简单的文本可以使用网站来快速转换,但是发现很多格式不能正确转换,所以研究了一个Py的方法来实现,如下:
安装Py插件
本方法主要借用markdown2 来实现,开始之前需要先安装一些库。
pip install markdown2 beautifulsoup4 lxml
Python 脚本实现转换
以下脚本将 Markdown 文件转换为 Confluence 格式:
默认输入md文件名为:input.md
默认输出md文件名为:output.confluence
默认Python 脚本文件名为:m2c.py
import markdown2
from bs4 import BeautifulSoup# 读取Markdown文件
with open('input.md', 'r', encoding='utf-8') as md_file:markdown_content = md_file.read()# 将Markdown转换为HTML
html_content = markdown2.markdown(markdown_content)# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html_content, 'lxml')# 定义一个函数,将HTML标签转换为Confluence标签
def convert_to_confluence(soup):# 替换标题标签for tag in soup.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6']):tag.name = 'ac:structured-macro'tag['ac:name'] = 'panel'tag.string = f"h{tag.name[-1]}: {tag.text}"# 替换段落标签for tag in soup.find_all('p'):tag.name = 'ac:structured-macro'tag['ac:name'] = 'panel'tag.string = tag.text# 其他标签转换可以按需添加return soup# 转换HTML为Confluence格式
confluence_content = convert_to_confluence(soup).prettify()# 保存为Confluence格式文件
with open('output.confluence', 'w', encoding='utf-8') as conf_file:conf_file.write(confluence_content)print("转换完成")
运行脚本
在脚本的目录中编写好md文件,然后运行脚本
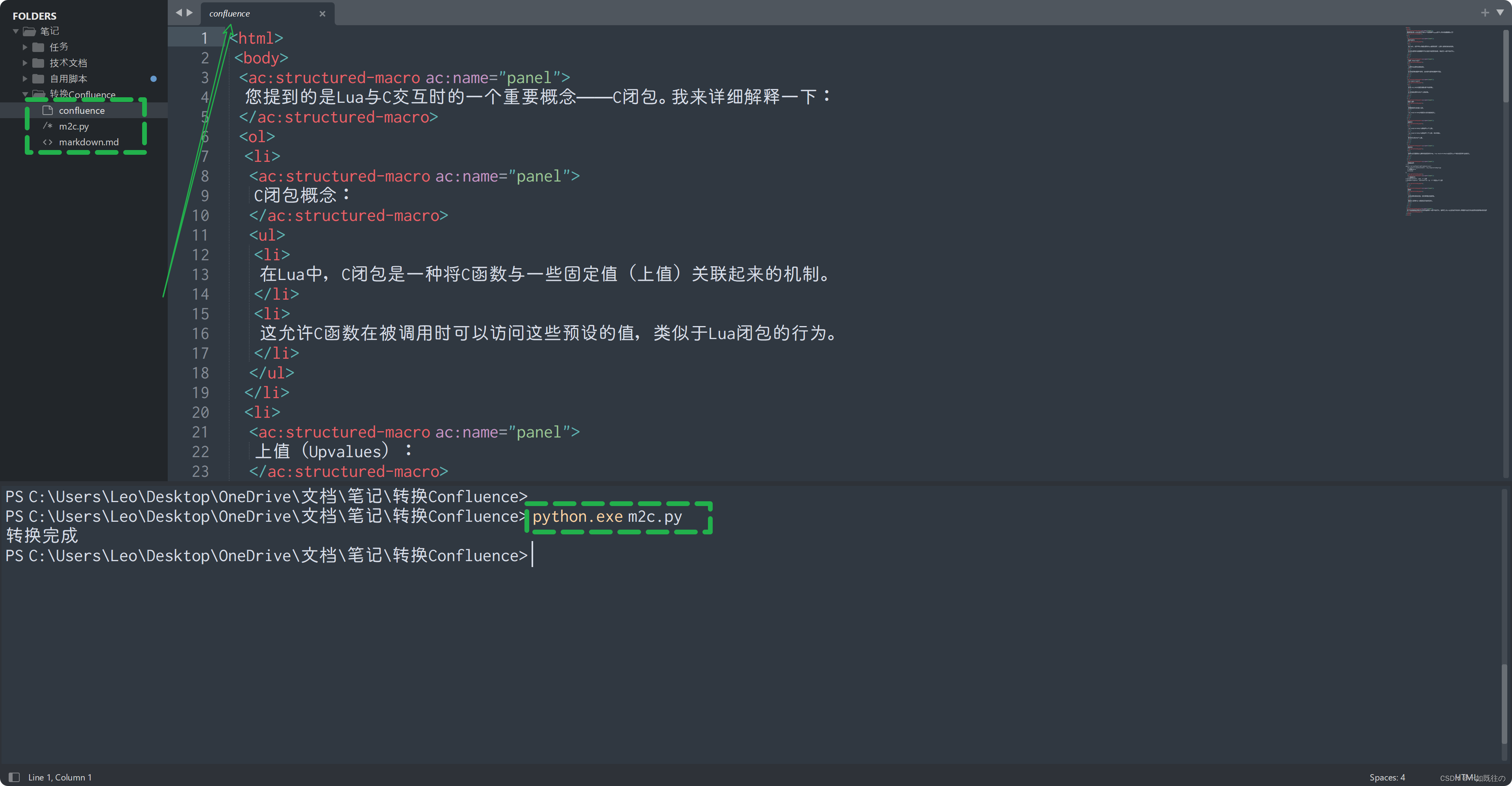
bash python m2c.py
得到类似XML格式的输出文件,全选复制:
编写Confluence
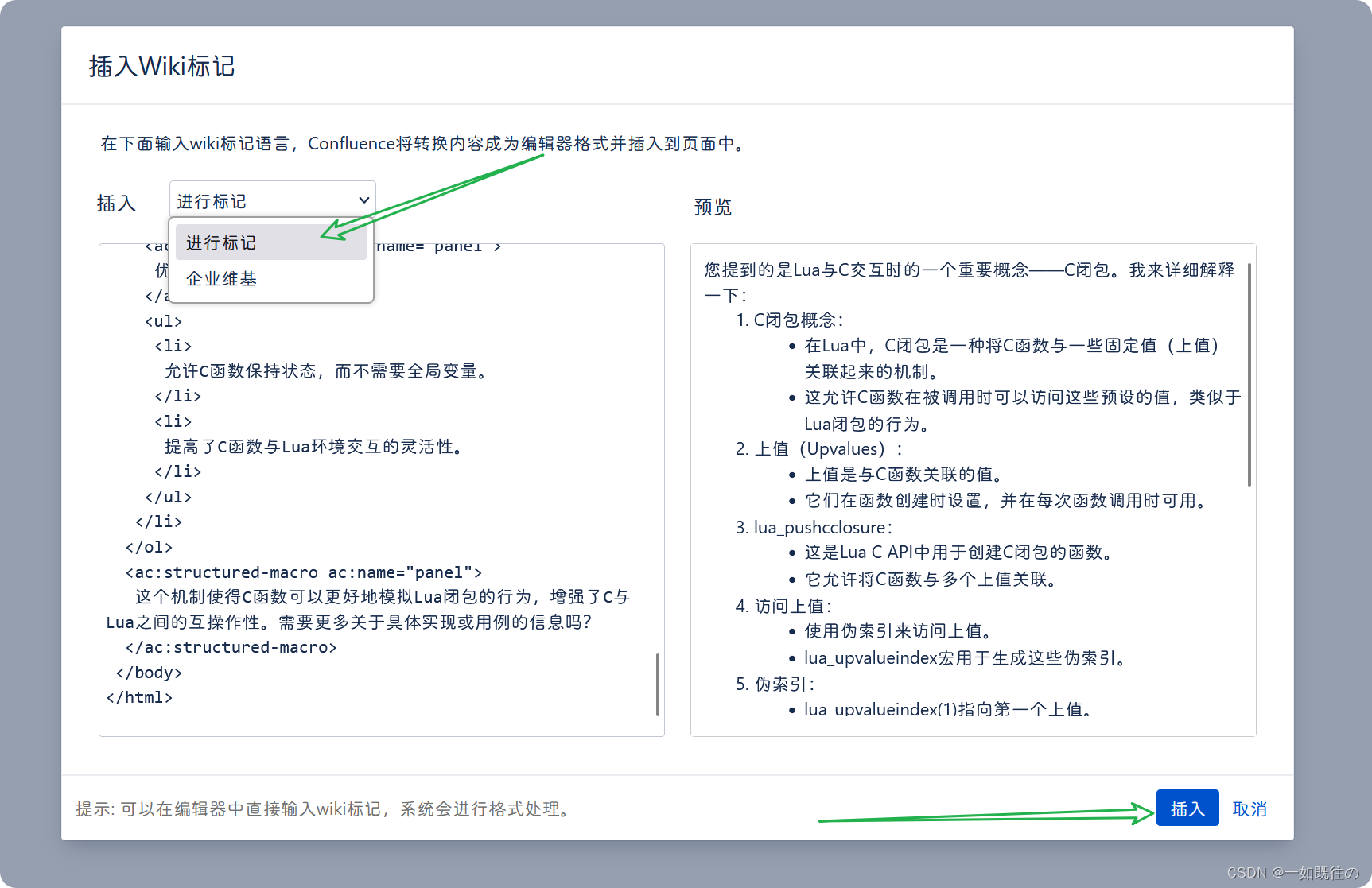
启动编写界面,然后点击插入Wiki标记:
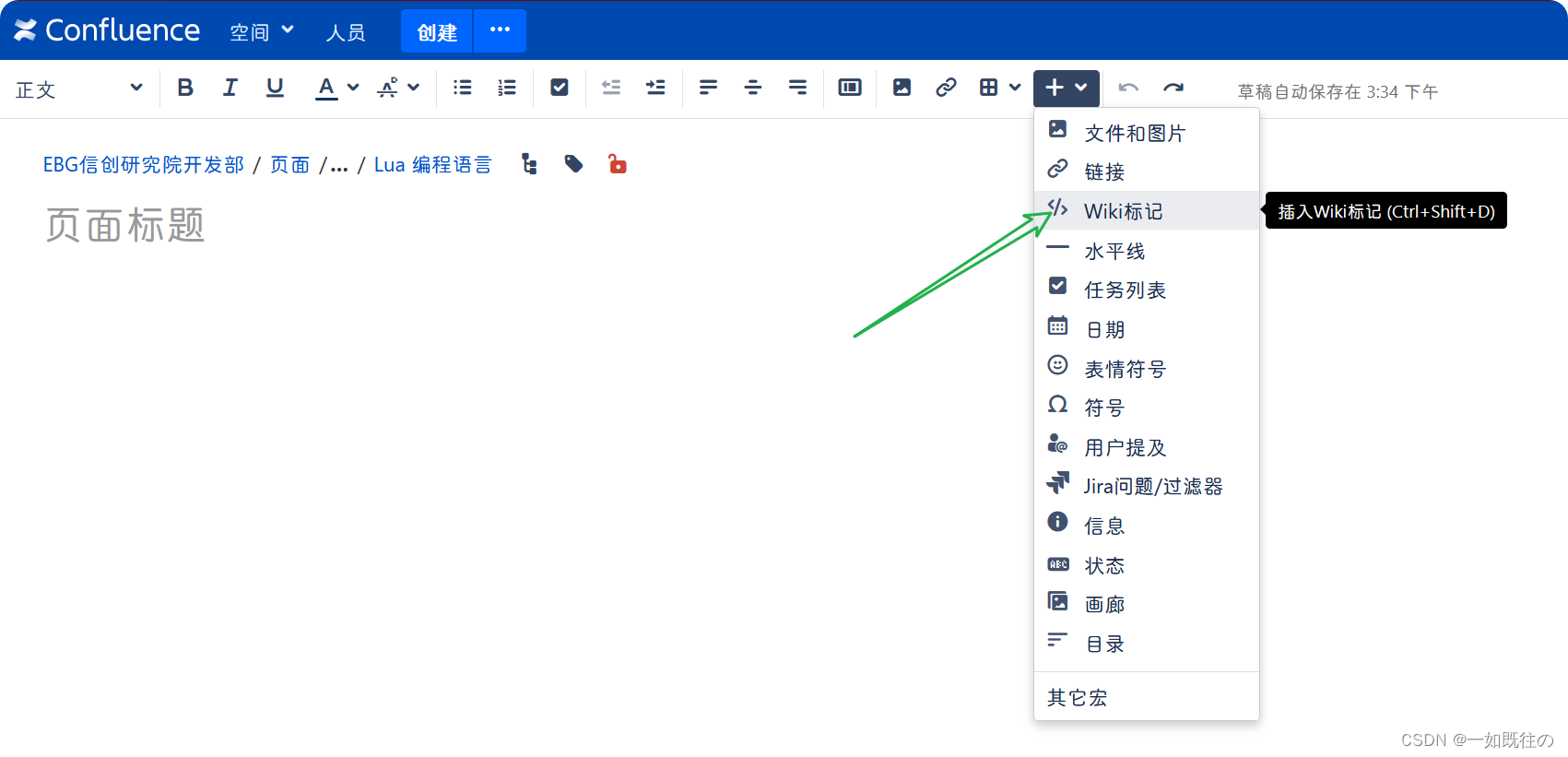
最后选择**进行标记**,然后粘贴复制的结果,可以看到预览框里面的显示非常完美,最后点击插入,保存即可。