1. 前言
Embedding是深度学习领域一种常用的类别特征数值化方法。在自然语言处理领域,Embedding用于将对自然语言文本做tokenization后得到的tokens映射成实数域上的向量。
本文介绍Embedding的基本原理,将训练大语言模型文本数据对应的tokens转换成Embedding向量,介绍并实现OpenAI的GPT系列大语言模型中将tokens在文本数据中的位置编码成Embedding向量的方法。
2. Embedding
Embedding是指将类别特征(categorical feature)映射到连续向量空间中,即使用实数域上的向量表示类别特征。其中,向量的长度是超参数,必须人为设定。向量中每一个元素的值,均是模型的参数,必须从训练数据中学习获得,即通过大量数据训练,模型自动获得每一个类别特征该被表示成一个怎样的向量。
Deep Learning is all about “Embedding Everything”.
Embedding的核心思想是将离散对象映射到连续的向量空间中,其主要目的是将非数值类型的数据转换成神经网络可以处理的格式。
Embedding向量维度的设定并没有精确的理论可以指导,设定的原则是:Embedding向量表示的对象包含的信息越多,则Embedding向量维度应该越高;训练数据集越大,Embedding向量维度可以设置得更高。在大语言模型出现前,深度学习自然语言处理领域,一般Embedding向量的维度是8维(对于小型数据集)到1024维(对于超大型数据集)。更高维度得Embedding向量可以捕获特征对象之间更精细的关系,但是需要更多数据去学习,否则模型非常容易过拟合。GPT-2 small版本使用的Embedding向量维度是768,GPT-3 175B版本使用的Embedding向量维度是12288。
在自然语言处理领域,可以将一个单词或token映射成一个Embedding向量,也可以一个句子、一个文本段落或一整篇文档映射成一个向量。对句子或一段文本做Embedding是检索增强生成(RAG, retrieval-augmented generation)领域最常用的技术方法,RAG是目前缓解大语言模型幻觉现象最有效的技术方法之一。
将一个单词或token映射成一个Embedding向量,只需要构造一个token ID到向量的映射表。将一个句子、一个文本段落或一整篇文档映射成一个向量,往往需要使用一个神经网络模型。模型的输入是一段文本的tokens对应的token ID,输出是一个向量。
以前比较流行的学习一个单词对应的Embedding向量的方法是Word2Vec。Word2Vec的主要思想是具有相同上下文的单词一般有相似的含义,因此可以构造一个给定单词的上下文预测任务来学习单词对应的Embedding向量。如下图所示,如果将单词对应的Embedding向量维度设置为2,可以发现具有相似属性的单词对应的Embedding向量在向量空间中的距离更近,反之则更远。

在大语言模型中不会使用Word2Vec等算法训练生成的Embedding向量,而是直接使用torch.nn.Embedding随机初始化各个tokens对应的Embedding向量,并在训练阶段更新这些Embedding向量中各个元素的值。将各个tokens对应的Embedding向量作为大语言模型的参数,可以确保学到的Embedding向量更加适合当前任务。
在自然语言处理项目实践中,如果训练数据集足够大,一般会使用上述随机初始化并训练Embedding向量的方法,如果训练数据集不够大,则更推荐使用在大数据集上预训练生成的Embedding向量,或者可以直接将预训练模型作为特征提取器,在其后接一个面向下游任务的输出层,只训练输出层参数。
3. 将Tokens转换成Embedding向量
对训练大语言模型的自然语言文本做tokenization,可以将文本转换成一系列tokens。通过词汇表(vocabulary)可以将tokens转换成token IDs。torch.nn.Embedding层可以将token ID映射成Embedding向量。
假设词汇表中共包含6个不同的tokens,每个token对应的Embedding向量维度设置为3。可以使用如下代码随机初始化各个tokens对应的Embedding向量:
import torchtorch.manual_seed(123)input_ids = torch.tensor([5, 1, 3, 2])
vocabulary_size = 6
embedding_dim = 3token_embedding_layer = torch.nn.Embedding(vocabulary_size, embedding_dim)
print(token_embedding_layer.weight)
执行上面代码,打印结果如下:
Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],[ 0.9178, 1.5810, 1.3010],[ 1.2753, -0.2010, -0.1606],[-0.4015, 0.9666, -1.1481],[-1.1589, 0.3255, -0.6315],[-2.8400, -0.7849, -1.4096]], requires_grad=True)
Embedding层的权重(weight)矩阵是一个二维的张量,矩阵的行数为6,列数为3,每一行是一个3维向量。词汇表中共6个不同的tokens,第1个token对应的Embedding向量即为权重矩阵的第1行,第2个token对应的Embedding向量即为权重矩阵的第2行。依次类推,第6个token对应的Embedding向量为权重矩阵第6行的向量。权重矩阵是随机初始化的,会在模型训练期间使用随机梯度下降算法更新。
假设输入文本对应的token ID列表为[5, 1, 3, 2],可以使用如下代码,将文本对应的token IDs全部转换成Embedding向量:
input_ids = torch.tensor([5, 1, 3, 2])
token_embeddings = token_embedding_layer(input_ids)
print(token_embeddings)
执行上面代码,打印结果如下:
tensor([[-2.8400, -0.7849, -1.4096],[ 0.9178, 1.5810, 1.3010],[-0.4015, 0.9666, -1.1481],[ 1.2753, -0.2010, -0.1606]], grad_fn=<EmbeddingBackward0>)
将文本对应的4个token IDs输入Embedding层,输出一个4行3列的张量矩阵。可以观察到矩阵的第1行即为Embedding层权重矩阵第6行对应的向量,第2行即为Embedding层权重矩阵第2行对应的向量,第3行即为Embedding层权重矩阵第4行对应的向量,第4行即为Embedding层权重矩阵第3行对应的向量。
如下图所示,输入的token ID列表为[5, 1, 3, 2],输出的张量矩阵分别由Embedding层权重矩阵的第6、2、4、3行的向量构成。由此可见,Embedding层本质上是初始化了一个token ID到Embedding向量的映射,将token ID列表输入Embedding层,会依次索引不同token ID对应的Embedding向量,返回一个Embedding向量矩阵。

4. 位置编码(Positional Encoding)
Embedding层构造了词汇表中全部token IDs到Embedding向量的映射,输入文本数据对应的token ID列表,Embedding层输出相应Embedding向量。Embedding向量与token ID是一一对应关系,token ID列表中不同位置的相同token ID对应的Embedding向量相同,即Embedding层输出的Embedding向量不包含token的位置信息。

大语言模型使用自注意力机制(self-attention)处理自然语言文本,其神经网络不具备循环结构。自注意力机制无法捕捉输入文本中的token序列位置信息,将两个含义不同的文本序列“你爸妈对我的看法”和“我爸妈对你的看法”输入自注意力层,生成的用于预测下一个字的输出向量会完全相同。
后续文章将详细介绍自注意力机制理论原理,提前了解自注意力机制无法捕捉输入文本中的token序列位置信息的原因,可以参见本人写的博客文章BERT与ERNIE - 4. Self-Attention层无法捕捉句子中词序信息原因。
在输入文本对应token的Embedding向量中添加token位置信息的方法有两种:相对位置编码(relative positional embeddings)和绝对位置编码(absolute positional embeddings)。
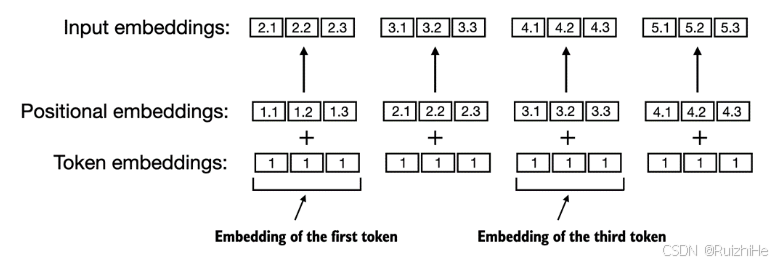
如下图所示,绝对位置编码直接将输入文本token的绝对位置编码成Embedding向量。假设大语言模型支持的最大输入token数量为 k k k,则总共包含 k k k个不同的待学习的位置Embedding向量。将token对应的Embedding向量与token所在位置对应的Embedding向量相加,生成最终输入大语言模型的Embedding向量。
相对位置编码并不将输入token的绝对位置编码成Embedding向量,而是将不同token之间的相对位置编码成Embedding向量。假设设定的最大输入token数量为 k k k,则总共包含 2 k − 1 2k-1 2k−1个不同的待学习的相对位置Embedding向量。
2 k − 1 2k-1 2k−1个不同的带学习的位置Embedding向量分别为: e − k + 1 , e − k + 2 , ⋯ , e − 1 , e 0 , e 1 , ⋯ , e i , ⋯ , e k − 2 , e k − 1 e_{-k+1}, e_{-k+2}, \cdots, e_{-1}, e_0, e_1, \cdots, e_i, \cdots, e_{k-2}, e_{k-1} e−k+1,e−k+2,⋯,e−1,e0,e1,⋯,ei,⋯,ek−2,ek−1,其中 i i i表示与当前token的相对距离为多少个token。
除了上述两种将token位置编码成Embedding向量的位置编码方法,还有许多其他类型的位置编码方法。不管那种位置编码方法,都是为了使大语言模型具备理解token之间顺序及位置关系的能力。OpenAI的GPT系列大语言模型使用的是上述绝对位置编码方法。
假设大语言模型支持的最大输入token数量为8,则可以使用如下代码随机初始化各个位置对应的Embedding向量,并生成输入文本对应的token ID列表中各个token位置对应的Embedding向量:
context_len = 8position_embedding_layer = torch.nn.Embedding(context_len, embedding_dim)
position_embeddings = position_embedding_layer(torch.arange(input_ids.shape[0]))
print(position_embeddings)
执行上面代码,打印结果如下:
tensor([[-2.1338, 1.0524, -0.3885],[-0.9343, -0.4991, -1.0867],[ 0.9624, 0.2492, -0.9133],[-0.4204, 1.3111, -0.2199]], grad_fn=<EmbeddingBackward0>)
将输入文本对应的token_embeddings与position_embeddings相加,即可生成最终输入大语言模型的Embedding向量:
input_embeddings = token_embeddings + position_embeddings
print(input_embeddings)
执行上面代码,打印结果如下:
tensor([[-4.9737, 0.2675, -1.7981],[-0.0166, 1.0818, 0.2144],[ 0.5609, 1.2158, -2.0615],[ 0.8549, 1.1101, -0.3805]], grad_fn=<AddBackward0>)
5. 结束语
对自然语言文本数据做tokenization,可以将文本分割成一连串tokens,并通过词汇表映射成token ID列表。使用Embedding层将token IDs及其位置转换成相同维度的Embedding向量,token对应的Embedding向量与其位置对应的Embedding向量相加,最终生成输入大语言模型的Embedding向量。
接下来,我们该去了解注意力机制了!
![[leetcode]kth-smallest-element-in-a-sorted-matrix 有序矩阵中第k小元素](https://i-blog.csdnimg.cn/direct/5fdc8a3f0a5e434f9d71c8373cd18bd7.png)