一:概念
顾名思义集成学习就是用多个其他的算法结合起来使用
对于“其他算法”有同类和同质的区别,同质指的是所用的算法都是同一类型的,比如决策树和神经网络,这种也叫基学习器。反之亦然,但一般使用的是同质的。
而集成学习要做的就是将这些方法结合起来,使得学习器有更好的泛化性能。
1.Bagging方法:
Bagging是利用自助采样生成多个有差异的训练集,训练出一系列个体学习器。根据偏差-方差分解定理,模型预测误差可拆分为偏差、方差和不可约误差三部分。Bagging通过引入随机性降低个体学习器间的相关性,进而降低集成模型的方差,提高整体预测性能。
对训练集进行抽样,将抽样的结果用于训练,并行,独立训练。
抽样是有放回的对原始数据进行均匀抽样,利用每次抽样的数据集训练模型,然后每次抽样会有一个模型,最终的那个模型对每次生成的模型进行投票

Boosting方法:
利用训练集练出模型,根据本次模型的预测结果调整训练集,然后利用调整后的训练集训练下一个模型
二:随机森林
Bagging+决策树=随机森林
将多个决策树结合在一起,每次数据集是随机的有放回的选出,同时随机选出部分特征作为输入,使用该算法被称为随机森林算法,可以看到随机森林算法是以决策树为估计器的Bagging算法。也就是上面写道的同质的算法,这里只用到了决策树来作为其他算法。
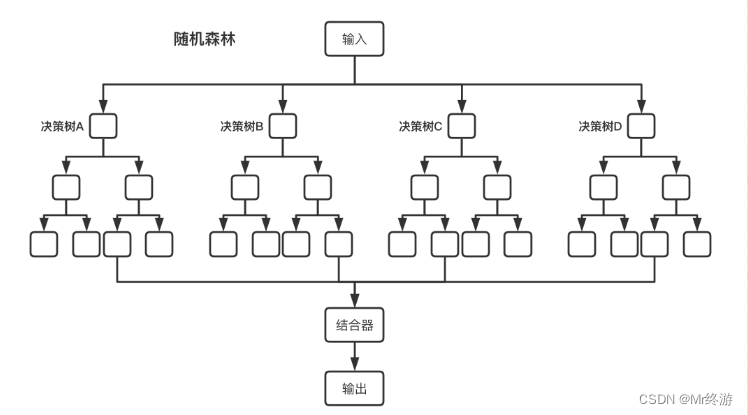
2.算法步骤:
假设有一个数据集T是N行M列(在表格中每一行就是一个特征),如果需要一个大小为K(自己定义的)的随机森林
1.变量随机森林大小K次
2.每一次遍历从数据集T中放回抽样的方式(Bagging)抽取n次形成一个新的训练集D
3.随机选择m(m<M)个特征
4.使用新的训练集D和m个特征,训练出一个完整的决策树
5.循环结束以后就得到一个有K个决策树的随机森林了
3.优缺点
优点:
对于很多种资料,可以产生高准确度的分类器
可以处理大量的输入变量
可以在决定类别时,评估变量的重要性
在建造森林时,可以在内部对于一般化后的误差产生不偏差的估计
包含一个好方法可以估计丢失的资料,并且如果有很大一部分的资料丢失,仍可以维持准确度
对于不平衡的分类资料集来说,可以平衡误差
可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类,也可侦测偏离者和观看资料
学习过程很快速
缺点:
牺牲决策树的可解释性
在某些噪声较大的分类或者回归问题上会过拟合
在多个分类变量的问题中,随机森林可能无法提高基学习器的准确性