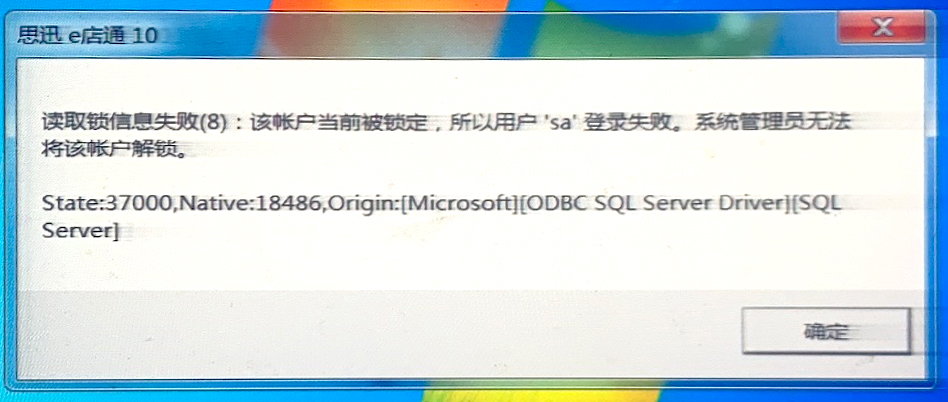
8 位线性量化的数学表达
- 将 32 位浮点(实数)模型转换为 8 位整数模型
F 32 = S c a l e ∗ ( I i n t 8 − Z ) 量化公式: I i n t 8 = F 32 S c a l e + Z F_{32} = Scale * (I_{int8}-Z)\\ 量化公式: I_{int8} = \frac{F_{32}}{Scale} + Z F32=Scale∗(Iint8−Z)量化公式:Iint8=ScaleF32+Z
| 对称量化 | 仿射量化 |
|---|---|
| Z = 0 Z = 0 Z=0 | Z ≠ 0 Z\neq 0 Z=0 |
| S = 2 ∗ m a x ( a b s ( F m a x ) , a b s ( F m i n ) ) I m a x − I m i n S=\frac{2*max(abs(F_{max}), abs(F_{min}))}{ I_{max} - I_{min}} S=Imax−Imin2∗max(abs(Fmax),abs(Fmin)) | S = F m a x − F m i n I m a x − I m i n S=\frac{ F_{max}-F_{min}}{ I_{max} - I_{min}} S=Imax−IminFmax−Fmin |
s =max(abs(A1), abs(A2))/(2^7) ,z =0 | s = (A1-A2)/(2^8 + 1) ,z = -(ROUND(A2 * s)) - 2^(8-1) |
| 量化到[-127,127] | 一般可量化到[-128,127] ([0,255]) |
卷积的量化(对称量化)

y 1 , 1 = x 1 , 1 ∗ w 1 , 1 + x 1 , 2 ∗ w 2 , 1 + x 1 , 3 ∗ w 3 , 1 = s a ∗ X 1 , 1 ∗ s b ∗ W 1 , 1 + s c ∗ X 1 , 2 ∗ s d ∗ W 2 , 1 + s e ∗ X 1 , 3 ∗ s f ∗ W 3 , 1 ( 量化 ) = s A ∗ s B ( X 1 , 1 ∗ W 1 , 1 + X 1 , 2 ∗ W 2 , 1 + X 1 , 3 ∗ W 3 , 1 ) ( 需满足 s A = s a , s c , s e 才行 ) y_{1,1} \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\ =x_{1,1}*w_{1,1}+x_{1,2}*w_{2,1}+x_{1,3}*w_{3,1} \\ = s_a*X_{1,1}* s_b*W_{1,1}+ \qquad \qquad \qquad \ \\\ s_c*X_{1,2}*s_d*W_{2,1}+\qquad \qquad \quad \ \ \\\ s_e*X_{1,3}*s_f*W_{3,1}(量化)\qquad \ \ \ \ \\ = s_A*s_B(X_{1,1}*W_{1,1}+X_{1,2}*W_{2,1} \ \ \ \ \\ +X_{1,3}*W_{3,1})(需满足s_A=s_a,s_c,s_e才行) y1,1 =x1,1∗w1,1+x1,2∗w2,1+x1,3∗w3,1=sa∗X1,1∗sb∗W1,1+ sc∗X1,2∗sd∗W2,1+ se∗X1,3∗sf∗W3,1(量化) =sA∗sB(X1,1∗W1,1+X1,2∗W2,1 +X1,3∗W3,1)(需满足sA=sa,sc,se才行)
手动实现的一些细节(代码来自github,A simple network quantization demo using pytorch from scratch)
- 基础公式
def quantize_tensor(x, scale, zero_point, num_bits=8, signed=False):if signed:qmin = - 2. ** (num_bits - 1)qmax = 2. ** (num_bits - 1) - 1else:qmin = 0.qmax = 2. ** num_bits - 1.q_x = zero_point + x / scaleq_x.clamp_(qmin, qmax).round_()return q_xdef dequantize_tensor(q_x, scale, zero_point):return scale * (q_x - zero_point)
- 重新定义梯度 pytorch实现简单的straight-through estimator(STE)
class QConv2d(QModule):def __init__(self, conv_module, qi=True, qo=True, num_bits=8):super(QConv2d, self).__init__(qi=qi, qo=qo, num_bits=num_bits)self.num_bits = num_bitsself.conv_module = conv_moduleself.qw = QParam(num_bits=num_bits)self.register_buffer('M', torch.tensor([], requires_grad=False)) # 将M注册为bufferdef freeze(self, qi=None, qo=None):if hasattr(self, 'qi') and qi is not None:raise ValueError('qi has been provided in init function.')if not hasattr(self, 'qi') and qi is None:raise ValueError('qi is not existed, should be provided.')if hasattr(self, 'qo') and qo is not None:raise ValueError('qo has been provided in init function.')if not hasattr(self, 'qo') and qo is None:raise ValueError('qo is not existed, should be provided.')if qi is not None:self.qi = qiif qo is not None:self.qo = qoself.M.data = (self.qw.scale * self.qi.scale / self.qo.scale).dataself.conv_module.weight.data = self.qw.quantize_tensor(self.conv_module.weight.data)self.conv_module.weight.data = self.conv_module.weight.data - self.qw.zero_pointself.conv_module.bias.data = quantize_tensor(self.conv_module.bias.data, scale=self.qi.scale * self.qw.scale,zero_point=0, num_bits=32, signed=True)def forward(self, x):if hasattr(self, 'qi'):self.qi.update(x)x = FakeQuantize.apply(x, self.qi)self.qw.update(self.conv_module.weight.data)x = F.conv2d(x, FakeQuantize.apply(self.conv_module.weight, self.qw), self.conv_module.bias, stride=self.conv_module.stride,padding=self.conv_module.padding, dilation=self.conv_module.dilation, groups=self.conv_module.groups)if hasattr(self, 'qo'):self.qo.update(x)x = FakeQuantize.apply(x, self.qo)return x
PTQ(Post Training Quantization)
- 一个帮助理解量化过程的demo
- A simple network quantization demo using pytorch from scratch
def quantize(self, num_bits=8):self.qconv1 = QConvBNReLU(self.conv1, self.bn1, qi=True, qo=True, num_bits=num_bits)self.qmaxpool2d_1 = QMaxPooling2d(kernel_size=2, stride=2, padding=0)self.qconv2 = QConvBNReLU(self.conv2, self.bn2, qi=False, qo=True, num_bits=num_bits)self.qmaxpool2d_2 = QMaxPooling2d(kernel_size=2, stride=2, padding=0)self.qfc = QLinear(self.fc, qi=False, qo=True, num_bits=num_bits)
预处理
- ONNX 运行时提供 python API,预处理使用命令
python -m onnxruntime.quantization.preprocess - 官方提供的实例为:
python -m onnxruntime.quantization.preprocess --input mobilenetv2-7.onnx --output mobilenetv2-7-infer.onnx
量化( 动态量化& 静态量化)
静态量化
- 官方提供的实例为:
python run.py --input_model mobilenetv2-7-infer.onnx --output_model mobilenetv2-7.quant.onnx --calibrate_dataset ./test_images/
静态量化方法首先使用一组称为校准数据的输入来运行模型。在这些运行期间,我们计算每个激活的量化参数。这些量化参数作为常量写入量化模型并用于所有输入。
import numpy as np
import onnxruntime
from onnxruntime.quantization import QuantFormat, QuantType, quantize_staticimport resnet50_data_reader
dr = resnet50_data_reader.ResNet50DataReader(calibration_dataset_path, input_model_path
)# Calibrate and quantize model
# Turn off model optimization during quantization
quantize_static(input_model_path,output_model_path,dr,quant_format=args.quant_format,# default=QuantFormat.QDQ, 有两种表示量化 ONNX 模型的方法:面向操作符(QOperator)的所有量化运算符都有自己的 ONNX 定义,如 QLinearConv、MatMulInteger 等。面向张量(QDQ;量化和反量化)。此格式在原始运算符之间插入 DeQuantizeLinear(QuantizeLinear(tensor)) 以模拟量化和反量化过程per_channel=args.per_channel,weight_type=QuantType.QInt8,optimize_model=False,
)
动态量化
- 动态量化动态计算激活的量化参数(比例和零点)。这些计算增加了推理成本,但与静态计算相比通常可以获得更高的准确性。
import onnx
from onnxruntime.quantization import quantize_dynamic, QuantTypemodel_fp32 = 'path/to/the/model.onnx'
model_quant = 'path/to/the/model.quant.onnx'
quantized_model = quantize_dynamic(model_fp32, model_quant)#
quantized_model = quantize_dynamic(model_fp32, model_quant, weight_type=QuantType.QUInt8)
调试与优化
- 调试与优化见官方的例子
console python run_qdq_debug.py --float_model mobilenetv2-7-infer.onnx --qdq_model mobilenetv2-7.quant.onnx --calibrate_dataset ./test_images/
参考与更多
-
此工具可用于量化选定的 ONNX 模型。支持基于模型中的运算符。使用详情请参考 ,示例请参考
-
基于离群值去除的卷积神经网络模型训练后量化预处理方法
-
Quantizing deep convolutional networks for efficient inference: A whitepaper
-
https://zhuanlan.zhihu.com/p/622334595 量化语言模型
FX
-
TORCH.FX第二篇——PTQ量化实操
-
aware ( a 表加强 + ware 注视 )adj. 意识到的; 意识到; 知道; 明白; 察觉到; 发觉; 发现; 对…有兴趣的; 有…意识的
-
Quantization Aware Training 量化感知训练
-
训练同时消弭量化的噪声
-
https://zhuanlan.zhihu.com/p/158776813
-
基于OneFlow实现量化感知训练
-
Quantization (QAT) Demo on CIFAR10
-
Inference of quantization aware trained networks using TensorRT
-
https://github.com/666DZY666/micronet
-
还有一个好处是, 你拿到的int8的pytorch模型, 可以无缝的部署到任何支持的框架上, 而不需要再其他框架上再进行量化.
-
使用 TensorFlow 模型优化工具包进行量化感知训练 - 性能与准确性
-
Pytorch实现量化感知训练QAT(一)
-
Brevitas: quantization-aware training in PyTorch
-
在本研究中,使用了Brevitas工具。它是一个基于流行的PyTorch工具的库,该工具允许训练量化神经网络(QNN)
-
Quantization library for PyTorch. Support low-precision and mixed-precision quantization, with hardware implementation through TVM(优化计算图的包).
-
Implements quantized distillation. Code for our paper “Model compression via distillation and quantization”
-
Summary, Code for Deep Neural Network Quantization
-
[CVPR’20] ZeroQ: A Novel Zero Shot Quantization Framework
-
PyTorch implementation for the APoT quantization (ICLR 2020)
-
商汤:PPL Quantization Tool (PPQ) is a powerful offline neural network quantization tool.
-
AIMET is a library that provides advanced quantization and compression techniques for trained neural network models.
-
4 bits quantization of LLaMa using GPTQ
- PyTorch量化感知训练(QAT)步骤
-
https://github.com/leimao/PyTorch-Quantization-Aware-Training/blob/main/cifar.py
-
https://leimao.github.io/blog/PyTorch-Quantization-Aware-Training/
-
Codes for paper: Central Similarity Quantization for Efficient Image and Video Retrieval,