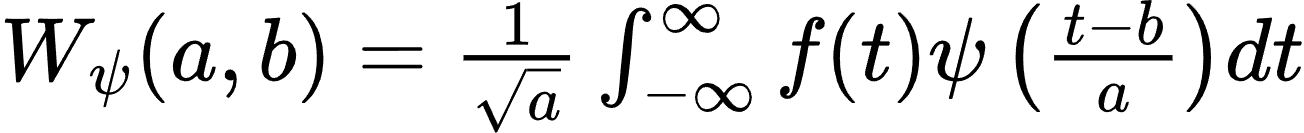※食用指南:文章内容为《SQL基础教程》系列学习笔记,该书对新手入门非常友好,循序渐进,浅显易懂,本人主要用来补全学习MySQL中未涉及的部分,便于刷题和做项目。
官方电子书:《SQL基础教程》第2版——图灵社区
官方授权视频:《SQL基础教程》第2版 零基础6小时
(个人觉得不是很有必要去看视频,自己看书做练习就够了)
目录:
第8章:SQL高级处理
8-1:窗口函数
(1)什么是窗口函数
(2)窗口函数语法
(3)语法的基本使用方法——使用RANK函数
(4)无需指定PARTITION BY
(5)专用窗口函数的种类
(6)窗口函数的适用范围
(7)作为窗口函数使用的聚合函数
(8)计算移动平均
(9)两个ORDER BY
8-2:GROUPING运算符
(1)同时得到合计行
(2)ROLLUP——同时得出合计和小计
(3)GROUPING函数——让NULL更加容易辨认
(4)CUBE——用数据来搭积木
(5)GROUPING SETS——取得期望的积木
章节练习:
第8章:SQL高级处理
8-1:窗口函数
(1)什么是窗口函数
窗口函数OLAP(Online Analytical Processing),对数据库数据进行实时分析处理(市场分析、创建财务报表、创建计划等)
![]()
(2)窗口函数语法
作为窗口函数使用的函数:
ROW_NUMBER、RANK、DENSE_RANK:专用窗口函数(排序函数)
SUM、AVG、COUNT、MAX、MIN:能够作为窗口函数的聚合函数
(3)语法的基本使用方法——使用RANK函数
RANK:用来记录排序的函数
PARTITION BY:设定排序的对象范围(根据什么分组)
ORDER BY:指定哪一列、何种顺序排序(默认升序,降序DECS)
❗根据不同种类(product_type),按照销售单价(sale_price)从低到高排序


PARTITION BY对表进行横向分组;ORDER BY决定纵向排序的规则
窗口函数兼具GROUP BY子句的分组功能以及ORDER BY子句的排序功能,但PARTITION BY不具备GROUP BY子句的汇总功能,因此使用RANK函数不会减少表中记录的行数
🔺PARTITION BY分组后的记录合集称为“窗口”,代表范围
因为在SQL中,“组”特指GROUP BY分割后的记录集合,为避免混淆使用PARTITION BY时称为窗口

(4)无需指定PARTITION BY
窗口函数中起到关键作用的是PARTITION BY、GROUP BY,其中PARTITION BY并不是必需的,即使不指定也可以正常使用窗口函数
和没有使用GROUP BY的聚合函数时效果一样,将整个表作为一个大的窗口来使用


(5)专用窗口函数的种类
ROW_NUMBER:唯一值连续位次
RANK:存在相同位次的记录,跳过之后的位次
DENSE_RANK:存在相同位次的记录,不跳过之后的位次

使用RANK或ROW_NUMBER时无需任何参数,只需要像RANK()或者ROW_NUMBER()保持括号中为空就行


练习:
LeetCode178题:
分数排名(不分组排序)

LeetCode184题:
每个部门工资最高的员工(分组排序)
①获得每个部门的员工及员工工资排序

②只提取工资最高的员工
salary_rank = 1:取每个分组降序后的第一个
t:取一个别名

使用RANK、DENSE_RANK都可以,因为如果工资都是一样的(位次),都要把它列出来
(6)窗口函数的适用范围
原则上窗口函数只能在SELECT子句中使用
窗口函数是对WHERE子句或者GROUP BY子句处理后的结果进行操作
(7)作为窗口函数使用的聚合函数
所有聚合函数都能用作窗口函数:SUM、AVG、COUNT、MAX、MIN

①计算销售单价的总计值,累计统计法
一行一行逐渐添加计算对象,按时间序列的顺序,计算各个时间的销售总额


②计算平均值,以当前记录为基准进行统计


(8)计算移动平均
窗口函数:将表以窗口为单位进行分割,并在其中进行排序的函数
框架:在窗口中指定更加详细的汇总范围的备选功能,该备选功能中的汇总范围
需要在ORDER BY子句之后使用指定范围的关键字
框架是根据当前记录来确定的,和固定的窗口不同,其范围会随着当前记录的变化而变化
①指定最靠近的3行作为汇总对象
ROWS(行)、PRECEDING(之前)
ROW 2 PRECEDING:截止到之前2行
-- 自身(当前记录)
-- 之前1行记录
-- 之前2行记录



以上的统计方法为移动平均(moving average),实时把控最近状态(常用于对股市趋势的实时跟踪)
②把PRECEDING替换成FOLLOWING,截止之后2行


汇总当前记录的前后行,同时使用PRECEDING、FOLLOWING
-- 之前1行的记录
-- 自身(当前记录)
-- 之后1行的记录



(能够熟练掌握框架功能,就可称之为窗口函数高手了)
(9)两个ORDER BY
注意:记录的排列顺序
使用窗口函数时必须要在OVER子句中使用ORDER BY,可能会误以为结果中的记录按照该ORDER BY 指定的顺序排序的
OVER子句中的OEDER BY只是用来决定窗口函数按照什么样的顺序进行计算的,对结果的排列顺序并没有影响
DBMS可以按照窗口函数的ORDER BY 子句所指定的顺序对结果进行排序,但也仅仅只是个例罢了


如果想让记录就按张ranking列的升序进行排序
在SELECT语句的最后,使用ORDER BY子句进行指定
使用两个ORDER BY 看起来有点怪,但这两个ORDER BY的动能完全不同

8-2:GROUPING运算符
(1)同时得到合计行
GROUP BY子句用来指定聚合键的场所,根据指定的键分割数据,不会出现合计行
合计行是不指定聚合键时得到的汇总结果
如果想要得到合计,分别计算出合计行和按照商品种类进行汇总的结果,再用UNION ALL连接在一起


(2)ROLLUP——同时得出合计和小计
GROUPING运算符:
ROLLUP
CUBE
GROUPING SETS
ROLLUP是卷起,卷起百叶窗、窗帘卷等,能够得到像从小计到合计,从最小的聚合级开始,聚合单位逐渐扩大的结果
ROLLUP(列1,列2,…),一次计算出不同聚合键组合的结果
-- GROUP BY()
-- GROUP BY(product_type)
GROUP BY():没有聚合键,相当于没有GROUP BY子句,会得到全部数据的合计行记录,超级分组记录(super group row)
超级分组记录的product_type列的键值(对DBMS来说)并不明确,会默认使用NULL
其他SQL语法:

MySQL专用语法:


①未使用ROLLUP前:


②使用ROLLUP后:
其他SQL语法:

MySQL专用语法:


使用ROLLUP多了合计行和3个不同商品种类的小计行(未使用登记日期作为聚合键的记录),这4行就是超级分组记录
SELECT语句使用UNION对3种模式的聚合级的不同结果进行连接
-- GROUP BY
-- GROUP BY(product_type)
-- GROUP BY(product_type,regist_date)


(3)GROUPING函数——让NULL更加容易辨认
regist_date中衣服有一列为NULL,而NULL作为了聚合键作为小计,两个NULL不易辨认

判断超级分组记录的NULL特定函数——GROUPING函数,参数列的值是超级分组记录产生NULL返回1,其他返回0


使用GROUPING函数可以在超级分组记录的键值中插入字符串
当GROUPING函数的返回值为1时,指定“合计”或者“小计”等字符串,其他情况返回通常的列的值
(实际业务中需要获取包含合计或者小计的汇总结果)
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
满足CAST表达式所有分支的返回值必须一致的条件,否则各个分支分别返回日期和字符串类型的值,执行时发生语法错误


(4)CUBE——用数据来搭积木
CUBE:立方体
将ROLLUP替换为CUBE


把regist_date作为聚合键
-- GROUP BY
-- GROUP BY(product_type)
-- GROUP BY(product_date)
-- GROUP BY(product_type,regist_date)
CUBE将GROUP BY子句中聚合键的“所以可能的组合“汇总结果集中到一个结果中
组合的个数2n(n是聚合键的个数)
聚合键有2个,所以是4,如果是3个聚合键则为8

(5)GROUPING SETS——取得期望的积木
GROUPING SETS运算符:用于从ROLLUP、CUBE的结果中取出部分记录,个别条件对应的不固定的结果
想从中选取将“商品种类“和”登记日期“各自作为聚合键的结果
或不想得到合计“记录和使用2个聚合键的记录“


章节练习:
8.1


按照product_id升序排序,计算出截至当前行的最高销售单价
商品编号越来越大,计算最大值的对象范围也不断扩大
(用于奥运会等竞技体育的最高纪录不断变化相似,随着运动员数量逐渐增加,要选出历史第一也会越来越难)
8.2
使用Proudct表,计算按照regist_date升序进行排列的各日期的sale_price的总额
排序需要将等级日期为NULL 的运动T恤记录排在第1位(看作弊比其他日期都早)
方法二:regist_date为NULL时,显示“1年1月1日“(日常骗一下DBMS)

方法一:regist_date为NULL时,将该记录放在最前显示(不推荐,可能因DBMS的需求改变无法使用)


————TBC