基于协同过滤算法的电影推荐
电影推荐系统使用了基于**协同过滤(Collaborative Filtering)的算法来生成推荐。具体来说,使用了基于用户的协同过滤(User-Based Collaborative Filtering)**算法,步骤如下:
- 数据预处理:将用户对电影的评分数据读入内存,形成一个用户-电影评分矩阵。
- 相似度计算:使用余弦相似度计算目标用户与其他用户之间的相似度。
- 评分预测:根据相似度和其他用户的评分,对目标用户未评分的电影进行评分预测。
- 生成推荐:选取评分预测值最高的前N部电影作为推荐结果。
以下是详细的代码及其解释:
package com.sf;import java.util.*;public class MovieRecommendation {// 示例评分矩阵// 行表示用户,列表示电影// 元素值表示用户对电影的评分,0表示未评分static double[][] ratings = {{4, 0, 0, 5, 1, 0, 0},{5, 5, 4, 0, 0, 0, 0},{0, 0, 0, 2, 4, 5, 0},{0, 3, 0, 0, 0, 0, 3}};// 计算两个用户之间的余弦相似度public static double cosineSimilarity(double[] user1, double[] user2) {double dotProduct = 0.0;double normUser1 = 0.0;double normUser2 = 0.0;for (int i = 0; i < user1.length; i++) {dotProduct += user1[i] * user2[i]; // 计算点积normUser1 += Math.pow(user1[i], 2); // 计算用户1的向量模normUser2 += Math.pow(user2[i], 2); // 计算用户2的向量模}return dotProduct / (Math.sqrt(normUser1) * Math.sqrt(normUser2)); // 返回余弦相似度}// 为特定用户生成电影推荐public static List<Integer> recommendMovies(int userId, int topN) {double[] userRatings = ratings[userId]; // 获取目标用户的评分数据double[] similarityScores = new double[ratings.length]; // 用于存储相似度得分// 计算目标用户与其他所有用户的相似度得分for (int i = 0; i < ratings.length; i++) {if (i != userId) {similarityScores[i] = cosineSimilarity(userRatings, ratings[i]);}}// 计算每部电影的加权得分double[] weightedScores = new double[ratings[0].length];for (int i = 0; i < ratings.length; i++) {if (i != userId) {for (int j = 0; j < ratings[i].length; j++) {weightedScores[j] += similarityScores[i] * ratings[i][j]; // 累加加权得分}}}// 创建一个优先队列,用于存储按得分排序的电影PriorityQueue<Integer> pq = new PriorityQueue<>((a, b) -> Double.compare(weightedScores[b], weightedScores[a]));// 将未评分的电影加入优先队列for (int i = 0; i < userRatings.length; i++) {if (userRatings[i] == 0) {pq.offer(i);}}// 获取前N部推荐电影List<Integer> recommendedMovies = new ArrayList<>();for (int i = 0; i < topN && !pq.isEmpty(); i++) {recommendedMovies.add(pq.poll());}return recommendedMovies;}public static void main(String[] args) {int userId = 0; // 假设我们为用户ID 0 生成推荐int topN = 3; // 推荐前3部电影List<Integer> recommendations = recommendMovies(userId, topN);// 输出推荐结果System.out.println("推荐给用户 " + userId + " 的电影ID是:" + recommendations);}
}
详细解释
-
数据预处理:代码中的
ratings矩阵是用户对电影的评分数据。行表示不同的用户,列表示不同的电影,元素值表示评分,0表示该用户未对该电影评分。 -
余弦相似度计算:
cosineSimilarity方法用于计算两个用户之间的相似度。公式如下: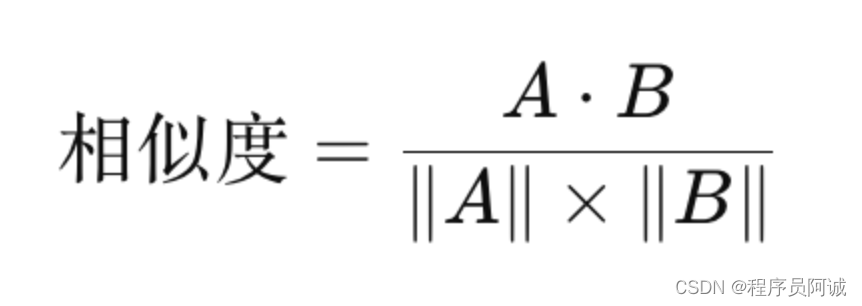
其中,A 和 B 是两个用户的评分向量。
-
评分预测和加权得分:
- 对于目标用户,计算其与其他所有用户的相似度得分。
- 使用这些相似度得分和其他用户的评分,计算每部电影的加权得分。加权得分越高,表明该电影越可能受到目标用户的喜爱。
-
生成推荐:
- 将目标用户未评分的电影按加权得分排序,选取得分最高的前N部电影作为推荐结果。
- 使用优先队列来存储和排序未评分的电影,确保获取得分最高的电影。
通过以上步骤,推荐系统可以为目标用户生成个性化的电影推荐列表。