一、安装
官网下载地址:EDB: Open-Source, Enterprise Postgres Database Management

双击安装程序进行安装
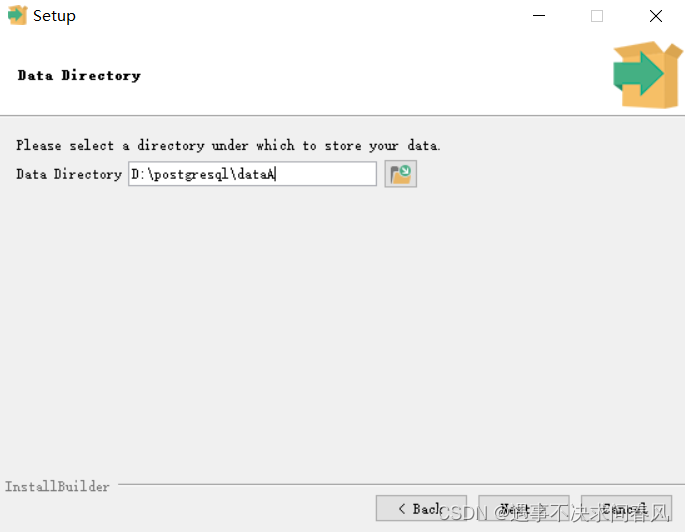
选择端口,默认的即可
验证是否安装成功
在开始菜单里找到PGAdmin 4
打开这个大象头,会在浏览器中打开新的标签页。第一次打开会提示设置密码。这个密码是pgAdmin的密码,以后连接服务器的密码需要保存,则会使用pgAdmin的密码对其加密和解密。
这里输入的密码,并不是安装过程中设置的PostgreSQL超级用户postgres的密码。

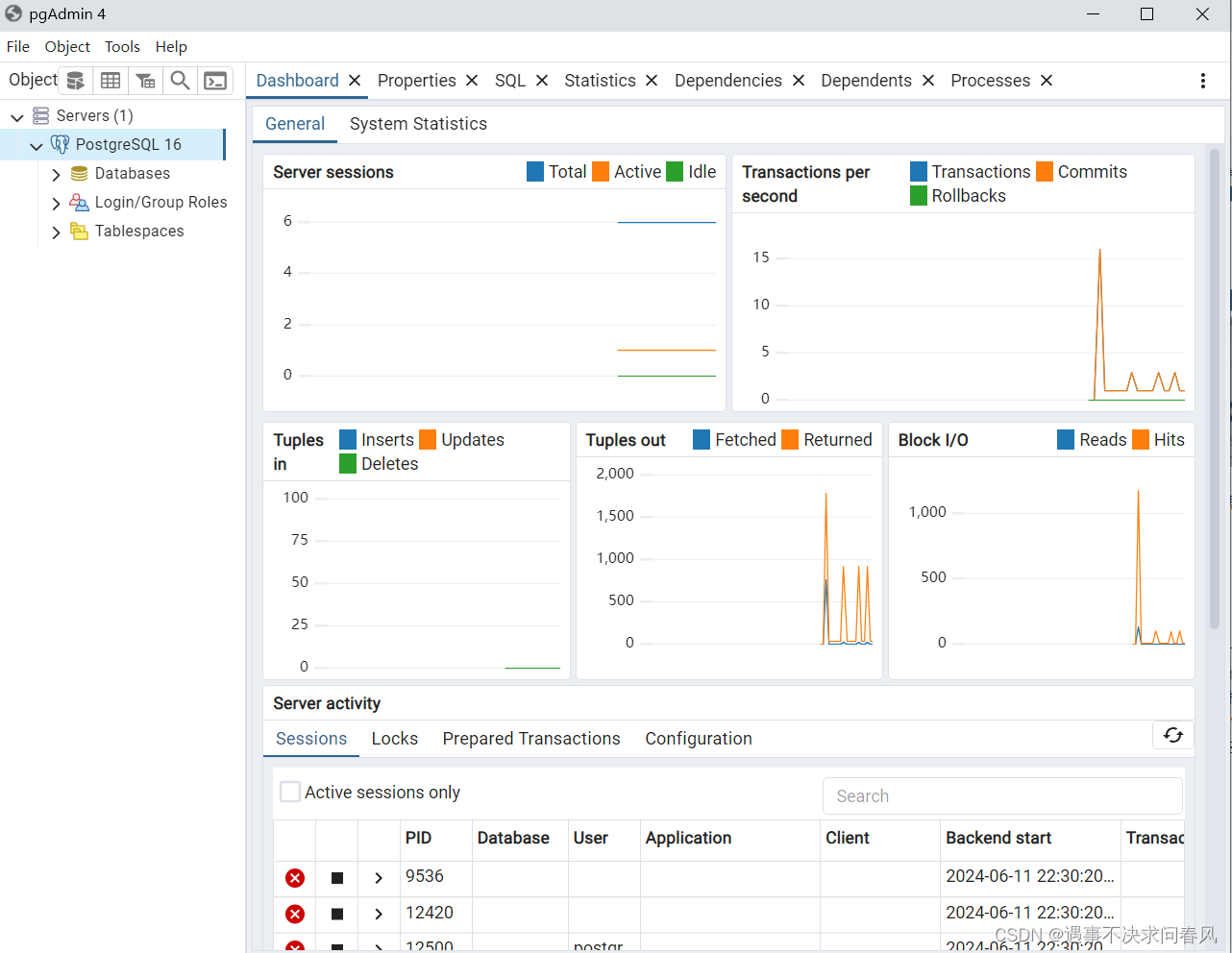
密码正确,连接成功,服务器图标变成大象头,没有红叉。服务器下属的数据库等信息都可以查看,主界面显示具体信息。这时候pg库的安装验证就完事了.
配置
找到pg_hba.conf文件,加入以下内容
host all all 0.0.0.0/0 md5
找到postgresql.conf文件,加入以下内容
wal_keep_segments:用于指定pg_wal目录中保存的过去的wal文件(wal 段)的最小数量,以防备用服务器在进行流复制时需要。
wal_keep_segments = 2
打开命令窗口,输入命令
services.msc
在弹出的窗口中找到以下进程,重新启动

修改环境变量
在命令行输入
sysdm.cpl
在打开的窗口选择高级 -> 环境变量
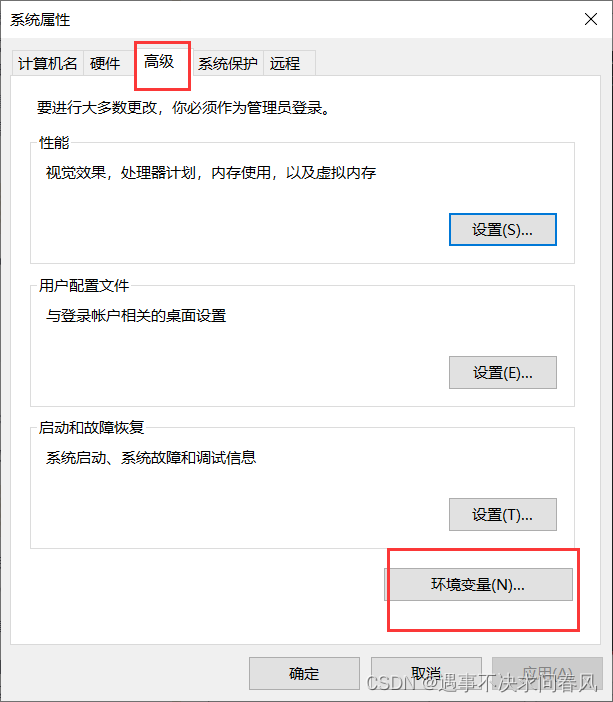
找到path,双击打开
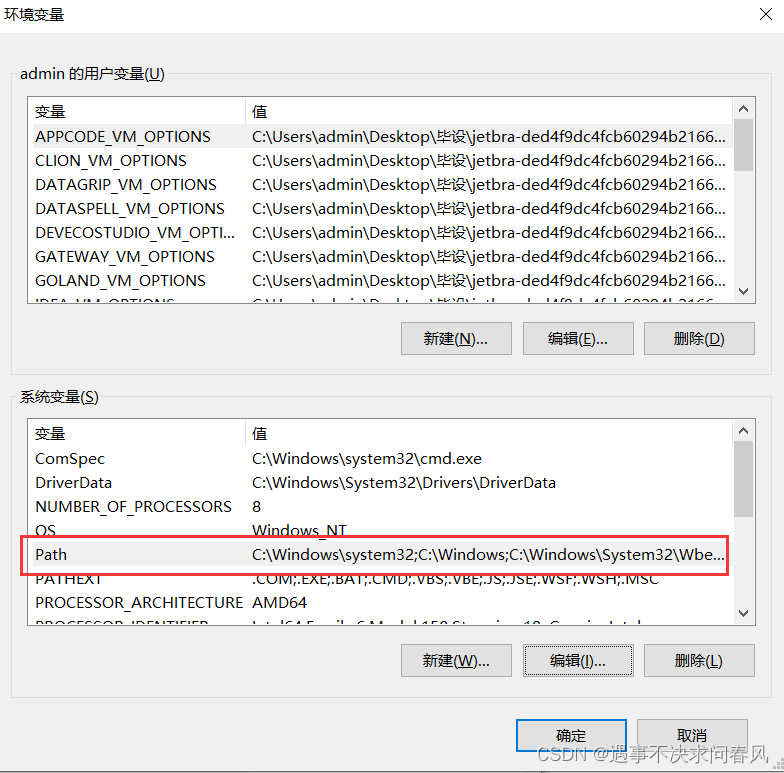

点击确定即可

二、了解
SQL(Structured Query Language)中文全称为”结构化查询语句“,SQL 是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。简单理解就是对我们数据库和数据库中的表进行”增删改查“操作的编程语言。虽然 SQL 是一门标准的计算机语言,但由于数据库类型繁多,存在着多种不同版本的 SQL 语言。为了与 ANSI 标准相兼容,它们必须以相似的方式共同地来支持一些主要的命令(比如 SELECT、UPDATE、DELETE、INSERT、WHERE 等等),下列为 postgresql 数据库操作示例。
按照其功能,主要分为以下几种类型:
DQL(Data QueryLanguage):数据查询语句。SELECT。
DML(Data Manipulation Language):数据操纵语句。INSERT,UPDATE,DELETE,MERGE,CALL,EXPLAIN PLAN,LOCK TABLE。
DDL(Data Definition Languages):数据库定义语句。CREATE,ALTER,DROP,TRUNCATE,COMMENT,RENAME。
TCL(Transaction Control Language):事务控制语句。GRANT,REVOKE
三、基本使用语句
1、创建数据库
create database [数据库名];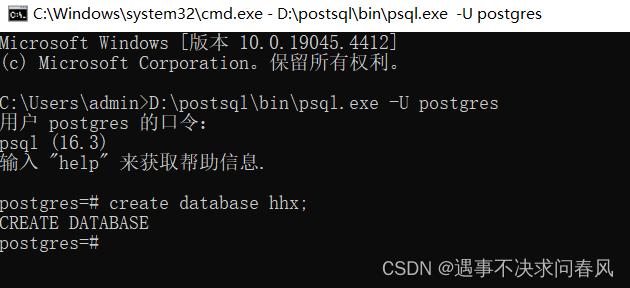
2、连接到创建的数据库
D:\postsql\bin\psql.exe -U postgres -d hhx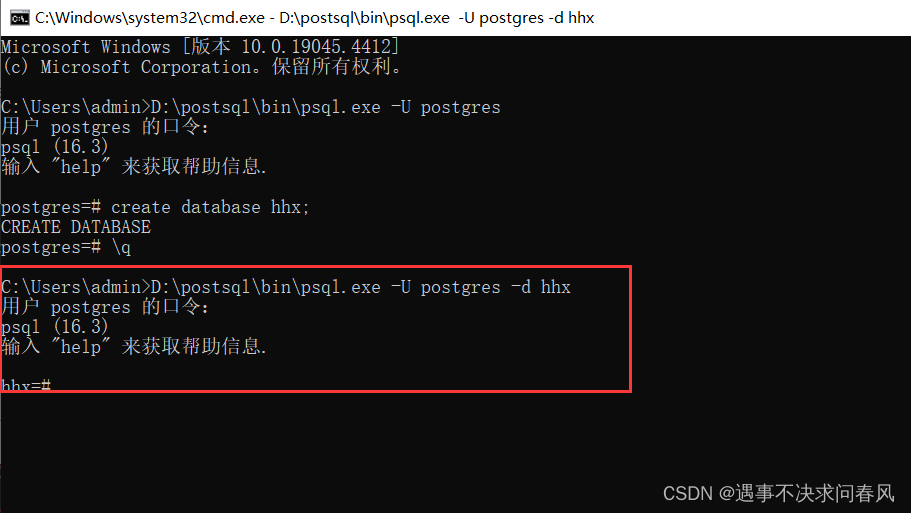
3、退出数据库
\q

4、使用 \l 查看已经存在的数据库
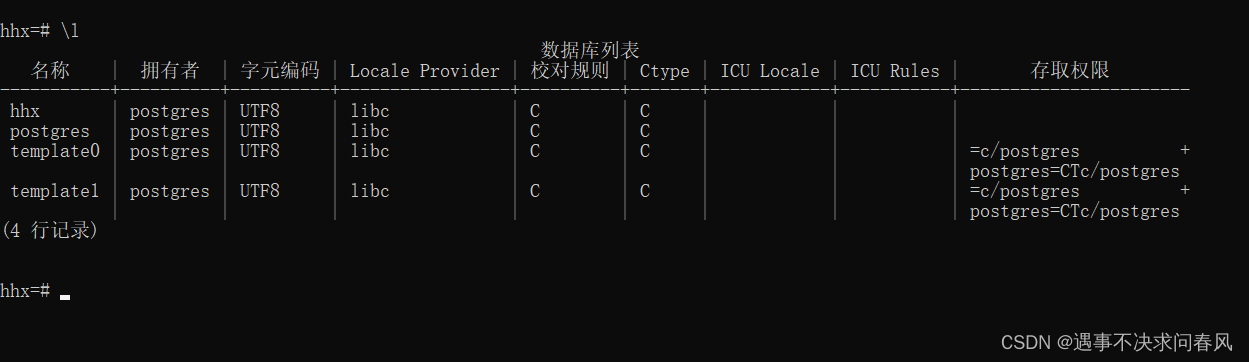
5、使用 \c + 数据库名进入数据库
6、删除数据库
DROP DATABASE [ IF EXISTS ] name
- IF EXISTS:如果数据库不存在则发出提示信息,而不是错误信息。
- name:要删除的数据库的名称。
7、创建表格
CREATE TABLE 是一个关键词,用于告诉数据库系统将创建一个数据表。
实例:
创建了一个表,表名为 COMPANY 表格,主键为 ID,NOT NULL 表示字段不允许包含 NULL 值:
CREATE TABLE COMPANY(ID INT PRIMARY KEY NOT NULL,NAME TEXT NOT NULL,AGE INT NOT NULL,ADDRESS CHAR(50),SALARY REAL
);8、\d 查看表格

9、\d + 表格名,查看表格信息

10、删除表格
//删除表格
drop table tablename;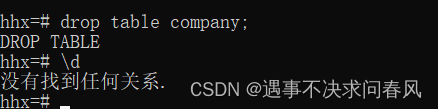
11、模式(SCHEMA)
PostgreSQL 模式(SCHEMA)可以看着是一个表的集合。
一个模式可以包含视图、索引、数据类型、函数和操作符等。
相同的对象名称可以被用于不同的模式中而不会出现冲突,例如 schema1 和 myschema 都可以包含名为 mytable 的表。
使用模式的优势:
允许多个用户使用一个数据库并且不会互相干扰。
将数据库对象组织成逻辑组以便更容易管理。
第三方应用的对象可以放在独立的模式中,这样它们就不会与其他对象的名称发生冲突。
语法:
CREATE SCHEMA myschema ( ... );上述语句将创建一个名为 myschema 的模式。
模式通常用于组织和隔离数据库对象,防止对象名称冲突。
实例:
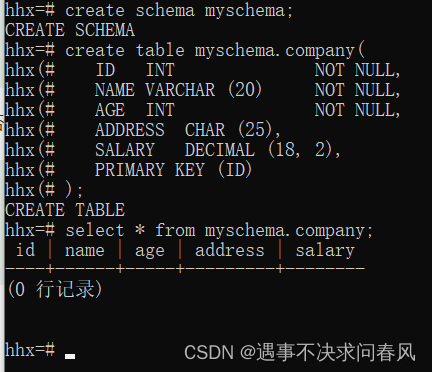
创建模式 myschema,根据该模式再创建一个表格
//创建模式
create schema myschema;//创建表格
create table myschema.company(ID INT NOT NULL,NAME VARCHAR (20) NOT NULL,AGE INT NOT NULL,ADDRESS CHAR (25),SALARY DECIMAL (18, 2),PRIMARY KEY (ID)
);查看结果:
12、删除模式
//删除一个为空的模式(其中的对象已经删除)
DROP SCHEMA myschema;//删除一个模式以及其中包含的所有对象
DROP SCHEMA myschema CASCADE;
13 、插入记录
格式:
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN)
VALUES (value1, value2, value3,...valueN);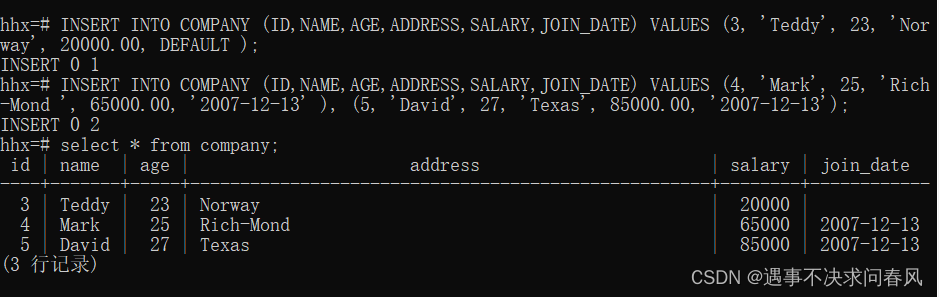
14、查询表格中的数据
select * from tablename;15、查找select
//读取表中的某段数据
SELECT column1, column2,...columnN FROM table_name;//读取表中的所有数据
select * from tablename;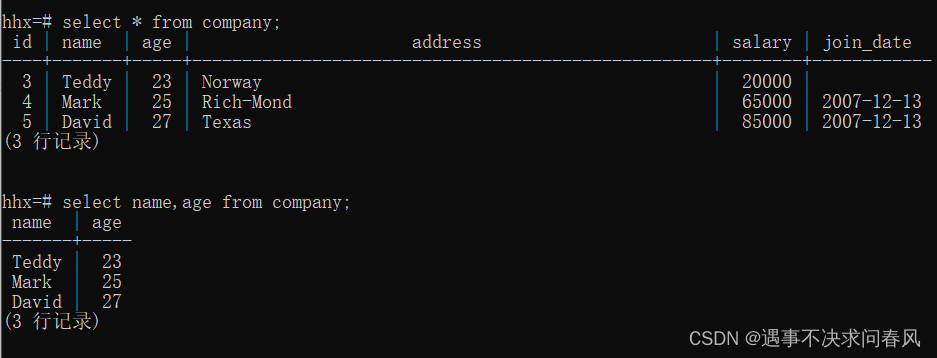
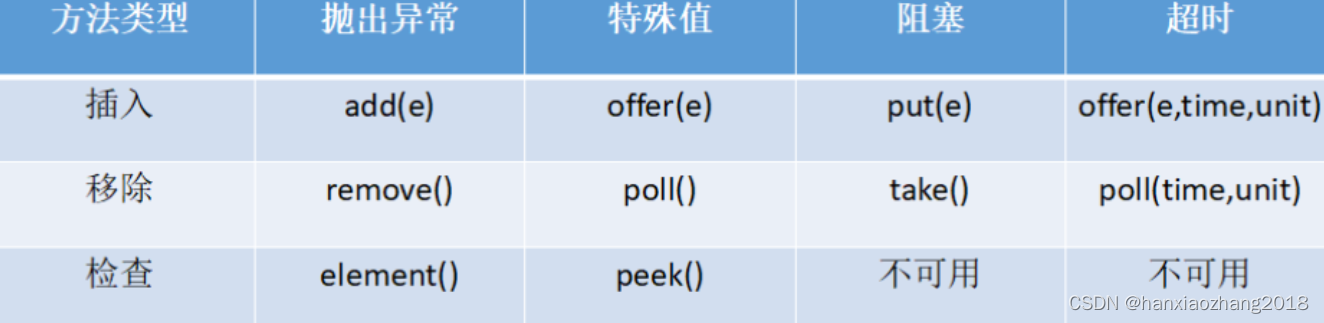
16、运算符
算术运算符
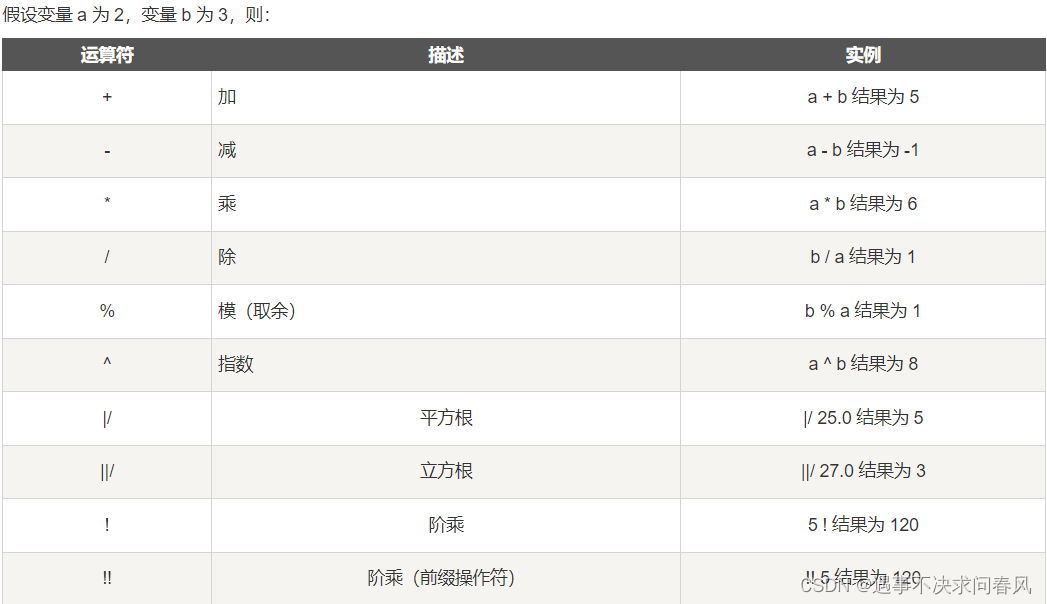
比较运算符
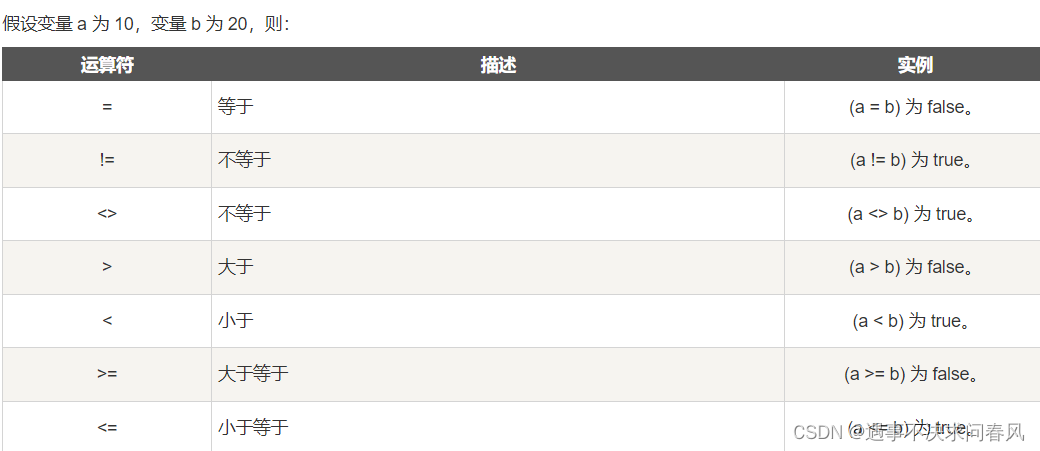
逻辑运算符

位运算符
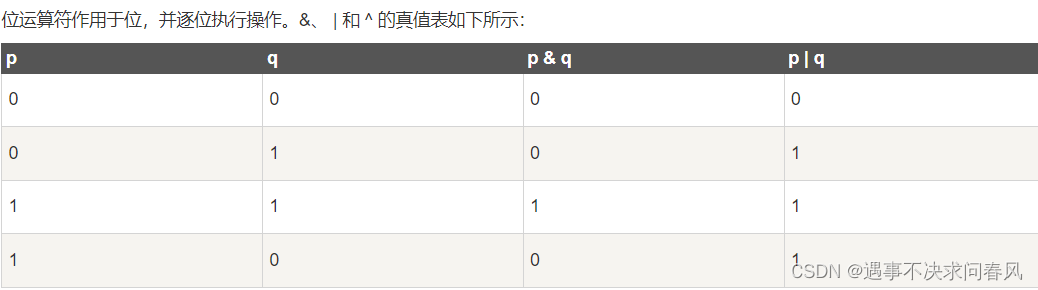
17、WHERE子句
作用是过滤数据
SELECT column1, column2, columnN
FROM table_name
WHERE [condition1]AND
找出符合多个条件的数据
select * from tablename where 条件1 and 条件2;OR
找出满足多个条件中某一个条件的语句
select * from tablename where 条件1 or 条件2;NOT NULL
找出某字段不为空的数据
select * from tablename where 字段 is not null;LIKE
模糊查找
//查找name字段中以h开头的数据 select * from tablename where name like 'h%';IN
找出该字段位于某范围的数据
//找出年龄为25或27的数据 select * from tablename where age in (25,27);NOT IN
用法与IN相似
//找出年纪不为25或27的数据 select * from tablename where age not in (25,27);BETWEEN
//找出年纪在25-27之间的数据 select * from tablename where age between 25 and 27;
18、update更新数据
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];19、删除数据
DELETE FROM table_name WHERE [condition];20、LIMIT子句
limit 子句用于限制 SELECT 语句中查询的数据的数量。
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows] OFFSET [row num]21、ORDER BY 语句
ORDER BY 用于对一列或者多列数据进行升序(ASC)或者降序(DESC)排列。
//年龄升序排列
SELECT * FROM COMPANY ORDER BY AGE ASC;22、ORDER BY 语句
GROUP BY 语句和 SELECT 语句一起使用,用来对相同的数据进行分组。



![[CAN] 创建解析CAN报文DBC文件教程](https://img-blog.csdnimg.cn/direct/4e79b98c4b3d4a92a123b481a4a6d698.png#pic_center)