于优化非聚集索引的插入和更新操作。以下是关于MySQL insert buffer的详细解释:
Insert buffer是一种特殊的数据结构(B+ tree),并不是缓存的一部分,而是物理页。当受影响的索引页不在buffer pool中时,MySQL会使用insert buffer来进行数据插入。
对于非聚集索引的插入或更新操作,MySQL不会每次直接将数据插入到索引页中。相反,它会先将数据存储在一个临时的区域(即insert buffer)中,然后再逐步将这些数据合并到目标索引页中。
从性能改进的角度来看,使用非集群次级索引可能会导致额外和随机的磁盘访问,从而降低存储设备的性能。MySQL的存储引擎通过插入缓冲来缓解这一问题,避免了额外的磁盘访问。这表明插入缓冲在减少磁盘I/O操作中起到了重要作用,有助于提高数据库的整体性能。
适用场景
MySQL在我们对非唯一的二级索引进行DML(删除行、写入行、修改行)时的优化
为什么是非唯一索引?
当我们对唯一索引进行插入的时候需要查询数据是否唯一,如果数据在缓冲池中则直接读取缓冲池,如果数据不在缓冲池中则读取磁盘数据页,所以唯一索引会产生大量磁盘IO。
原理
对非唯一二级索引插入的流程如下:
- 数据在缓冲池中,直接修改缓冲池数据页
- 数据不在缓冲池中
- 写入到 insert buffer,异步刷新到磁盘
insert buffer 数据写回磁盘的时机:
- 辅助索引页被读取到缓冲池时
- 当辅助索引页被读取到缓冲池时,例如正在执行正常的 select 查询操作,这时需要检查 Insert Buffer Bitmap 页,然后确认该辅助索引页是否有记录存放于 Insert Buffer B+ 树中。若有,则将 Insert Buffer B+ 树中该页的记录插入到辅助索引页中
- insert buffer bitmap 页追踪到该辅助索引页已经没有可用空间
- Insert Buffer Bitmap是InnoDB存储引擎中用于追踪每个辅助索引页的可用空间,并确保至少有1/32页的空间以防止插入操作导致页面溢出。这个特殊的数据页类型可以标记多个辅助索引页的可用空间,以保证每次合并插入操作的成功
- Master Thread
- 在 Master Thread 中每秒或每10秒会进行一次 Merge Insert Buffer 操作
为什么 insert buffer 能提高性能
Insert Buffer B+ 树通过将对数据页的多次操作通过一次操作合并到原有的辅助索引中
insert buffer 提高了哪方面的性能
减少了磁盘随机读,因为当数据不在内存页的时候也不用去磁盘读取对应的数据页再更新数据页,而是直接存储在 Insert Buffer 中,再择机刷会磁盘
insert log 和 redo log 的区别
- 功能和目的:
- Insert Buffer:主要用于优化非聚集索引(辅助索引)的插入操作。当受影响的索引页不在Buffer Pool中时,会将其放入Insert Buffer中,以便后续合并操作。
- Redo Log:用于保证事务的原子性和持久性,记录的是页的物理修改操作,用来恢复提交事务修改的页操作。
- 数据结构:
- Insert Buffer:是一种特殊的数据结构(B+ tree),并不是缓存的一部分,而是物理页。
- Redo Log:由每个512字节大小的日志块组成,存储在内存中的redo log buffer中。
- 应用场景:
- Insert Buffer:主要针对非聚集索引的插入或更新操作,当插入的索引页不在Buffer Pool中时使用。
- Redo Log:主要用于恢复提交后的物理数据页,确保数据的一致性和持久性
Reference
- https://cloud.tencent.com/developer/article/2398501
- https://www.cnblogs.com/booksea/p/17380938.html
- https://juejin.cn/post/6953442154249191454