先赞后看,Java进阶马上一大半
海外geeksforgeeks网站画了这么一张Set集合的层次结构图,基本把Set集合涉及的常用类关系给标明了。

大家好,我是南哥。
一个Java学习与进阶的领路人,相信对你通关面试、拿下Offer进入心心念念的公司有所帮助。
⭐⭐⭐本文收录在全网独一份的《JavaProGuide》:https://github.com/hdgaadd/JavaProGuide
1. Set集合
1.1 HashSet
面试官:你说说对HashSet的理解?
Set集合区别于其他三大集合的重要特性就是元素具有唯一性,南友们记不住这个特性的话,有个易记的方法。Set集合为什么要叫Set呢?因为Set集合的命名取自于我们小学数学里的集合论(Set Theory),数学集合一个很重要的概念就是每个元素的值都互不相同。
Set集合常见的有实例有:HashSet、LinkedHashSet、TreeSet,南哥先缕一缕HashSet。
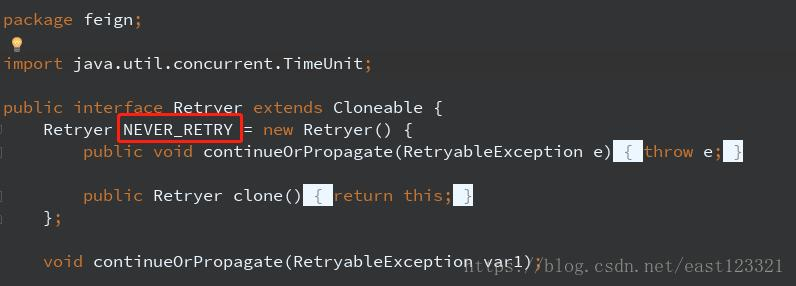
// HashSet类源码
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable {...}
HashSet底层实现其实是基于HashMap,HashMap的特点就是Key具有唯一性,这一点被HashSet利用了起来,每一个HashMap的Key对应的就是HashSet的元素值。来看看官方源码的解释。
此类实现Set接口,由哈希表(实际上是HashMap实例)支持。它不保证集合的迭代顺序;特别是,它不保证顺序随时间保持不变。此类允许null元素。
我们创建一个HashSet对象,实际上底层创建了一个HashMap对象。
// HashSet构造方法源码public HashSet() {map = new HashMap<>();}
HashSet一共提供了以下常用方法,不得不说HahSet在业务开发中还是用的没那么多的,南哥在框架源码上看HashSet用的就比较多,比如由Java语言实现的zookeeper框架源码。
(1)添加元素
public boolean add(E e) {return map.put(e, PRESENT)==null;}
我们看上面add方法的源码,是不是调用了HashMap的put方法呢?而put方法添加的Key是HashSet的值,Val则是一个空的Object对象。PRESENT是这么定义的。
// Dummy value to associate with an Object in the backing Mapprivate static final Object PRESENT = new Object();
(2)判断元素是否存在
public boolean contains(Object o) {return map.containsKey(o);}
HashSet的contains方法同样是调用HashMap判断Key是否存在的方法:containsKey。
(3)移除元素
public boolean remove(Object o) {return map.remove(o)==PRESENT;}
1.2 LinkedHashSet
面试官:LinkedHashSet呢?
接着轮到LinkedHashSet,同为Set集合之一,它和上文的HashSet有什么区别?南哥卖个关子。
源码对LinkedHashSet的解释。
Hash table and linked list implementation of the Set interface, with predictable iteration order. This implementation differs from HashSet in that it maintains a doubly-linked list running through all of its entries. This linked list defines the iteration ordering, which is the order in which elements were inserted into the set (insertion-order).
源码的大概意思就是:Set接口的哈希表和链表实现,具有可预测的迭代顺序。此实现与HashSet的不同之处在于,它维护一个贯穿其所有条目的双向链表。此链表定义迭代顺序,即**元素插入集合的顺序 (**插入顺序)。
底层数据结构是一条双向链表,每个元素通过指针进行相连,也就有了按插入顺序排序的功能。
知道了LinkedHashSet的特性,看看他的构造方法。
/*** 构造一个新的、空的链接哈希集,具有默认初始容量(16)和负载因子(0.75)。*/public LinkedHashSet() {super(16, .75f, true);}
这个super方法向上调用了底层C语言源码实现的LinedHashMap的构造方法。LinkedHashMap的特点就是元素的排序是根据插入的顺序进行排序,那LinkedHashSet也就继承了这个特性。
// C语言源码HashSet(int initialCapacity, float loadFactor, boolean dummy) {map = new LinkedHashMap<>(initialCapacity, loadFactor);}
LinkedHashSet的常见方法和HashSet一样,同样是add()、contains()、remove(),这里我写个简单的Demo。
public static void main(String[] args) throws IOException {LinkedHashSet<Integer> set = new LinkedHashSet<>();set.add(1);System.out.println(set.contains(1));set.remove(1);System.out.println(set.contains(1));}
# 运行结果
true
false
1.3 TreeSet
TreeSet和它们比有什么特性?
轮到你了,TreeSet。我们南友们很好奇为什么他叫TreeSet?
因为他是基于TreeMap实现的。。。
但根本原因不是,TreeMap的底层是通过红-黑树数据结构来实现自然排序,那TreeSet也就继承了这个特性。
官方源码对TreeSet的解释:
基于TreeMap的NavigableSet实现。元素使用其自然顺序进行排序,或者根据使用的构造函数,使用创建集合时提供的Comparator进行排序。
源码解释告诉我们,TreeSet和HashSet、LinkedHashSet不同的特性在于,元素既不像HashSet一样无序,也不是像LinkedHashSet一样是以插入顺序来排序,它是根据元素的自然顺序来进行排序。
b、c、a这三个元素插入到TreeSet中,自然顺序就和字母表顺序一样是:a、b、c。
public static void main(String[] args) throws IOException {TreeSet<String> treeSet = new TreeSet<>();treeSet.add("b");treeSet.add("c");treeSet.add("a");System.out.println(treeSet);}
# 运行结果
[a, b, c]
TreeSet除了拥有以下的add()、contains()、remove()方法。
// 如果指定元素尚不存在,则将其添加到此集合中。public boolean add(E e) {return m.put(e, PRESENT)==null;}
// 如果此集合包含指定元素,则返回true public boolean contains(Object o) {return m.containsKey(o);}
// 如果存在指定元素,则从此集合中移除该元素。public boolean remove(Object o) {return m.remove(o)==PRESENT;}
值得提出来的是,TreeSet还拥有first()、last(),可以方便我们提取出第一个、最后一个元素。
// 返回集合中的第一个元素。public E first() {return m.firstKey();}
// 返回集合中的最后一个元素。public E last() {return m.lastKey();}
1.4 TreeSet自定义排序
面试官:那TreeSet要怎么定制排序?
TreeSet的自定义排序我们要利用Comparator接口,通过向TreeSet传入自定义排序规则的Comparator来实现。
官方源码是这么解释的,南友们看一看。
// 构造一个新的空树集,根据指定的比较器进行排序。// 插入到集合中的所有元素都必须能够通过指定的比较器相互比较: comparator. compare(e1, e2)不得对集合中的任何元素e1和e2抛出ClassCastException 。// 如果用户尝试向集合中添加违反此约束的元素,则add调用将抛出ClassCastException public TreeSet(Comparator<? super E> comparator) {this(new TreeMap<>(comparator));}
传入Comparator接口时,我们还需要定义compare方法的游戏规则:如果compare方法比较两个元素的大小,返回正整数代表第一个元素 > 第二个元素、返回负整数代表第一个元素 < 第二个元素、返回0代表第一个元素 = 第二个元素。
下面我写了一个Demo,Comparator接口的规则是这样:人的岁数越小,那么他排名越靠前。
public class JavaProGuideTest {public static void main(String[] args) {TreeSet set = new TreeSet(new Comparator() {public int compare(Object o1, Object o2) {Person p1 = (Person)o1;Person p2 = (Person)o2;return (p1.age > p2.age) ? 1 : (p1.age < p2.age) ? -1 : 0;}});set.add(new Person(5));set.add(new Person(3));set.add(new Person(6));System.out.println(set);}@Data@AllArgsConstructorprivate static class Person {int age;}
}
# 执行结果
[JavaProGuideTest.Person(age=3), JavaProGuideTest.Person(age=5), JavaProGuideTest.Person(age=6)]
戳这,《JavaProGuide》作为一份涵盖Java程序员所需掌握核心知识、面试重点的Java学习进阶指南。

欢迎关注南哥的公众号:Java进阶指南针。公众号里有南哥珍藏整理的大量优秀pdf书籍!
我是南哥,南就南在Get到你的有趣评论➕点赞➕关注。
创作不易,不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️