今天给大家分享的是国内顶级期刊2023年发表论文《数字基础设施与代际收入向上流动性——基于“宽带中国”战略的准自然实验》使用到的重要数据集——“宽带中国”政策变量数据、互联网发展指数以及工具变量(所在城市到杭州市的球面距离和到“八纵八横”政策节点城市距离)数据,该文章研究了数字基础设施对农村人口代际收入向上流动的影响,在新古典增长模型和代际收入流动分析框架基础上,从理论上探讨了数字基础设施对代际收入向上流动的影响以及作用机制,然后将“宽带中国”政策外生冲击与CFPS数据相结合,利用DID模型以及包括工具变量法在内的多种内生性分析方法从实证角度检验了这一影响,并探讨了其中的作用机制。该论文在研究过程中使用到了宽带中国政策变量数据、数字基础设施代理变量互联网发展指数数据以及内生性检验中的工具变量数据(所在城市到杭州市的球面距离和到“八纵八横”政策节点城市距离),我们对这些数据进行了整理,并进行了适当的拓展方便大家研究,,数据获取请关注公众号“明天科技屋”,打开公众号文章获取文末数字关键词并回复,在该数据发布24小时之内可以通过分享获得。
一、论文讲解 
该文章将宽带中国政策与CFPS数据相结合,采用双重差分模型研究数字基础设施对代际收入向上流动的影响,并进行了更换被解释变量和核心解释变量、遗漏变量分析、平行趋势检验、稳定单元处理效果假设检验以及工具变量法等一系列稳健性检验,结果仍然保持文件,并且从提高父代对子代的人力资本投资回报、减少子代对父代社会资本继承、增加子代的“市场运气”等方面进行了机制分析,最终得出结论,给出相应的政策建议。
(一)基准模型
其中,为被解释变量,定义为c市农村户籍的i子代在t时是否实现了代际收入的向上流动,如果父代收入位于同代收入分布的后50%,而子代收入位于同代收入的前50%,则认为子代实现了代际收入的向上流动,取值为1,否则为0。
是文章关注的DID项,即个体i所在城市在t时刻是否开始实施政策的处理变量。
是个体、父母、家庭和省市层面的控制变量。
和
分别是个体以及时间固定效应。
是随机扰动想。
(二)数据介绍
宏观数据主要包括数字基础设施发展状况、省市层面的控制变量、机制变量等。其中数字基础设施发展状况代理变量的“宽带中国”政策数据来源于工信部。省市层面的控制变量以及机制变量数据来源于CEIC数据库、复旦大学和第一财经研究院等发布的数据。微观数据来源于中国家庭追踪调查(CFPS)。
(三)实证分析
1. 基准回归
2.更换被解释变量结和核心解释变量
论文中在这一块研究中对被解释变量和核心解释变量均进行了更换,被解释变量更换请查看论文,核心解释变量采用了互联网发展指数来代理数字基础设施发展状况,互联网发展指数由移动电话用户数、互联网宽带接入用户数、信息传输、计算机服务和软件业的就业人员、电信收入以及普惠金融指数等指标通过主成分分析得到,我们对这部分数据进行了收集整理,具体数据详情和合成步骤请查看后文。
3.遗漏变量分析
4.平行趋势检验
5.稳定单元处理效果假设检验
6.工具变量法
该论文研究过程中主要使用了两个工具变量(所在城市到杭州市的球面距离和到“八纵八横”政策节点城市距离),我们根据论文中的参考文献,找到了这两部分数据的原始信息,并进行这部分数据的收集整理,数据详情请阅读后文
(四)作用机制
1.数字基础设施有助于提高父代对子代对人力资本投资回报
2.数字基础设施减少了子代对父代社会资本继承
3.数字基础设施增加了子代的“市场运气”
(五)结论与政策含义
以上就是本篇论文的大致框架结构和内容,接下来给大家介绍重点内容我们收集整理的数据。
二、重要数据
该论文因为是和CFPS微观个体层面数据相结合,论文只提到了“宽带中国”政策相关的执行年份,研究样本大致上也是政策实施年份左右,即2013-2016年左右,政策变量的使用也是以地级市城市与个体进行匹配,我们收集整理了“宽带中国”政策实施的地级市数据,并考虑到大家会进行省级或地级市的其他层面研究,将数据区间进行了拓展,得到了2008年-2022年“宽带中国”政策地级市实施数据,同时论文中使用到了我们上述提到的两个工具变量数据,我们也进行了整理,同时论文研究过程中使用到了互联网发展指数的指标,我们也进行了收集整理,结合实际数据情况得到了2011-2021年地级市城市的互联网发展指标数据,方便大家研究。
(一)宽带中国政策原始数据
“宽带中国”政策名单是从2014年开始发布的,一共三个批次名单,时间区间为2014年-2016年,包含地级市、城市群、自治州以及县级市多种类型名单,其中长株潭城市群包括长沙市、株洲市以及湘潭市三个城市,名单中我们进行了拆分,我们收集整理名单数据,数据保留在“原始数据”表中,具体展示如下: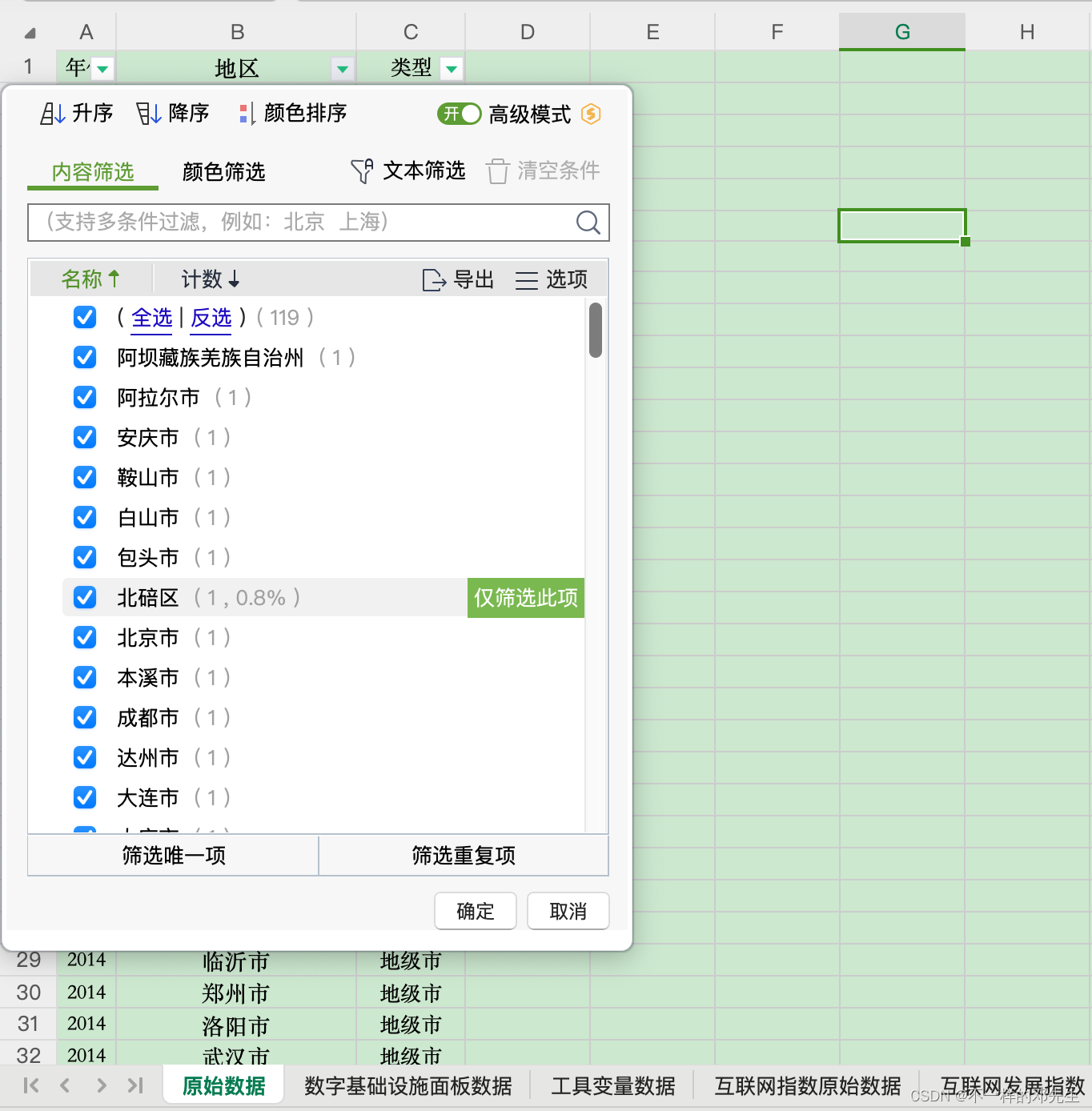
(二)宽带中国面板数据
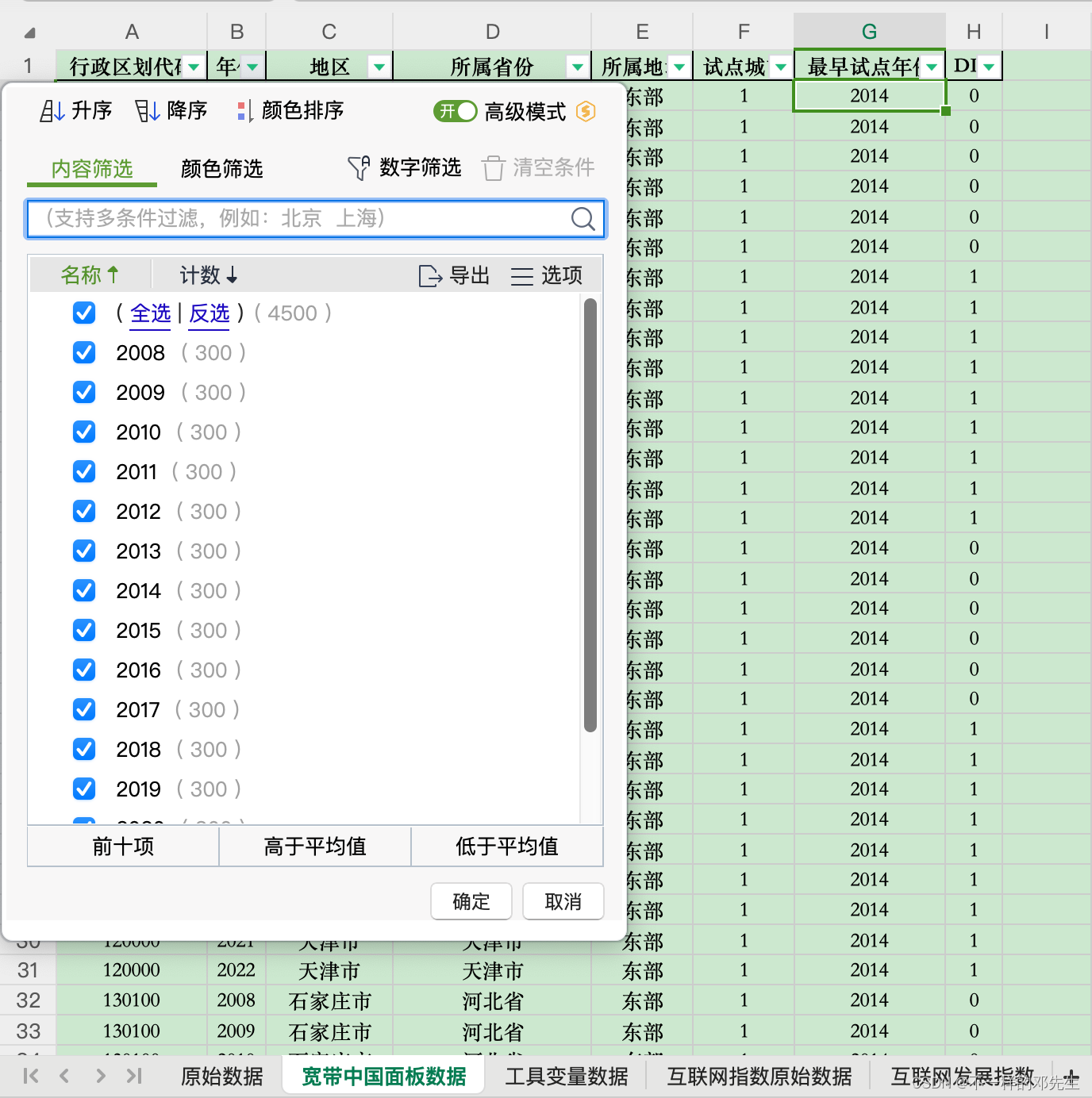
在原始名单基础上,我们将数据转换成了面板数据,其中,重庆市的试点都是辖区进行试点,我们考虑在地级市层面的研究应该将重庆市纳入处理组更为合理,同时我们将数据进行了延伸拓展,数据区间为2008-2022年,没有生成2023年的数据是因为大家在实际研究过程中2023年的其他数据经常会缺失,同时也不会延伸到最近年份进行研究,我们的数据是可以满足大家的实际研究需求的,大家不要盲目追求数据数量,寻找适合自己研究的数据最好,这一点我们会在将互联网发展指数的时候谈到这点,最终得到了2008年-2022年300个地级市层面面板数据,政策实施的虚拟变量保留在DID中,数据保存在“宽带中国面板数据”表中,数据展示如下:
(三)工具变量数据
论文在进行内生性检验的时候使用到了工具变量数据,我们找到了论文中提到到的参考文献,并根据原参考文献中使用的工具变量进行分析,即所在地到杭州市的球面距离(张勋等(2019))和 所在地到“八纵八横”光缆骨干网络节点城市的球面距离(田鸽和张勋(2022)),其中在《干线光缆传输网与中国信息网络城市节点体系》中讲到北京和南京是“八纵八横”光缆骨干网络节点城市,因此我们取所在地到北京和南京球面距离最小距离为该工具变量距离(论文作者回答),同时我们保存了到北京和南京的球面距离数据以及最终的最小距离数据,方便大家检查,最终得到了2008-2022年300个地级市数字基础设施工具变量面板数据,保存在“工具变量数据”表中,数据展示如下:

(四) 互联网指数原始数据
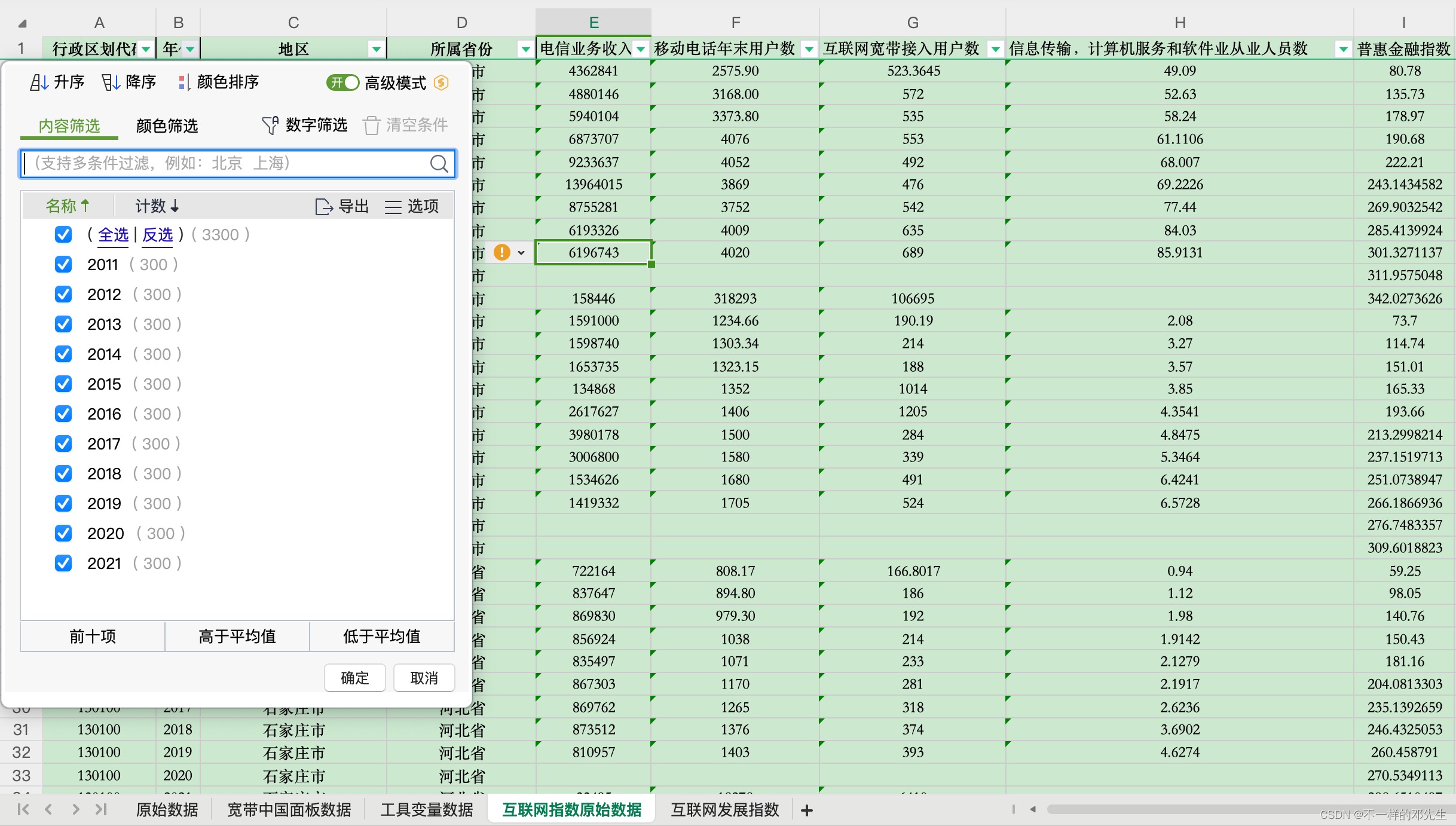
论文中使用到了互联网发展指数指标,该指标由移动电话用户数、互联网宽带接入用户数、在信息传输、计算机服务和软件业的就业人数、电信业务收入以及普惠金融指数等指标通过主成分分析得到,我们收集整理了这些数据,最终得到了2011-2021年互联网发展指数原始数据指标,数据中存在少量缺失值,我们对这些缺失值数据按照统计年鉴等数据源进行了核对,均为正常缺失,官方也没有公布,为什么我们的数据是从2011年开始的呢?是因为普惠金融指标是从2011年开始更新的,所以数据也只能从2011年开始,在这里我特地强调一下,目前市面上存在一些使用普惠金融指标进行合成的数据,最终的数据区间是从2000年开始的,这是非常严重的错误,他们常用的办法是将2011年之前的指标全部设置为0,不谈他们最终合成方法是否正确,连最基本的数据质量都无法保证,而且价格非常贵,动不动就70、80甚至上百,非常气愤,希望大家注意一下数据质量,不要被骗。原始数据保存在“互联网原始数据”表中,数据展示如下:
(五)互联网发展指数
在原始数据的基础上,我们按照要求采用主成分分析对数据进行合成,首先我们对缺失值数据进行了处理,对数据严重缺失的城市以及涉及撤销的城市,我们进行了剔除,剔除数据都是合理的,大家可以使用原始数据进行对照,剩余数据采用stata中线性插值的方法填充缺失值数据,填充结果均以“填充数据-”开头保存在相应的列中,我们对填充数据进行了核查,与数据原始趋势大致一致,说明填充没有什么问题,填充完成之后我们开始使用主成分分析进行指标合成,合成方法参考国内顶级期刊数量经济技术经济研究中《中国金融稳定指数构建、形势分析与预判》中采用的指标合成方法,使用stata完成指标合成,参考论文的主成分选择标准,根据PCA分析结果,我们确定选择为3个主成分。
同时,我们参考论文进行了KMO和Bartlett's 球形检验,检验结果说明,数据总体上适合进行主成分分析,检验结果如下:

最终我们开始进行指标合成,合成的结果存在负值,按照我们实际分析需求以及参考论文中的处理办法,将指标进行了归一化处理,映射到0-1区间上的正值数据,最终合成指标保存在“总互联网发展指数”列中,全部数据保存在“互联网发展指数”表中,如果大家选择我们的数据,还会将主成分分析的代码一起发送给大家,数据展示如下: 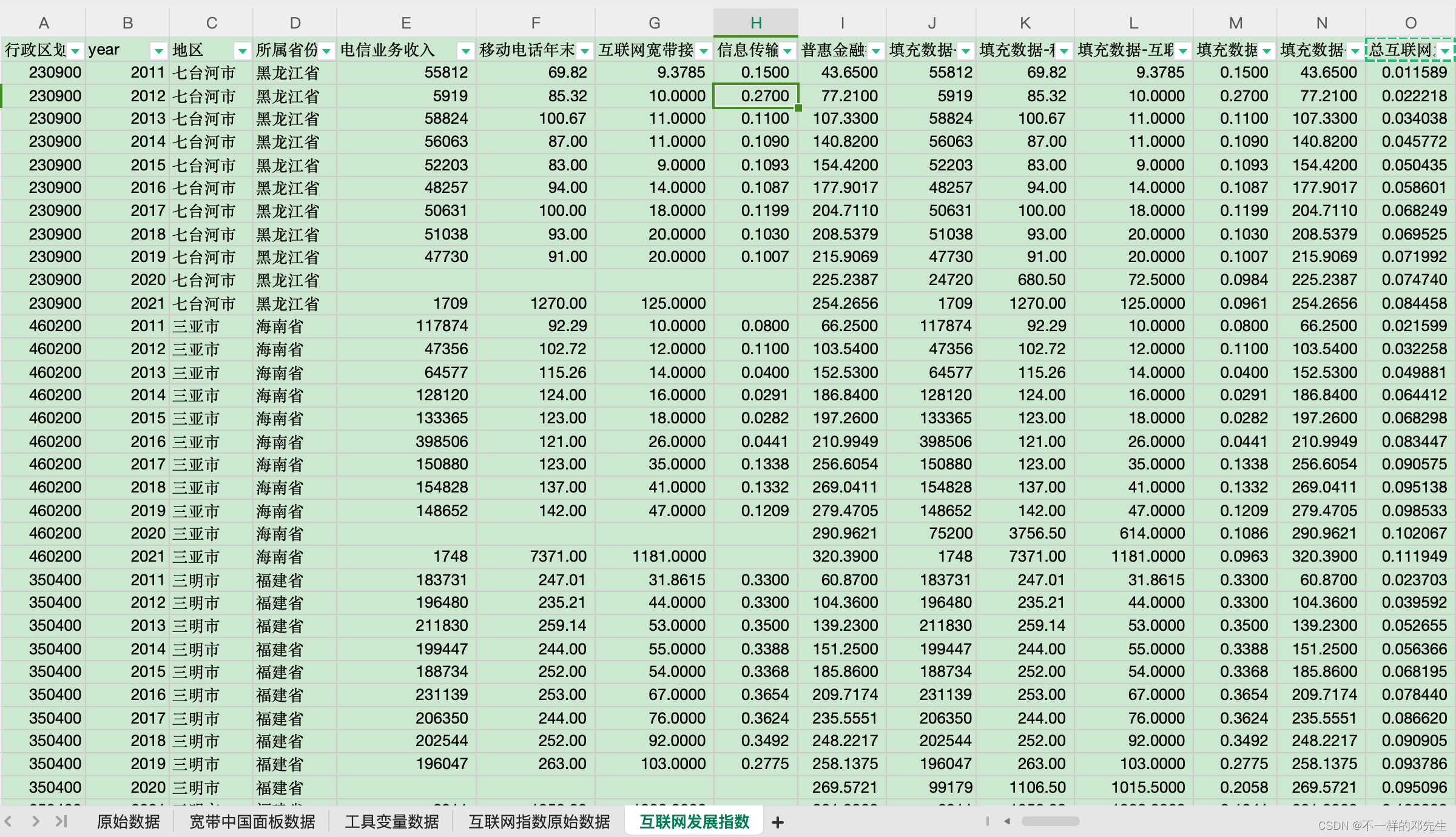
以上就是本次分享的全部内容,大家可以看到我们对分享的数据是十分认真和用心的,并且站在使用者的角度考虑,所以大家完全可以相信数据的质量,最后,数据在发布时间起24小时内通过关键词指示操作即可免费获取,关注公众号“明天科技屋”并回复数字关键词了解数据获取方式,该数据由明天科技屋一手整理,版权归明天科技屋所有,未经允许,不得用于商业盈利,否则将追随法律责任!!!