介绍
Kettle(也称为Pentaho Data Integration)是一款开源的ETL(Extract, Transform, Load)工具,由Pentaho(现为Hitachi Vantara)开发和维护。它提供了一套强大的数据集成和转换功能,用于从各种数据源提取数据、进行数据转换和清洗,并将数据加载到目标系统中。
-
ETL功能:Kettle专注于提供ETL功能,即从不同的数据源(如数据库、文件、Web服务等)中提取数据,并对数据进行转换和整理,最后将数据加载到目标系统中。它支持各种数据处理操作,如过滤、排序、聚合、连接、转换等,以满足不同的数据集成需求。
-
可视化设计:Kettle提供了一个可视化的设计界面,称为Spoon。通过Spoon,用户可以通过拖拽和连接各种组件来创建数据转换和工作流程。这种可视化的设计方式使得ETL过程更加直观和易于理解。
-
多种数据源支持:Kettle支持多种数据源的连接和操作,包括关系型数据库(如MySQL、Oracle、SQL Server等)、非关系型数据库(如MongoDB、Hadoop等)、文件(如CSV、Excel等)、Web服务(如REST API、SOAP等)等。这使得Kettle可以处理各种不同类型和格式的数据。
-
强大的转换和清洗功能:Kettle提供了丰富的转换和清洗功能,可以对数据进行各种操作,如字段映射、数据类型转换、数据清洗、数据合并、数据拆分等。这些功能使得数据在整个ETL过程中能够得到有效的处理和准备。
-
可扩展性:Kettle提供了一套插件机制,允许用户根据自己的需求进行功能扩展和定制。用户可以编写自定义的插件,以满足特定的数据集成和处理需求。
Kettle是一款功能强大、灵活可扩展的ETL工具,适用于各种数据集成和转换任务。在开源系统中,它的可视化设计界面和丰富的功能使得数据处理变得更加简单和高效。
尽管目前市面上开源ETL老牌工具有Sqoop,datax,Canal、StreamSets等,新晋ELT工具有airbyte, seaTunnel等。但kettle作为传统老牌ETL工具,在易用性,资料丰富性等方面仍然有一席之地,对于千万级内的数据量级处理,仍是不可替代的优秀ETl工具之一。
本人是KETTLE使用爱好者以及二次开发者,拥有8年的丰富使用经验。在使用过程中针对kettle的弱项,以及对市面上一些kettle二开工具的对比发现,目前尚未有一款好用的调度管理工具。经此,于是准备开发一款简单易用,灵活部署,可以水平扩展的分布式调度管理平台。
功能介绍和对比
废话不多说,上才艺:
| 比较维度 | 功能 | 本产品 | 第三方产品 | ||||
| 设计及架构 | 框架 | springcloud微服务 | springboot或springmvc单体 | ||||
| 设计 | 前后端分离ui层 | 管理,调度,执行耦合在一个服务中 | |||||
| 调度层 | |||||||
| agent层 | |||||||
| 执行层 | |||||||
| 调度层 | 基于xxl-job封装和优化,支持集群和动态分片,集群模式下支持数十万至百万级任务调度 | 基于quartz或者spring schedule组件 | |||||
| agent层 | springcloud微服务模式,用来管理kettle的carte服务,支持水平扩展,接受调度层的指令,来向执行层发送转换做作业的任务。 1、支持carte服务的管理和探活,自动剔除异常节点,和故障转移 2、支持8种负载均衡策略 3、基于分片模式的任务执行状态定时检测,不存在单点压力和故障。 4、任务异常告警,carte服务监控告警可视化配置 | 无 | |||||
| 执行层 | 基于kettle的carte模式采用插件策略二次开发,无代码入侵,不集成任何kettle源码,兼容kettle5.x, kettle6.x, kettle7.x, kettle8.x,kettle9.x | kettle源码嵌入单体服务中,不利于版本升级和管理 | |||||
| 前端UI | 框架 | vue2.X | easyUI, jquery, bootstrap | ||||
| 权限设计 | 基于RBAC模式设计 | 部门,岗位,角色 | 无 | ||||
| 菜单,按钮,资源层精细化控制 | |||||||
| 数据权限 | |||||||
| 业务模块设计 | 数据集成 | 任务报表概览 | 任务管理 | ||||
| 项目管理 | 无 | ||||||
| 任务管理 | 无 | ||||||
| 集群管理 | 无 | ||||||
| 节点管理 | 无 | ||||||
| 无 | |||||||
| 元数据管理 | 血缘分析 | 无 | |||||
| 数据源管理 | |||||||
| 数仓管理 | ODS原始数据层 | 无 | |||||
| DWD数据明细层 | 无 | ||||||
| DWS服务数据层 | 无 | ||||||
| ADS数据应用层 | 无 | ||||||
| 数据服务 | 数据发布 | 无 | |||||
| 授权管理 | 无 | ||||||
| api管理 | 无 | ||||||
| 监控模块 | 服务器监控 | Prometheus,hertzbeat | 无 | ||||
| 服务级监控 | grafana | 无 | |||||
| jvm监控 | 无 | ||||||
| 日志观测;链路追踪模块 | loki日志可视化 | loki日志可视化 | 无 | ||||
| oss日志存储 | oss日志存储 | 无 | |||||
| jaeger链路追踪 | jaeger链路追踪 | 无 | |||||
架构设计
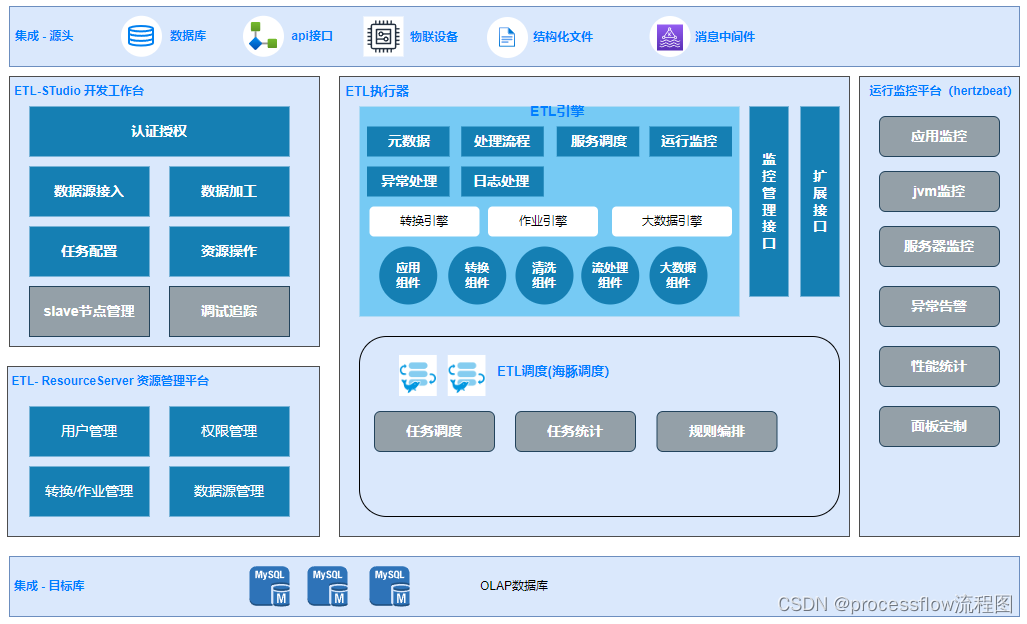
详细功能介绍
1、ETL概览
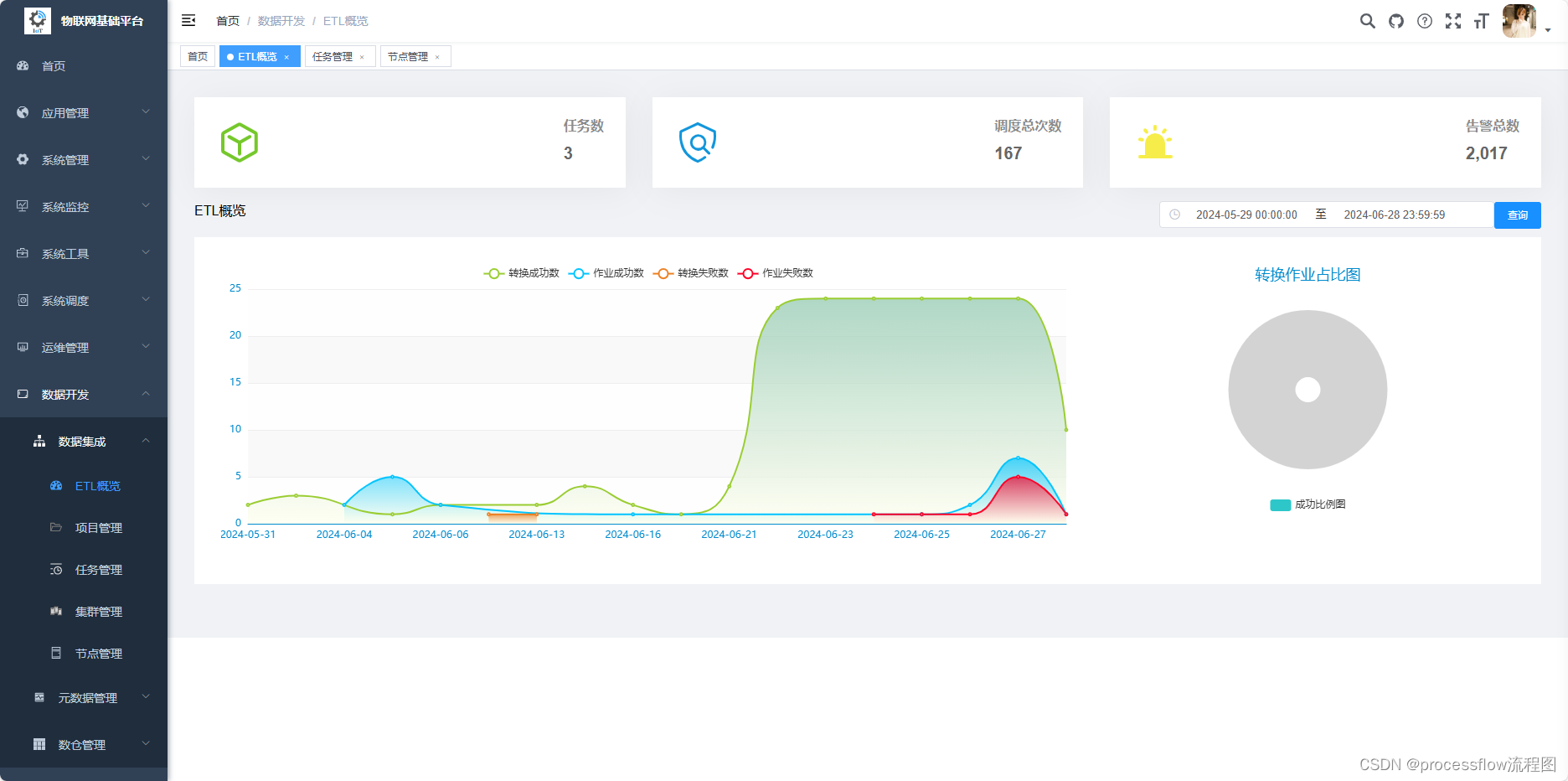
首先是ETL概览,最上面是统计当前管理的任务数,以及任务执行情况。下面的折线图是展示每日执行的转换和作业的成功失败数。
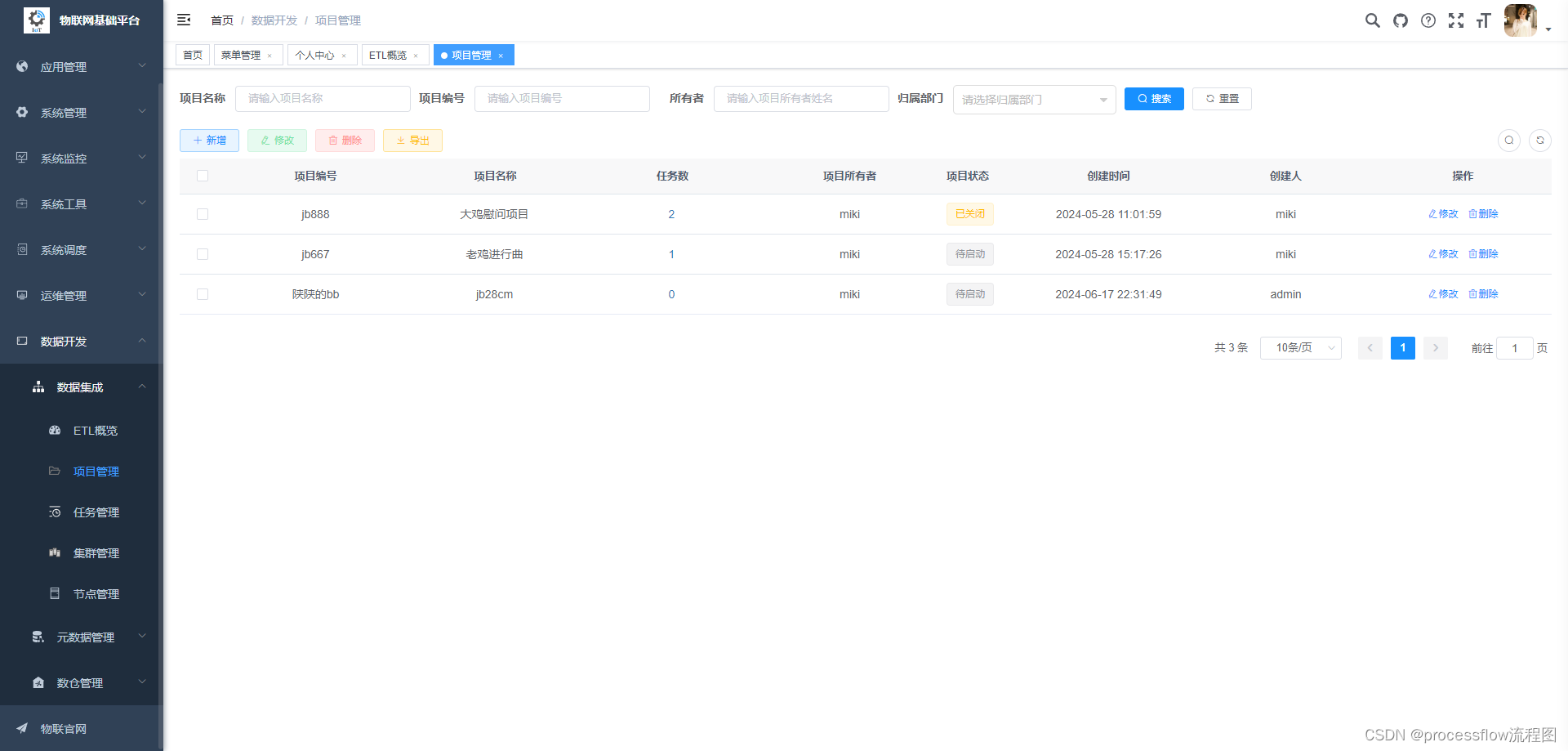
2、项目管理
2.1 项目管理
对ETL任务进行项目维度的包装,将ETL任务和业务进行绑定,使之具备生命周期属性,更易于理解和管理。
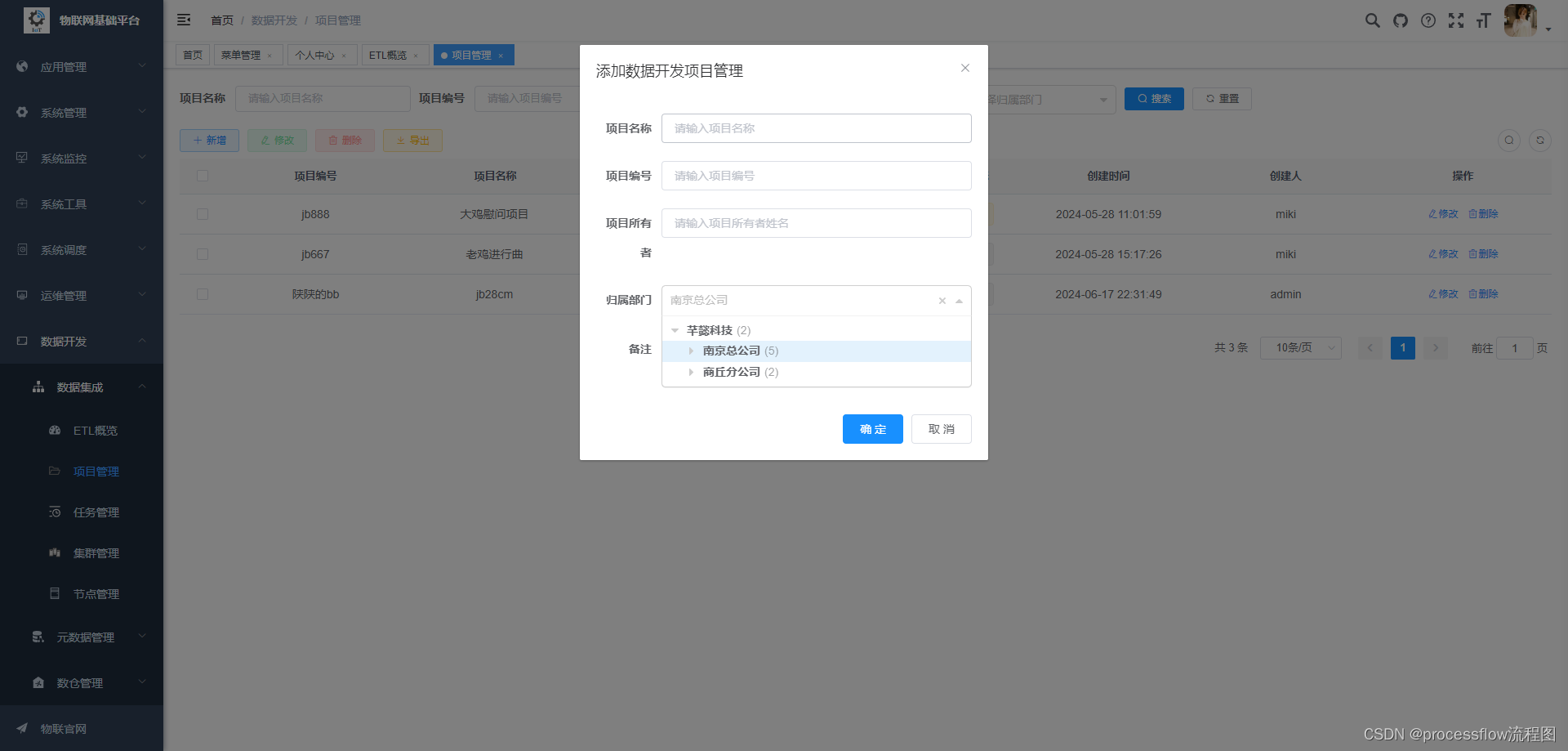
2.2 项目新增
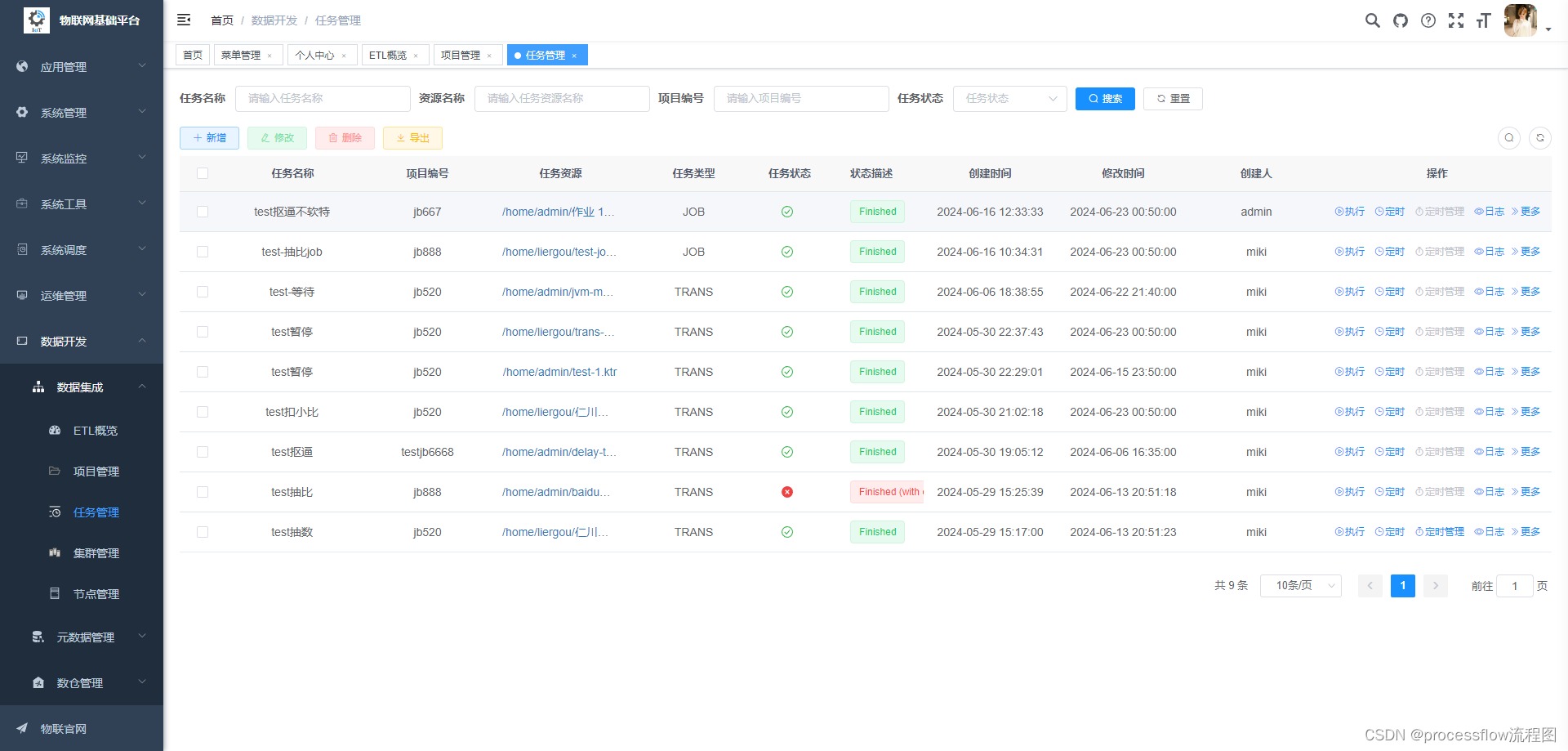
3、任务管理
整个系统的最核心地方,对ETL任务进行封装,与项目映射为多对一的关系。一个项目任务绑定一个carte集群,和一个调度任务,并拥有任务状态属性。可以实时查看当前任务执行状态,以及执行日志。
-
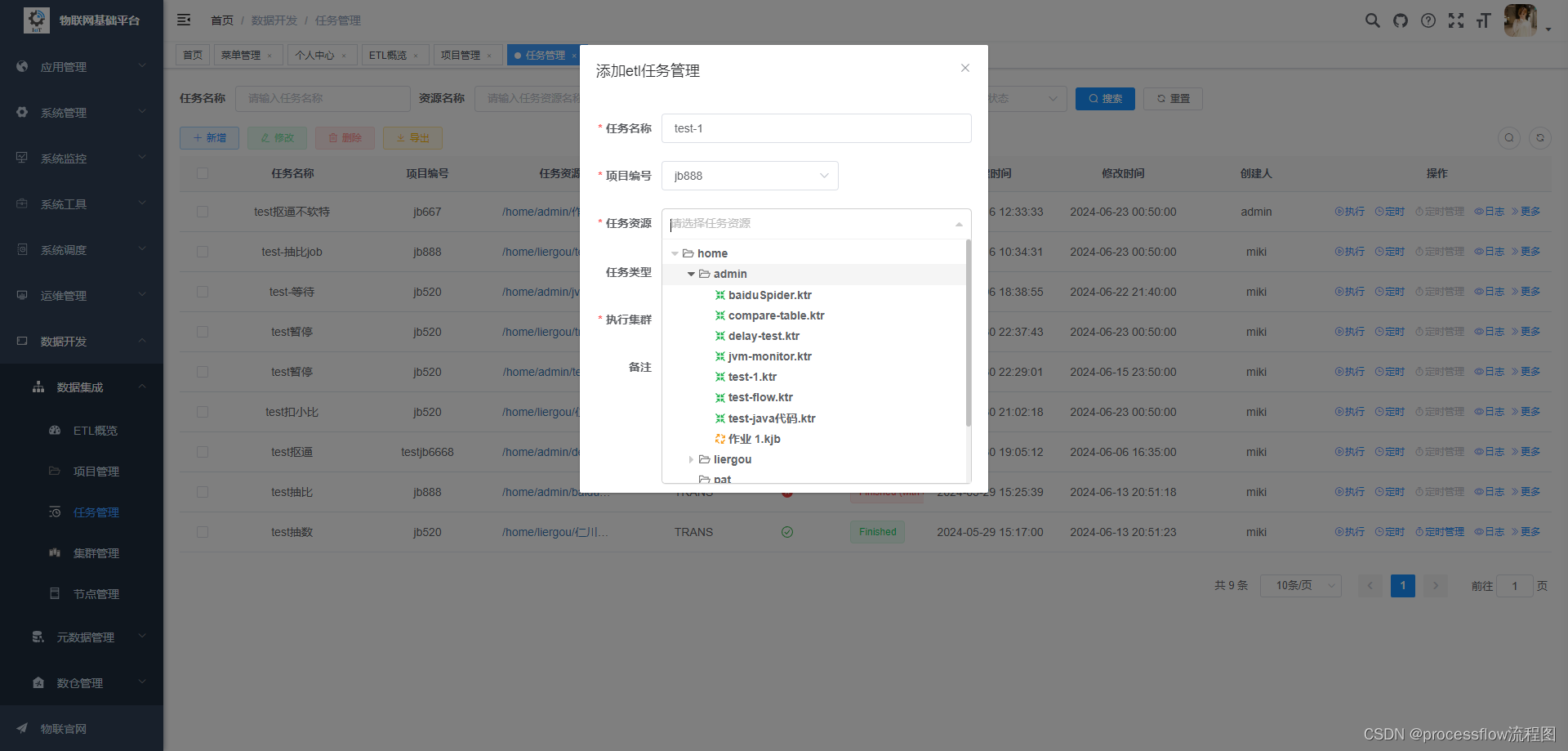
任务新增
新增任务,需要绑定项目,和ETL资源库的转换或作业信息,然后再指定要执行的carte集群。
支持运行中的任务实时修改转换或作业信息。改动下次执行生效。
-
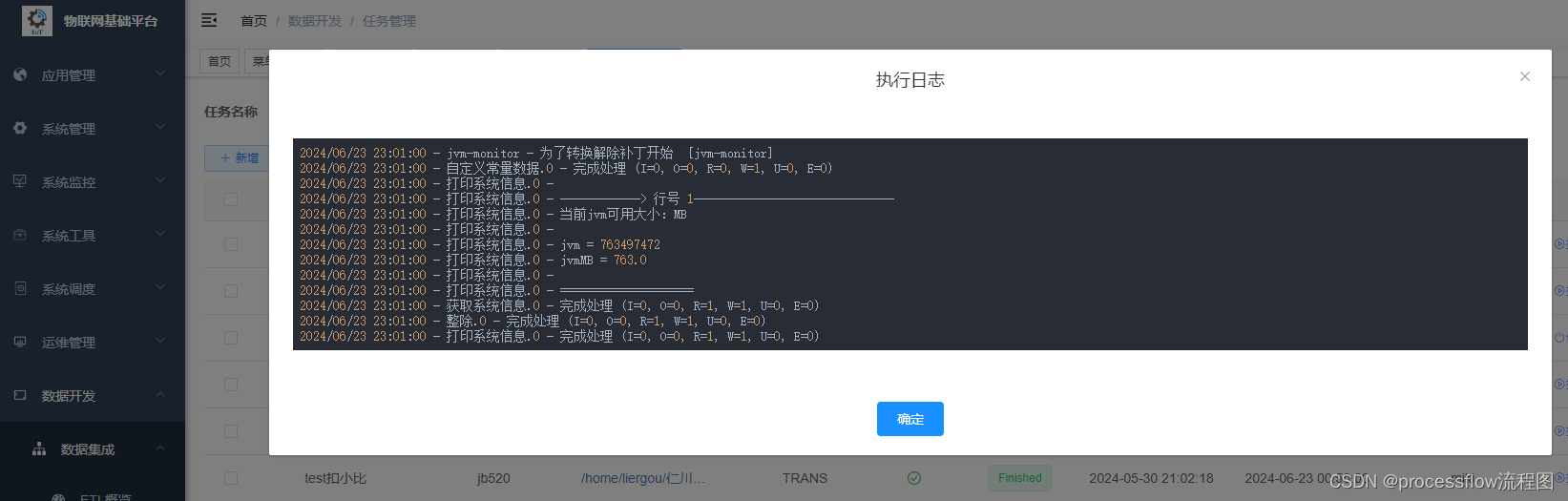
任务执行
任务创建完成之后,可以点击右侧按钮执行执行一次,此时agent层会从集群中根据负载均衡策略,选取一个可用的slave节点,将转换做作业信息发送到该节点上执行,并将改任务添加到状态监控队列,对任务的执行状态进行更新和日志监控

当任务启动后,状态栏会切换为动态转换的蓝色小齿轮,同时可以实时查看进行中的日志
-
任务定时执行
对于ETL任务,90%的都要定时重复执行,这里可以设置定时执行:
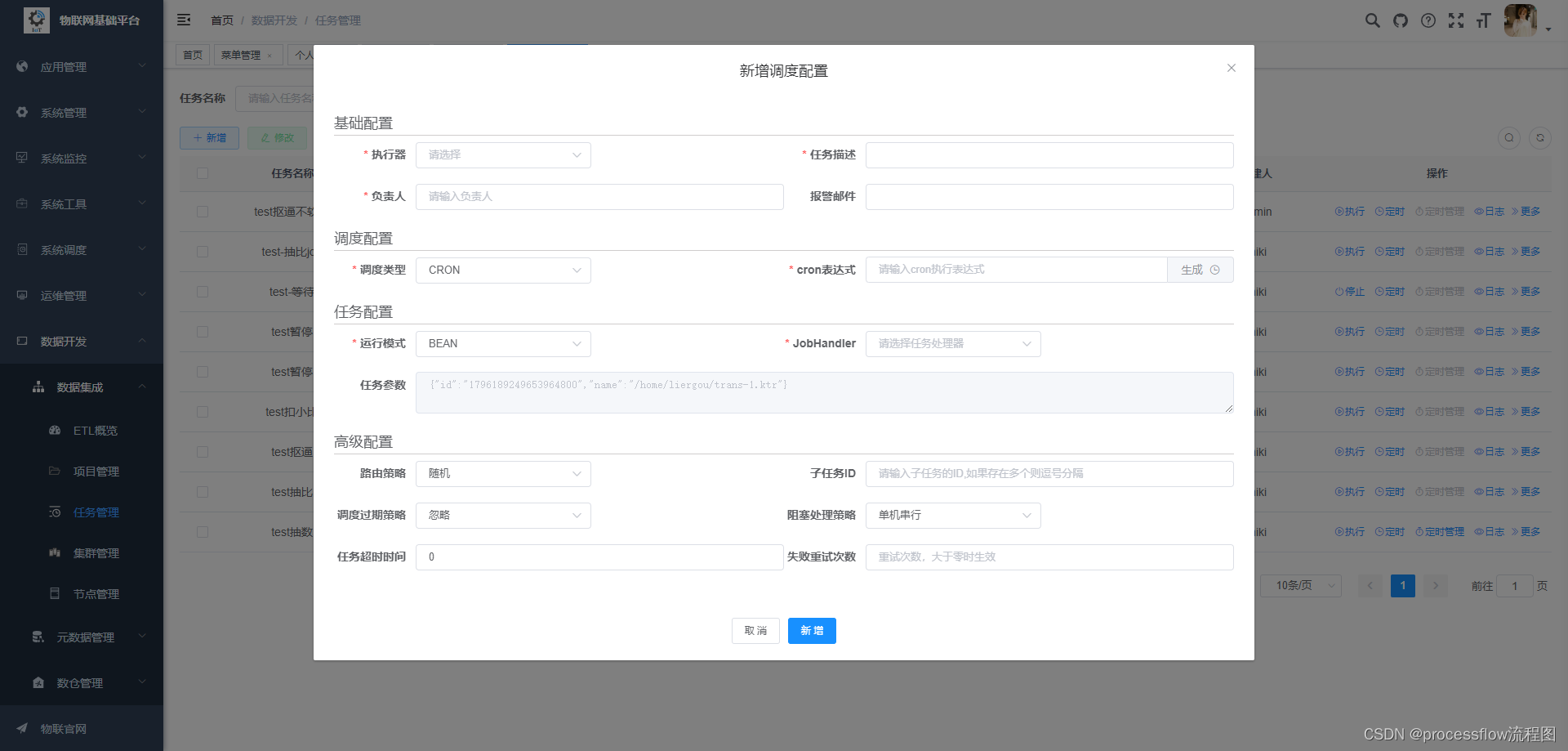
这里可以对定时方式进行配置,指定agent作为执行器,以及agent的路由策略,cron表达式,以及失败策略等。
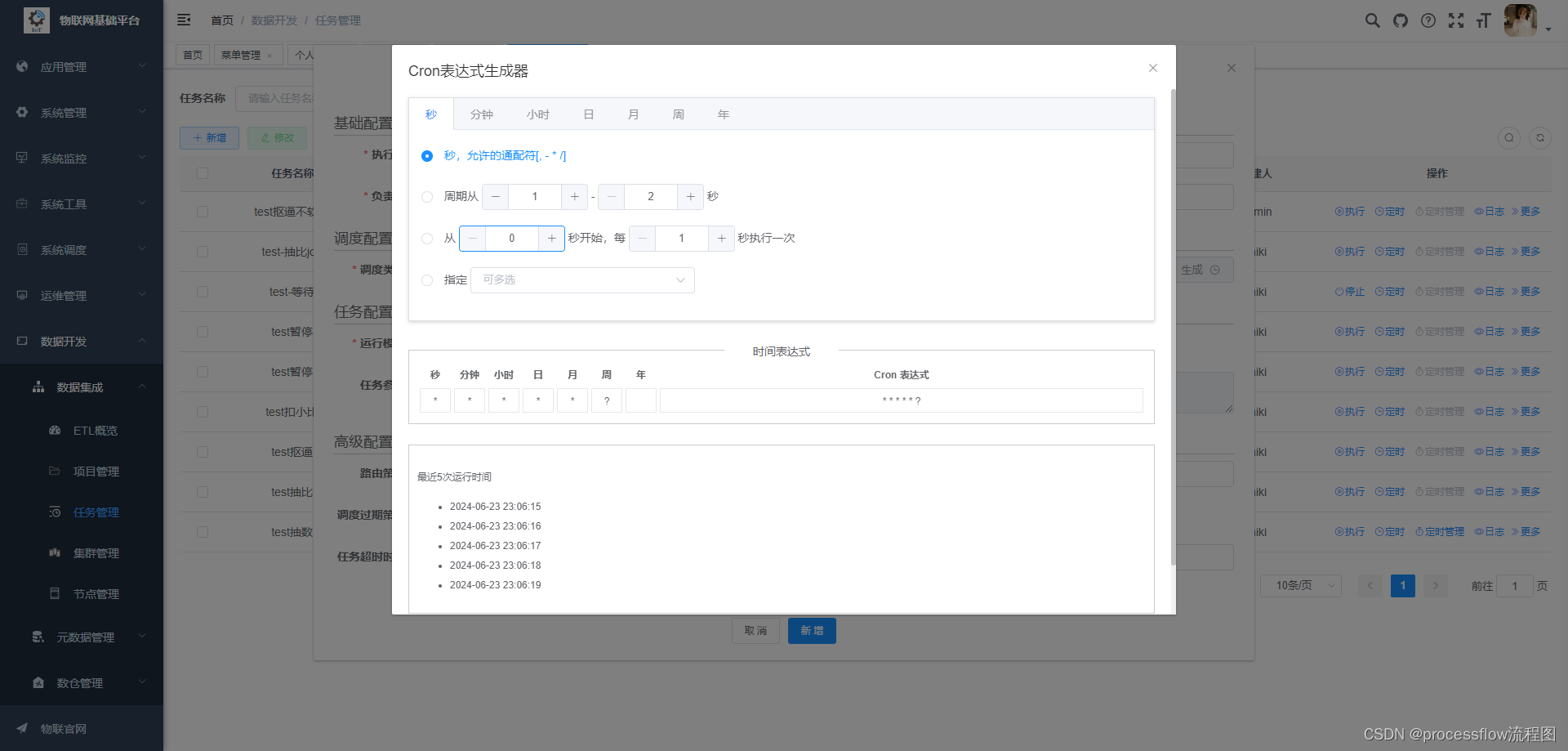
-
启动定时任务
点击定时管理按钮,可以对定时任务进行执行,停止,以及删除操作。
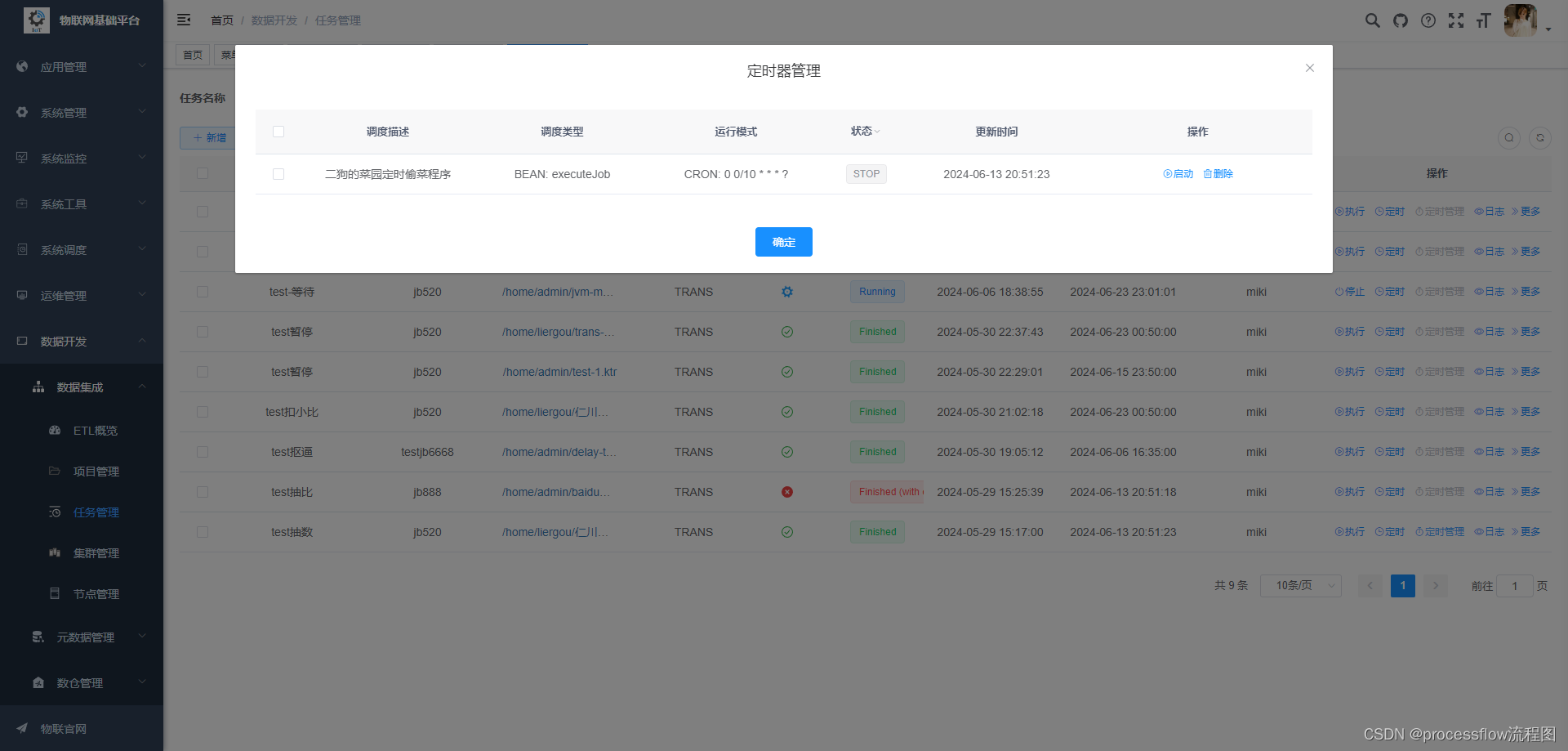
-
任务修改
支持实时的任务修改,和集群修改,下次执行时会自动生效。
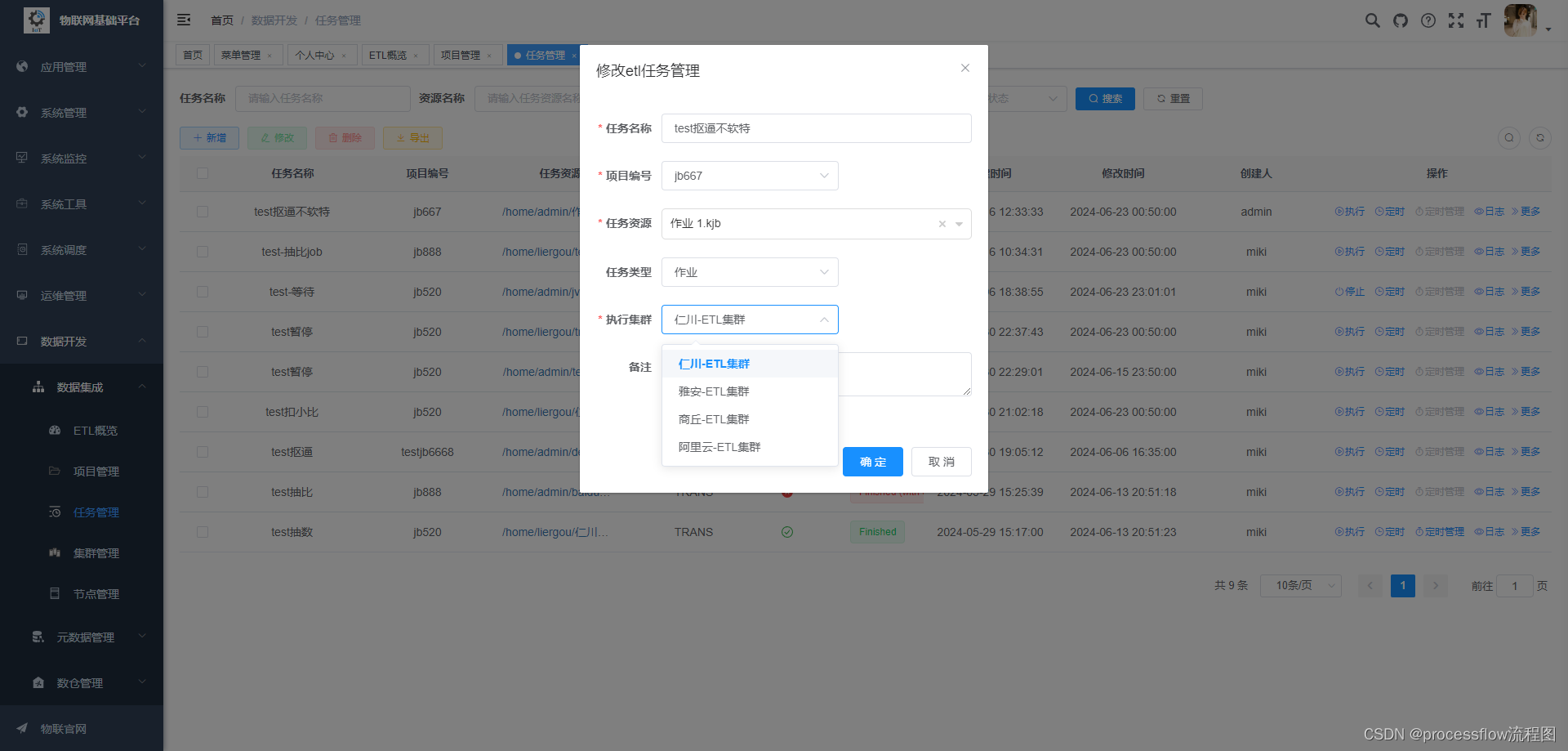
任务DAG查看
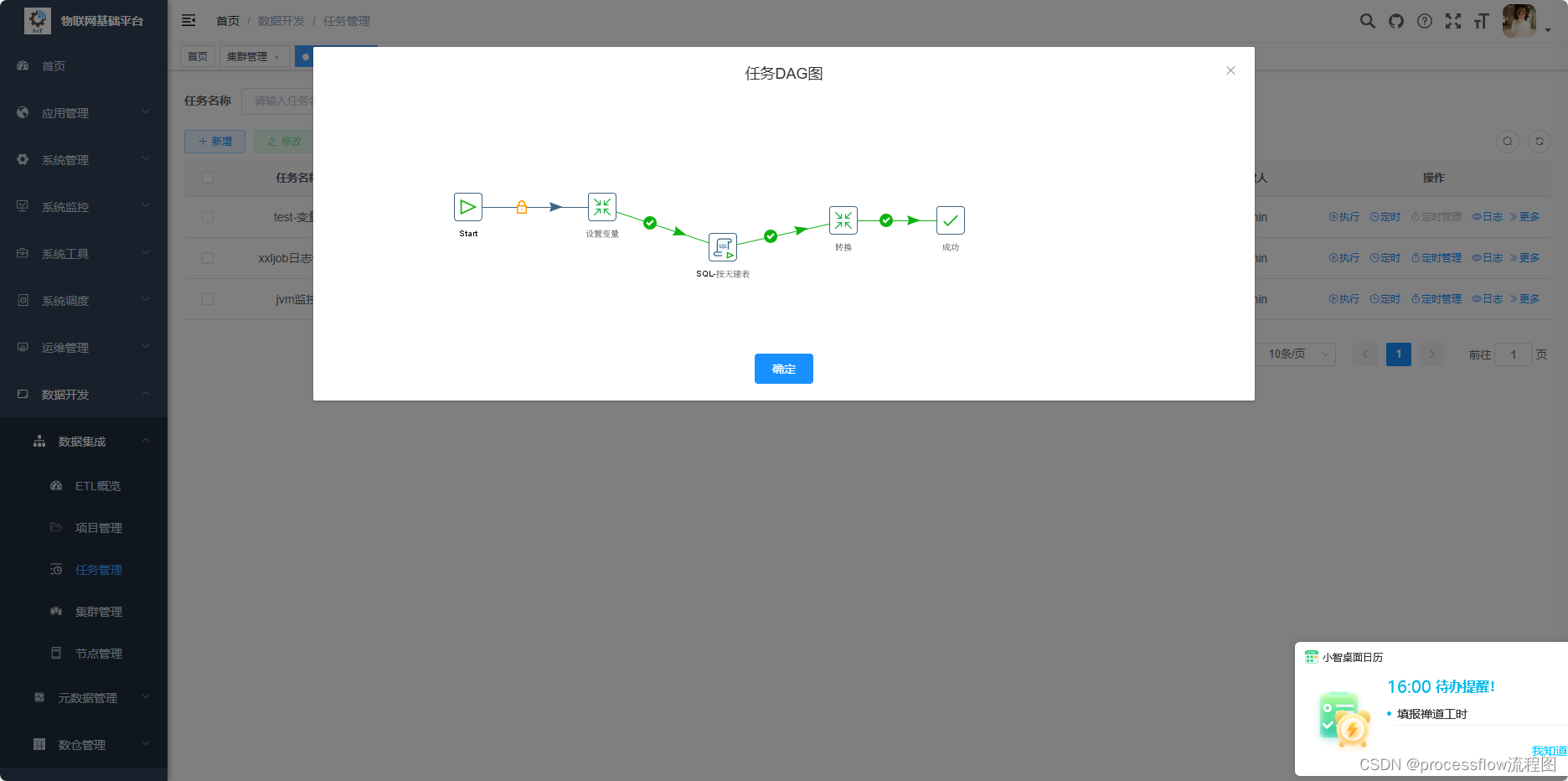
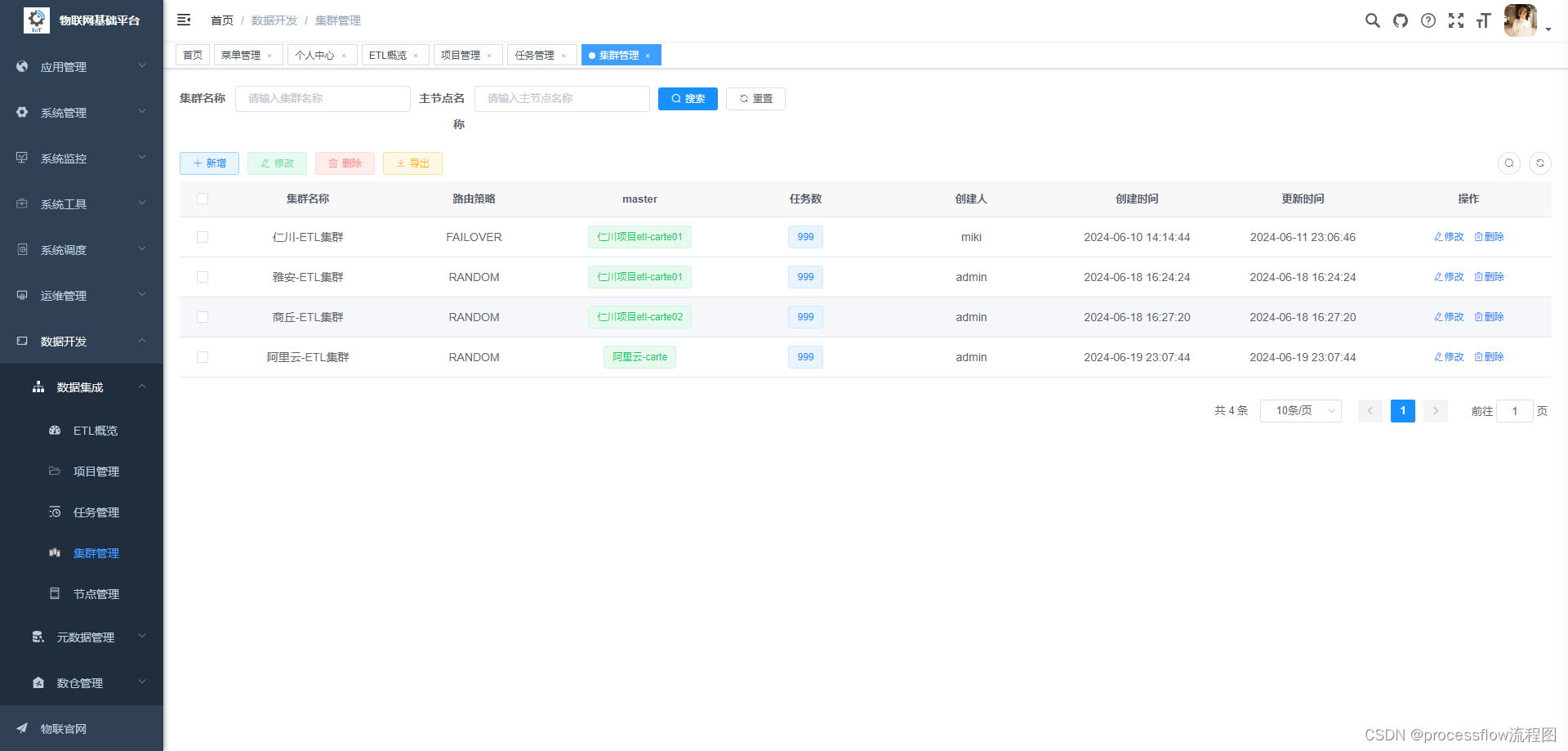
4、集群管理
这里重新设计了carte的集群配置,carte本身的集群只是简单的主从模式,这里设计了master动态选举集群模式,
master节点挂掉之后,会自动选择其他slave节点作为master节点。
-
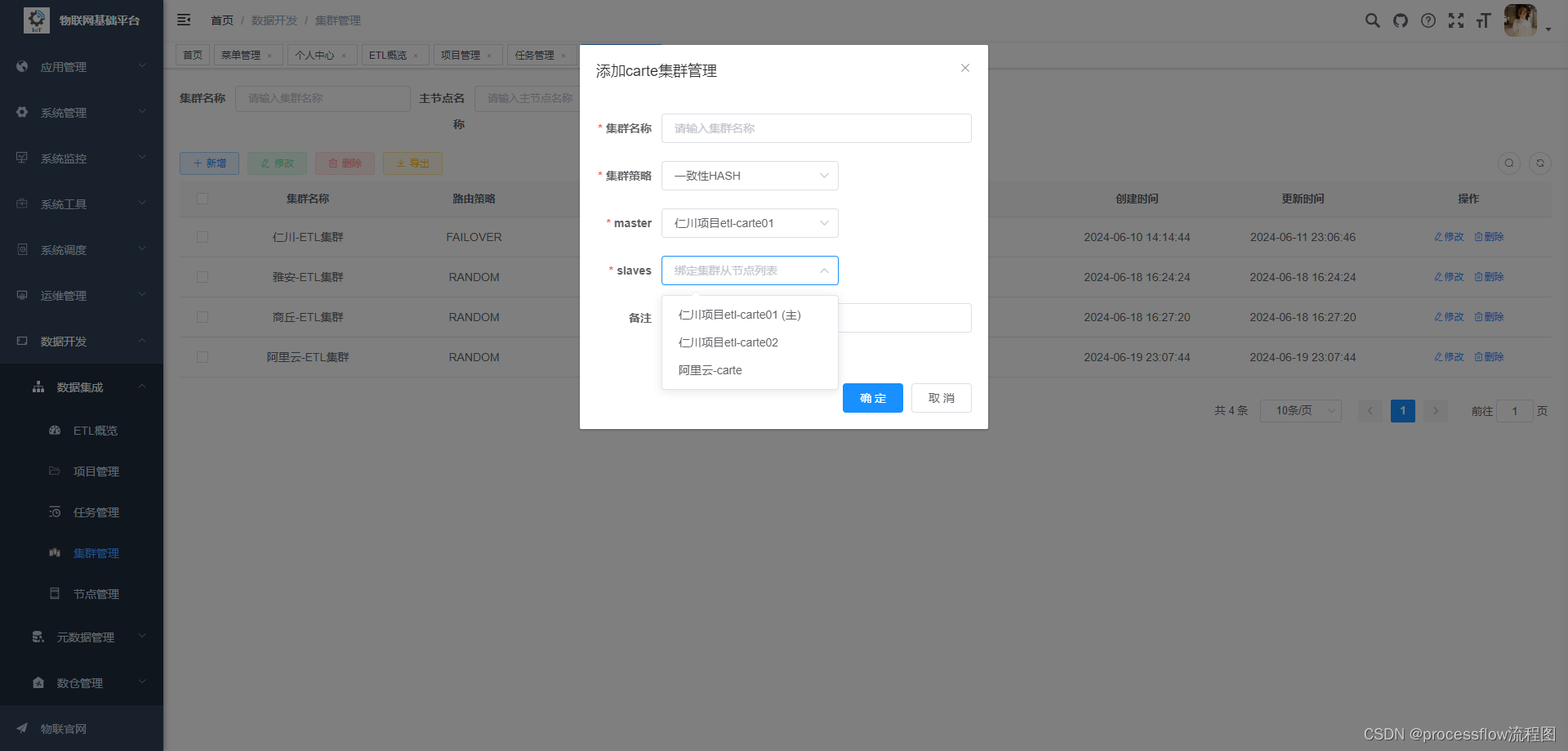
新建集群
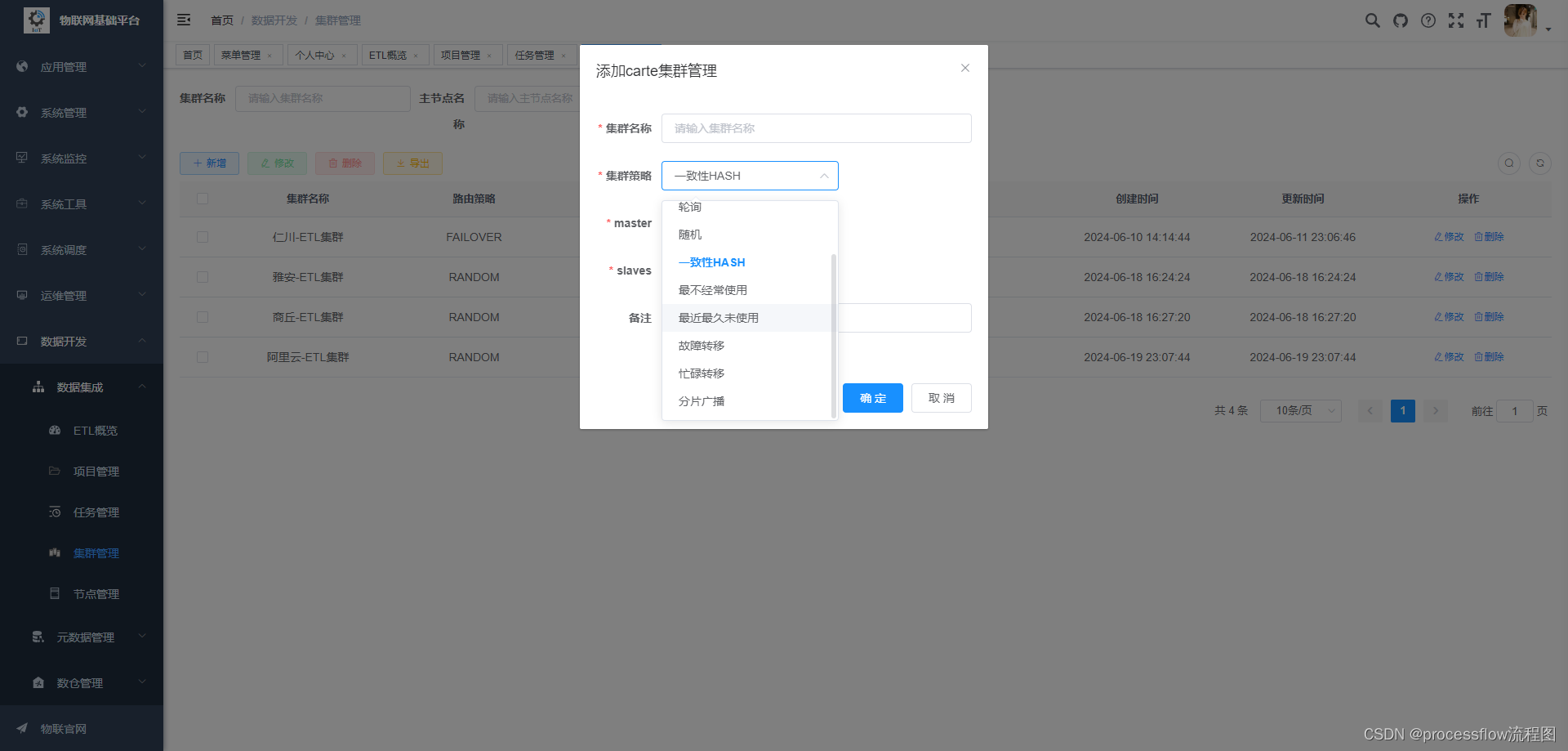
每个slave可以加入到多个集群中,互不冲突。集群策略支持8种负载均衡模式,如果对任务执行成功率有严格要求,可以设置为故障转移模式,但这种情况可能会存在任务倾斜的情况,导致某个carte节点任务数很多,而有的carte又很闲。后面会考虑增加一个组合模式的负载均衡策略,将故障转移和轮询或者一致性hash结合在一起。正常情况建议选择一致性hash或者轮询策略。
5、节点管理
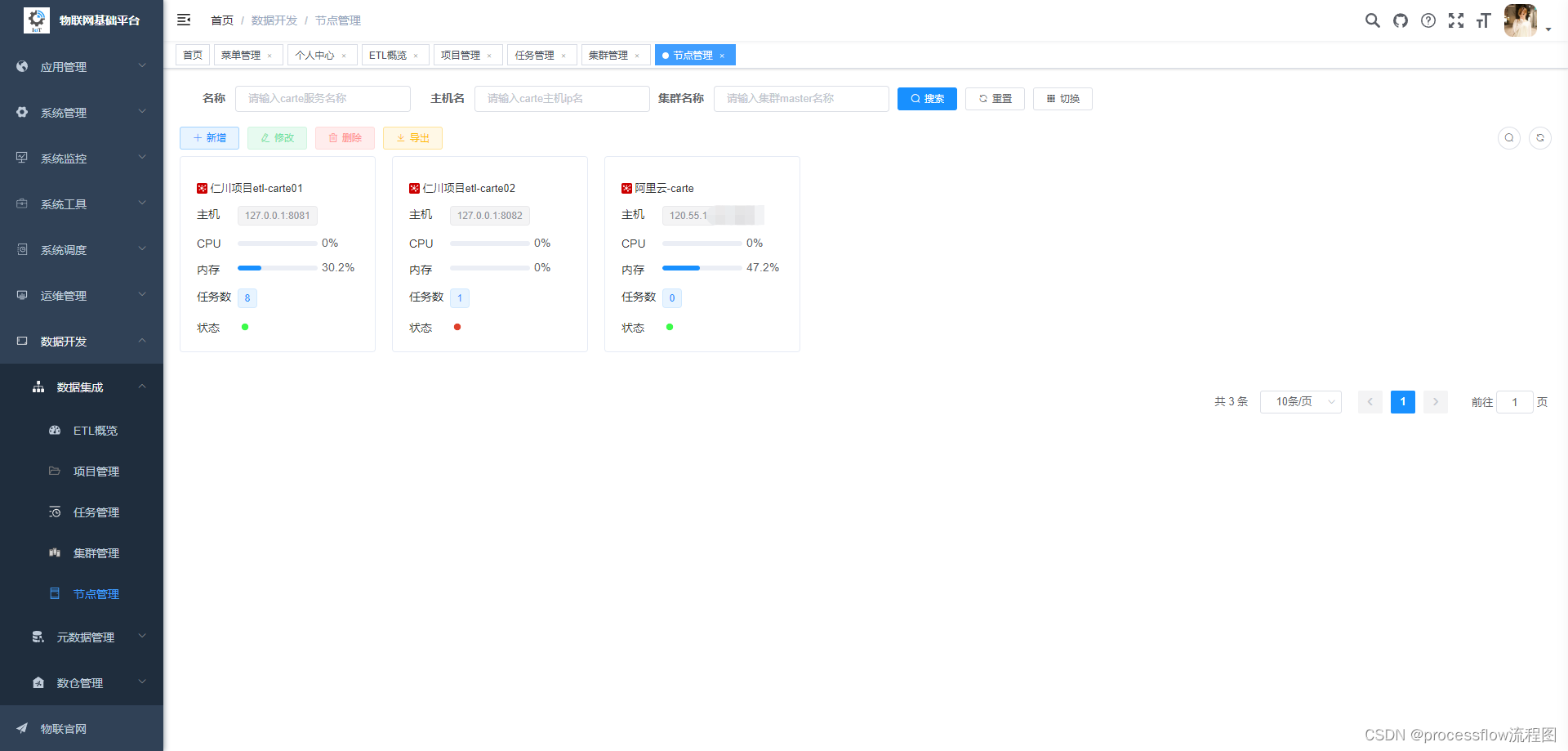
节点是集群的组成核心之一,所有集群都是从节点池中选择一批进行组合。
管理列表这里优先展示节点身上的任务数,以及cpu和内存使用情况。
-
节点操作
可以对节点进行刷新,编辑,停止等操作。

6、日志观测平台
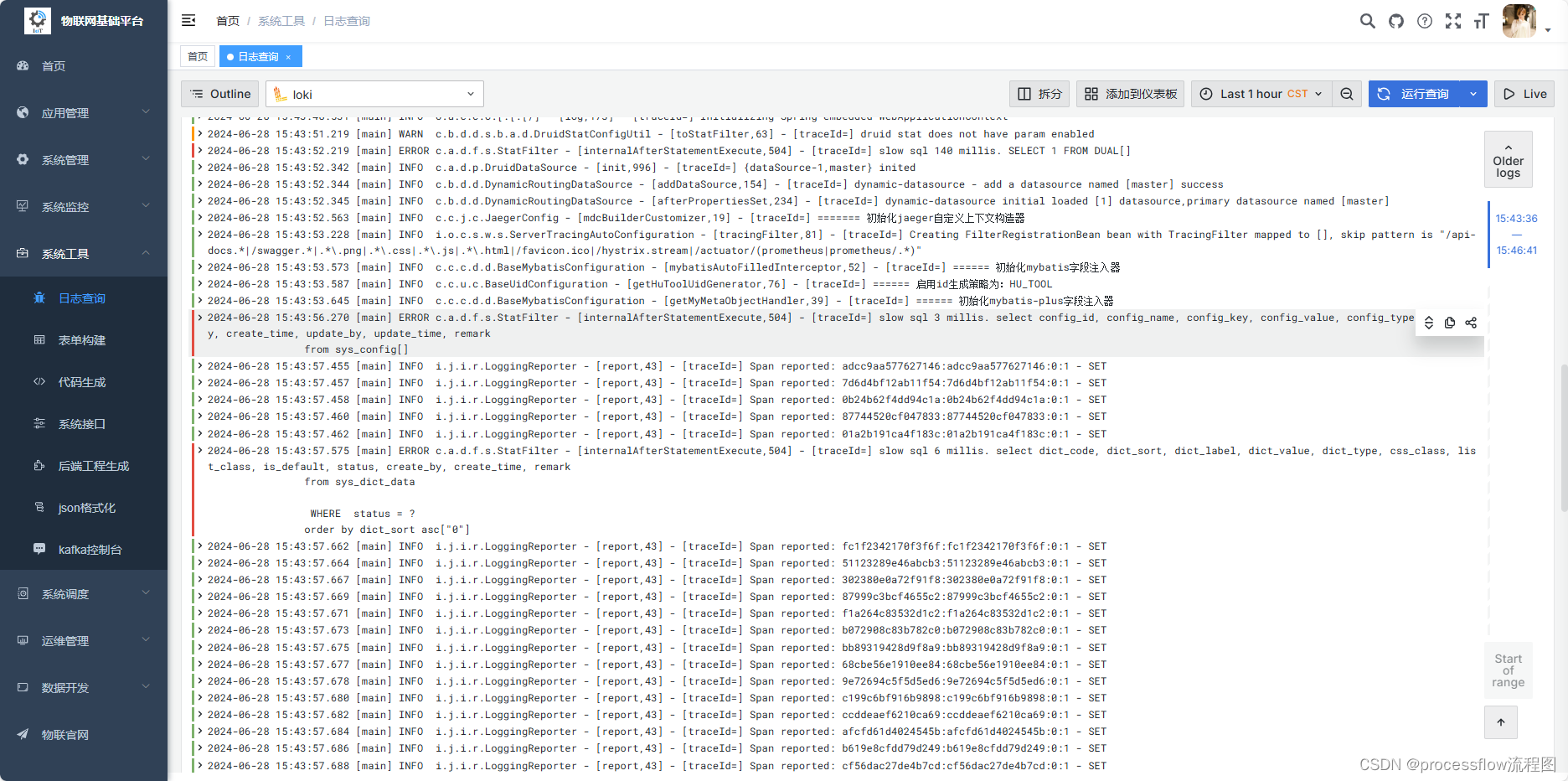
日志观测平台基于分布式轻量级日志存储系统loki, 和采集器vector, 以及grafana可视化展示平台组成,方便开发实时排查系统日志和快速定位问题。
7、监控告警平台
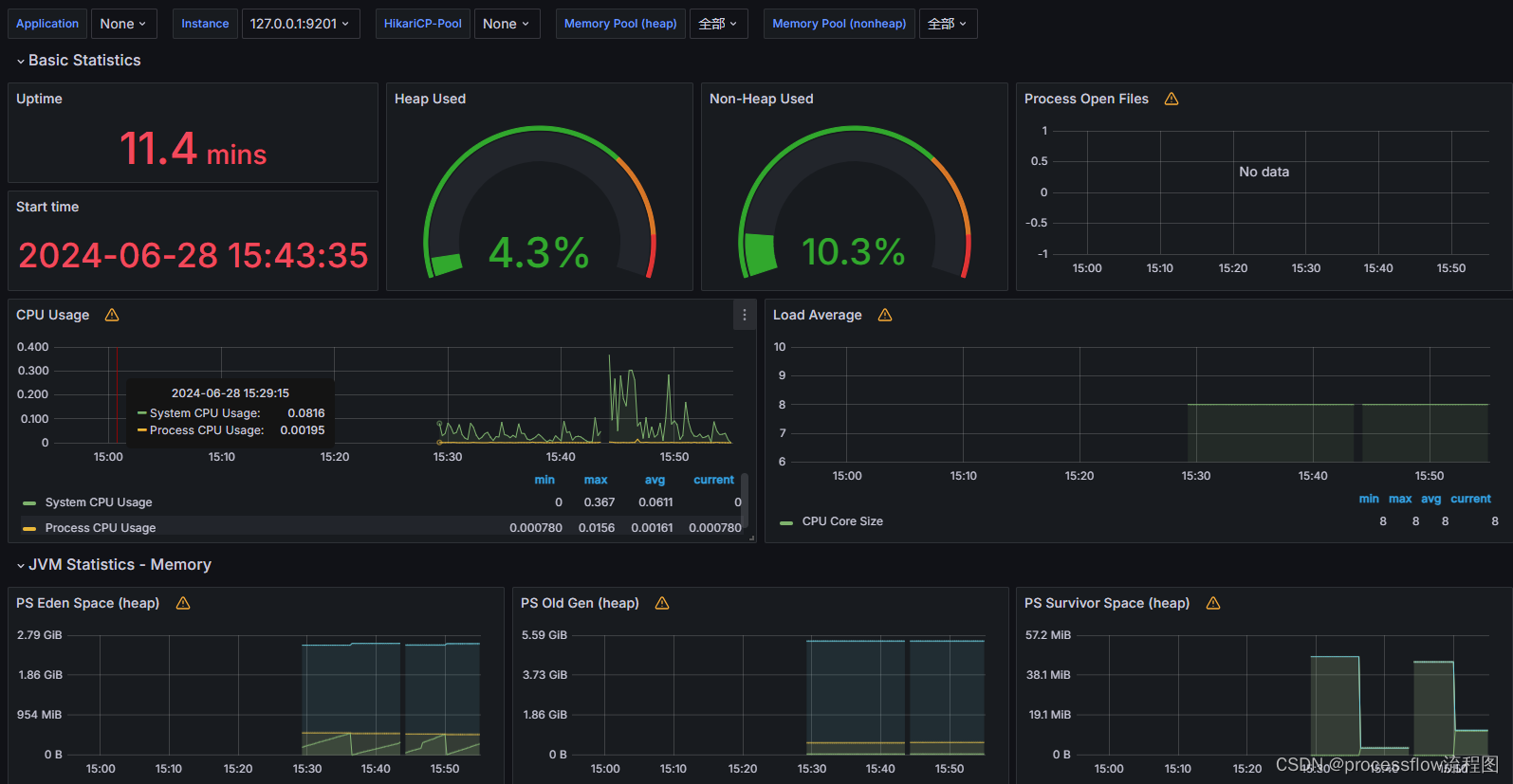
基于jmx和prometheus非入侵方式对carte服务进行jvm维度的监控,一旦服务状态异常,秒级响应告警,方便运维实时处理问题,保证ETL任务的稳定性和可靠性。
系统体验
生活不易,系统目前在持续升级,迭代中,暂时未计划开源。核心功能ETL部分已在自有阿里云服务器稳定运行3个月之久,2C2G的单机carte配置,可稳定运行10-100个任务(视具体任务的数据体量而定)。