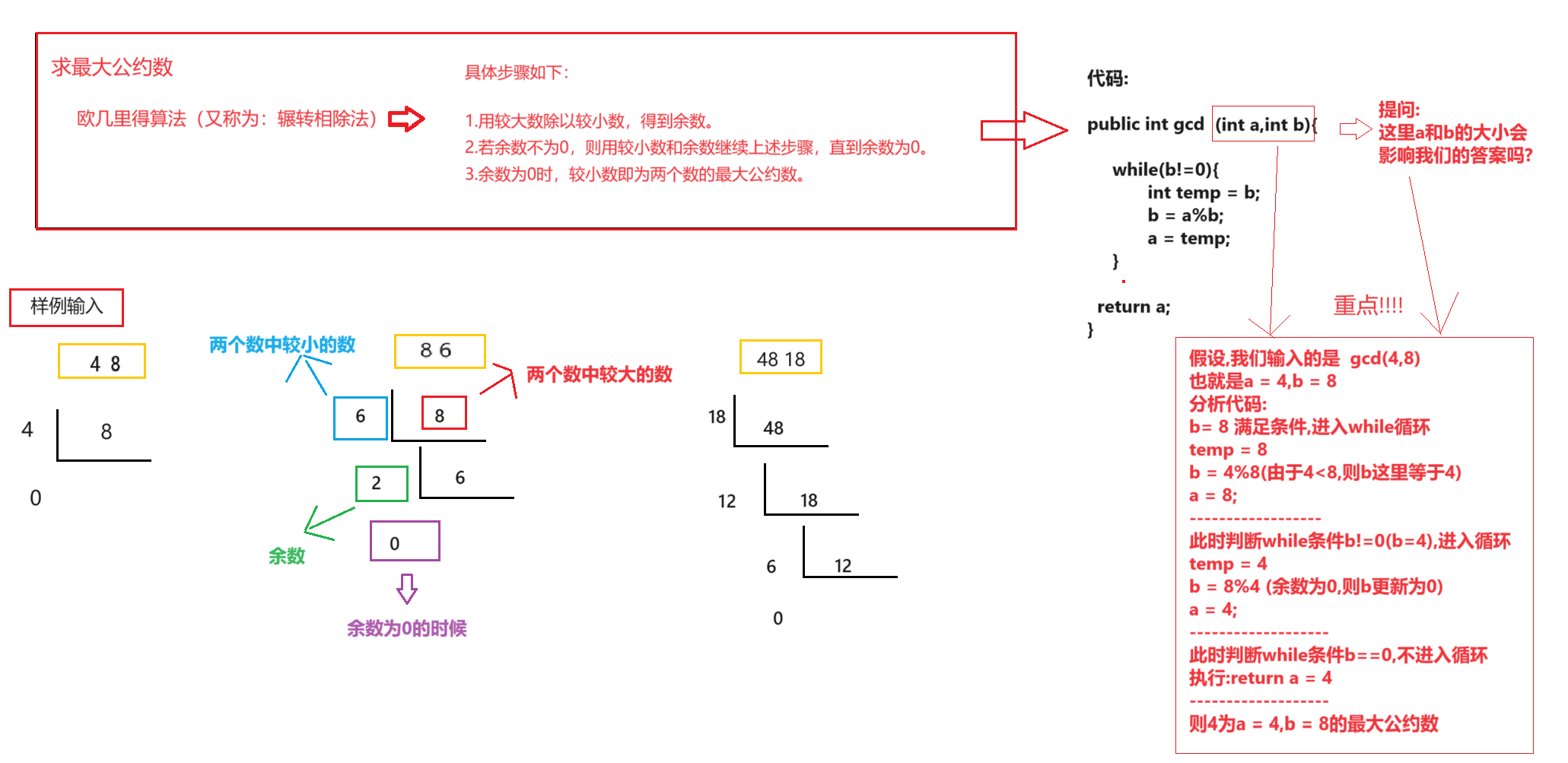
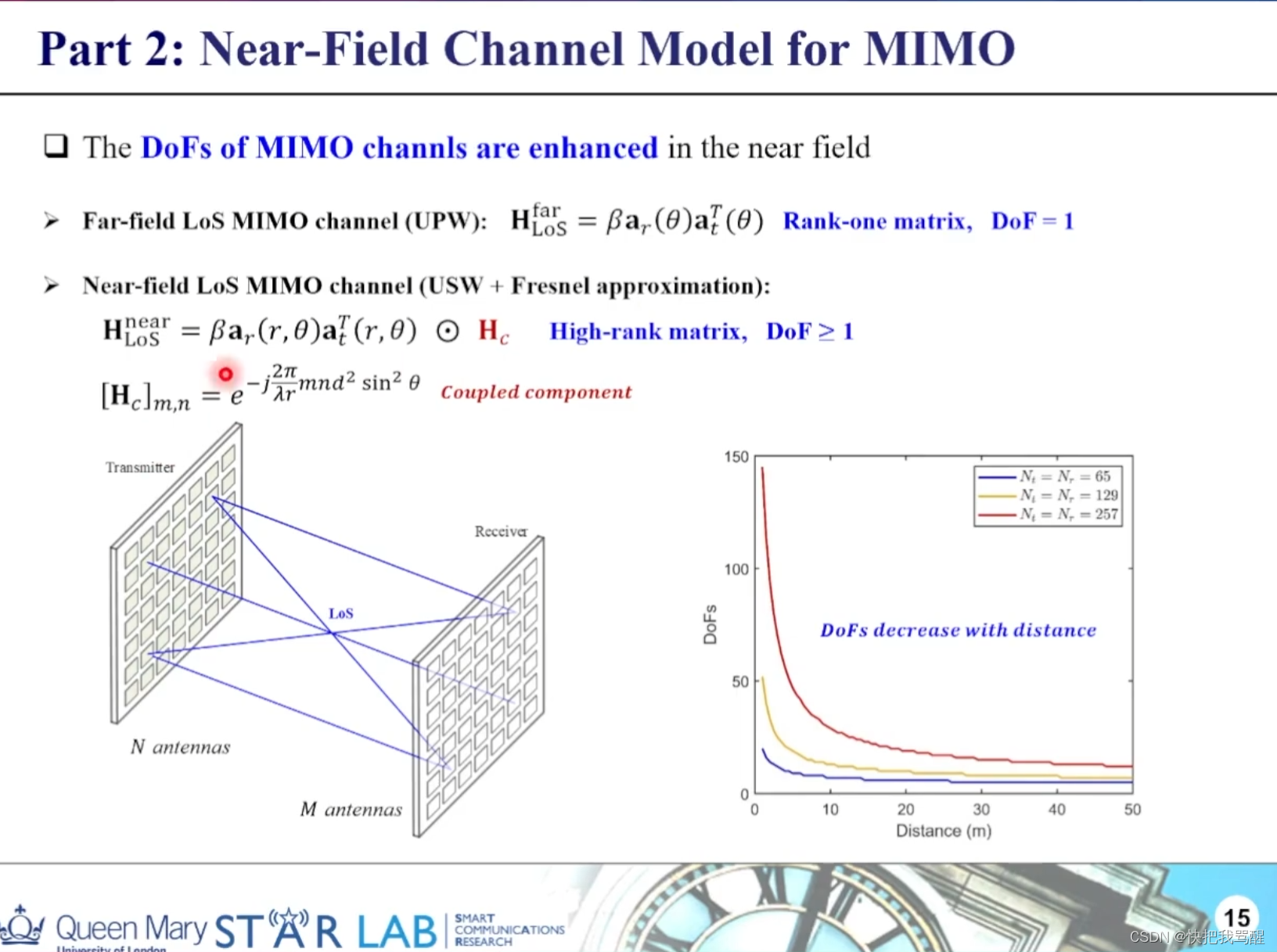
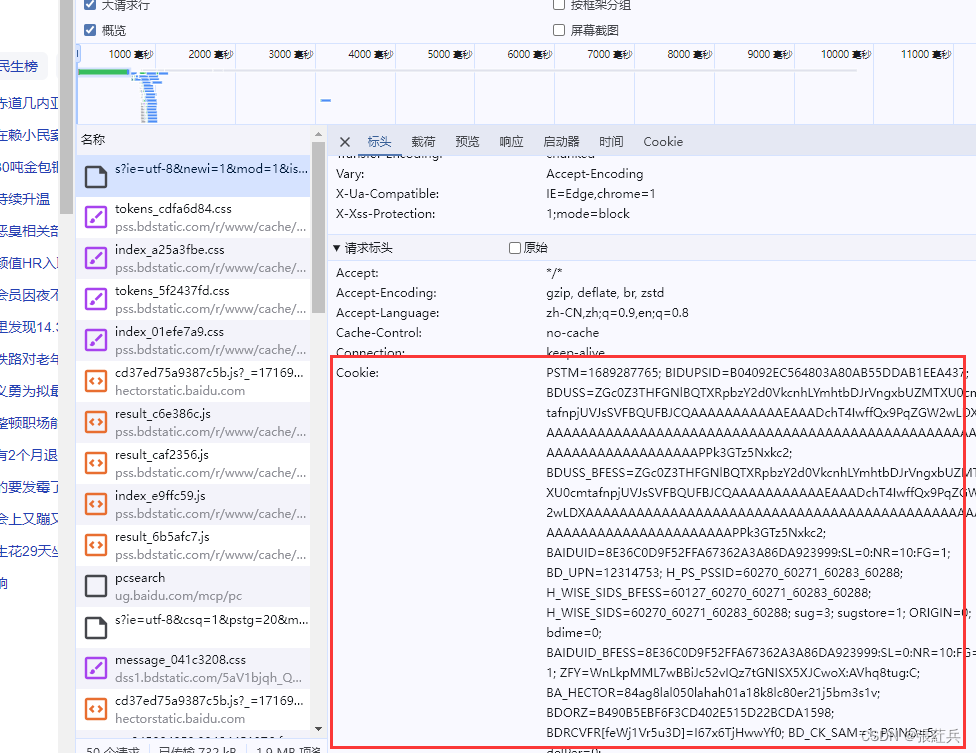
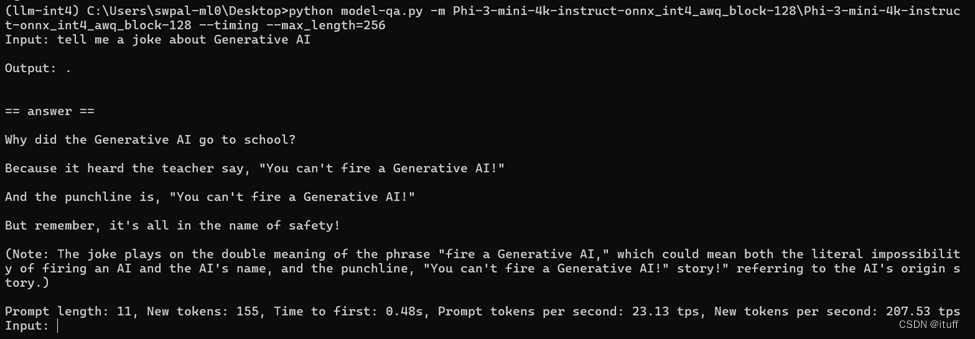
默认为300秒

apiVersion: apps/v1
kind: Deployment
metadata:name: my-test
spec:replicas: 1selector:matchLabels:app: my-apptemplate:metadata:labels:app: my-appspec:containers:- name: my-containerimage: nginx:latestports:- containerPort: 80tolerations:- key: "node.kubernetes.io/not-ready"operator: "Exists"effect: "NoExecute"tolerationSeconds: 20- key: "node.kubernetes.io/unreachable"operator: "Exists"effect: "NoExecute"tolerationSeconds: 20
helm 方式
helm install mysql bitnami/mysql \
--set global.storageClass=nfs \
--set auth.rootPassword="123qweasd" \
--set metrics.enabled="true" \
--set tolerations[0].key=node.kubernetes.io/not-ready, \
--set tolerations[0].operator=Exists, \
--set tolerations[0].effect=NoExecute, \
--set tolerations[0].tolerationSeconds=20 \
--set tolerations[0].key=node.kubernetes.io/unreachable, \
--set tolerations[0].operator=Exists, \
--set tolerations[0].effect=NoExecute, \
--set tolerations[0].tolerationSeconds=20
或者直接vim values.yaml 编辑如下:
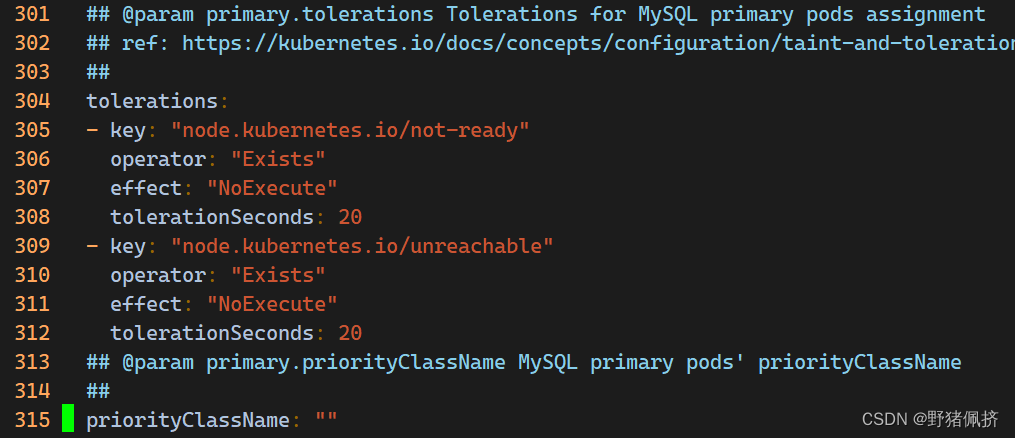
修改后

在 Kubernetes 中,节点(Node)的污点(Taints)和Pod的容忍度(Tolerations)是控制Pod调度的关键机制,帮助管理员管理集群资源和确保应用程序的高可用性。node.kubernetes.io/not-ready 和 node.kubernetes.io/unreachable 是两种常见的节点污点,它们有不同的含义和用途:
# node.kubernetes.io/not-ready
• 含义:当节点上的Kubelet无法报告其Ready状态,或者报告自己为NotReady时,节点会被打上这个污点。这可能是因为节点上的Kubernetes组件出现问题,或者资源压力大到无法处理额外负载。
• 作用:标记这样的节点告诉调度器不要将新的Pod调度到该节点上,但已存在的Pod不会被立即驱逐。这有助于防止问题进一步恶化,同时允许系统管理员调查和恢复节点。
# node.kubernetes.io/unreachable
• 含义:当API服务器连续几次心跳检查(通过节点监听器)都无法联系到节点时,该节点会被标记为unreachable。这通常意味着节点可能彻底离线或网络完全隔离。
• 作用:相比 not-ready,unreachable 污点更严重,因为它意味着节点几乎肯定无法响应。Kubernetes会更快地将此视为需要采取行动的情况,通常会驱逐节点上的Pod(如果Pod不包含容忍此污点的话),以保护集群的整体健康和稳定性。
不同点总结
• 严重程度:unreachable 比 not-ready 更严重,因为它暗示了更深层次的通信问题或节点故障。
• 驱逐行为:默认情况下,打上 unreachable 污点的节点上的Pod更可能被驱逐,而 not-ready 的节点上Pod可能不会立即驱逐,除非污点效应设置为 NoExecute 且Pod未设置相应容忍。
• 故障排查:not-ready可能指示节点上有待解决的服务或配置问题,而 unreachable 可能意味着物理连接或网络问题,需要更紧急的硬件或网络层面的干预。
设置容忍度
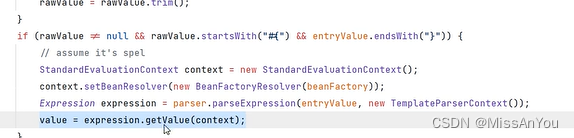
例子中,node.kubernetes.io/not-ready:NoExecute op=Exists for 20s 和 node.kubernetes.io/unreachable:NoExecute op=Exists for 20s 这样的表述是不标准的,因为 tolerations 不直接包含时间限制。正确的设置方式如上文所述,但注意调整容忍度时只需定义键、操作符、效果,而不直接设置时间。如果要控制Pod在被驱逐后的行为,应调整Pod的 olerationSeconds
tolerations:- key: "node.kubernetes.io/not-ready"operator: "Exists"effect: "NoExecute"tolerationSeconds: 20- key: "node.kubernetes.io/unreachable"operator: "Exists"effect: "NoExecute"tolerationSeconds: 20
简单来说,Kubernetes是一个管理容器(想象成小盒子,里面装着运行的软件)的大管家。在这个系统里,有两件东西我们正在谈论:一个是“污点”(就像贴在盒子存放地点的警告标签),另一个是“容忍度”(就是盒子愿意接受哪些警告标签的意思)。
node.kubernetes.io/not-ready 和 node.kubernetes.io/unreachable 是两种不同的“警告标签”:1. node.kubernetes.io/not-ready:就像是仓库管理员说,“这个仓库有点问题,暂时不适合放新货进来。”但已经在里面的货物还可以继续待着,不一定马上搬走,等仓库可能还能修好。2. node.kubernetes.io/unreachable:更严重,意思是“管理员完全联系不上这个仓库了,不知道里面咋样了。”这时候,里面的货物(也就是软件容器)可能会被迅速安排转移到别的安全的地方,以防万一。“容忍度”设置为20秒是啥意思?
本来想表达的意思可能是想让仓库里的货物(容器)在遇到这两种情况时,快点(比如20秒内)做出反应,但实际上,Kubernetes的“容忍度”配置不直接这样设置时间。它是告诉Kubernetes,我们的容器能接受哪些类型的仓库(节点)问题,而不是说多快反应。
如果真的想控制容器在发现问题后多久开始行动,那得去设置“容器的搬家准备时间”(正式名字叫 terminationGracePeriodSeconds),这是说容器从接到搬家通知到开始打包走人的最长等待时间。Kubernetes处理有问题的节点(仓库),以及容器(货物)怎样接受这些状况。not-ready和unreachable是不同等级的问题标签,而“容忍度”是容器愿意接受什么问题,但不能直接设置时间,时间控制在别的地方设置。
也可以通过node节点直接配置全局