论文:An image is worth 16x16 words: Transformers for image recognition at scale
作者:Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
机构:谷歌研究院
链接:https://arxiv.org/abs/2010.11929#
代码:https://github.com/google-research/vision_transformer
文章目录
- 1、算法概述
- 2、ViT细节
- 2.1 模型设计
- 2.2 微调和更高的分辨率
- 3、实验
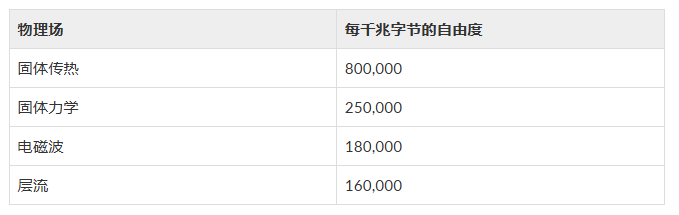
- 3.1 ViT和其它SOTA模型性能对比
- 3.2 数据集大小的重要性
1、算法概述
Transformer在NLP领域应用的风生水起,但是在视觉领域还没有得到大量应用,作者尝试尽可能少的改变transformer结构,让其应用在图像任务上。为此,作者将图像分割成小块,并将这些小块的线性嵌入序列作为transformer的输入。图像块的处理方式与NLP中token处理方式相同。作者以监督的方式对模型进行图像分类训练。
作者在中等规模的数据集ImageNet上训练模型,最后得到的结果比ResNets还差一点。作者把这个结果归因于Transformer结构缺乏归纳偏置(inductive biases),这个归纳偏置也可看作先验知识,这是CNN结构先天具备的,比如平移不变性和局部性。所以,在数据量不足的情况下,Transformer不能很好的完成泛化。然而,如果模型在更大的数据集(14M-300M图像)上训练,作者发现大规模训练胜过归纳偏见,ViT能达到CNN结构的 state of the art结果。
2、ViT细节
在模型设计中,作者尽可能地遵循原始Transformer结构,力求直接沿用NLP中的Transformer框架。
2.1 模型设计
Vit结构如下图所示:

由于transformer最开始是处理NLP的结构,它接收的输入是一维的token embedding序列。对于二维的图像,就需要把二维变成一维了,作者将图像x∈RHxWxC变成了N个拉平的图像块的序列xp∈RNx(PxPxC),这里H和W代表原始输入图像的高和宽,C代表通道数,(P,P)是切分成的图像块的大小,N=HW/P2代表图像块数量。Transformer在其所有层中使用恒定的潜在向量长度为D,因此作者将按照下面公式1将patch拉平后并使用可训练的线性投影映射到D维。作者将该投影的输出称为patch embedding。
和原始Transformer在NLP中的应用一样,这里也需要位置嵌入,作者将位置嵌入添加到patch embedding中以保留位置信息。作者通过实验得出使用标准的可学习的1D位置嵌入就可以了,两者以相加的方式,而非concat方式得到的嵌入向量序列作为Transformer编码器的输入。
在每个Block之前应用层规范化(Layernorm, LN),在每个Block之后应用残差连接。MLP结果包含两个全连接层,每个全连接层后面接了GELU激活层。

关于归纳偏置: Transformer比CNN具有更少的图像特定的感应偏置。在CNN中,局部性、二维邻域结构和平移等方差被嵌入到整个模型的每一层中。在ViT中,只有MLP层是局部的,在平移上是等变的,而自注意力层是全局的。其次,ViT中二维邻域结构的使用也非常少,在模型开始时将图像切割成小块,在微调时调整不同分辨率图像的位置嵌入。除此之外,初始化时的位置嵌入不携带关于patch的二维位置信息,所有patch之间的空间关系都需要从头学习。
混合结构(Hybrid Architecture),也就是CNN Feature+Transformer: 这有点像检测中DETR的思路,即Transformer接收的输入是CNN得到的特征图拉平的。在特殊情况下,patch的空间大小可以是1x1,这意味着输入序列是通过简单地将feature map的空间维度平坦化并投影到Transformer维度来获得的。
2.2 微调和更高的分辨率
作者在大型数据集上预训练ViT模型,然后在小的下游任务上进行微调。与预训练相比,在更高分辨率下进行微调通常能带来有益效果。当输入更高分辨率的图像时,作者保持patch大小不变,从而获得更大的有效序列长度。ViT可以处理任意序列长度(直到内存限制),但是,预训练的位置嵌入可能不再有意义。因此,我们根据预训练的位置嵌入在原始图像中的位置对其进行二维插值。请注意,此分辨率调整和补丁提取是将图像的2D结构的感应偏置手动注入ViT的唯一点。
3、实验
作者评估了ResNet、Vision Transformer (ViT)和hybrid(混合模型)的表示学习能力。为了了解每个模型的数据需求,作者在不同大小的数据集上进行预训练,并评估许多基准任务。当考虑到预训练模型的计算成本时,ViT表现非常好,以较低的预训练成本在大多数识别基准上达到最先进的水平。
数据集设置: 为了探索模型的可扩展性,作者用了ILSVRC-2012 ImageNet,它包含1000个类别和130万张图片;另一个是ImageNet-21k数据集有21000个类别和1400万张图像;JFT数据集包含18000个类别和303百万张高分辨率图像。同时参考BiT,删除预训练数据集中和下游任务测试集中重复的数据。下游数据集包括:ImageNet(on the original validation labels),ImageNet (on the cleaned-up ReaL labels ),CIFAR-10/100,Oxford-IIIT Pets,Oxford Flowers-102,VTAB (19 tasks)
模型变体: 作者参考BERT,也设计了“Base”,“Large”,“Huge”三种变体,具体参数设置如下表:

作者在文中以变体名称加patch大小来标记,例如:ViT-L/16是指具有16×16输入patch大小的“Large”变体。请注意,Transformer的序列长度与patch大小的平方成反比,因此具有较小patch大小的模型在计算上更昂贵。
3.1 ViT和其它SOTA模型性能对比

可以看到在JFT数据集上预训练的ViT模型,迁移到下游任务后,表现要好于基于ResNet的BiT和基于EfficientNet的Noisy Student,且需要更少的预训练时间。
3.2 数据集大小的重要性

左图(Figure 3)显示出在规模不大的数据集上(ImageNet),BiT能超越ViT的效果,但随着数据集规模增大,ViT的性能逐渐表现出来。
右图(Figure 4)显示模型规模与数据集数量的关系,对于像ViT-b(ViT-B所有隐藏层减半)和ResNet50x1这样的小规模模型,随着数据量的增加,性能很容易到达瓶颈,对于ViT-L规模模型,性能可以随着数据量的增加一直提升。