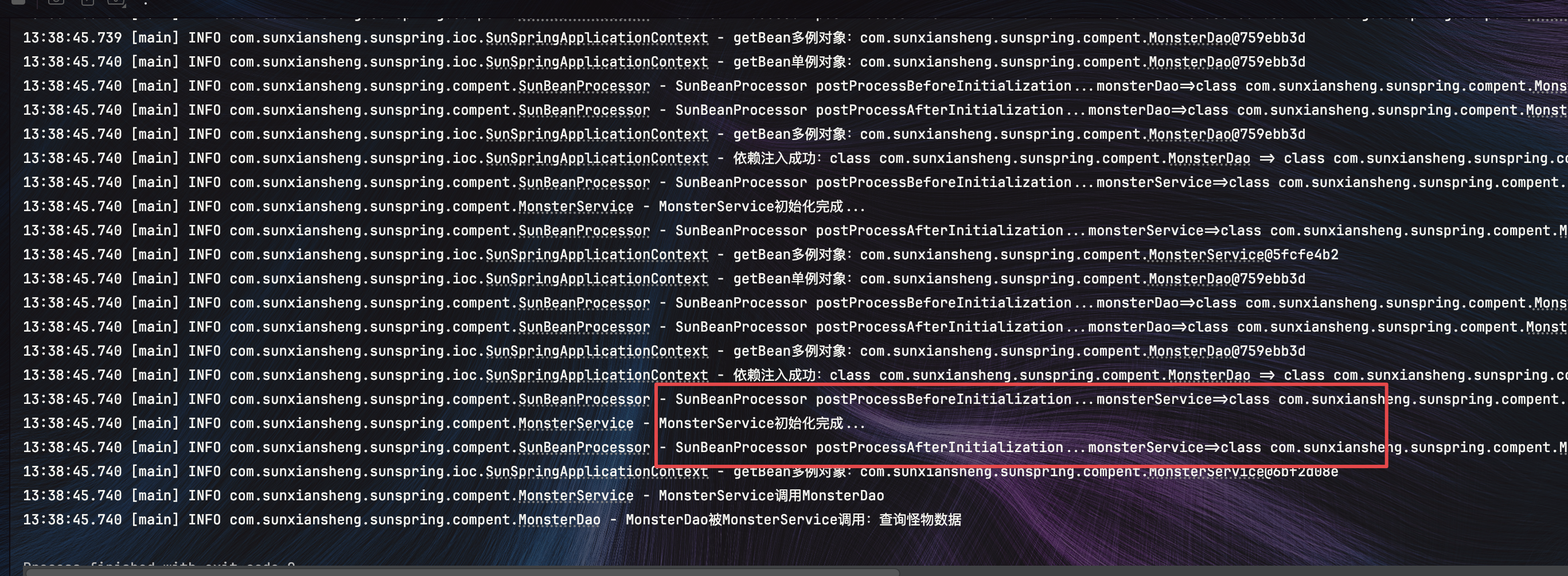
1 序列数据
利用CNN构建图像识别模型,对每个样本的假设是独立同分布的,然而,大多数的数据并非如此。例如,文章中的单词是按顺序写的,如果顺序被随机地重排,就很难理解文章原始的意思。同样,视频中的图像帧、对话中的音频信号以及网站上的浏览行为都是有顺序的(称之为序列数据)。因此,针对此类数据而设计特定模型,可能效果会更好。
简言之,如果说卷积神经网络可以有效地处理空间信息,那么本章的循环神经网络(recurrent neural network,RNN)则可以更好地处理序列信息。循环神经网络通过引入状态变量存储过去的信息和当前的输入,从而可以确定当前的输出。[1]
2 从MLP到RNN 【2】
MLP和CNN的输出只考虑与当前输入的关系,同一层之间不存在关系,所以同层不存在与前一时刻或者后一时刻的关系。


RNN关注隐层每个神经元在时间维度上的不断成长与进步,与MLP相比,没有添加新的神经元,但是沿着时间维度recurrent,建立时序上的关联。图中的隐层神经元数量并没有增加,而是表示隐层不同时刻的状态。隐层之间的关联可以是全连接的,也可以是其他的形式。隐层不同时刻之间的关联共享一个矩阵 W s W_s Ws(减少训练参数)。

MLP的隐藏层只与当前的输入 X X X有关系。写成数学公式就是: S = f ( W i n X + b ) (1) S=f(W_{in}X+b) \tag{1} S=f(WinX+b)(1)
但是,RNN的隐藏层不仅与当前输入 X X X有关系,还与前一时刻的隐层状态 S t − 1 S_{t-1} St−1有关系。写成数学公式就是: S t = f ( W i n X + W s S t − 1 + b ) (2) S_t=f(W_{in}X+W_sS_{t-1}+b) \tag{2} St=f(WinX+WsSt−1+b)(2)
不同时刻隐层之间的关系通过矩阵 W s W_s Ws进行关联。让神经网络有了某种记忆的能力。

3 输入输出的不同形式会有不同的应用
3.1 看图说话(1toN)

3.2 句子分类(Nto1)

3.3 词性标定(等长NtoN)

3.4 Seq2Seq/Encoder-Decoder
先将输入数据编码成一个上下文向量,然后通过它预测输出的序列。机器翻译、文本理解、对话系统

4 代码
突出RNN与MLP在数据的预处理、输入、训练、输出等各个阶段的处理有什么不同
4.1 时间序列预测
4.1.1 下载数据并观察
#数据加载
import pandas_datareader as pdr
dji = pdr.DataReader('^DJI', 'stooq')
print(dji)
数据显示如下:
Open High Low Close Volume
Date
2024-08-22 40932.23 41026.64 40584.47 40712.78 3.047464e+08
2024-08-21 40881.03 40974.40 40738.43 40890.49 2.696454e+08
2024-08-20 40874.52 40909.38 40756.65 40834.97 2.947137e+08
2024-08-19 40670.83 40907.32 40670.83 40896.53 2.708081e+08
2024-08-16 40528.86 40726.03 40453.58 40659.76 3.087936e+08... ... ... ... ...
2019-08-30 26476.39 26514.62 26295.59 26403.28 2.191756e+09
2019-08-29 26249.09 26408.84 26185.71 26362.25 2.086640e+08
2019-08-28 25712.99 26041.57 25637.43 26036.10 2.069843e+08
2019-08-27 26014.46 26054.02 25721.85 25777.90 2.635140e+08
2019-08-26 25826.05 25941.25 25716.39 25898.83 2.228613e+08[1257 rows x 5 columns]
四列分别对应着开盘、最高点、最低点和收盘。将收盘这一列拿出来画曲线图:
import matplotlib.pyplot as pltfig1=plt.figure(num=1)
plt.plot(dji['Close'])
plt.show()

任务就是通过最近一段时间的收盘价格,预测明天的收盘价格。“最近一段时间”指的是多长时间这个可以自己定义,在程序中就是通过变量seq_len指定。
为了对比MLP和RNN,下面对MLP和RNN分别进行定义
4.1.2 定义模型:MLP和RNN
################################### MLP
class MLP(nn.Module):def __init__(self, input_size, output_size, num_hiddens):super().__init__()self.linear1 = nn.Linear(input_size, num_hiddens)self.linear3 = nn.Linear(num_hiddens, num_hiddens)self.linear2 = nn.Linear(num_hiddens, output_size)def forward(self, X):output = torch.relu(self.linear1(X))output = torch.relu(self.linear3(output))output = self.linear2(output)return output############################## DRNN
class DRNN(nn.Module):def __init__(self, input_size, output_size, hidden_size, num_layers):super(DRNN, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) # batch_first 为 True时output的tensor为(batch_size,seq_len,hidden_size),否则为(seq_len,batch_size,hidden_size)self.linear = nn.Linear(hidden_size, output_size)def forward(self, x):# 初始化隐藏状态和细胞状态state = torch.zeros(self.num_layers, x.size(0), self.hidden_size)# 计算输出和最终隐藏状态output, _ = self.rnn(x, state)output = self.linear(output)return output
通过模型定义可以看出以下几点:
(1)RNN不需要定义序列长度:RNN用于处理序列数据,但是在模型定义中并没有定义序列长度是多少。这一点和MLP不需要定义batch size是一样的,batch size和序列长度都是等数据注入模型的时候才能决定。
(2)nn.RNN前向传播输入除了当前时刻输入(x)还需要上一时刻隐藏层的状态(state)作为输入,而nn.Linear不需要上一时刻隐藏层的状态(state)作为输入
(3)因为2,所以RNN需要有一个最初始的隐藏曾状态(state),这个state的形状是(隐藏层个数,batch size,hidden_size)
(4)nn.RNN的输出也是两个,一个是feature,一个是隐藏层状态。feature的形状要看在定义的时候batch_first的设置。如果batch_first=True,那么feature的形状为(batch_size,seq_len,hidden_size),否则为(seq_len,batch_size,hidden_size)。隐藏层状态的形状就是(隐藏层个数,batch size,hidden_size)
4.1.3 对数据进行预处理
import torch
from torch.utils.data import DataLoader, TensorDatasetnum = len(dji) # 总数据量
x = torch.tensor(dji['Close'].to_list()[::-1]) # 股价列表,把顺序倒过来,因为原来的时间顺序是从大到小的x = (x - torch.mean(x)) / torch.std(x) #对数据进行归一化
这里有个需要注意的点,x把数据从dataframe里拿出来的时候,倒转了顺序,因为dataframe里的时间顺序是从大到小的
4.1.4 为训练做准备
因为要做MLP与RNN的对比,所以要准备两组数据,因为这两个模型对输入输出的要求不太一样
准备RNN的train_loader
seq_len = 16 # 预测序列长度
batch_size = 32 # 设置批大小X_feature = torch.zeros((num - seq_len, seq_len)) # 构建特征矩阵,num-seq_len行,seq_len列,初始值均为0
Y_label = torch.zeros((num - seq_len, seq_len)) # 构建标签矩阵,形状同特征矩阵for i in range(seq_len):X_feature[:, i] = x[i: num - seq_len + i] # 为特征矩阵赋值Y_label[:, i] = x[i+1: num - seq_len + i + 1] # 为标签矩阵赋值train_loader = DataLoader(TensorDataset(X_feature[:num-seq_len].unsqueeze(2), Y_label[:num-seq_len]),batch_size=batch_size, shuffle=True) # 构建数据加载器,训练各种RNN
准备MLP的train_loader
y_label = x[seq_len:].reshape((-1, 1)) # 真实结果列表,用于MLPtrain_loader_mlp = DataLoader(TensorDataset(X_feature[:num-seq_len], y_label[:num-seq_len]), batch_size=batch_size, shuffle=True) # 构建数据加载器,训练mlp
定义超参数
# 定义超参数
input_size = 1
output_size = 1
num_hiddens = 64
n_layers = 2
lr = 0.001
建立模型
# 建立模型
model = DRNN(input_size, output_size, num_hiddens, n_layers)
mlp = MLP(seq_len, output_size, num_hiddens)criterion = nn.MSELoss(reduction='none')trainer = torch.optim.Adam(model.parameters(), lr)
trainer_mlp = torch.optim.Adam(mlp.parameters(), lr)
4.1.5 开始训练
# 训练轮次
num_epochs = 20
mlp_loss_history = []
rnn_loss_history = []
####################### MLP训练
for epoch in tqdm(range(num_epochs)):# print('##########################epoch:',epoch)# 批量训练for X, y in train_loader_mlp:# print('%%%%%%%%%%%')# print('X.shape:',X.shape)#####X.shape: torch.Size([32, 16])# print('y.shape:',y.shape)######y.shape: torch.Size([32, 1])trainer_mlp.zero_grad()y_pred = mlp(X)# print('y_pred.shape:',y_pred.shape)######y_pred.shape: torch.Size([32, 1])loss = criterion(y_pred, y)# print('loss:',loss)loss.sum().backward()trainer_mlp.step()# 输出损失with torch.no_grad():total_loss = 0for X, y in train_loader_mlp:y_pred = mlp(X)loss = criterion(y_pred, y)total_loss += loss.sum()/loss.numel()avg_loss = total_loss / len(train_loader)print(f'Epoch {epoch+1}: Validation loss = {avg_loss:.4f}')# loss_history.append(avg_loss.detach().numpy())mlp_loss_history.append(avg_loss)####################### DRNN训练for epoch in tqdm(range(num_epochs)):# 批量训练for X, Y in train_loader:trainer.zero_grad()y_pred = model(X)##X.shape: torch.Size([32, 16,1]),其中1是input_size;#Y.shape: torch.Size([32, 16])###y_pred.shape: torch.Size([32, 16, 1]),其中1是output_sizeloss = criterion(y_pred.squeeze(), Y.squeeze())loss.sum().backward()trainer.step()# 输出损失with torch.no_grad():total_loss = 0for X, Y in train_loader:y_pred = model(X)loss = criterion(y_pred.squeeze(), Y.squeeze())total_loss += loss.sum()/loss.numel()avg_loss = total_loss / len(train_loader)print(f'Epoch {epoch+1}: Validation loss = {avg_loss:.4f}')rnn_loss_history.append(avg_loss)# 绘制损失曲线图
# import matplotlib.pyplot as plt
# plt.plot(loss_history, label='loss')
fig2=plt.figure(num=2)
plt.plot(mlp_loss_history, label='MLP_loss')
plt.plot(rnn_loss_history, label='RNN_loss')
plt.legend()
plt.show()
损失曲线图如图所示:

可以看到RNN的损失更低一些。
需要注意几点:
(1)MLP预测时间序列的输入输出形式与rnn不同,mlp如下:

RNN如下:

MLP的input_size就是序列长度,输出size是1;RNN的输入size与输出size都是1
(2)注入MLP的数据与注入RNN的数据的形状不同:注入MLP的数据形状是(batch_size, input_size=seq_len),注入RNN的数据形状是(batch_size, seq_len, input_size=1)
(3)MLP输出形状和RNN输出形状不同:MLP输出形状:(batch_size, output_size)RNN输出形状(batch_size, seq_len, output_size=1)。这个时候,我们就可以看出MLP与RNN的数据的区别了,MLP少了一个seq_len的维度,而这个维度是在数据侧决定的,不是在模型侧。
(4)RNN是可以输出隐藏层的状态的,只是这里没有输出。(RNN的输入需要X和state,输出是Y和state,state看需要,可以不输出)
所以为了能够正确的训练和预测,需要对数据的形状进行整理,需要用到unsqueeze()和squeeze(),这两个函数的原理请参考【3】
另外MSEloss也需要注意,reduction='none’就是每个元素进行差和平方,保留数据形状,不加和不平均。可参考【4】
4.1.6 预测
fig3=plt.figure(num=3)
rnn_preds = model(X_feature.unsqueeze(2))
mlp_preds = mlp(X_feature)
rnn_preds.squeeze()
time = torch.arange(1, num+1, dtype= torch.float32) # 时间轴plt.plot(time[:num-seq_len], x[seq_len:num], label='dji')
# plt.plot(time[:num-seq_len], preds.detach().numpy(), label='preds')
plt.plot(time[:num-seq_len], mlp_preds.detach().numpy(), label='mlp_preds')
plt.plot(time[:num-seq_len], rnn_preds[:,seq_len-1].detach(), label='RNN_preds')######只取了序列最后节点的输出
plt.legend()
plt.show()
这里需要注意的是,预测的时候,RNN的预测值只是取了最后时刻节点的输出。

4.2 文本
参考:
【1】动手学深度学习
【2】【循环神经网络】5分钟搞懂RNN,3D动画深入浅出
【*】PyTorch nn.MSELoss() 均方误差损失函数详解和要点提醒
【3】unsqueeze()和squeeze()