介绍
通过数据库管理系统, 编写执行SQL语句, 实现对数据库数据的管理
- 数据库(DataBase): 储存和管理数据的仓库
- 数据库管理系统(DBMS): 操作和管理数据库的软件
- SQL语言: 操作关系型数据库的通用语言
- 数据库可以分为关系型数据库和非关系型数据库
相关产品
常见的关系型数据库产品


数据库设计
1.mysql概述
1.分类
官方提供了商业版和社区版

2.安装
根据安装文档 下载安装 mysql 到本机

- 官网: https://dev.musql.com/downloads/mysql/
- 验证: cmd->mysql->有提示
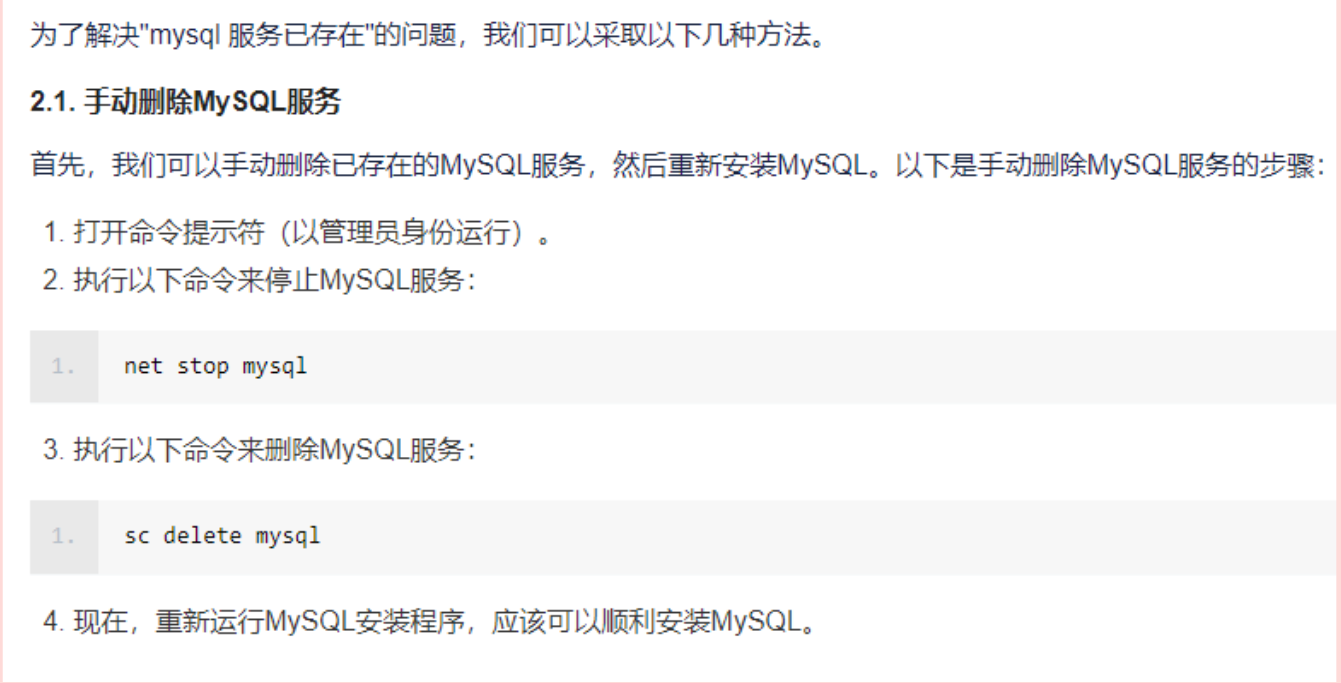
- 意外: 注册mysql服务报错
3.常用命令
- net start mysql // 启动服务
- net stop mysql // 停止服务
- mysql -uroot -p1234 // 登录数据库
- exit //退出登录
4.远程数据库
企业中开发时会使用远程数据库, 因为要多人协作

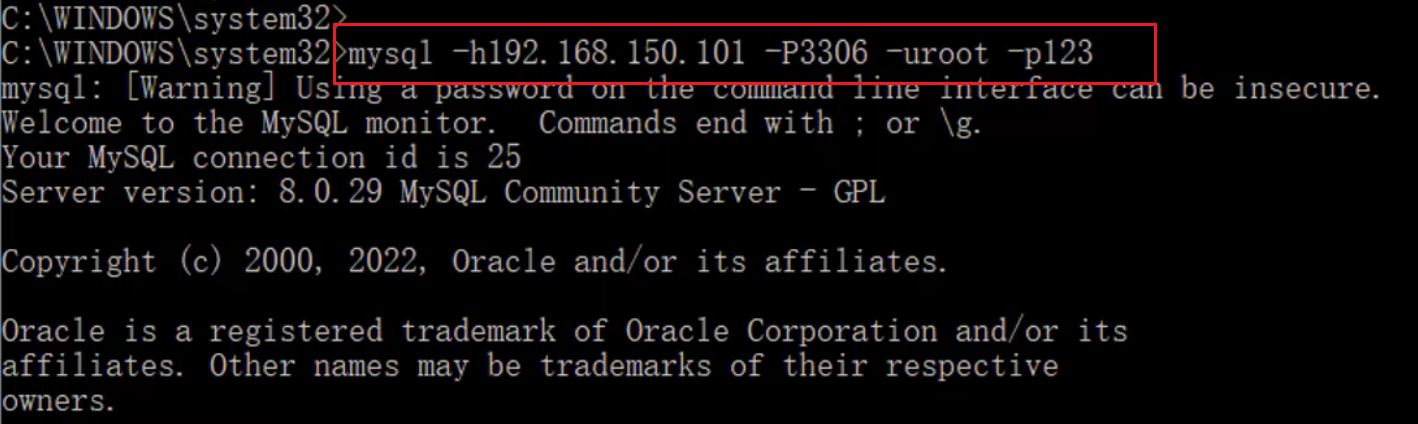
- 命令: mysql -u用户名 -p密码 -h要连接的mysql服务器的ip地址 -p端口号
- 默认服务器地址127.0.0.1
- 默认程序端口号3306
4.关系型数据库
建立在关系模型基础上,由多张相互连接的二维表组成的数据库
- 使用表存储数据, 格式统一,便于维护
- 使用SQL语言,标准统一, 使用方便, 可以用于复杂查询
5.数据模型
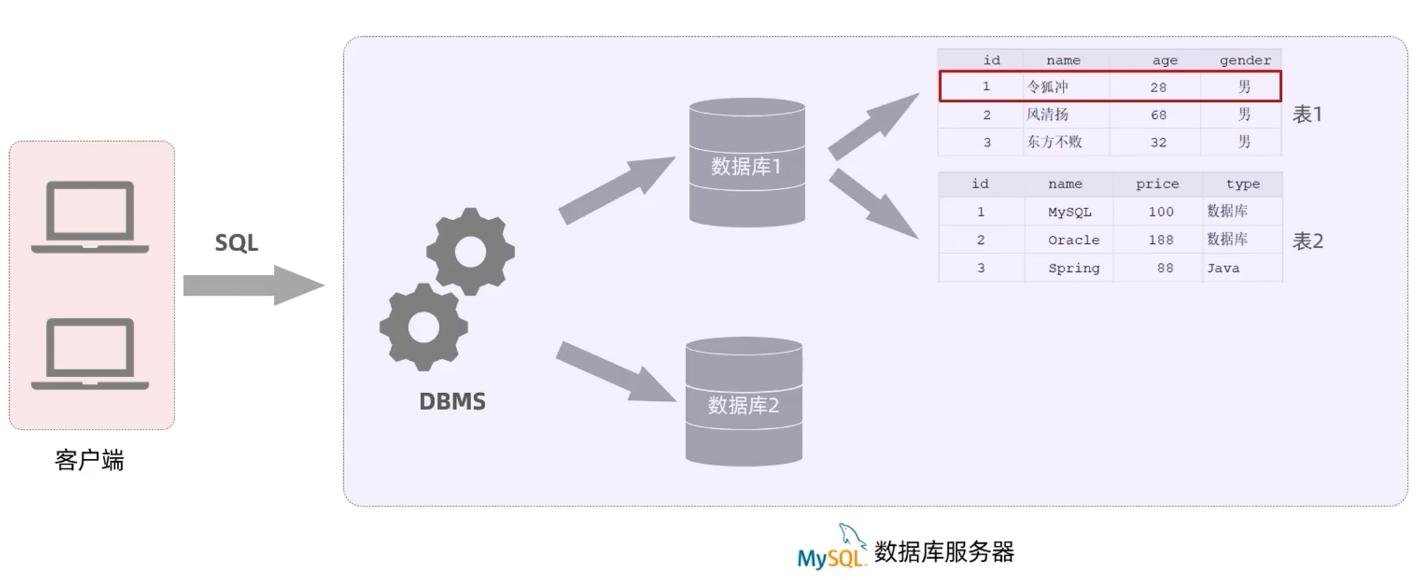
- MySql数据库服务器自带数据库操作系统(DBMS)
- 在客户端编写SQL语句, 数据库操作系统执行sql语句操作数据库
- 一个数据库服务器可以创建多个数据库
- 一个数据库可以创建多张数据表
- 一张数据表可以记录多行数据
6.通用规则
SQL是一种操作关系型数据库的编程语言, 定义操作所有关系型数据库的统一标准
- 可以写单行也可以写多行, 必须分号结尾
- 可以使用 空格和缩进 增强代码的可阅读性
- SQL语句不区分大小写
- 单行注释: --注释内容 或 #注释内容
- 多行注释: /* 注释内容 */

7.语句分类
SQL语句通常分为4大类

2.数据库设计DDL
1.数据库操作

- 上述语法中的database, 也可以替换成schema, 比如 create scheam ds01;
2.数据表操作


约束
作用在字段上的规则, 用于限制存储在表中的数据


- 目的: 保证数据库中数据的正确性, 有效性, 完整性
数据类型
- 数值类型

- num tinyint -> 表示有符号的tinyint类型, 取值在-128-127之间
- age tinyint unsigned -> 表示无符号的tinyint类型, 取值在0-255之间, 不出现负数, 适合年龄数据
- scoredouble(4,1) -> 4位数字,1位小数,即最大值999.9, 适合分数数据
- 字符串类型

- char(10) -> 定长字符串, 即长度固定, 最多只能储存10字符, 超出报错, 不足10个字符,也占用10个字符
- 特点: 占用的空间固定, 性能好, 可能会浪费空间
- varchar(10) -> 变长字符串, 即长度不固定, 最多只能存10个字符, 超出报错, 不足10个字符, 按照实际长度存储
- 特点: 根据实际长度占用空间, 节省空间, 计算的过程会损耗性能
- phone char(11) -> 表示11位固定长度的字符串, 适合手机号
- unsername varchar(20) -> 表示最多存储20个字符, 不足20按实际长度存储, 适合用户名
- 日期时间类型

- birthday date -> 日期类型, 表示生日日期
- updatetime datetime -> 日期时间, 表示更新时间
操作语句

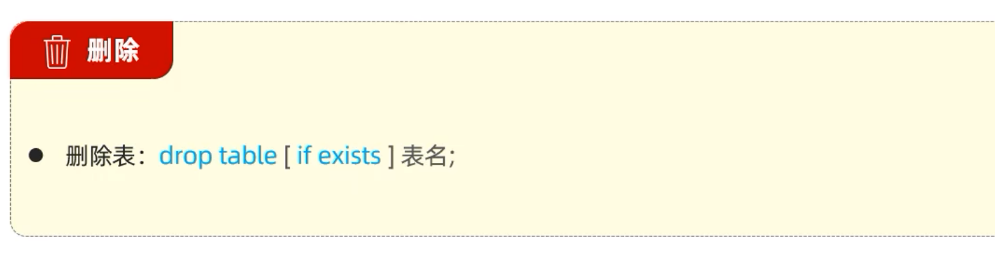
- 在删除表时, 表中的全部数据也会被删除

数据库操作
1.数据操作DML
DML全称数据操作语言, 用来对数据表的数据进行增删改查操作

// 指定字段添加数据
insert into tb_emp(username,name,gender,update_time) values ('wuji','张无忌',1,now());// 指定字段批量添加数据
insert into tb_emp(username,name,gender,update_time) values ('weiyixiao','韦一笑',1,now()), ('xiexun','谢逊',1,now());// 全部字段批量添加数据
insert into tb_emp values (null,'zhiruo','周芷若',2,'2010-01-01',now()), (null,'sanfeng','张三丰',1,'2000-10-01',now());
- 插入数据时, 指定的字段顺序需要与值的顺序对应起来
- 字符串和日期型数据应该包含在引号内
- 插入数据的大小, 应该在字段的规定范围内, 否则报错
- 可以通过SQL的 now()函数 获取系统当前时间
- 主键自定的数据插入时传入null即可

根据条件更新指定的数据
update tb_update set name = '张三' , update_time = now() where id = 1;没有条件则更新整张表的数据
update tb_update set entrydate = '2001-12-10' , update_time = now();- 更新整张表数据会出现警告, 点击执行即可


// 根据条件删除数据
delete from tb_emp where id = 1;// 删除所有数据
delete from tb_emp;- 更新整张表数据会出现警告, 点击执行即可

- delete语句不能删除某一个字段的值, 如果需要, 可以使用update语句将字段的值置为null
2.数据查询DQL


基础查询

// 查询指定字段
select name,entrydate, from tb_emp;// 查询全部字段
select * from tb_emp;// 设置别名
// as关键字可以省略
select name as 姓名, entrydate as 入职日期 from tb_emp;// 去除重复记录
// 不去重的结果: 1,2,2,1,3,3,4,
// 去重的结果: 1,2,3,4
select distinct job from tb_emp;- 少使用 * 号, 不直观, 性能低, 建议罗列全部字段名
- 如果设置的别名需要出现空格或特殊字符, 需要使用引号包裹, 不然报错
条件查询

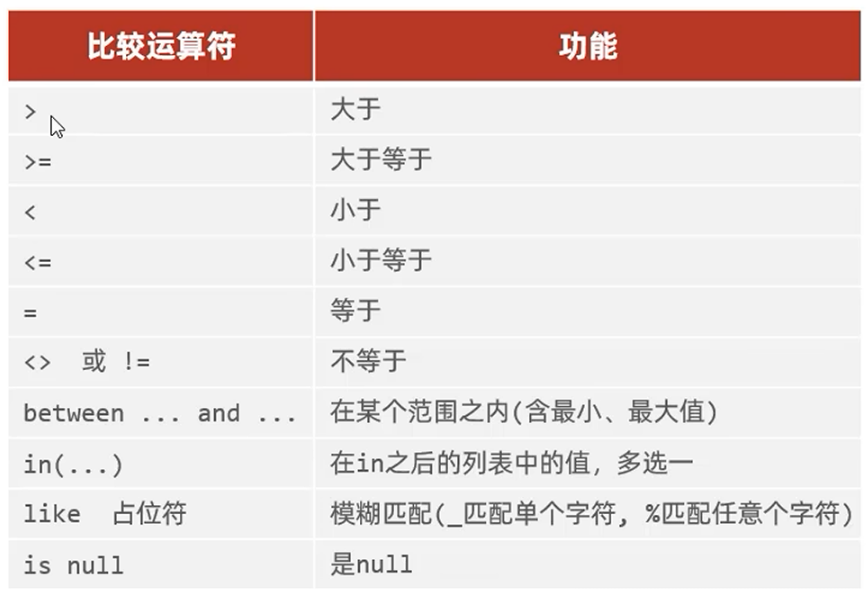

// 查询姓名为 杨逍的员工
select * from tb_emp where name = '杨逍';// 查询id 小于等于5 的员工
select * from tb_emp where id <= 5;// 查询没有分配职位的员工
select * from tb_emp where job is null;// 查询分配了职位的员工
select * from tb_emp where job is not null;// 查询密码不等于'123456'的员工
select * from tb_emp where possword != '123456';// 查询入职日期在 2000-01-01(包含) 到 2010-01-01(包含) 的员工
select * from tb_emp where entrydate >= '2000-01-01' and enteydate <= '2010-01-01';
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01';// 查询入职日期在 2000-01-01(包含) 到 2010-01-01(包含) 的员工, 并且性别为女
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' and gender = 2;// 查询职位是 2(讲师) 3(学生主管) 4(教研主管) 的员工
select * from tb_emp where job = 2 or job = 3 or job = 4;
select * from tb_emp where job in(2,3,4);// 查询姓名为两个字的员工
select * from tb_emp where name like '__';// 查询性张的员工
select * from tb_emp where name like '张%';
聚合查询


// 统计员工数量
// 写法1: count(字段)
select count(id) from tb_emp;
// 写法2: count(常量)
select count('A') from tb_emp;
// 写法3: count(*) --推荐
select count(*) from tb_emp;// 统计最早入职的员工
select min(entrydate) from tb_emp;// 统计最晚入职的员工
select max(entrydate) from tb_emp;// 统计平均值
select avg(id) from tb_emp;// 统计和
select sum(id) from tb_emp;- null值不参与聚合函数的运算
- 统计数量推荐使用count(*), 因为数据库进行了优化
分组查询

// 根据性别分组, 统计男性和女性员工的数量
select gender,count(*) from tb_emp group by gender;// 先查询入职时间在'2015-01-01'(包含)之前的员工, 并对结果根据职位分组, 获取员工数大于等于2的职位信息
select job,count(*) from tb_emp where entrydate <= '2015-01-01' group by job having count(*) >= 2;- 分组之后, 查询的字段一般是聚合函数和分组字段, 查询其他字段没有意义
- 执行顺序: where > 聚合函数 > having
- where和having的区别:
- 执行时机不同: where是分组前执行, 不满足条件不参与分组, having是分组之后对结果进行过滤.
- 判断条件不同: where不能对聚合函数进行判断, 而having可以
排序查询


// 根据入职时间, 对员工升序排序
// asc是默认的, 可以省略
select * from tb_emp order by entrydate asc;// 根据入职时间, 对员工进行降序排序
select * from tb_emp order by entrydate desc;// 根据入职时间, 对员工进行升序排序,如果入职时间相同, 再按照更新时间降序排序
select * from tb_emp order by entrydate , update_time desc;- 如果是多字段排序, 当第一个字段值相同时, 才会根据第二个字段进行排序
分页查询

// 起始索引 = (查询页码 - 1)* 每页显示记录数;
// 葱起始索引0开始 查询员工数据,每页5条数据
select * from tb_emp limit 0,5;// 查询第1页的员工数据, 每页5条数据
select * from tb_emp limit 0,5;// 查询第2页的员工数据, 每页5条数据
select * from tb_emp limit 5,5;// 查询第3页的员工数据, 每页5条数据
select * from tb_emp limit 10,5;- 起始索引从0开始。
- 起始索引 = (查询页码 - 1)* 每页显示记录数;
- 分页查询时数据库的方言, 不同的数据库有不同的实现, mysql中是LIMT
- 如果查询的是第一页数据, 起始索引可以省略, 简写limit 10;
函数表达式
完成列表数据查询

// 根据输入条件,查询第一页数据,每页展示10条
// 姓名:张, 性别:男, 入职日期: 2000-01-01 2015-12-31
select *
from tb_emp
where name like '%张%'and gender = 1and entrydate between '2000-01-01' and '2015-12-31'
order by update_time desc
limit 0,10;完成员工数据统计


// 员工性别统计
// if(条件表达式, true取值, false取值)
select if(gender = 1, '男性员工', '女性员工') as 性别,count(*)
from tb_emp
group by gender;// 职位信息统计
// case 表达式 when 值1 结果1 [when 值2 结果2] [else 默认结果] end
select (case job when 1 then '班主任' when 2 then '讲师' when 3 then '学生主管' when 4 then '教研主管' else '未分配职位' end) as 职位,count(*)
from tb_emp
group by job;3.多表操作
多表设计
在项目开发中, 由于业务之间相互关联, 所以各个表结构之间也存在着各种联系
表关系可以分为一对多, 多对多, 一对一
一对多
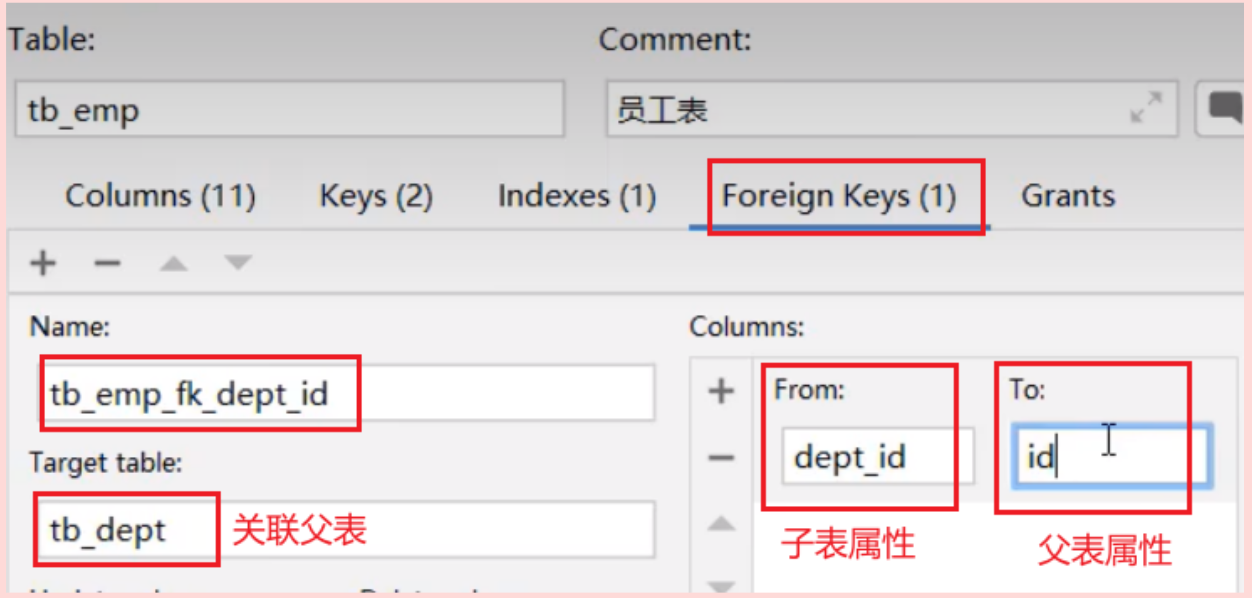
关系实现: 在数据库表中多的一方(子表),添加外键字段关联另一方(父表)的主键。


外键约束
作用: 让两张表的数据建立关联, 保证数据的一致性和完整性


物理外键
概念: 使用 foreign key 定义外键关联另一张表

// 建表时指定
create table 表名( 字段名 数据类型, ...[constraint] [外键名称] foreign key (外键字段名) references 主表 (字段名)
);// 建表后添加
alter table 表名
add constraint 外键名称
foreign key(外键字段名) references 主表(字段名);如果使用了逻辑外键, 可以图形化的查看多表之间的关系

逻辑外键

一对一
实现: 在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
一对一关系, 多用于单表拆分, 将一张表的基础字段放在一张表中, 其他字段放在另一张表中, 以提升操作效率
示例: 用户与身份信息

// 用户表
create table tb_user (id int auto_increment primary key comment '主键ID',name varchar(10) not null comment '姓名',gender tinyint unsigned not null comment '性别, 1男,2女', phone char(11) comment '手机号',degree varchar(10) comment '学历'
) comment '用户表';insert into tb_user values (null,'白眉鹰王',1,'15552388198','小学'),(null,'青翼蝙王',1,'18818881111','大专');// 用户信息表
create table tb_student (id int auto_increment primary key comment '主键ID',nationality varchar(10) not null comment '民族',birthday date not null comment '生日',idcard char(18) not null comment '身份证号'user_id int unsigned not null unique comment '用户id',constraint fk_user_id foreign key (user_id) refrences tb_user(id)
) comment '用户信息表';insert into tb_student(name,no) values (null,'汉','1900-12-12','100000110000000000',1),(null,'汉','1900-12-12','100000110000000000',2),(null,'汉','1900-12-12','100000110000000000',2);多对多
实现: 建立第三张中间表,中间表至少包含两个外键,分别关联两方主键

实例: 学生与课程
// 学生表
create table tb_student (id int auto_increment primary key comment '主键ID',name varchar(10) comment '姓名',no varchar(10) comment '学号'
) comment '学生表';insert into tb_student(name,no) values ('黛丽丝','2000100101'),('谢逊','2000100102');// 课程表
create table tb_course (id int auto_increment primary key comment '主键ID',name varchar(10) comment '课程名称'
) comment '课程表';insert into tb_student(name) values ('java'),('php'),('mysql');// 中间表
create table tb_student_course (id int auto_increment primary key comment '主键ID',student_id int not null comment '学生id',course_id int not null comment '课程id',
) comment '学生课程中间表';insert into tb_student_course(student_id,course_id) values (1,1),(1,2),(2,3),(3,4);设计流程
1.阅读页面原型和需求文档, 分析各个模块涉及到的表结构, 以及表结构之间的关系

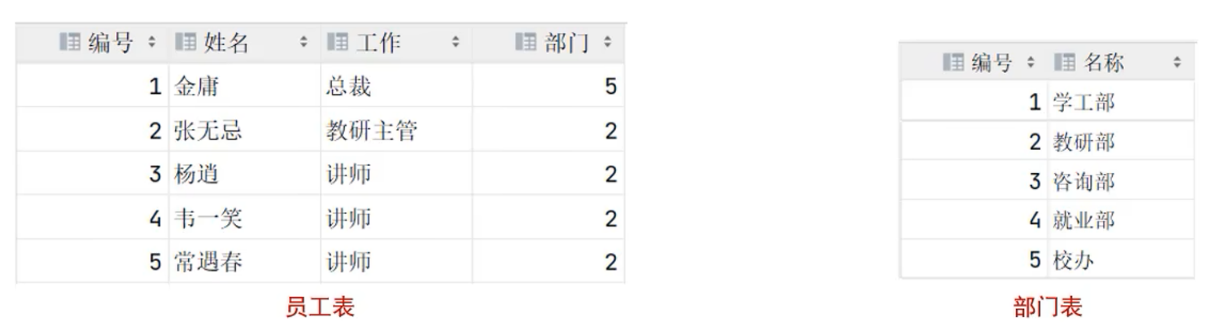
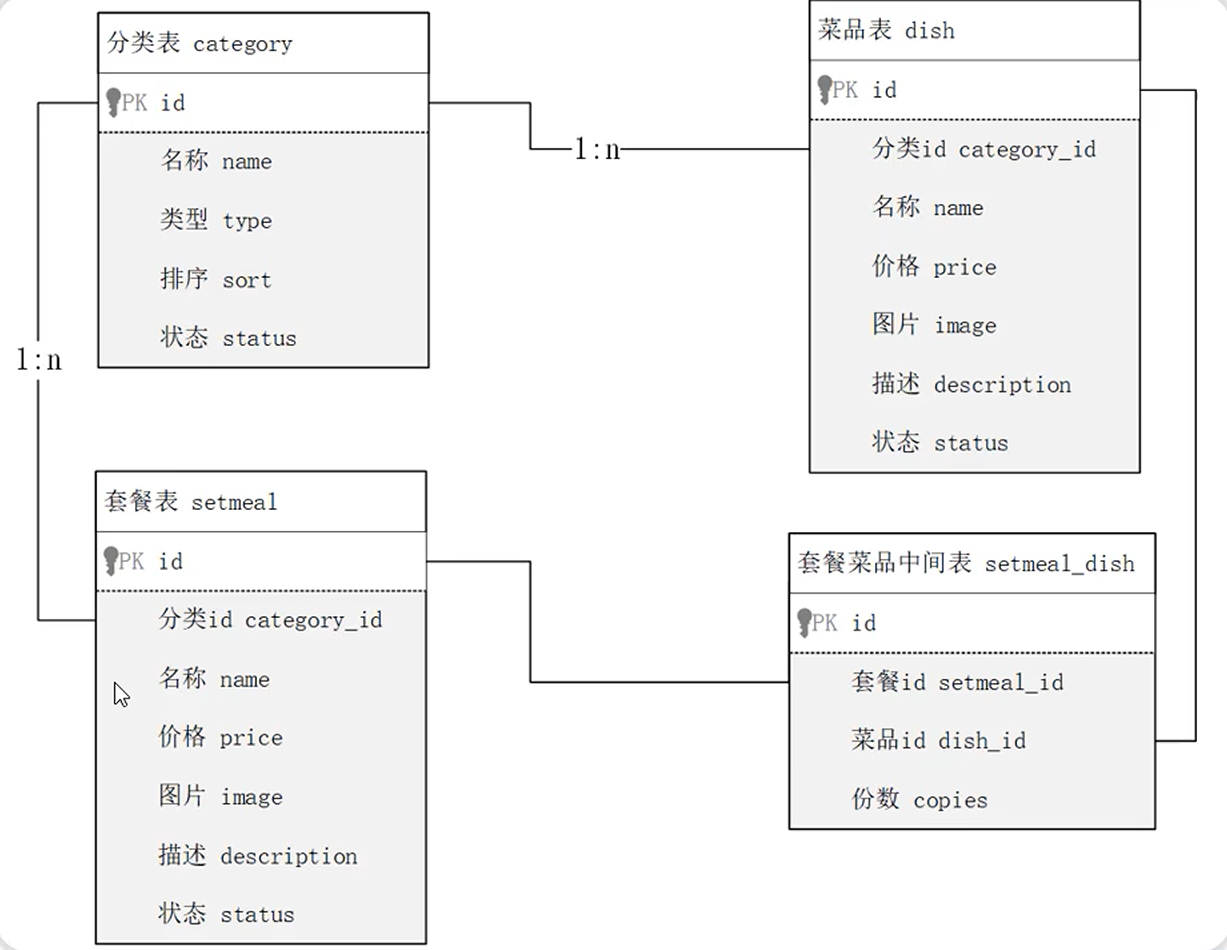
- 分类表和菜品表是一对多的关系, 一个分类下可以有多个菜品, 一个菜品只能归属一个分类
- 分类表和套餐表是一对多的关系, 一个分类下可以有多个套餐, 一个套餐只能归属一个分类
- 菜品表和套餐表是多对多的关系, 一个菜品可以归属多个套餐, 一个套餐下可以有多个菜品
2.根据页面原型以及需求文档, 分析各个表结构中具体的字段以及约束



多表查询
概念: 从多张表中查询数据
// 多表查询
select * from tb_emp, tb_dept;
笛卡尔积: 在数学中, 两个集合的所有组合情况被称为笛卡尔积, 在多表查询时, 需要消除无效的笛卡尔积
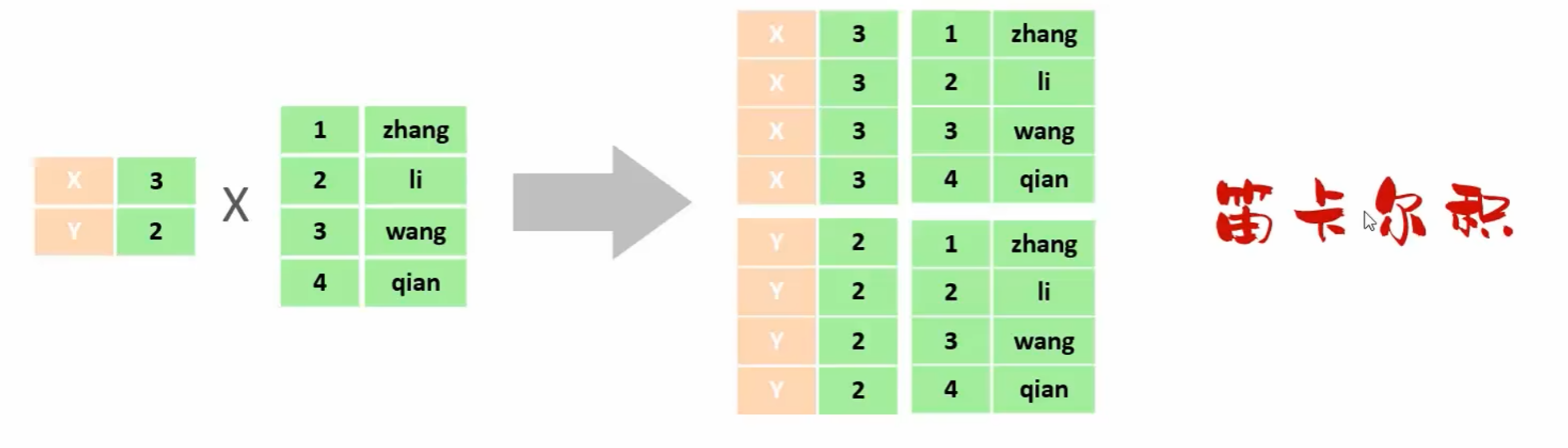
// 有效多表查询
select * from tb_emp,tb_dept where tb_emp.dept_id = tb_dept.id;1.连接查询
内连接
相当于查询A,B两个表 交集部分 的数据, 没有交集的数据查询不出来

// 使用隐式内连接, 查询员工的姓名, 以及所属部门的名称
select tb_emp.name,tb_dept.name from tb_emp,tb_dept where tb_emp.dept_id = tb_dept.id;// 使用显式内连接, 查询员工的姓名, 以及所属部门的名称
select tb_emp.name,tb_dept.name from tb_emp inner join tb_dept on tb_emp.dept_id = tb_dept.id;// 起别名
select e.name, d.name from tb_emp e , tb_dept d where e.dept_id = d.id;

外连接
查询两张表 交集部分 的数据, 同时把其中一张表的数据全部查出来, 包括无交集的数据

- 左外连接: 完全包含左表数据, 以及两张表交集部分的数据
- 右外连接: 完全包含右表数据 , 以及两张表交集部分的数据
- 推荐使用左外连接
// 左外连接, 查询员工表所有员工的姓名和对应的部门名称
select e.name,d.name from tb_emp e left join tb_dept d on e.dept_id = d.id;// 右外连接, 查询员工表所有员工的姓名和对应的部门名称
select e.name,d.name from tb_emp e right join tb_dept d on e.dept_id = d.id;
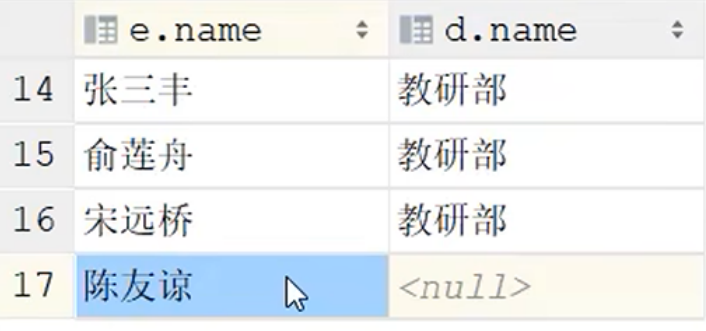
2.子查询
SQL语句中嵌套select语句, 称为嵌套查询, 又称子查询
- 子查询外部语句可以是insert update delete select , 常见的是select
- 子查询语句较长, 可以分步实现, 然后再组合语句


// 标量子查询
// 查询教研部的所有员工信息
// select id from tb_dept where name = '教研部';
// select * from tb_emp where dept_id = 2;
select * from tb_emp where dept_id = (select id from tb_dept where name = '教研部');// 查询在方东白入职之后的员工信息
// select entrydate from tb_emp where name = '方东白';
// select * from tb_emp where entrydate > '2010-01-1';
select * from tb_emp where entrydate > (select entrydate from tb_emp where name = '方东白');


// 列子查询
// 查询教研部和咨询部的所有员工
// select id from tb_dept where name = '教研部' or name = '咨询部';
// select * from tb_emp where dept_id in (3,2);
select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部');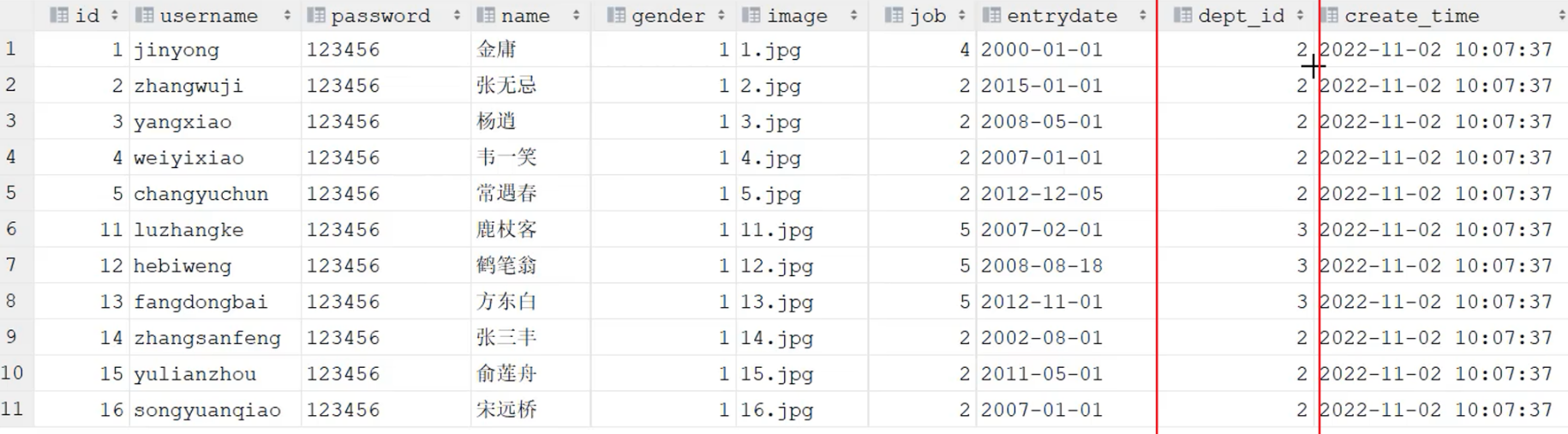

// 行子查询
// 查询与韦一笑入职日期及职位相同的员工信息
// select entrydate,job from tb_emp where name = '韦一笑';
// select * from tb_emp where entrydate = '2007-01-01' and jon = 2;
// select * from tb_emp where (entrydate,job) = ('2007-01-01',2);
select * from tb_emp where (entrydate,job) = (select entrydate,job from tb_emp where name = '韦一笑');
// 表子查询
// 查询入职日期是2006-01-01之后的员工信息, 以及部门名称
// select * from tb_emp where entrydate > '2006-01-01';
select e.*, d.name from (select * from tb_emp where entrydate > '2006-01-01') e, tb_dept d where e.dept_id = d.id; 3.案例
// 1.查询价格低于10元的菜品的名称,价格以及所属的分类名称
// 表: dish category
select d.name,d.price,c.name
from dish d, category c
where d.category_id = c.idand d.price < 10;// 2.查询所有价格在 10(包含)到50(包含)之间 且 状态为起售的菜品, 展示菜品的名称,价格,菜品分类名称(即使菜品没有分类,也要展示出来)
// 表: dish category
select d.name,d.price,c.name
from dish d, left join category c on d.category_id = c.id
where d.price between 10 and 50 and d.status = 1;// 3.查询每个分类下最贵的菜品, 展示出分类的名称,最贵菜品的价格
// 表: dish , category
select c.name, max(d,price)
from dish d, category c
where d.category_id = c.id
group by c.name;// 4.查询各个分类下菜品状态为起售, 并且该分类下菜品总数量大于等于3的分类名称
// 表: dish category
select c.name, count(*)
from dish d, category c
where d.category_id = c.idand d.status = 1
group by c.name
having count(*) >= 3;// 5.查询上午套餐A中包含的菜品, 展示套餐名称,价格,包含菜品名称,价格,份数
// 表 setmeal setmeal_dish dish
select s.name,s.sprice,d.name,d.price,sd.copies
from setmeal s,setmeal_dish sd,dish d
where s.id = sd.setmeal_idand sd.dish_id = d.idand s.name = '商务套餐A';// 6.查询出低于菜品评价价格的菜品,展示菜品名称,菜品价格
// 表: dish
// select avg(price) from dish;
select dish.name,dish.price from dish where price < (select avg(price) from dish;);
数据库优化
事务
事务是一组操作的集合, 事务把一组操作看成一个整体, 这组操作要么全部成功, 要么全部失败
// 1.开启事务:
start transaction;// 正常操作
delete from tb_dept where id = 3;
// 模拟失败
delete from tb_emp where dept_id == 3;// 2.提交事务:
commit;// 3.回滚事务:
rollback;// 4.关闭事务:
begin;四大特性(ACID)

- 原子性: 事务是不可分割的最小单元, 要么全部成功, 要么全部失败
- 一致性: 事务完成时, 必须使所有的数据都保持一致状态
- 隔离性: 数据库系统提供的隔离机制, 保证事务在不受外部并发操作影响的独立环境下运行
- 持久性: 事务一旦提交, 它对数据库中的数据的改变就是永久的
索引
1.介绍
索引(index) 是帮助数据库 高效获取数据的 数据结构

- 无索引的情况下, 数据库查找数据的方式是全表扫描, 从前到后依次查找数据
- 有索引的情况下, 数据库查找数据的方式是索引匹配, 通过几次对比就可以定位数据
- 索引的本质就是一张表, 作用类似于书的目录, 可以快速定位内容所在页码
- 在600万的数据中查找一条数据, 全表扫描耗时约13m, 索引匹配耗时约5ms

2.结构
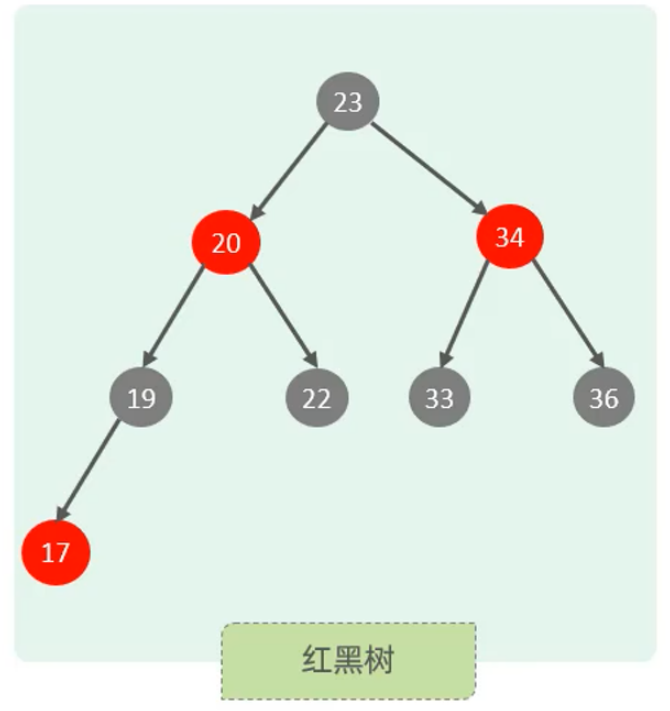
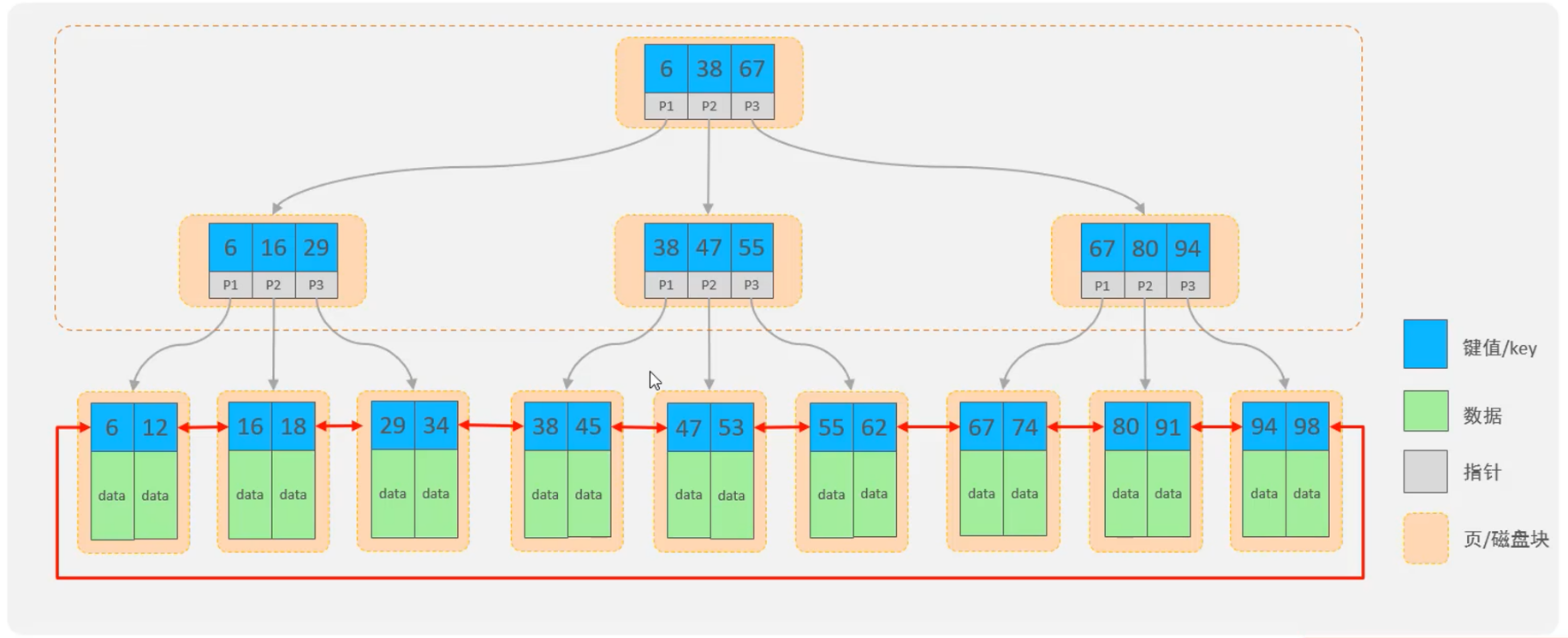
MySql数据支持的索引结构有很多. 如Hash索引, B+Three索引, Full-Test索引, 如果没有特别说明, 默认是B+Three结构的索引

- 优势
- 多路平衡搜索树, 首先是平衡树, 避免瘸腿现象, 带有排序的特点,
- 与红黑树树相比, 索引节点包含多个值, 使得整颗树的高度更合理,
- 整体特征就是矮胖, 一般树的高度是3或4层
- 在大数量的情况下,层级越深, 检索速度越慢
- 特点
- 每一个节点, 都可以储存多个key,(有n个key, 就有n个指针),
- 所有的数据都储存在叶子节点, 非叶子节点仅用于索引数据
- 叶子节点形成了一课双向链表, 而且是有序的, 便于数据的排序以及区间范围查询
3.语法

// 为tb_emp表的name字段创建一个索引
create index idx_emp_name on tb_emp(name);// 查询tb_emp表的索引信息
show index from tb_emp;// 删除tb_emp表中name字段的索引
drop index idx_emp_name on tb_emp;- 主键字段, 在建表时, 会自动创建主键索引, 主键索引的查询效率最高
- 添加唯一约束时, 数据库实际上会添加唯一索引
语句优化
分库分表
图形化工具
DataGrip是一款数据库管理工具, 是管理和开发MySql, Oracle, PostgreSQL的理想解决方案
- 官网: https://www.jetbrains.com/zh-cn/datagrip/
- 安装:参考资料中提供的安装手册
- IDEA中已经集成了DataGrip插件
- 其他工具

1.连接
选择 Datebase -> +号 -> Data Source -> MySQL
连接信息

下载驱动
2.数据库操作
- 数据库列表: 点击loaclhost旁边的数字 -> All schemas
- 新建数据库: 右键loaclhost -> new -> Scheam
- 删除数据库: 右键数据库 -> Drop
- 切换数据库: 下拉选择

- 打开命令面板: 右键loaclhost -> Jump ti Query Console -> open default console
3.数据表操作
建表流程
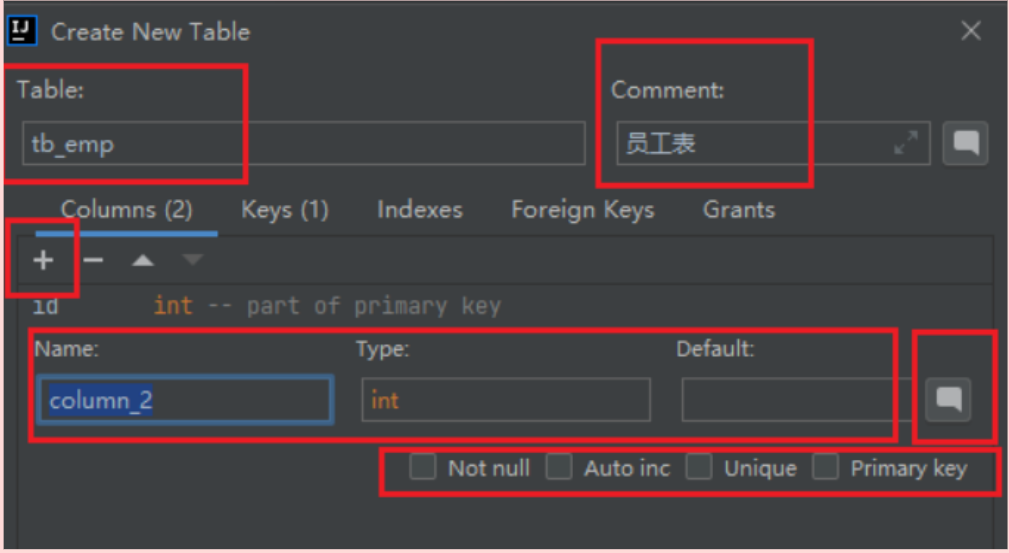
依据页面原型和需求, 设计表中的每个字段( 字段类型 字段的约束 ) , 再添加一些通用字段, 形成一张数据表,

添加表
操作步骤: 右键数据库 -> New -> Table

操作表
- 查看表
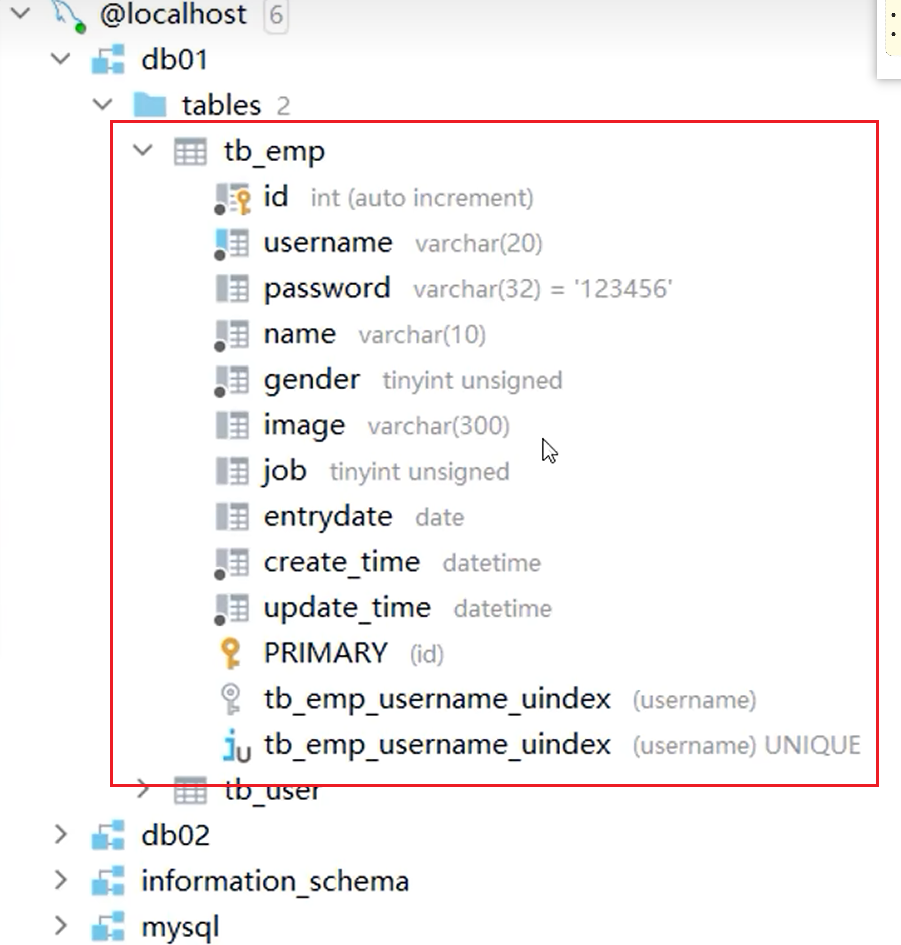
- 进入表: 双击表名
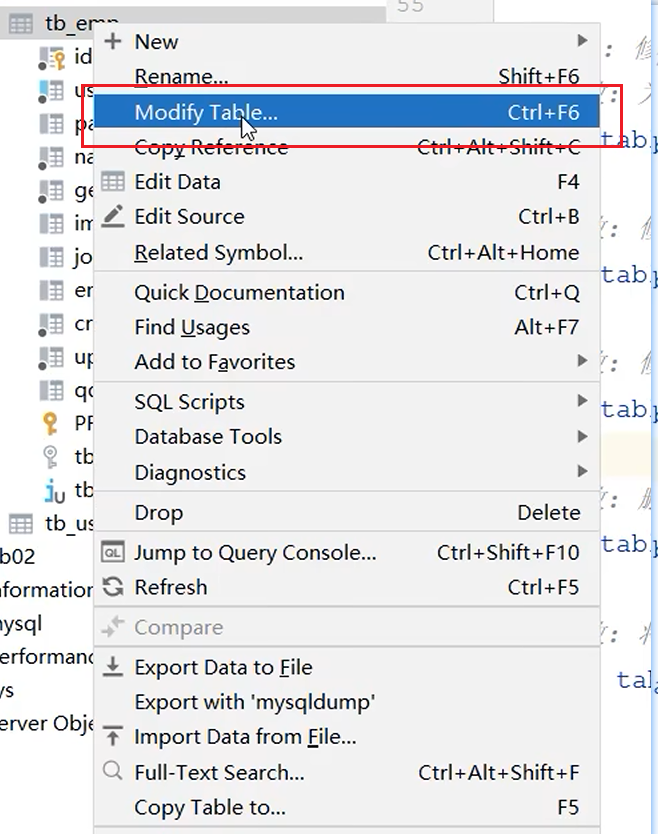
- 编辑表
- 右键表 -> Modify Table

- 添加外键约束
- 修改表名: 右键表 -> Rename
- 查询建表语句: 右键表 -> Go to DDL
- 删除表: 右键表 -> Drop

操作数据
- 添加数据:
- 双击进入表
- 加号 -> 添加数据
- 上箭头 -> 保存数据