前言
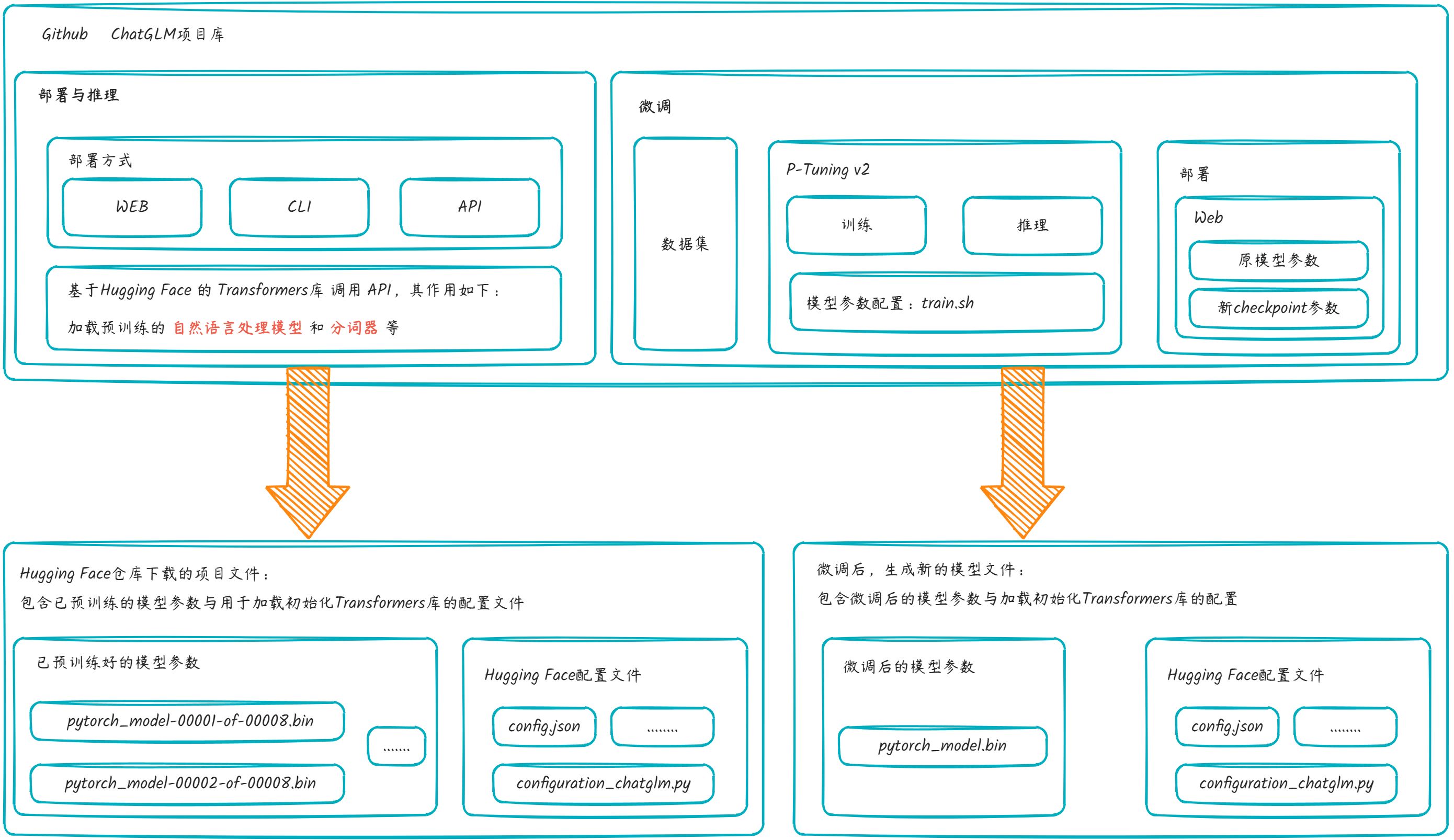
ChatGLM的部署,主要是两个步骤:
- 在Github上下载chatglm的库文件
- 在Hugging Face上下载模型参数与配置文件
ChatGLM包
从Github上看ChatGLM项目文件的结构来看,仅仅是包含三种部署方式的py代码与微调的py代码
而相关的实现细节,比如神经网络、激活函数、损失函数等具体的实现,并不在该项目源码中。
不管以哪种方式部署,最核心就是三句代码,其作用是引入模型参数,初始化transformers配置;以web部署的方式为例:
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()// 引入Gradio,实现web方式的使用// 调用模型方法,开始进行对话推理
xx = model.stream_chat(xxxx);web的调用是基于Gradio;
api的调用是基于fastapi;
cli的调用是基于python解释器;
Hugging Face
Hugging Face平台的模型库如下:
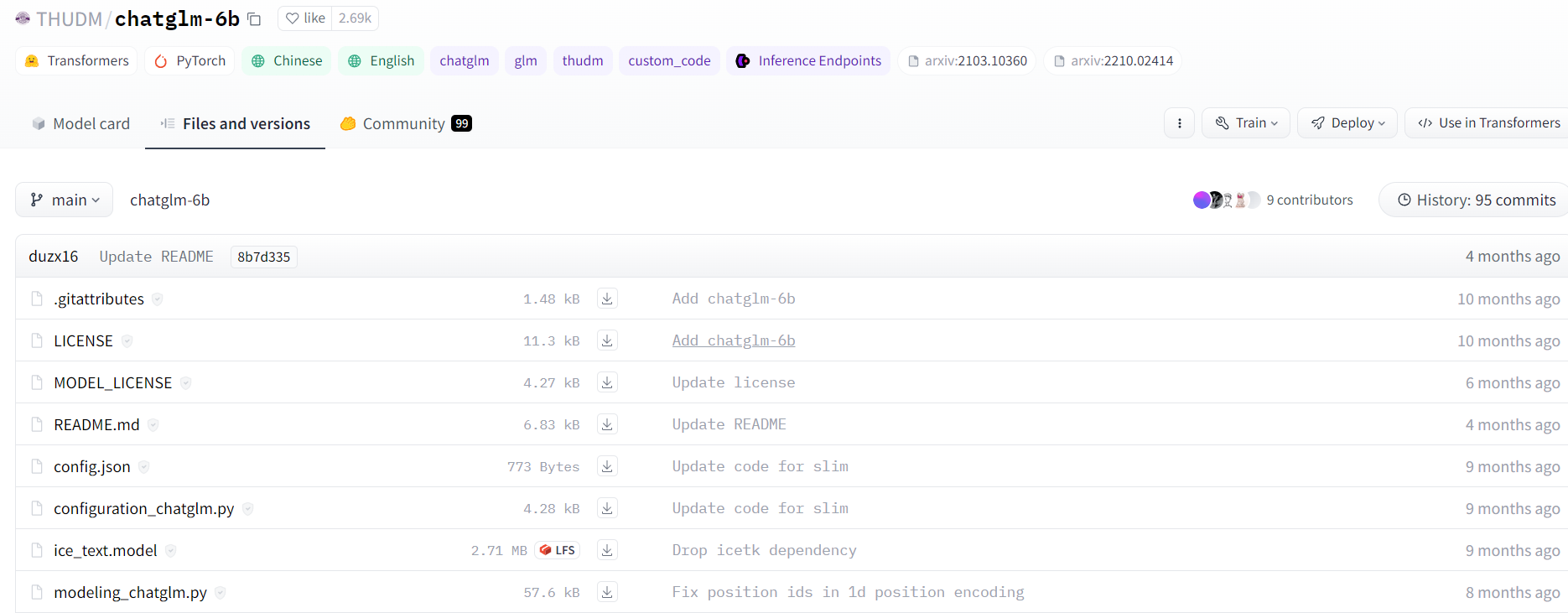
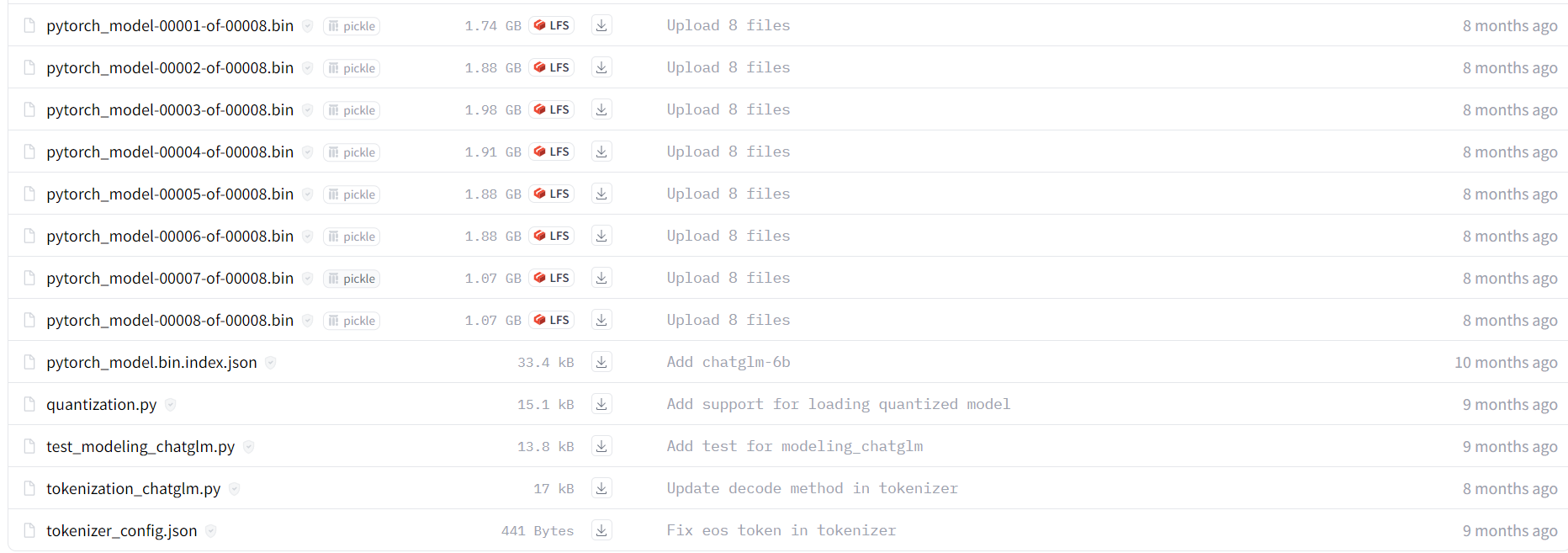
除去与训练后的模型参数(xxx.bin)外,其余的文件是huggingface的文件结构。
微调
微调的解决方案一般是P-Tuning或LoRA;ChatGLM-6B是基于P-Tuning v2实现的微调,P-Tuning v2是基于连续提示(continuous prompts)的思想。微调会生成新的模型参数文件,也称为checkpoint文件。
微调时可以选择全参数微调或是部分参数微调,其流程是训练+推理。训练生成新的checkpoint文件(模型参数);推理则是加载模型参数文件。
训练前,需要调整参数,一般修改train.sh脚本文件就行。
推理时,加载原模型文件与微调后生成的checkpoint文件。还是通过那三句代码。
输出的checkpoint文件如下:
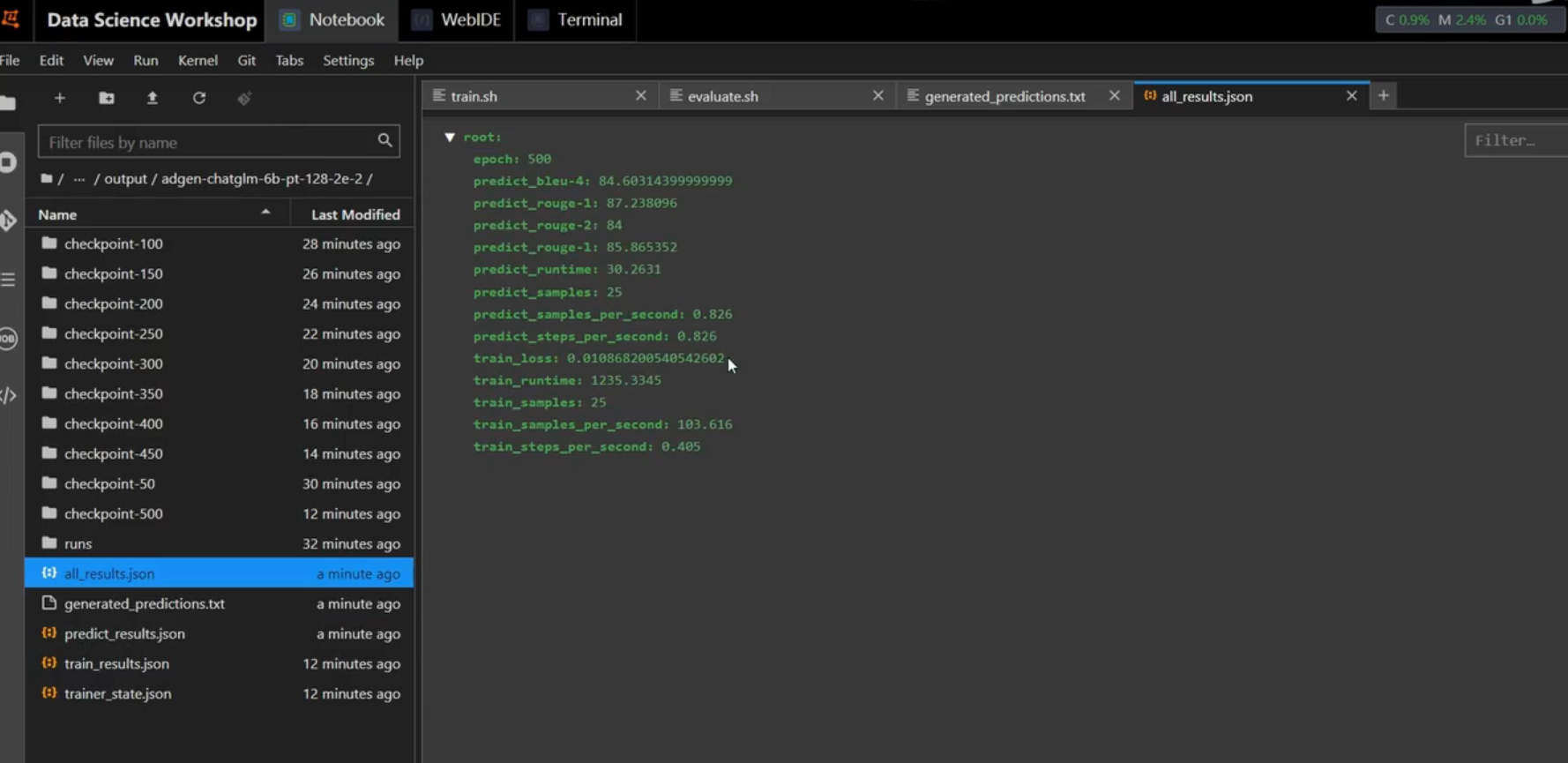
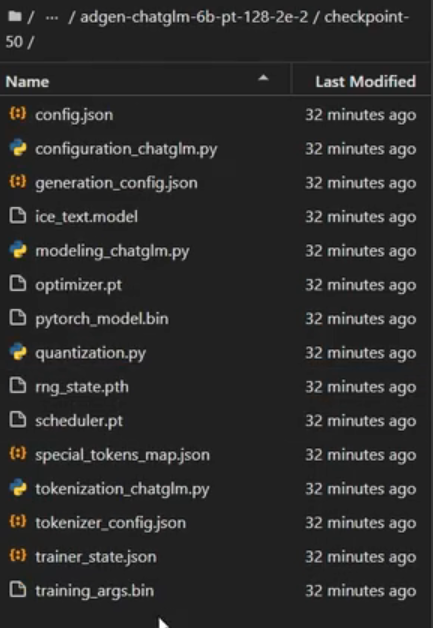
checkpoint文件夹内的文件如下:
transformers的联系
目前的模型,都会对接到Hugging Face平台的transformers库中,通过transformers库来管控大模型。所以在推理阶段通过三句代码就能调用AI模型。在微调阶段,生成的checkpoint文件中,其结构是Hugging Face平台的文件结构,包含transformers的相关配置及初始化信息。
总结
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】





![[极客大挑战 2019]PHP1](https://i-blog.csdnimg.cn/direct/7eb250f819704004a8eb3c0693821014.png)