终于,业内迎来了首个全链条大模型开源体系。
大模型领域,有人探索前沿技术,有人在加速落地,也有人正在推动整个社区进步。
就在近日,AI 社区迎来首个统一的全链条贯穿的大模型开源体系。
虽然社区有LLaMA等影响力较大的开源模型,但由于许可证限制无法商用。InternLM-7B 除了向学术研究完全开放之外,也支持免费商用授权,是国内首个可免费商用的具备完整工具链的多语言大模型,通过开源开放惠及更多开发者和企业,赋能产业发展。

WAIC 上书生・浦语的发布。
今年世界人工智能大会 WAIC 上,上个月初「高考成绩」超越 ChatGPT 的「书生」大模型来了次重大升级。
在 7 月 6 日的活动中,上海 AI 实验室与商汤联合香港中文大学、复旦大学、上海交通大学及清华大学共同发布了全新升级的「书生通用大模型体系」,包括书生・多模态、书生・浦语和书生・天际三大基础模型。其中面向 NLP 领域的书生・浦语语言大模型迎来了 104B 的高性能版和 7B 的轻量级版。
相较初始模型,104B 的书生・浦语全面升级,高质量语料从 1.6 万亿 token 增至了 1.8 万亿,语境窗口长度从 2K 增至了 8K,支持语言达 20 多种,35 个评测集上超越 ChatGPT。这使得书生・浦语成为国内首个支持 8K 语境长度的千亿参数多语种大模型。
而在全面升级的同时,更值得关注的是书生・浦语在开源上的一系列动作。
此次书生・浦语将 7B 的轻量级版 InternLM-7B 正式开源,并推出首个面向大模型研发与应用的全链条开源体系,贯穿数据、预训练、微调、部署和评测五大环节。其中 InternLM-7B 是此次开源体系的核心和基座模型,五大环节紧紧围绕大模型开发展开。
上海 AI 实验室开放其整套基础模型和开发体系。大模型的研究,第一次有了一套开源的、靠谱的全链条工具。
模型 + 全套工具,开源真正实现「彻底」
此前,AWS 等国内外公司纷纷推出了基础大模型技术平台。基于大厂的能力,人们可以构建起生成式 AI 应用。相比之下,基于上海 AI 实验室的基座模型和全链条开源体系,企业、研究机构/团队既可以构建先进的应用,也可以深入开发打造各自垂直领域的大模型。
在上海 AI 实验室看来,基础大模型是进一步创新的良好开端。「书生」提供的并非单个的大模型,而是一整套基座模型体系,在全链条开源体系加持下,为学界和业界提供了坚实的底座和成长的土壤,从底层支撑起 AI 社区的成长,并且与更多的探索者共同建设「枝繁叶茂」的生态。

因此,就此次书生・浦语的开源而言,它是一套系统性工程,旨在推动行业进步,让一线开发者更快获取先进理念和工具。用「全方位开源开放」来形容可以说名副其实,模型、数据、工具和评测应有尽有。相比业界类似大模型平台,书生・浦语首个实现了从数据到预训练、微调,再到部署和评测全链条开源。
轻量化模型,性能业界最强
书生・浦语的 7B 轻量级版 InternLM-7B 不仅正式开源,还免费提供商用。作为书生・浦语开源体系中的基座模型,它为上海 AI 实验室未来开源更大参数的模型做了一次探索性尝试。
我们了解到,InternLM-7B 为实用场景量身定制,使用上万亿高质量语料来训练,建立起了超强知识体系。另外提供多功能工具集,使用户可以灵活自主地搭建流程。目前 GitHub star 量已经达到了 1.5K。
开源地址:
https://github.com/InternLM
InternLM-7B 的性能表现如何呢?上海 AI 实验室给出的答案是:在同等参数量级的情况下全面领先国内外现有开源模型。
我们用数据来说话。对 InternLM-7B 的全面评测从学科综合能力、语言能力、知识储备能力、理解能力和推理能力五大维度展开,结果在包含 40 个评测集的评测中展现出卓越和均衡的性能,并实现全面超越。
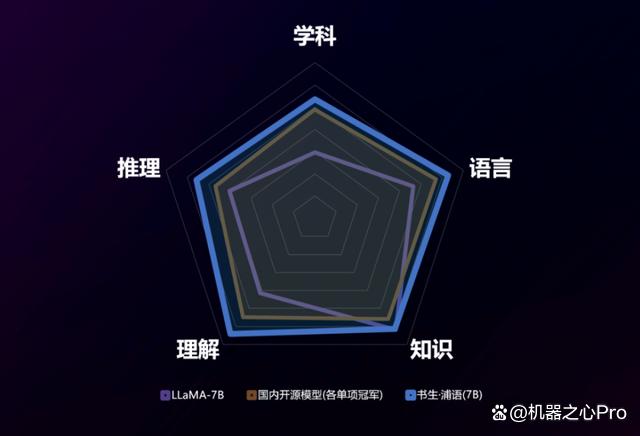
下图展示了在几个重点评测集上,InternLM-7B 与国内外代表性 7B 开源模型(如 LLaMA-7B)的比较。可以看到,InternLM-7B 全面胜出,在 CEval、MMLU 这两个评价语言模型的广泛基准上分别取得了 53.25 和 50.8 的高分,大幅领先目前业内最优的开源模型。
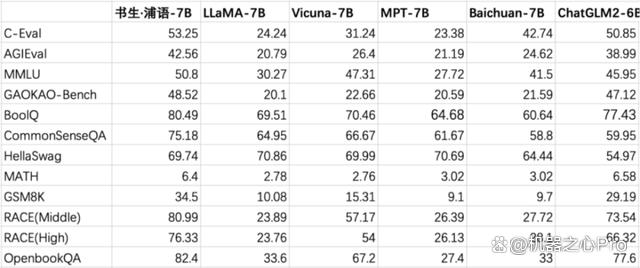
InternLM-7B 在开放评测平台 OpenCompass 的比较结果。
书生是如何做到的?在接受机器之心专访时,上海 AI 实验室林达华教授向我们介绍了致胜之道。
与以往在单项或数项基准上达到高水平的模型不同,InternLM-7B 是一个基座模型,它不是针对某个特定任务或领域,而是面向广泛的领域提供比较强大和均衡的基础能力。因而强调各方面能力的均衡是它的一大特点。
为了实现均衡且强大的能力,InternLM-7B 在训练和评估过程中使用了创新的动态调整模式:在每训练一个短的阶段之后,便对整个模型全面评估,并根据评估结果及时调整下一阶段训练数据分布。通过这套敏捷的闭环方式,模型在成长过程中始终保持能力均衡,不会因数据配比不合理而导致偏科。
同时,InternLM-7B 在微调体系上也有明显升级,使用了更有效的微调手段,保证模型的行为更加可靠。
除了以上模型技术层面的升级,InternLM-7B 还具备可编程的通用工具调用能力。以 ChatGPT 为例,大模型可在解方程、信息查询等简单任务上调用工具来实现更准确有效的结果,但在复杂任务上需要调用更多机制才能解决问题。
InternLM-7B 具备了这种通用工具调用能力,使模型在需要工具的时候自动编写一段 Python 程序,以综合调用多种能力,将得到的结果糅合到回答过程,大幅拓展模型能力。
正是在训练 - 评估 - 训练数据分布调整闭环、微调以及工具调用等多个方面的技术创新,才让 InternLM-7B 领跑所有同量级开源模型变成了可能。
大模型开源,就需要全链条
在书生・浦语全链条开源体系中,不仅囊括了丰富多元的训练数据、性能先进的训练与推理框架、灵活易用的微调与部署工具链,还有从非商业机构的更纯粹学术和中立视角出发构建的 OpenCompass 开放评测体系。
与同类型开源体系相比,书生・浦语的最大特点体现在链条的「长」。竞品工具链可能会覆盖从微调到部署等少量环节,但书生・浦语将数据、预训练框架、整个评测体系开源了出来。而且链条中一个环节到另一个环节,所有格式全部对齐,无缝衔接。
上海 AI 实验室围绕书生・浦语大模型打造了五位一体的技术内核。除了大模型本身,值得关注的还有预训练环节开源的面向轻量级语言大模型训练的训练框架 InternLM-Train 以及评测环节的开放评测平台 OpenCompass。
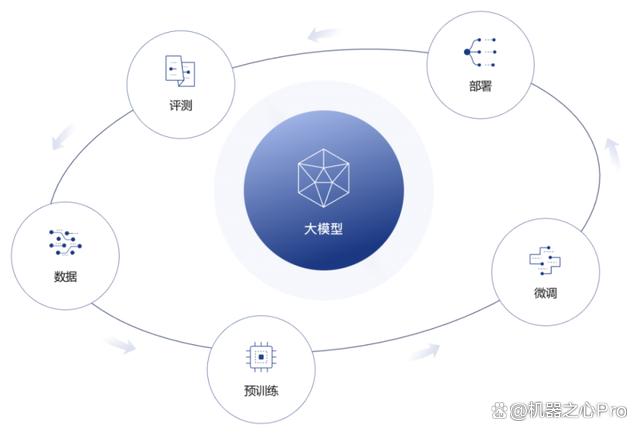
书生・浦语全链条工具体系。图源:https://intern-ai.org.cn/home
我们知道,在现有 AI 大模型开发范式中,预训练 + 微调是主流。可见预训练对于大模型的重要性,很大程度上决定了模型任务效果。而其中底层的预训练框架要在能耗、效率、成本等方面尽可能做到节能、高效、低成本,因此框架的创新势在必行。
书生・浦语开源了训练框架 InternLM-Train。一方面深度整合了 Transformer 模型算子,使得训练效率得到提升。一方面提出了独特的 Hybrid Zero 技术,实现了计算和通信的高效重叠,训练过程中的跨节点通信流量大大降低。
得益于极致的性能优化,这套开源的体系实现了千卡并行计算的高效率。InternLM-Train 支持从 8 卡到 1024 卡的计算环境中高效训练 InternLM-7B 或者量级相仿的模型,训练性能达到了行业领先水平。千卡规模下的加速效率更是高达 90 %,训练吞吐超过 180Tflop,平均单卡每秒处理 token 也超过 3600。
如果说预训练决定了大模型的「成色」,评测则是校验大模型成色的关键一环。当前由于语言大模型的能力边界极广,很难形成全面、整体的评价,因而需要在开放环境中逐渐迭代和沉淀。
书生・浦语开源体系上线了 OpenCompass 开放评测体系,更纯粹学术和中立视角之外,它的另一大特点是基准「全」。除了自己的一套评测基准,OpenCompass 还整合了社区主流的几十套基准,未来还将接纳更多,从而让开源模型更充分地彼此较量。
图源:https://opencompass.org.cn/
具体地,OpenCompass 具有六大核心亮点。从模型评测框架来看,它开源可复现;从模型种类来看,它支持 Hugging Face 模型、API 模型和自定义开源模型等各类模型的一站式测评,比如 LLaMA、Vicuna、MPT、ChatGPT 等。InternLM-7B 正是在该平台上完成评测。
从能力维度来看,它提供了学科综合、语言能力、知识能力、理解能力、推理能力和安全性六大维度。同时提供这些能力维度下的 40+ 数据集、30 万道题目,评估更全面。
林达华教授认为,能力维度的广度和复杂度是模型评测面对的最大挑战。一方面要充分考虑如何从不同的维度进行评价,一方面当要评测的指标变多的时候,还要兼顾如何以负担得起的方式去评测。
此外,OpenCompass 非常高效,一行命令实现任务分割和分布式评测,数小时内完成千亿模型全量评测;评测范式多样化,支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板轻松激发各种模型最大性能;拓展性极强,轻松增加新模型或数据集、甚至可以接入新的集群管理系统。
目前,OpenCompass 上线了 NLP 模型的评测,也即将支持多模态模型的评测。
随着 OpenCompass 平台的影响力增加,上海 AI 实验室希望对于大模型基准的评测也会对整个领域起到带动作用。与此同时,在构建 AI 标准化的大模型专题组中,上海 AI 实验室也与很多厂商形成了良好的合作关系。

在大模型快速演进的关键时期,标准制定与实施是推动产业进步的现实需求,也将为产业的可持续发展指明方向。
林达华教授表示:「创新是人工智能技术进步的源动力,而基座模型和相关的工具体系则是大模型创新的技术基石。通过此次书生・浦语的高质量全方位开源开放,我们希望可以助力大模型的创新和应用,让更多的领域和行业可以受惠于大模型变革的浪潮。」
做真正有影响力的工作
值得一提的是,上海AI 实验室成立的时间并不长——成立于 2020 年 7 月。作为一个新型研发机构,其主要开展重要基础理论和关键核心技术。得益于其原创性、前瞻性的科研布局,以及强大的科研团队,实验室近期在多个关键领域实现重大突破。
「我们坚持上下游协同,做出的大模型第一时间在团队中进行分享,在应用中得到反馈,进而持续迭代,」林达华介绍称。
上海 AI 实验室的技术领先,还在于做好三个方面的事:不设定发表论文或盈利的 KPI,做真正前沿有影响力的工作;开放创新空间,鼓励团队间积极交流,勇于尝试不同的方向与想法;最后,实验室为研究团队提供了海量数据和算力作为支持。
此次书生・浦语的开源体系降低了大模型技术探索和落地的门槛,对于学界和业界而言意义重大,帮助更多研究结构和企业省去了基础模型构建的步骤,他们可以在已有的强大模型与工具体系的基础上继续演进,实现创新。
未来,上海 AI 实验室还将基于「书生・浦语」,在基础模型和应用拓展方面进行探索,努力构建适用于关键领域落地的基础模型。
书生开源体系可以大幅降低大模型技术探索和落地的门槛,如果你感兴趣,欢迎来试试。
书生官网链接:
https://intern-ai.org.cn/home



















