为促进最新研究成果的传播与交流,CCF语音对话与听觉专委在专委会微信公众号启动论文导读栏目,定期分享最新语音、对话与听觉相关研究方向论文。本期是2024年导读栏目的第1期,也是INTERSPEECH 2024专题第一部分,共遴选了7篇论文,覆盖声学场景分类、语音自监督表征、语音编辑、频带拓展、音频生成、伪造语音检测等研究方向。
此次INTERSPEECH2024专题导读论文仍在持续征集中,欢迎踊跃投稿,投稿方式请参见文末指南。

1- Low-Complexity Acoustic Scene Classification Using Parallel Attention Convolution Network
【论文作者】李艳雄,谭嘉昕,陈国庆,李佳龙,司永洁,贺前华
【论文单位】华南理工大学
【作者邮箱】
eeyxli@scut.edu.cn; tanjiaxin02@126.com
【论文亮点】
该论文提出基于并行注意力卷积网络(Parallel Attention Convolution Network, PACN)的低复杂度声场景分类方法。PACN能够有效提取音频中的全局上下文信息(Global Contextual Information, GCI)和局部上下文信息(Local Contextual Information, LCI)。另外,该论文还引入知识蒸馏、数据增广和自适应残差归一化(Adaptive Residual Normalization, ARN)等技术,从而进一步提升论文方法的声场景分类准确率和降低论文方法的复杂度。
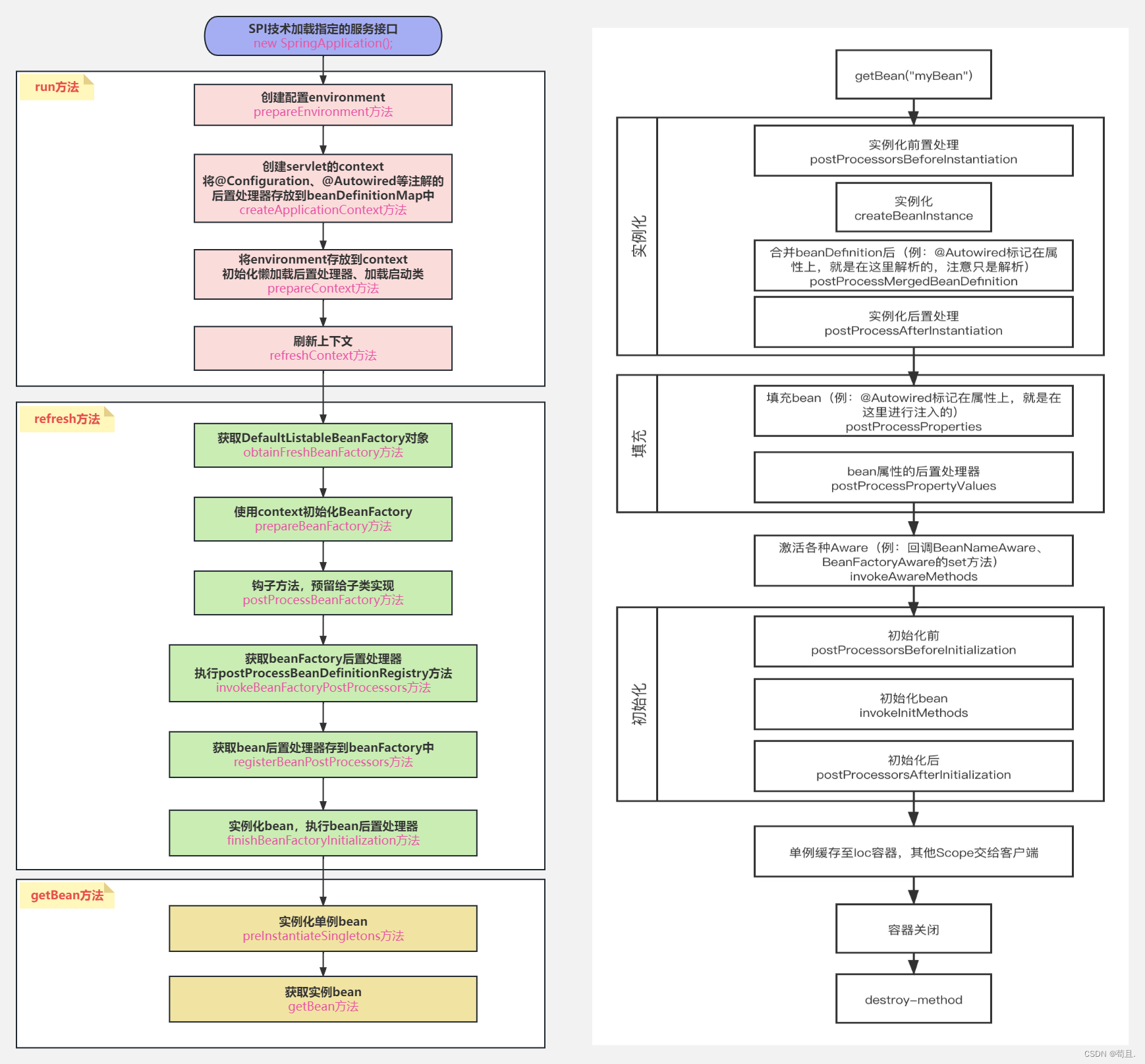
【论文简介】声场景分类是音频和声学信号处理领域的一个重要研究方向。其目标是将每个音频片段判决为预定义的声场景类别。卷积神经网络及其变体能有效提取局部上下文信息,但它不能有效提取全局上下文信息。上述两种信息具有互补性。该论文设计一个并行注意力卷积网络,采用两个并行的网络分支分别提取局部与全局的上下文信息。图1.1是并行注意力卷积网络框架,包括预处理、LCI提取、GCI提取块和融合模块。
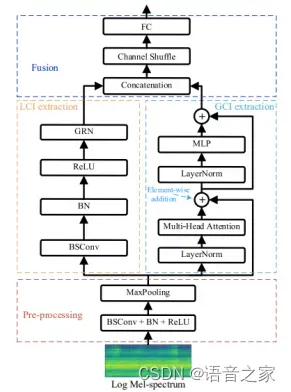
图1.1 并行注意力卷积网络的框架
预处理模块将对数梅尔谱图进行变换,以便提取GCI和LCI。它包括(Blueprint Separable Convolution, BSConv)、批量归一化(Batch Normalization, BN)、修正线性单元(Rectified Linear Unit, ReLU)和最大池化(MaxPooling)。LCI提取模块包括蓝图可分离卷积、批量归一化、修正线性单元和全局响应归一化(Global Response Normalization, GRN)。GCI提取模块由层归一化(Layer Norm)、多头注意力(Multi-head Attention)、按位相加和多层感知器(Multi-Layer Perceptron, MLP)组成。融合模块用于融合GCI和LCI,包括拼接(Concatenation)、通道混洗(Channel Shuffle)和全连接层(Fully-Connected Layer)。
此外,该论文还采用了知识蒸馏、数据增广和自适应残差归一化等技术,进一步提高声场景分类性能。实验结果表明,论文方法在DCASE 2023挑战赛的开发数据集上的准确率为56.10%,参数量为5.21KB,乘法累加操作为1.44百万次,整体优于对比方法的性能。在训练不可见设备录制的音频片段上进行测试,论文方法也获得了更高的准确率52.74%。显著性检验的结果表明,不同方法的准确率存在不同的统计显著性差异。
【论文链接】
https://arxiv.org/abs/2406.08119
【代码链接】
https://github.com/Jessytan/Low-complexity-ASC
2-Fully Few-Shot Class-Incremental Audio Classification Using Expandable D
【论文作者】司永洁,李艳雄,李佳龙,谭嘉昕,贺前华
【论文单位】华南理工大学
【作者邮箱】
eeyongjiesi@mail.scut.edu.cn; eeyxli@scut.edu.cn
【论文亮点】该论文探讨一个新的音频分类问题:完全小样本类增量音频分类(Fully Few-shot Class-incremental Audio Classification, FFCAC)。该论文提出基于可扩展双表征提取器(Expandable Dual-embedding Extractor, EDE)的FFCAC方法。EDE由预训练的音频频谱图转换器(Audio Spectrogram Transformer, AST)和微调的AST拼接而成,可在增量学习过程中持续学习新类,同时提取区分性表征和泛化性表征从而提高模型分类性能。
【论文简介】
1. 方法框架
如图2.1所示,FFCAC包括基础环节和增量环节,所有环节都只有少量训练样本可用。基础环节包括:微调预训练的AST、构建EDE和基础分类器,并保存当前所有类表征的统计信息(均值与方差矢量)。在每个增量环节,使用新类样本和旧类统计信息生成旧类表征,扩展并更新EDE,再用更新后的EDE生成原型并更新分类器。
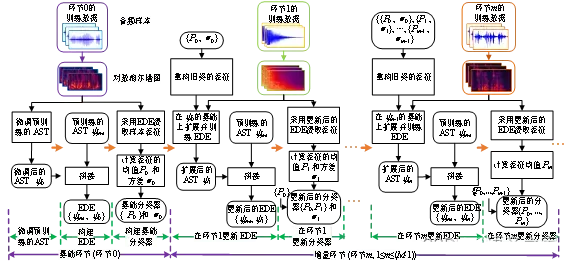
图2.1 论文方法框架。
2. 可扩展双重表征提取器
如图2.2所示,可扩展双表征提取器由预训练的AST和微调的AST拼接而成,分别用于提取泛化性表征和区分性表征。每个音频样本的对数梅尔谱图被分割成多个图像块,并在添加可训练的位置表征后输入转换器的编码器。编码器包括多个转换模块,各模块由多个自注意力层和全连接层组成。在增量学习过程中,通过扩展最后一层变换模块实现新类区分性表征的持续学习。

图2.2 可扩展双表征提取器框架。
3. 实验结果
采用三个公开数据集LS-100、NSynth-100和FSC-89作为实验数据,评测不同方法的性能。采用平均精度(Average Accuracy, AA)作为评价指标。论文方法在LS-100、NSynth-100和FSC-89三个数据集上的AA值分别为61.85%、65.40%和37.36%,高于七个对比方法的AA值。此外,该论文还进行了消融分析和显著性检验比较。
4. 结论
在相同实验条件下,论文方法在平均精度方面优于对比方法。可扩展双表征提取器可以在FFCAC任务中提高模型对旧类的稳定性和对新类的可塑性,获得更优的音频分类性能。但是,AST参数量较大。随着EDE的扩展,它的参数量将不断增加。未来的工作将考虑轻量级的FFCAC方法。
【论文链接】
https://arxiv.org/abs/2406.08122
【代码链接】
https://github.com/YongjieSi/EDE
3-Emotion-Aware Speech Self-Supervised Representation Learning with Intensity Knowledge
【论文作者】刘瑞,马泽宁
【论文单位】内蒙古大学
【作者邮箱】
liurui_imu@163.com; codening_2022@163.com
【论文亮点】现有的自监督模型往往忽略了情绪相关先验信息的引入,从而忽略了通过语音中的情绪先验知识来增强情绪任务理解的潜在效果。本文提出一种具有强度知识的情绪感知语音表示学习。我们利用已建立的语音情绪理解模型来提取帧级的情绪强度,并且提出一种新颖的情绪掩码策略(EMS),将情绪强度纳入掩码过程,从而得到更能表现出情感的高级表征。
【论文简介】基于自监督学习的(SSL)预训练模型最初用于自然语言处理(NLP),现在已扩展到语音领域。事实证明,将这些模型作为特征提取器获得的表征是非常有效的,将得到的表征应用到到语言和语音处理下游任务上时效果极佳。虽然自监督模型已经取得了成功,但现有方法往往忽略了在预训练过程中纳入与情感相关的信息。情感在人类交流中起着至关重要的作用,利用情感感知表征可以显著提高情感相关任务(如 SER 任务)的性能。为了应对上述挑战,我们提出了一种基于强度知识的情感感知语音表征学习方法。具体来说,我们首先使用已建立的情感提取模型提取帧级情感强度分数。其次,受在 NLP 文本任务中引入情感的策略启发,我们提出了情感掩蔽策略(EMS)。该方法指示自监督模型在屏蔽过程中识别出情感强度较高的帧。将我们提出的方法应用于Mockingjay和NPC模型,并在 SER 任务中使用提取的高级表征,结果超过了原始模型的性能。这项工作的主要贡献可总结如下:
1. 我们提出了一种新颖的情感感知语音 SSL 表示学习方案。
2. 我们从语音中提取了细粒度的情感强度先验信息,并提出了情感掩蔽策略。我们选择了两个经典的 SSL 模型:Mockingjay和 NPC 作为研究对象。
3. 实验证明,在 SER 任务和其他相关任务中,我们提出的方法所得到的表示优于原始模型。
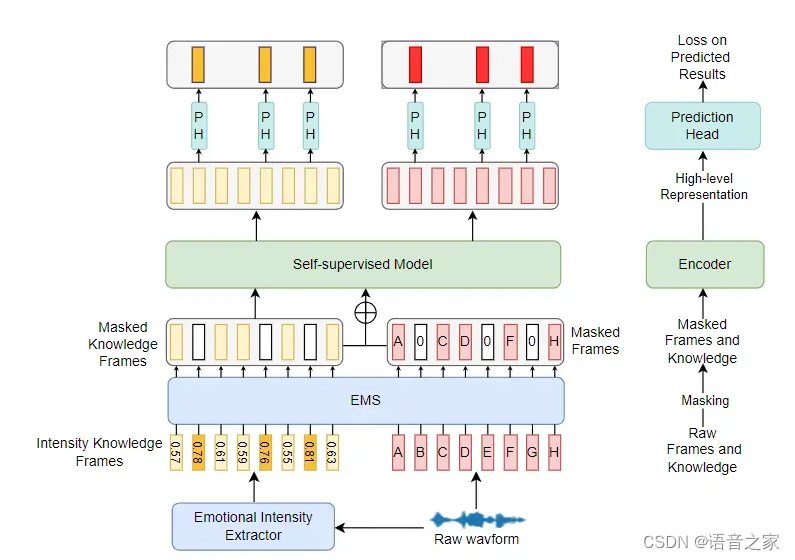
图3.1 模型框架图。
图中的小矩形表示帧级情感强度分数或声学特征,带数字的矩形表示情感强度得分,白色部分表示屏蔽。自监督模型表示改进模型的编码器部分。
【论文链接】
https://arxiv.org/abs/2406.06646
【代码链接】
https://github.com/AI-S2-Lab/EMS
4-FluentEditor: Text-Based Speech Editing by Considering Acoustic and Prosody Consistency
【论文作者】刘瑞1,席嘉甜1,江子越2,李海洲3,4
【论文单位】1内蒙古大学,2浙江大学,3香港中文大学(深圳),4新加坡国立大学
【作者邮箱】
liurui_imu@163.com; x_jiatian@163.com; ziyuejiang@zju.edu.cn; haizhouli@cuhk.edu.cn
【论文亮点】基于文本的语音编辑(Text-based Speech Editing, TSE)技术主要关注于缩减编辑区域内生成的语音片段与参考目标之间的差异,而忽视了其在上下文和原始话语中的局部和全局流畅性。为保持语音的平滑过渡,本文提出了一种流畅性语音编辑模型,称为FluentEditor,通过在TSE训练中考虑流畅性感知的训练准则,分别从声学和韵律两个方面提升编辑边界处的平滑度。
【论文简介】在过去的几年中,许多学者尝试采用文本到语音(Text-to-Speech,TTS)系统来构建基于神经网络的TSE模型。然而,在训练过程中,现有方法只是约束待预测的梅尔频谱与真实值之间的欧几里得距离,以确保TSE的自然性。尽管它们考虑了使用上下文信息来缓解编辑语音的过度平滑问题,但其目标函数并未设计为确保输出语音的流畅性。本文认为,有效的语音流畅性建模需要解决两个挑战:1)声学一致性(Acoustic Consistency):待编辑区域与其邻近区域之间拼接的平滑性应接近真实拼接点;2)韵律一致性(Prosody Consistency):合成音频在待编辑区域的韵律风格需与原始话语的整体韵律风格一致。为了解决上述问题,本文提出了一种新颖的流畅性语音编辑方案,称为FluentEditor,通过引入声学和韵律一致性训练准则,以实现自然且流畅的语音编辑。具体来说,1)为实现声学一致性,设计了声学一致性损失,用于计算边界处的方差是否接近真实拼接点处的方差;2)为实现韵律一致性,引入韵律一致性损失,使待编辑区域合成音频的高层韵律特征接近原始话语的高层韵律特征。高级的韵律特征由预训练的基于GST的韵律提取器提取。在VCTK数据集上的主观和客观结果表明,FluentEditor的声学和韵律一致性显著优于先进的TSE基线模型,同时能够确保高度流畅的真实语音。
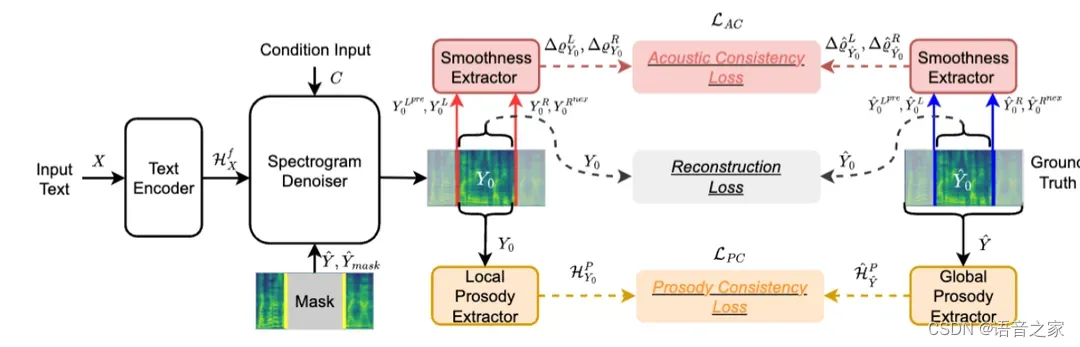
图4.1 模型框架图。FluentEditor采用基于掩码预测的扩散网络作为骨干网络,包括一个文本编码器和一个谱图去噪器。谱图去噪器采用去噪扩散概率模型(Denoising Diffusion Probabilistic Model, DDPM),通过固定长度为P(·)的马尔可夫链的反向过程逐步去噪一个正态分布变量来学习数据分布。
【论文链接】
https://arxiv.org/abs/2309.11725
【代码链接】
https://github.com/AI-S2-Lab/FluentEditor
5- Multi-Stage Speech Bandwidth Extension with Flexible Sampling Rate Control
【论文作者】鲁叶欣,艾杨,盛峥彦,凌震华
【论文单位】中国科学技术大学
【作者邮箱】
yxlu0102@mail.ustc.edu.cn; yangai@ustc.edu.cn; zysheng@mail.ustc.edu.cn; zhling@ustc.edu.cn
【论文亮点】绝大多数的语音频带扩展模型都在固定的源和目标采样率下运行,考虑到在不同的实际应用场景中对采样率的要求不同,对每一组采样率对都单独建立一个语音频带扩展模型会带来大量的内存占用需求,并且限制了模型使用的灵活性。因此,本文提出了一种多阶段的语音频带扩展模型MS-BWE,它能够处理一系列源-目标采样率对,从而实现频带之间的灵活扩展。实验结果表明所提出的MS-BWE在扩展语音质量上与SOTA的语音频带扩展方法相当。在生成效率方面,MS-BWE的单阶段生成在现有的语音频带扩展方法基础上实现了至少四倍的加速。
【论文简介】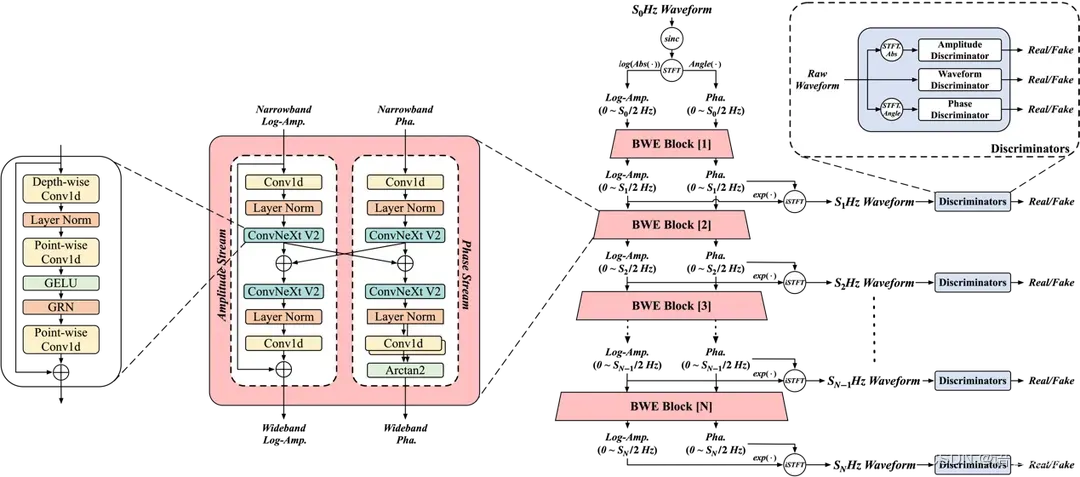
图5.1 MS-BWE模型框架图。
本文提出的 MS-BWE 由多个频带扩展 (Bandwidth Extension, BWE) 模块构成,分别负责不同阶段相邻采样率之间的扩展。为了实现更好的频带扩展效果,每个BWE模块被设计成双流结构,通过平行的幅度流和相位流分别进行幅度和相位的扩展。对于窄带语音信号输入,BWE模块首先通过短时傅里叶变换 (Shot-Time Fourier Transform, STFT) 提取窄带幅度谱和相位谱。幅度流通过预测高频幅度并与窄带幅度相加得到扩展后的幅度谱,而考虑到相位的卷绕特性,相位流通过相位的平行估计架构和Arctan2函数直接预测宽带相位,最后扩展后的幅度相位谱通过逆短时傅里叶变换得到扩展后的语音信号。对于每个BWE模块的输出幅度和相位谱,MS-BWE定义了幅度谱损失、相位谱抗卷绕损失以及复数谱损失,同时对于输出的语音波形使用波形判别器、幅度判别器以及相位判别器进行生成对抗训练。
由于需要将所有BWE模块级连进行联合训练,为了缩小训练和推断过程的不一致,我们在训练过程中采用了Teacher-Forcing的策略。在训练过程中,除了首个BWE模块,每个BWE模块以一定的概率采样真实的窄带幅度相位谱或者上一个BWE模块输出的幅度相位谱作为输入,采样真实幅度相位谱的概率随着训练的进行不断下降,以帮助模型能够逐渐适应自己内部的输出,从而与推断过程保持一致。
总的来说,MS-BWE使用了一个通用的模型在保证高效率生成的同时实现了不同采样率之间的灵活扩展。通过逐阶段的生成,MS-BWE充分利用了模型参数,具有应用于资源受限场景中的潜力。
【论文链接】
https://arxiv.org/abs/2406.02250
【Demo链接】
https://yxlu-0102.github.io/MS-BWE-demo
6-PPPR: Portable Plug-in Prompt Refiner for Text to Audio Generation
【论文作者】施淑辰,傅睿博,温正棋,陶建华,汪涛,强春雨,陆逸,戚鑫,柳雪飞,刘育坤,李永伟,汪智勇,王小鹏
【论文单位】上海第二工业大学,中国科学院自动化研究所,清华大学,天津大学,中国科学院大学
【作者邮箱】
20221513084@stu.sspu.edu.cn; ruibo.fu@nlpr.ia.ac.cn
【论文亮点】本文提出了一种名为“Portable Plug-in Prompt Refiner (PPPR)”的Text-to-Audio(TTA)前端增强方法。该方法利用大型语言模型(LLM)中丰富的文本描述知识,增强了TTA声学模型的鲁棒性,而无需改变声学训练集。此外,引入了一种模仿人类验证的思维链(CoT),以提高音频描述的准确性,从而在实际应用中提高生成内容的准确性。
【论文简介】TTA任务旨在根据给定的文本描述生成相应的音频,在多媒体制作中扮演着重要角色。然而,现有的TTA数据集中的文本描述缺乏丰富的变化和多样性,导致模型在处理复杂文本时性能下降。
为了解决这一问题,本篇文章提出了Portable Plug-in Prompt Refiner(PPPR)方法。PPPR通过增加训练数据集中文本描述的细粒度多样性来增强声学模型的鲁棒性,并通过提高输入文本描述的准确性来提升TTA模型在实际应用中的准确性。具体而言,为了解决文本描述多样性不足的问题,PPPR使用Llama主动增强原始文本描述,生成具有细粒度多样性的广泛文本描述。为了提高文本描述的准确性,PPPR使用CoT引导Llama逐步规范输入文本描述,例如纠正拼写错误和检查描述的准确性,以获得准确规范的文本描述。

图 6.1 基于 LDM 使用 PPPR 进行音频生成模型的训练和推理过程。
为了验证方法的有效性,文章基于潜在扩散模型构建了一个TTA生成模型。由于LLM增强后的文本描述分布更加复杂,文章选择了LLM Flan-T5作为文本编码器,而未采用基于语言-音频预训练的CLAP的文本编码器。实验结果表明,PPPR方法在Inception Score(IS)上达到了8.72的高分,超越了现有的AudioGen、AudioLDM和Tango等方法,并且在Frechet Distance(FD)和Kullback Leibler(KL)得分上与表现最好的基线模型相近,这表明PPPR能够生成更多样化和高质量的音频。此外,PPPR通过规范化文本描述显著提高了模型在实际应用中生成音频的准确性。
【论文链接】
https://arxiv.org/abs/2406.04683
7-Codecfake: An Initial Dataset for Detecting LLM-Based Deepfake Audio
【论文作者】陆逸*,谢元坤*,傅睿博,温正棋,陶建华,汪智勇,戚鑫,柳雪飞,李永伟,刘育坤,王小鹏,施淑辰(*代表对本工作同等贡献)
【论文单位】中国科学院自动化研究所,中国科学院大学,中国传媒大学,清华大学,上海第二工业大学
【作者邮箱】
luyi22@mails.ucas.ac.cn; xieyuankun@cuc.edu.cn; ruibo.fu@nlpr.ia.ac.cn
【论文亮点】本文提出了一个名为Codecfake的数据集,是首个针对大语言模型(LLM)合成的深度伪造音频进行检测数据集。这个数据集是通过七种代表性的神经编码器方法生成的伪造音频,涵盖了当前主流的LLM音频生成模型。Codecfake数据集包含总计1,058,216个音频样本,其中包括132,277个真实音频样本和925,939个假音频样本。通过该数据集的实验结果表明,使用Codecfake数据集训练的音频Deepfake检测(ADD)模型在检测基于编解码器的Deepfake音频方面表现显著优于基于声码器训练的ADD模型,有效提升了检测准确性和泛化能力。
【论文简介】
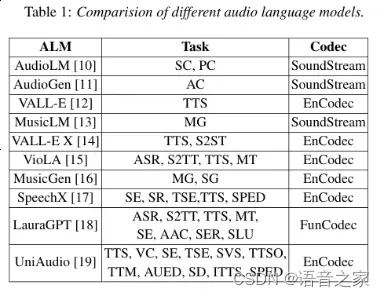
随着大型语言模型(LLM)在音频生成方面的进步,越来越多的Deepfake音频被生成。这些新型的音频生成方法采用了端到端的神经编解码技术,与传统依赖声码器的生成方法不同。这给现有的音频Deepfake检测(ADD)模型带来了挑战,因为它们主要依赖声码器的伪影进行检测。 为了应对这一挑战,我们提出了Codecfake数据集,这是一个专门用于检测基于LLM的Deepfake音频的初始数据集。该数据集包括七种代表性的神经编解码方法,涵盖了当前主流的音频生成技术。通过使用Codecfake数据集,我们希望评估并改进ADD模型在检测基于编解码器生成的Deepfake音频方面的性能。 实验结果表明,基于声码器训练的ADD模型在检测基于编解码器生成的音频时效果不佳,无法有效区分真实音频和伪造音频。相反,使用Codecfake数据集训练的ADD模型在各种测试条件下表现出色,显著降低了平均等错误率(EER),表明其在检测任务中具有更好的泛化能力。总之,Codecfake数据集为检测基于LLM的deepfake音频提供了一个重要工具,帮助研究人员开发更有效的检测方法,从而提升对音频伪造的防护能力。
【论文链接】
https://arxiv.org/abs/2406.08112
论文导读投稿指南
此次专题导读论文为INTERSPEECH 2024已接受论文,且已经在arXiv或其他预印本网站发布。论文导读投稿模版参见附件,要求投稿内容控制在500-800字左右,并附上导读论文的完整引用信息。论文导读投稿请以电子邮件形式提交至tcsdap_ccf@163.com,联系人:张雯、李雅、吴锡欣。
附录:论文导读模版-v2.docx