牛马我🐴上周又挨锤了, 网络是不稳定的,博学多知的你可能知道,可能不知道。但假如没亲身经历过,知不知道都不深刻,牛马踩了个网络的坑,深刻了,这里分享下,
一个真相
无论是 移动端的4/5G网络,PC端的宽带有线网络 ,还是 云上的网络,都是不稳定的。
多年来,线上服务都是躲在大公司运维基建的后面,或依托于阿里云等服务厂商的网络架构后面,我习惯性的认为云上的网络是相对可靠的,基本上不会出什么大问题。直到这天,
两次事故
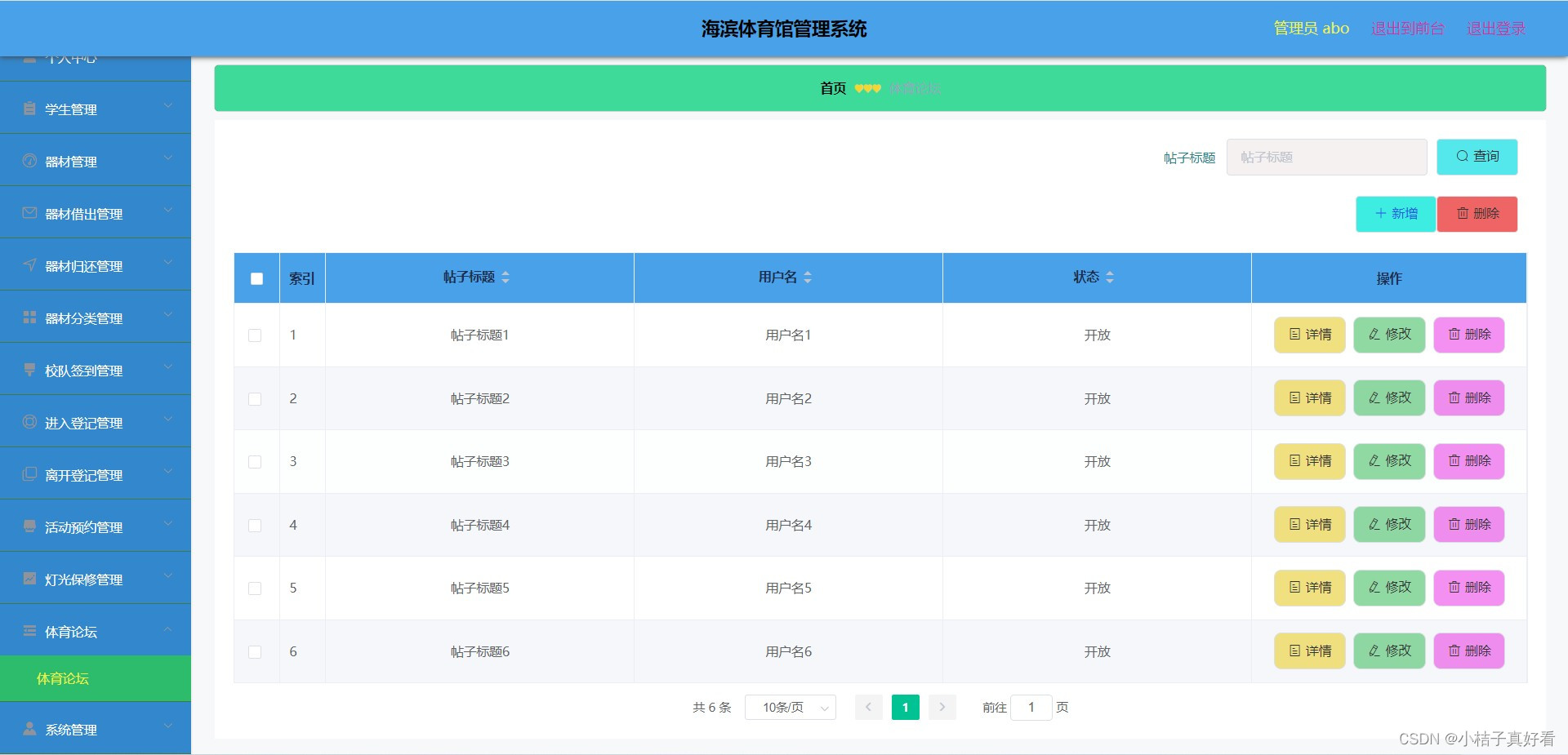
7天内连续2次,类似下面这种,在线ToC业务的 p99屏响突然被拉高,表现为
- 体感上:ToC的在线服务突然有明显延迟,甚至部分超时,
- 指标上:所有服务 p99 都在短时间,都被拉升,类似如图表现,

p99表现,图上是个示意,横轴是时间线,纵轴是延迟时间单位是秒。
p99是网络性能统计中的一个指标,表示99%的请求延迟或响应时间小于或等于该值,用于衡量系统在极端情况下的表现。
开始分析
部署上:这些服务各自独立,独立数据库,独立部署,都部署在某个k8s集群上,如下图。

依次排查,全流程,各指标先快速看一眼,
- k8s 流量入口,无暴涨流量,正常,
- 业务所在k8s集群,Prometheus监控,服务所在环境cpu/mem/io等正常,
- 数据库,无大量慢查询,cpu/mem/io/连接数等正常,
整体指标快速一过,无明显异常,线索中断,思考一下,这个时候需要抓一条具体的返回延时大的请求来看下,看下请求具体耗时情况。按照这个思路一抓,还真抓到了,
APM立功
之前服务基建,服务有接入apm工具,这里选用的是elasticsearch - apm工具,会对请求进行抽样抓取,

看具体请求,类似下图这样,发现请求时间变长,有一大部分耗时在开始的某个函数上,这个函数再细看发现和redis的操作有关,redis去拿数据,有时特别慢,甚至超时。
(备注:为了加速查询,业务里使用redis,有个初始的数据会从redis里拿,拿到以后再进行后续流程)

一下范围就缩小了不少,这下好办了 ,再细查,看业务层和redis的相关日志,发现有报错,
罪魁祸首,网络波动

这一查,发现了p99升高的时候,redis连接有断开报错。 原来 业务层的出口(k8s集群的出口) 与 redis之间的连接串走的是公网,公网网络环境复杂,网络一波动,连接短时间内断开,流量就有异常,p99就会被拉升。
而我们这里 Redis 和 业务层 应该是走内网的,所以很快 ,解决方案,
走内网

切换完内网连接串后,p99正常,没有在出现 接口延时 ,指标上涨等问题 ,这个问题本身看起来解决了。但是事后,在想下,这个真的全怪网络波动吗? 甚至说 换成内网就一定没有网络问题吗?
是时候转变思路了
网络本身复杂,涉及软硬件模块众多,甚至与运营商有关,虽然可以说大部分时间,网络都是可靠的,但是这并不绝对。
所以,开发时的思路就要改变了,开发时要假设, 网络是不稳定的 ,针对这种不稳定,有不稳定的开发模式。
三点建议
- 内网
尽量内网连接,针对这个问题,假设外网99%的时候是正常的,内网就是99.999%的概率是正常的,这里数据也许不准确,但是却说明了 优先使用内网连接的重要性,常识性的东西,没注意踩坑了,才真正深刻了。
- 容错
代码结构优化 , 数据库重连策略 ,连接数,连接间隔,一般默认就OK ,但是有的时候 需要根据你的业务,敏感程度,还是有调整和优化的必要性的,这个要具体问题 具体看。
同时建立好相应的指标,看实际开销和指标 能达多少,做好业务需求和运维成本能接收的均衡即可。
- 大规模
当业务体量到达一定程度时,上面的提到各种优化,其实并不能解决的。就假如说你在北京的运营商都挂了,区域所在的网络整体都down了,而你的业务又是高敏感的,每分钟都垮垮掉钱,就问你怕不怕?这个时候就不得不提异地容灾了。异地容灾有比较成熟的方案 ,网络上也有比较多介绍的文章,这里就先不再展开。
结语
遇到坑,填上坑,通过填坑,反思一下,对一个真相更深刻,那么就今天 ,深刻了各位 哈哈哈哈哈。最后祝大家端午安康,轻松填坑,快速成长,升职加薪!