Transformer模型介绍

Transformer 是工业化、同质化的后深度学习模型,其设计目标是能够在高性能计算机(超级计算机)上以并行方式进行计算。通过同质化,一个Transformer 模型可以执行各种任务,而不需要微调。Transformer 使用数十亿参数在数十亿条原始未标注数据上进行自监督学习。
这些后深度学习架构称为基础模型。基础模型Transformer 是始于 2015年的第四次工业革命的一部分(通过机器-机器自动化将万物互联)。工业4.0(I4.0)的 AI,特别是自然语言处理(NLP)已经远远超越了过往时代,颠覆了以往的开发范式。
Transformer 架构具有革命性和颠覆性,它打破了过往RNN和CNN 的主导地位。BERT 和GPT模型放弃了循环网络层,使用自注意力机制取而代之。Transformer 模型优于RNN和CNN,这是AI历史上划时代的重大变化,Transformer模型标示着AI新时代的开始。
图源《基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理》
掌握Transformer 模型的必读书
在不到4 年的时间里,Transformer 模型以其强大的性能和创新的思想,迅速在NLP 社区崭露头角,打破了过去30 年的记录。BERT、T5 和GPT 等模型现在已成为计算机视觉、语音识别、翻译、蛋白质测序、编码等各个领域中新应用的基础构件。因此,斯坦福大学最近提出了“基础模型”这个术语,用于定义基于巨型预训练Transformer 的一系列大型语言模型。所有这些进步都归功于一些简单的想法。
《基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理》可作为所有对Transformer 工作原理感兴趣的人的参考书。作者在理论和实践两方面都做出了出色的工作,详细解释了如何逐步使用Transformer。阅读完本书后,你将能使用这一最先进的技术集合来增强你的深度学习应用能力。本书在详细介绍BERT、RoBERTa、T5 和GPT-3 等流行模型前,先讲述了Transformer 的架构以便为你的学习奠定坚实基础。本书还讲述了如何将Transformer 应用于许多用例,如文本摘要、图像标注、问答、情感分析和假新闻分析等。如果你对这些主题感兴趣,那么本书绝对是值得一读的。
图源《基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理》
内容简介
Transformer正在颠覆AI领域。市面上有这么平台和Transformer模型,哪些最符合你的需求?本书将引领你进入Transformer的世界,将讲述不同模型和平台的优势,指出如何消除模型的缺点和问题。本书将引导你使用Hugging Face从头开始预训练一个RoBERTa模型,包括构建数据集、定义数据整理器以及训练模型等。
《基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理》分步展示如何微调GPT-3等预训练模型。研究机器翻译、语音转文本、文本转语音、问答等NLP任务,并介绍解决NLP难题的技术,甚至帮助你应对假新闻焦虑(详见第13章)。
从书中可了解到,诸如OpenAI的高级平台将Transformer扩展到语言领域、计算机视觉领域,并允许使用DALL-E 2、ChatGPT和GPT-4生成代码。通过本书,你将了解到Transformer的工作原理以及如何实施Transformer来决NLP问题。

清华大学出版社/2024.01
主要内容
• 了解用于解决复杂语言问题的新技术
• 将GPT-3与T5、GPT-2和基于BERT的Transformer的结果进行对比
• 使用TensorFlow、PyTorch和GPT-3执行情感分析、文本摘要、非正式语言分析、机器翻译等任务
• 了解ViT和CLIP如何标注图像(包括模糊化),并使用DALL-E从文本生成图像
• 学习ChatGPT和GPT-4的高级提示工程机制
原版评价

样章试读

目录
第1 章 Transformer 模型介绍
1.1 Transformer 的生态系统
1.2 使用Transformer 优化NLP模型
1.3 我们应该使用哪些资源
1.4 本章小结
1.5 练习题
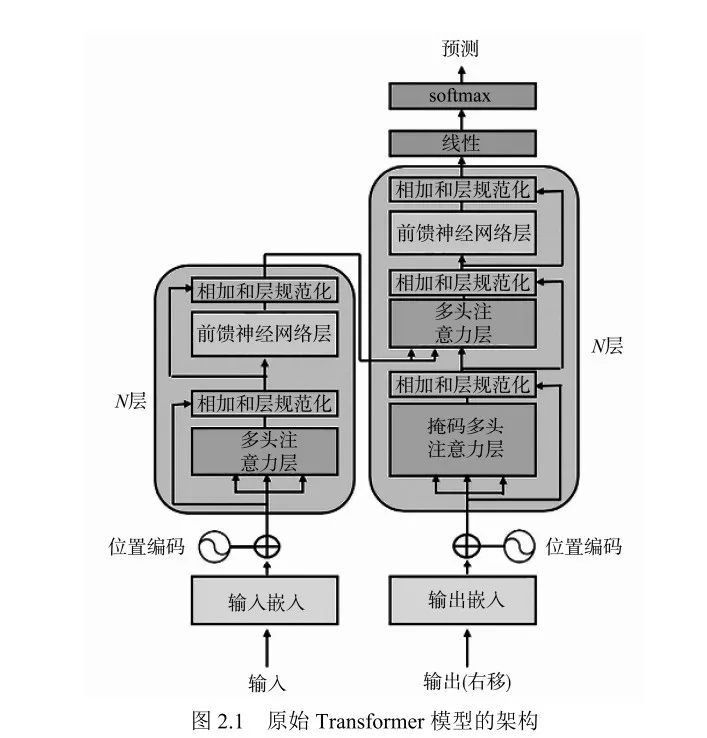
第2 章 Transformer 模型架构入门
2.1 Transformer 的崛起:注意力就是一切
2.2 训练和性能
2.3 Hugging Face 的Transformer模型
2.4 本章小结
2.5 练习题
第3 章 微调BERT 模型
3.1 BERT 的架构
3.2 微调BERT
3.3 本章小结
3.4 练习题
第4 章 从头开始预训练RoBERTa模型
4.1 训练词元分析器和预训练Transformer
4.2 从头开始构建Kantai BERT
4.3 后续步骤
4.4 本章小结
4.5 练习题
第5 章 使用Transformer 处理下游NLP 任务
5.1 Transformer 的转导与感知
5.2 Transformer 性能与人类基准
5.3 执行下游任务
5.4 本章小结
5.5 练习题
第6 章 机器翻译
6.1 什么是机器翻译
6.2 对WMT 数据集进行预处理
6.3 用BLEU 评估机器翻译
6.4 Google 翻译
6.5 使用Trax 进行翻译
6.6 本章小结
6.7 练习题
第7 章 GPT-3
7.1 具有GPT-3 Transformer模型的超人类NLP
7.2 OpenAI GPT Transformer模型的架构
7.3 使用GPT-2 进行文本补全
7.4 训练自定义GPT-2 语言模型
7.5 使用OpenAI GPT-3
7.6 比较GPT-2 和GPT-3 的输出
7.7 微调GPT-3
7.8 工业4.0 AI 专家所需的技能
7.9 本章小结
7.10 练习题
第8 章 文本摘要(以法律和财务文档为例)
8.1 文本到文本模型
8.2 使用T5 进行文本摘要
8.3 使用GPT-3 进行文本摘要
8.4 本章小结
8.5 练习题
第9 章 数据集预处理和词元分析器
9.1 对数据集进行预处理和词元分析器
9.2 深入探讨场景4 和场景5
9.3 GPT-3 的NLU 能力
9.4 本章小结
9.5 练习题
第10 章 基于BERT 的语义角色标注
10.1 SRL 入门
10.2 基于BERT 模型的SRL 实验
10.3 基本示例
10.4 复杂示例
10.5 SRL 的能力范围
10.6 本章小结
10.7 练习题
第11 章 使用Transformer 进行问答
11.1 方法论
11.2 方法0:试错法
11.3 方法1:NER
11.4 方法2:SRL
11.5 后续步骤
11.6 本章小结
11.7 练习题
第12 章 情绪分析
12.1 入门:使用Transformer进行情绪分析
12.2 斯坦福情绪树库(SST)
12.3 通过情绪分析预测客户行为
12.4 使用GPT-3 进行情绪分析
12.5 工业4.0 依然需要人类
12.6 本章小结
12.7 练习题
> 第13 章 使用Transformer 分析假新闻
13.1 对假新闻的情绪反应
13.2 理性处理假新闻的方法
13.3 在我们继续之前
13.4 本章小结
13.5 练习题
> 第14 章 可解释AI
14.1 使用BertViz 可视化Transformer
14.2 LIT
14.3 使用字典学习可视化Transformer
14.4 探索我们无法访问的模型
14.5 本章小结
14.6 练习题
> 第15 章 从NLP 到计算机视觉
15.1 选择模型和生态系统
15.2 Reformer
15.3 DeBERTa
15.4 Transformer 视觉模型
15.5 不断扩大的模型宇宙
15.6 本章小结
15.7 练习题
> 第16 章 AI 助理
16.1 提示工程
16.2 Copilot
16.3 可以执行领域特定任务的GPT-3 引擎
16.4 基于Transformer 的推荐系统
16.5 计算机视觉
16.6 数字人和元宇宙
16.7 本章小结
16.8 练习题
第17 章 ChatGPT 和GPT-4
17.1 超越人类NLP 水平的Transformer 模型:ChatGPT和GPT-4
17.2 ChatGPT API
17.3 使用ChatGPT Plus 编写程序并添加注释
17.4 GPT-4 API
17.5 高级示例
17.6 可解释AI(XAI)和Whisper语音模型
17.7 使用DALL-E 2 API入门
17.8 将所有内容整合在一起
17.9 本章小结
17.10 练习题
附录A Transformer 模型术语
附录B Transformer 模型的硬件约束
附录C 使用GPT-2 进行文本补全
附录D 使用自定义数据集训练GPT-2 模型
附录E 练习题答案 参考资料
朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















