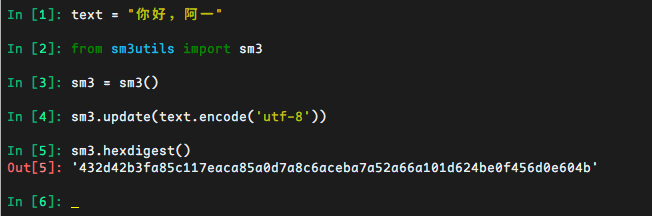
算法:
1.提取二进制位最右边的
r = i & (~i + 1)
2.树上两个节点最远距离,先考虑头结点参与不参与。

3.暴力递归改dp。
1.确定暴力递归方式。
2.改记忆化搜索
3.严格表方式:
分析可变参数变化范围,参数数量决定表维度、
标出计算的终止位置、
标出不用计算直接出答案的位置,根据暴力递归中的basecase、
推出普遍位置如何依赖其他位置、
确定依次计算的顺序,跟递归顺序一致。
4.得到精致版dp,如斜率优化。
4.动态规划尝试模型
从左往右,范围尝试
5.尝试的好坏:
1.单参的维度(如int类型和数组)。决定参数范围
2.参数的个数
5.有序表包括:
1.红黑树、2.avl树,3.sb树,4.跳表
6.绳子问题用滑动窗口
7.打表法。
循环参数,暴力打印结果,根据结果找到规律。憋出表达式。
8.预处理
9.二维表问题关注宏观设计,不要关心局部实现。
10.两个队列可以实现栈,两个栈可以实现队列。
11.动态规划dp表空间压缩技巧。
12.菲波拉契数列复杂度从n优化到logn。
相同类型问题通用。
几阶问题会生成几阶的行列式。

计算某数的次方。降为logn。

13.注意数字越界
math.MaxInt
14.假设答案法。
假设答案,用尽量简单的流程找到答案。
15.压缩数组
看到子矩阵,先想子数组。

16.优化动态规划
从数据状况入手,从问题本身入手。
17.递归死循环,要根据实际增加平凡边界。

18.看到子串和子数组问题,就想以每个字符结尾会怎样。
19.舍弃可能性
20.dp斜率优化,当有枚举行为时,使用临近格子的值代替枚举行为。(凑面值问题)
21.寻找等长有序的两个数组上中位数。

22.约瑟夫环问题,可推理数学公式:老的编号=(新的编号 + m -1)% i + 1
m:数到哪个编号淘汰
i:本轮一共多少人

23.有序表增删改查都是O(logn)
24.有单调性用滑动窗口。无单调性用 前缀和 map

25.动态规划压缩技巧,从dp表压缩到数组,从数组压缩到变量。


26.尝试模型
从左往右、范围上尝试、两个字符串对应
范围尝试模型,重点讨论开头和结尾
范围尝试模型指在这样的可能性分类下,能不能把整个域上的问题解决。
从i开始到j结尾的可能性讨论下,能不能解决该问题。
一般来说子序列问题。
27.bfprt算法

28.如果没有枚举行为,停留在记忆化搜索就行,如果有,则改为dp表,尝试进行斜率优化。
29.二叉树的递归套路,父节点找左右子树要信息,往上传递。
30.完美洗牌问题

abcde123字符串,原地变为123 abcde:
abcde逆序,变为edcba;123逆序变为321;整体逆序,变为123abcde.

31.递归大问题调小问题,一定要保证,大问题所做决策的所有影响都已经体现在小问题的参数上了。让小问题再决策时有信息可用。(无后效性递归)
32.arr[start] 到 arr[i]的异或和 = arr[0] 到 arr[i] 的异或和 异或 arr[0] 到 arr[start] 的异或和。
33.前缀树


34.不会碰到的递归状态,dp填表的时候别填。
观察好,哪些位置不需要填。
初始位置根据basecase填好,终止位置是哪个。
普遍位置怎么依赖,规定好填写顺序。
35.滑动窗口+负债表

36.二维图形问题,转为一维线段问题求解。

golang:
map:
1.k是可比较类型,切片,func和map是不可比较的。struct中至少有一个字段是可比较的。
2.写数据时如果map没有初始化,将会panic,删除时如果没有初始化,不会报错。
3.map中有2的整数次幂的桶数组。桶中固定装8个kv,超过放在溢出桶。
4.解决哈希冲突时兼顾了拉链法和开放地址法。

5.扩容分为增量扩容和等量扩容。
增量扩容阈值:kv数量/桶数量 > 6.5时。
等量扩容:溢出桶数量 > 2^B ,B为桶数组长度的指数,2^B即桶的个数。
6.扩容时kv的迁移位置是固定的,要么在原位置,要么在原位置+原来桶长度的位置。

7.bucket中不仅存储kv,还存储了hash值的高8位。
8.初始化map时,会根据数组长度预先创建溢出桶。
9.如果正在扩容状态,先判断旧桶中的标识,是否迁移完。如果迁移完,去新桶中查询。
10.tophash有特殊标识,标识以后的位置都是空。
11.写或删除数据时如果正在扩容,进行辅助扩容。
12.写数据时判断是否需要进行增量或等量扩容。
13.桶中每个槽位都有tophash,emptyone(当前位置被删除)和emptyrest(之后的位置都为空)。这两个值都是删除的时候设置的。
14.如果正在迁移,先遍历新桶。
15.遍历时如果桶正在迁移,按照已经迁移完的顺序遍历。
16.根据oldbucket是否为空判断是否处于扩容阶段。
17.如果处于扩容阶段,每次写操作会帮助map进行扩容,1.帮助自己要写入或删除的桶,2.帮助索引最小的桶。
18.map不支持并发操作的主要原因是因为采用的渐进式扩容机制。
sync.map:
空间换时间
1.sync.map结构包括四个字段,锁,只读value,读写map,和miss次数。

2.entry的状态有3种,1:正常,2:软删除,3:硬删除。
软删除的作用是,如果刚删的数据要重新插入,不需要重新加锁,只需要对entry的指针进行原子操作即可。
3.miss次数>=写map的kv数,把写map覆盖读map。同时把读map中的amemded flag置为false。写map置为空。
4.因为读写map的value存储的都是指针,所以插入数据时,如果kv还存在是软删除状态,直接使用cas更新,不需要加锁。
5.插入完数据后,如果amended flag是true,就要将写map拷贝到读map。
6.插入数据时,如果写map是空,需要从读map拷贝一份到写map。
7.写map拷贝到读map时是直接全量覆盖,读map拷贝到写map时,需要过滤软硬删除的数据,量比较重。
8.写多读少时性能较低,写指的是插入,如果是更新性能还好。

9.删除如果读map中有,就置为软删除态。如果读map中没有且amended flag是true,就在写map中物理删除。也会触发misscount的增加。
10.执行遍历时,会判断读map的数据是不是完整的,如果不是,进行写map的覆盖。
11.软删除态和硬删除态:
软删除态是指读map和写map都有这个kv,只是v的指针指向软删除常量。
硬删除态是指读map中有这个kv,但是写map没有。
硬删除态只发生在写数据时,读map向写map拷贝数据,写map会过滤掉软硬删除态的数据,读map同时要把软删除态变为硬删除态。

12.通过读写map的相互复制,实现内存回收,避免内存泄露。


锁:
1.锁冲突解决方式:

阻塞/唤醒属于悲观锁。
自旋+CAS属于乐观锁。
2.golang是两种结合。
四次自旋未果之后,陷入阻塞。
或者cpu是单核的,直接进行阻塞/唤醒。
当前p后面还有待执行的g。
3.饥饿模式:
有g长时间得不到锁,将抢锁的流程从非公平模式转到公平模式。
进入条件:存在协程1ms没有获取到锁。
退出条件:没有阻塞队列,或者队列中没有等待时间超过1ms的协程。
4.正常模式:阻塞队列头部协程被唤醒,和刚到达的协程竞争锁。如果失败,重新回到队列头部。
5.饥饿模式:新进入的协程不能竞争锁,只从阻塞队列遵循先进先出。

6.饥饿模式会带来性能损耗。



7.先尝试使用cas加锁。bit整体是0,才会加锁成功。
8.当有等待协程被唤醒时,判断是否需要退出饥饿状态。
读写锁:

9.添加读锁是使用cas方法对readercount+1,如果加完是负值说明添加失败,说明有写锁。因为在添加写锁时readercount字段会直接减最大值。
10.解锁时对readercount字段-1,如果减完是负值,说明有写锁在等待,尝试唤醒。

11.释放写锁之后,唤醒所有读等待的协程。
12.如果有写锁阻塞,读锁也不可获取。
13.添加写锁会把当前读锁的数量放到readerwait中,此时readercount也被更新为负值,之后就不会有读锁进来。

切片:
1.在作为参数传递时,是进行的值拷贝,但是结构体内部存储的是指向数组的指针。

map也会如此:

2.切片的结构:

len:逻辑意义上切片中实际存放了多少个元素。
cap:物理意义上的容量。
3.没有初始化的切片也可以进行append。
4.截取切片为左闭右开。截取完之后的新切片,还是指向同一底层数组。
5.append操作在容量不足时才会扩容。
6.扩容时,需要的容量大于老容量的2倍,直接取新容量。
如果容量小于256,翻倍扩容。否则每次扩容1/4并累加上192,直到大于等于预期容量。
最后根据元素类型结合go的内存分配机制,向上取整,找到合适的容量。
将原数组拷贝到新数组,切换指针,完成拷贝。

7.切片的删除操作只能使用截取拼接实现。
8.使用系统方法copy可以实现切片的深拷贝。




context:
1.生命周期的终止事件传递的单调性。由上往下传递。
2.context.Backgroud()和context.todo()返回的都是空context。
3.cancelContext的核心为开启一个守护协程,在父终止时,终止子。

4.timerContext继承cancelContext。
5.valueContext只能存储一个key-value,获取时如果当前Context不存在会一直向父节点查找。
6.valueContext的读取代价很高,而且相同的key不会覆盖,在不同位置会取到不同的value。


gmp:
1.goroutine的栈可动态扩缩容。

2.g有自己的运行栈,状态及任务函数。
3.g需要绑定p才能执行,在g的视角,p就是他的cpu。
4.goroutine相对协程最大的优化在于,goroutine将协程和线程的强绑定关系给释放了。

5.因为p的本地队列有可能被窃取,所以也会有并发访问,不能完全做到无锁。
6.g结构中存有m的指针,但不是强绑定关系,受p的调度。

7.g有自己的生命周期。


8.m中存储特殊goroutine g0,属于顶级goroutine。

9.p结构中主要是环形队列,和指向首尾的指针,以及下一个可执行的g。

10.g0负责调度,执行一直在g0到g的切换。

11.调度类型:
主动调度:用户主动调用runtime.Gosched
被动调度:如互斥锁,channel等,后续需要被唤醒。
正常调度:
抢占调度:将由全局监控goroutine monitor完成。因为此时已经进入内核态,绑定的m也失去控制。
12.schedule负责找到下一个要被执行的goroutine。

13.先从本地队列取,取不到从全局队列取,再尝试获取io就绪态的goroutine,最后从其他队列窃取一半的goroutine,放到本地队列。
每第61次,会直接从全局队列取,避免goroutine饥饿。
14.窃取会尝试4次,随机选择其他队列。
15.窃取是拨动对方队列的头指针实现的。
16.用户主动让出执行权,会将执行权转移给g0,g0将该goroutine加入全局队列。
17.全局监控goroutine是main方法启动的,会定时检查p的状态。满足条件就会进行抢占。抽离当前的p,为他分配新的m。

channel:
1.读已关闭且缓冲区为空的channel,bool返回false。
2.读已关闭channel不会陷入阻塞。
3.向已关闭channel写入数据会panic。
4.channel的缓冲区是一个唤醒数组。

5.空status类型长度为0.
6.往没有初始化的channel中写数据,goroutine会陷入异常阻塞。
7.channel写入时,如果有阻塞读goroutine。会通过memmove element直接把数据拷贝给阻塞等待的goroutine。然后唤醒读取的goroutine。


8.对于用select的情况,在读写该陷入goroutine阻塞的情况,转而进入自旋。
9.当channel被关闭时,所有阻塞的读或写goroutine都会被唤醒。写goroutine会panic。
10.避免重复关闭channel,可以用sync包的once方法。
11.for range 循环遍历channel,只要channel没关闭,就会一直读取。
sync.WaitGroup:
等待聚合模式。
1.本质上是并发计数器。
2.可以被多个goroutine监听。即wait方法可以被多个goroutine调用。
3.尽量先调用add再调用wait。
4.waitGroup是防拷贝的。指在不同的方法内也应该传递指针,不应该传递值。

5.done方法本身也是调用的add,传-1.
6.如果done之后数量为0,则唤醒所有wait goroutine。
7.核心还是利用atomic包进行计数。
8.在执行过wait之后,add的操作不应该并发执行,注意waitgroup的轮次性。

内存管理&垃圾回收
1.虚拟内存最小单位为页,物理内存最小单位为帧。
2.单位太小会影响效率,太大会造成内存碎片。Linux为4kb。
3.golang内存分配核心:以空间换时间,一次申请多次复用。利用多级缓存,实现无锁||细锁化。

4.golang页的大小为8kb。
5.mspan为最小的管理单元,大小为8kb的整数倍。从8到80被划分成67个类型。
6.mspan会减少外部内存碎片,且细化锁的粒度。
7.mspan分配的内存页都是连续的。

8.同等级的mspan属于同一个mcentral,会被前后指针组织成双向链表。
9.mspan内部会使用bitmap辅助寻找空闲的内存页。
10.mspan有隐藏等级0,上不封顶的容量。

11.spanClass有8个比特位,高7位对应等级,最低位表示nocan。nocan与垃圾回收有关。
12.每个p对应的mcache

13.每个中心缓存mcentral都对应一类spanClass。

14.全局堆缓存mheap,负责将连续页组装成span。通过heapArena记录页和span的映射关系。

15.通过空闲页基数树辅助快速寻找空闲页。
16.内存不够时,向操作系统申请,单位是heapArena,即64M。
17.每个基数树可以管理16G空间内存的占用情况,用于帮助mheap快速找到连续的未使用的内存空间。mheap一共持有2^14个基数树。

分别标识,从起点开始最大连续空闲页、最大连续空闲页、尾端最大连续空闲页。

寻找时相邻的pallocSum可以拼接。如尾部有3个空闲连续页可以和下一个头部的空闲页相加。

18.对象类型:
微对象tiny 0-16kb,小对象small 16-32kb,大对象>32kb。

19.内存分配函数也是一个触发垃圾回收的入口。
20.gc由守护goroutine来执行。
21.经典垃圾回收算法有:标记-清楚、标记-压缩、半空间复制、引用计数等。
22.golang从1.8之后的垃圾回收算法为:并发三色标记法+混合写屏障机制。
黑色:自身可达且指向对象标记完成。
灰色:自身可达但指向对象未标记完成。
白色:尚未被标记,可能是垃圾。
23.使用广度优先遍历。
24.分级别的内存管理机制会将垃圾回收产生的碎片控制在内部。
25.golang的内存逃逸机制,判断对象的生命周期如果更长,就会转移到堆上。生命周期短的会被分配到栈上,随方法结束被回收。
26.强弱三色不变式。


27.插入写屏障保证强三色不变式。

28.删除写屏障实现若三色不变式。

29.因为屏障有性能损耗,所以无法用于栈对象,因栈是轻量级,且变化比较频繁。
30.混合写屏障。

31.跨栈的对象会进入堆中。


32.gc触发分为三类,1是定时触发,两分钟一次,2是对象分配时达到堆内存阈值,3是手动调用。


33.标记准备工作

34.开启的标记goroutine数量占p资源的25%,开启的标记goroutine会放到池子中。
如果p能被4整出,则按p的数量进行计算,否则按执行时间计算。
35.stop the world 将所有的p设置为stop状态。
36.开启写屏障后,对象会被放入缓冲队列中,在标记完成前取出置灰。
37.p在获取可执行goroutine时,会判断是否在gc阶段,保证p只会获得一次gc goroutine。
38.每种颜色的对象都在一个队列里。

39.每次弹出一个灰色对象,把他指向的对象变成灰色,把自己变成黑色。


40.标记模式:

41.对象是否在使用的标识利用mspan的bitmap。

42.标记的本质是修改mspan中bitmap的标记位。

43.扫描根对象是扫描每个goroutine对应的方法栈,会根据函数的入参进行扫描,如果是引用类型,才需要去判断其指向的对象。非指针类型利用函数销毁即可完成回收,指针类型才有可能引用堆上的对象。
44.每个函数栈都有一个bitmap,来标识参数。

45.通过heapArena可以实现从页到mspan的映射。

46.辅助标记,当goroutine有负债的时候,会先尝试从全局资产中窃取,如果窃取不到,就要进行辅助标记进行偿还。

47.标记终止。

48.清扫goroutine会在main方法中初始化,陷入阻塞,被终止标记唤醒,清扫完一个goroutine后就会让出p,直到所有goroutine清扫完成后重新陷入阻塞。
49.重新设置下次触发gc的阈值,阈值可通过用户设置,默认为100%。
50.将内存还给操作系统:runtime会启动一个回收协程,以1%cpu的利用率运行,持续回收内存。
利用基数树辅助查询。

string:
1.string会被分配到只读内存段,不可被修改,即使切换到unsafe类型。修改会重新分配内存。
2.stringstruct包含两个字段,str和len,str是内存的起始位置,len表示长度为多少字节。
mysql:
1.page页大小为4kb。mysql一次取16kb。

2.mysiam引擎叶子节点存储指针,类似于非聚簇索引,好处在于不会频繁导致页分裂,从而降低增删数据成本。
高性能MYSQL(学习笔记)—索引篇3_剧组索引-CSDN博客
3.mysql数据量到达两千万或三千万后性能会急剧下降,因为树的深度变身,io次数增加。
4.innodb三大特性:1.自适应哈希、2.buffer poll、双写缓冲区。
5.自适应哈希:1.不需要手动添加,2.底层是散列表,3.只使用等值查询。

6.buffer pool即缓冲池,由缓存数据页和数据块组成。默认大小128m。
7.page页大小为16kb,数据块为数据页的5%,大概800字节。
8.mysql通过哈希表判断数据页是否在缓冲池中。

9.配置页会根据状态分为三种,通过三个链表进行管理。
freelist表示空闲缓冲区,管理freepage,只保存对应的控制块。
flushlist表示需要刷新到磁盘的缓冲区。管理dirty page。指被修改过的page页。
lrulist表示正在使用的缓冲区,用来管理没有被修改的数据页cleanpage和dirtypage。

10.写缓冲区change buff是针对二级索引页的更新优化。占用的buffer pool的空间。
如果要更新的页没有在缓存中,就会先把更新操作缓存起来。查询时如果更新操作在缓存中,就更新到页离。

11.写缓冲区只适用于非唯一索引,因为唯一索引需要做唯一性校验,需要io页。
12.传统lru算法存在的问题是,当进行大范围数据查询时,会将真正的热数据替换掉。mysql的预读也会影响真正的热数据。
13.优化过的lru分为热数据和冷数据区,数据新进来的时候插入到冷数据的头部。
如果存在时间超过1秒钟,就会将它移动到热数据的头部。

14.索引最好不要超过五个字段。
15.创建索引的原则。

16.page页分为几种:数据页,undo页,系统页,事务数据页等。
fileheader:文件头,描述页信息。
pageheader:记录页的状态。
infimun和supermum records用来记录比行记录主键都小的值和比行记录主键都大的值。
user records:记录的是实际行的记录。
free space:记录空闲空间。
page directory:查找page页记录的信息。
file trailer:检测数据完整性。
17.页整体分为三个部分,通用部分(文件头和文件尾)、存储记录空间、索引部分。
通用部分有指向上一页和下一页的指针。
18.数据页中的行记录由记录头使用单向链表串联起来,page directory实现了目录功能,可以使用二分查找。

19.mysiam的索引都是指向数据存储的地址的,因此也不存在回表。
20.聚簇索引和非局促索引的区别。

21.全文索引

22.联合索引创建时,mysql会根据最左边的字段进行排序,所以要查询时要遵循最左原则。
23.索引下推:在遍历的过程中进行判断,减少回表次数。

24.想解决%在左边的模糊查询索引失效问题,使用覆盖索引。会从全文扫描变成全索引扫描。
25.自增id的缺点:高并发情况下竞争自增锁。
26.页插入大小到15/16时就会插入下一个页,留下的空间为以后更新用。
27.b树主要用于文件系统及部分数据库索引,如mogodb。
28.根节点保存在内存中,其余节点保存在磁盘。
29.一个b+树能存储的最大数据量。

30.explain用于模拟sql的执行过程。

31.分页查询在偏移量固定时,随返回条数性能下降,同理,在条数固定时,随偏移量增加性能也下降。因为分页查询每次都是从第一条开始扫描。
32.优化方案:1.利用滚动翻页。2.利用子查询,实际上与1一致。

33.排序有全字段排序和rowid排序两种。
redis:
sds:
1.redis中的string为sds类型,即动态字符串。
2.redis不使用c中的字符串是因为:1.获取长度困难,2.非二进制安全,3.不可修改。

3.sds可以进行扩容。

intset:
4.intset是set集合的一种实现方式,基于整数数组实现,具备长度可变和有序性。

5.contents存储的是指针,真正的数字大小由encoding决定。
6.存储的元素所占字节一样,是为了方便寻址。
7.超过预定大小会进行类型升级,整个数组都要统一类型,倒序重新放置。
8.插入时使用的是二分查找,找到要插入的位置,后面的元素后移。

dict:
9.dict由3部分组成:1.哈希表,2.哈希节点,3.字典。

求一个数的余数,相当于&该数-1。sizemask的用处。

10.如果有hash冲突,新来的元素会占据头位置。
11.dict在每次新增时会检查是否需要扩容,根据元素个数/数组长度来计算出负载因子。
12.如果是新建的hash表,初始大小为4.

13.扩容会在原基础上+1,寻找到大于该数的2的n次方的数。
14.在删除元素的时候会检查用不用收缩,负载因子小于0.1进行收缩。
15.收缩最小不能小于初始化长度4.

16.dict中有两个hash表,扩容时会创建新的放到ht[1],等迁移完成后,重新放到ht[0]。
17.扩容时渐进式进行的,每次增删改查时,迁移一个位置。


ziplist:
18.ziplist是压缩列表,使用连续的内存模仿双端链表,可以省去指针占用的内存。

19.entry的长度是不固定的,以此来达到节省空间的目的。

20.查询数据必须遍历,会有性能的损耗。所以ziplist长度不宜过长。

21.连锁更新也会造成性能损耗。


quicklist:
22.结构为双端列表,用于解决ziplist的长度限制问题,每个节点都是一个ziplist。



skiplist:
23.最多允许32级指针。



redisObject:
24.redis中任意的键值都会被封装成redisObject。

25.每个对象头都有固定的空间占用,存储多个string占用的空间比用list要大。

string:
26.string有三种编码方式,如果存储的是数字,则不需要sds对象。如果是字符串,有raw和embstr两种编码方式,raw编码时对象头和sds的内存是不连续的,通过指针指向。embstr编码时,内存是连续的。

27.选择44字节进行判断是为了方便内存分配,object信息+存储的信息=64,正好是内存的一个分片,可以避免内存碎片。

28.使用object encoding命令可以查看key的编码方式。
list:
29.list类型可以从首尾操作元素,使用quicklist实现。
30.默认ziplist为8kb,压缩等级为1,首尾各有一个节点不压缩。
set:
31.单列集合,元素唯一,不保证顺序,可以求交并集。
32.set需要经常判断元素存不存在,所以链表结构不适合查询。
33.使用哈希表,即dict。value统一放null。
34.如果存入的都是整数,且元素数量不超过阈值,使用intset。

35.intset编码后续有可能转为dict。

zset:
36.zset同时使用dict和skiplist。


37.当数据量过小时,会使用ziplist作为底层结构。

hash:
38.hash和zset一样,在数据量小的时候用ziplist,数据量超过阈值,使用dict。

内核态和用户态:
39.提高io效率核心要解决的问题是等待时间和拷贝时间。

io模型:
40.五种io模型
阻塞io:在数据没有到达时会陷入阻塞。
非阻塞io:循环调用数据有没有到达,到达后拷贝数据也会陷入阻塞。
io多路复用:利用单线程同时监听多个fd,即文件描述符。
select、poll在有数据到达时不知道具体的fd是哪个,epoll是直接知道的。



41.select有数量限制,poll没有数量限制。


42.select底层使用的bitmip上线1024,poll底层使用的链表,虽然无上限,但是过长会影响性能。epoll底层使用红黑树。

43.异步io也是比较好的方式,只是用户代码实现需要考虑并发问题。

44.redis多路复用会监听3个时间,客户端连接,客户端可读,客户端可写。

45.单线程模型的瓶颈主要在读数据。引入多线程进行读写客户端请求和解析命令。
过期策略:
46.每个redis的db都是一个redisDb对象,里面包含多个dict字典。

47.redis过期使用惰性删除。访问key的时候如果过期则删除。
48.周期删除:定时抽样部分过期数据进行删除。

49.周期删除有两种模式。


淘汰策略:
50.redis是在每次处理命令之前,检查内存。

51.每个redisObject对象中都会记录key的访问时间或访问次数,根据根据配置不同,记录信息不同。

52.redis使用的不是严格的lru和lfu,每次是挑选样本进入淘汰池,从淘汰池中淘汰。因为池子会满,所以最后会趋近lru和lfu。

哨兵模式:



53.redis快的原因,纯内存操作、单线程无上下文切换、渐进式rehash、缓存时间戳、多路复用。
扩容也是两倍扩容,利用空间换时间,有两个数组,交换使用。
获取时间戳是系统调用,所以redis有定时任务来缓存时间戳。
54.redis为什么不用多线程:1.redis的性能瓶颈不在cpu,在内存和网络。使用redispipeline可达到每秒钟百万请求。
55.redis高级功能:1.慢查询,2.pipeline,3.watch,4.lua脚本
56.redis的事务是弱事务,不支持回滚操作,只能做语法判断。

57.看门狗问题。

58.redis和memcache。redis是支持集群的。memcached是预申请内存。

59.过期key有可能造成主从不同步。

60.hyperloglog的每个输入都会进行hash转换成二进制串。
每一个二进制串,我们都可以看作是一个伯努利过程。
每个二进制位可以当做硬币的正反面,通过出现1的次数,估算进行了多少次投币。
【Redis笔记】一起了解 Redis 中的 HyperLogLog 算法?-CSDN博客
61.rdb为快照,不适合实时持久化,有数据丢失问题。
aof的效率没有rdb高。
生产可以使用混合模式。
62.mysql和redis数据一致性的保证,容易出现的问题。

63.redis集群功能的限制。

64.集群不可用情况。

65.redis分槽使用的是一致性哈希的改进,虚拟一致性哈希。
66.redis槽一共16384个,不设计更多的槽是因为在1000个节点的情况下,16384个槽就够用了,如果节点过多,节点间通信会占用大量的网络带宽。
67.redis的哈希槽使用bitmap进行存储。
68.redis集群写入数据有可能丢失,redis不提供数据一致性保证。
69.提升redis性能。
主节点不开启持久化,从节点进行持久化。数据比较重要,主节点就使用aof。
主从复制速度的保证,尽量在同一内网。
70.数据更新之前被度去过两次,可以成为热数据。
71.redis阻塞的情况:1.来自客户端的命令执行耗时,如keys*,hgetall等。2.大key的获取和删除。3.清空库,4.aof同步写。
etcd:
raft协议:
1.etcd是一个键值对存储组件,可以实现配置共享和服务发现。
2.etcd满足cap理论的c和p指标。
3.etcd内部通信使用grpc。
4.使用mvcc将数据记录在boltDB中。
5.etcd中的数据提交前都会先记录到日志中。
6.利用日志和快照机制实现故障恢复。
7.raft算法需要超过半数节点同意,不包括半数。
8.预写日志保证了操作顺序,保证最终一致性的核心。
9.数据足够新的follower才能竞选leader。
10.leader在发送预写日志时,会带上上一个预写日志索引。
11.索引包含任期和索引。
12.如果缺少索引,会向主节点请求。
13.如果日志索引超前,从节点就会删除超前日志,以主节点为准。
14.索引有两个,一个是apliedindex,一个是commitindex。
15.解决读不一致性的方案,1:都从leader节点读,2:写入时主节点返回最新的index,读的时候带上。
16.写记录现在leader执行,然后通知follower,得到响应后提交。
17.如果有两个leader,在收到消息后,会判断任期,如果自己更靠前,则拒绝,让另一个leader退位。

18.follower中会有定时器,一段时间没有收到leader的心跳,就会发起选举。
19.发起选举时,如果任期相同,会判断索引大小,索引大于等于自己,就会同意,否则拒绝。
20.如果拉票超时,就会增加任期值,从新发起。
21.配置变更和增加节点都需要leader节点同步。
22.节点变更期间的选举,只有老节点可以参与投票,处理请求也是如此。
23.为了解决瓜分选票造成的无限循环问题,在心跳超时和选举超时时间上会加上扰动值。
24.每个leader上任后,必须提交一笔自己任期内的写数据操作。
25.leader向follower同步数据,超时会进行重发。
26.通过幂等处理leader成功提交,但未完成响应客户端的情况。
27.为了规避无意义竞选,follower在发起竞选前,会提前试探,有多数派回复,确认自己网络没有问题,才会竞选。
28.ack重试机制保证客户端数据不丢失,幂等序列号,保证请求的唯一性。
etcd实现:
29.etct结构分为应用层和算法层。

30.应用层和算法层都使用for+select监听对方的消息。

31.算法层本质上是一个节点状态机。
32.两次提交指的是预写日志提交和真实提交。
33.预写日志有两种类型,一种是配置变更如节点增加或减少,另一种是正常写请求。

34.预写日志会被封装到message中。message有多种类型。

35.算法层只能对持久化日志进行查询,真正的持久化是在应用层做的。

36.算法层会将预写日志先缓存在内存中,收到应用层可提交的消息后,通知应用层持久化。

37.node是应用层和算法层通信的入口。

38.强制读主的方式需要leader去自证自己是主节点,没有出现分裂。
39.raft是算法层的核心类。

40.应用层是提供服务的入口。

41.etcd默认是线性读。


42.数据持久在boltDB中。



43.mvcc是一种乐观锁。不能解决更新丢失问题。
44.读请求会请求leader拿到最新的index,然后判断自己的节点是否和最新的一致。
45.在 etcd v3 中引入 treeIndex 模块正是为了解决这个问题,支持保存 key 的历史版本,提供稳定的 Watch 机制和事务隔离等能力。
46.etcd 在每次修改 key 时会生成一个全局递增的版本号(revision)。
然后通过数据结构 B-tree 保存用户 key 与版本号之间的关系;
再以版本号作为 boltdb key,以用户的 key-value 等信息作为 boltdb value,保存到 boltdb。
47.当etcd服务器重启后,内存中的treeIndex数据确实会丢失,因为treeIndex是内存中的数据结构,用于快速索引和查找键值对。但是,etcd具有持久化存储机制,它将数据写入磁盘以在重启后恢复数据。
具体来说,etcd使用一种称为WAL(Write-Ahead Log)的机制来持久化数据。每当在etcd中进行更改(比如添加、更新或删除键值对)时,这些更改会被追加到WAL日志中。WAL日志是一个顺序写入的日志文件,它确保了数据的持久性和一致性。
在etcd启动时,它会读取WAL日志文件并重新构建内存中的树状结构。
48.在treelndex中,每个节点的 key是一个keyIndex结构,etcd就是通过它保存了用户的key 与版本号的映射关系。

49.那么 key 打上删除标记后有哪些用途呢?什么时候会真正删除它呢?
-
一方面删除 key 时会生成 events,
Watch 模块根据 key 的删除标识,会生成 对应的 Delete 事件。 -
另一方面,当你重启 etcd,遍历 boltdb 中的 key 构建 treeIndex 内存树时, 你需要知道哪些 key 是已经被删除的,并为对应的 key 索引生成 tombstone 标 识。
而真正删除 treeIndex 中的索引对象、boltdb 中的 key 是通过压缩 (compactor) 组件异步完成。
正因为 etcd 的删除 key 操作是基于以上延期删除原理实现的,因此只要压缩组件未回收历 史版本,我们就能从 etcd 中找回误删的数据。
50.在 etcd v3 中,为了解决 etcd v2 的以上缺陷,使用的是基于 HTTP/2 的 gRPC 协议,双向流的 Watch API 设计,实现了连接多路复用。
在 HTTP/2 协议中,HTTP 消息被分解独立的帧(Frame),交错发送,帧是最小的数据单位。每个帧会标识属于哪个流(Stream),流由多个数据帧组成,每个流拥有一个唯一的 ID,一个数据流对应一个请求或响应包。
50.etcd 的确使用 map 记录了监听单个 key 的 watcher,但是你要注意的是 Watch 特性不仅仅可以监听单 key,它还可以指定监听 key 范围、key 前缀,因此 etcd 还使用了如下的区间树。
当收到创建 watcher 请求的时候,它会把 watcher 监听的 key 范围插入到上面的区间树中,区间的值保存了监听同样 key 范围的 watcher 集合 /watcherSet。
51.定时自动淘汰(leader做的)
leader 在 etcd server 启动时会启动一个 goroutine RevokeExpiredLease() , 每 500ms 检查一次。
使用 最小堆 管理 lease,按到期时间升序排序,每次检查时从堆顶取出元素,检查lease过期时间
52.Checkpoint 检查点机制(leader做的)
leader 在 etcd server 启动时会启动一个 goroutine CheckpointScheduledLeases(),每 500ms 将 lease 的 ttl 通过 raft 同步给 follower
RabbitMQ:
1.4种交换机类型。




2.消息可靠性保证。

3.生产者确认有两种方式,同步和异步。
4.如果没有开启消息持久化,当内存满了,mq要将一部分数据迁移到磁盘,会造成阻塞。

5.数据可靠性保证有两种方式1:数据持久化,2:lazyqueue。



5.消费者确认机制。

6.消息失败可以先在本地重试,不要直接重新投递给mq。
7.利用死信交换机实现延迟队列。


8.底层使用最小堆实现。
9.RabbitMQ 的元数据都是存在于 Erlang 自带的分布式数据库 Mnesia 中的。
10.在实现上,每台 Broker 节点都会保存集群所有的元数据信息。当 Broker 收到请求后,根据本地缓存的元数据信息判断 Queue 是否在本机上,如果不在本机,就会将请求转发到 Queue 所在的目标节点。
11.Mnesia 本身是一个分布式的数据库,自带了多节点的 Mnesia 数据库之间的同步机制。
12.如果消费者(处理消息的程序)连接到节点 B 来读取队列的消息,节点 B 会自动把这个请求转发到节点 A,因为队列存在于 A。
13.集群模式可以为节点添加镜像队列节点,同步节点的数据。
镜像队列可以让队列的数据在多个节点之间复制。例如,你可以让队列的副本同时存在于节点 A 和 B 上。这样,即使节点 A 挂了,节点 B 依然有该队列的完整副本,可以继续处理消息。
14.不支持有且仅有一次的保证。
15.RabbitMQ 从队列中取出待处理的消息,并将其分发给消费者 A。
消息的状态在分发后会被标记为“正在处理中”,即消息进入了一个冻结状态。
16.RabbitMQ 使用文件来存储持久化消息。这些文件通常位于 RabbitMQ 的数据目录(如 /var/lib/rabbitmq/mnesia/)中,文件格式通常是二进制格式,专门设计用于高效存取和存储消息。
17.队列元数据:队列的元数据也会被持久化到磁盘中,包括队列的定义、绑定信息等。这些数据存储在 Mnesia 数据库中,这是 RabbitMQ 用来管理内部状态的数据库。
es:
1.非关系型文档数据库。
2.pb级数据秒级查询。
3.稳当是json格式。
4.mapping中的类型,数字类型,keyword:精确查找不进行分词,text:文本类型会被分词,时间类型,alias:别名。另外还有结构类型,如坐标类型。
5.可以不定义结构直接写入数据,会动态判断自动创建。
6.映射方式分为自动和手动两种。
7.全文检索就是会被分词的检索。
8.检索和搜索的区别,检索是指相关度。
9.全文索引步骤:切词、规范化、去重、字典序。
10.将用户输入进行分词,每个词进行查询,命中次数最多的id,相关度就高。
11.should在和must或者filter同时出现时,should会失效。
12.filter是不计算相关度的,效率相对高一些。
13.嵌套查询:object、nested、join。
14.按查询准确度可以分为:1.全文检索match、2.精确查找term、模糊匹配:suggester、通配符正则等。搜索提示是基于suggester实现的。
15.match会进行分词搜索,term不会。
16.如果使用.keyword,查询的就是不分词的。

17.match和term是针对输入词的,keyword是针对源数据的。
18.评分算法:BM25和tf-idf。
19.倒排索引的存储结构为fst。
20.倒排表使用压缩算法:稠密数组for,稀疏数组roaring bitmaps。

21.通用最小化算法。
22.fst 和 trie字典树又称前缀树。
23.数据模型。
- 倒排索引:用于存储词项到文档 ID 的映射,优化了全文搜索。采用压缩的索引结构,如跳跃表、B+ 树或哈希表。
- 文档 ID 到文档的映射:存储字段以列式存储方式存储,确保快速提取所需字段。
- DocValues:为排序和聚合操作设计的列式存储结构,提供高效的数据访问。
- 段:包含上述所有结构的基本单元,每个段都是独立的索引,段合并优化了存储和查询效率。
24.段和文档的关系,段是不可修改的。
段存储的是文档数据,因此它们之间的关系可以这样概括:
- 文档被写入 Elasticsearch 时,Lucene 会将其组织到段中。段中包含多个文档,这些文档会按照倒排索引的方式被存储,便于高效检索。
- 每个段包含文档的多个部分,包括:
- 倒排索引(Inverted Index):文档中的词项(Token)到文档 ID 的映射,用于支持全文搜索。
- 存储字段(Stored Fields):文档的实际内容(如 JSON 格式的数据),以便在搜索时返回文档的原始数据。
- DocValues:用于排序和聚合的字段值。
- 删除标记(Delete Markers):如果文档被删除,则该文档不会立即被物理删除,而是在段中添加删除标记,直到段合并时才真正删除这些标记的文档。
25.FST 的作用是:
- 通过快速查找定位词项在倒排索引中的位置;
- 一旦定位到词项,倒排索引会提供对应的文档 ID 列表,这个列表可以包含与该词项相关的所有文档。
26.每个文档存储在某个 段(Segment) 中,每个段会存储文档的元数据以及文档的实际内容。Elasticsearch 会根据文档 ID 查找到具体的段文件,然后在段文件中读取该文档的内容。
27.每个文档都有一个全局的文档 ID(用户提供的 ID),而 Lucene 内部为每个段中的文档分配一个局部的 DocID,这个 DocID 仅在段内部有效。
28.查询示例。
- 段扫描顺序:通常是从旧到新,或者从小到大,但实际操作中可能会并行扫描多个段。
- 并行扫描:多个线程可以并行扫描不同的段,以提高查询效率。
- FST 和倒排索引:在每个段中,首先使用 FST 查找关键词,然后使用倒排索引获取匹配的文档 ID。
- 结果合并:最终结果会在所有段的匹配结果中合并、去重和排序后返回给用户。
29.数据先写入内存buffer中,当到达时间阈值或空间阈值时,会写入到索引段文件中,段文件将数据放入到OS Cache中。
30.当数据放入到OS Cache中后,索引段文件将处于open状态,此时数据就可被查到了。
31.当OS Cache数据达到阈值,会fsync到磁盘中。
32.读写分离的意义在于减小磁盘的读写压力。
33.commit point会将段文件进行合并。
34.数据写入内存buffer中时,会同步写入到tranlog中,以保证数据的完整性。

35.es多节点写入流程。请求的节点会找到写入数据对应的主节点,写入主节点之后,主节点同步副节点,副节点完成写入后,通知主节点,主节点将结果通知请求节点,请求节点响应客户端。
36.拼写纠错和模糊查询利用fuzzy实现。fuzziness步长最大为2。不指定的话为auto,会根据字符总长度来给定。

37.距离算法为damerau-莱文斯坦距离。
38.多个分片组成一个index,每个分片都是一个单独的lucene实例。
39.主分片可读可写,副本分片是只读的。
40.分片创建策略:分片在创建之前要指定分片的数量和大小。
分片的分配策略:要尽可能均匀的分配到不同的节点上。
再分配策略:当有节点加入或离开时,会重新分配。
延迟分配策略:再分配会延迟一分钟执行。
分片的数量策略:不宜太多或太少。
分片的大小策略:10-50g
41.1gb堆内存能管理的分片在20左右。
42.两个节点不具备选举能力,稳定的集群至少需要三个节点。
43.索引的组成部分。

44.索引的分片的数量和副本的数量是在settings中设置的。
45.索引有三种含义:1.es的index,2.索引文件,3.动词写入数据。
46.es会有两个进程定时检查主节点和副节点的存活状态。masterFD和nodesFD。通过其他节点给master节点发送请求。
47.当副节点发现master节点失联,或者主节点能联系到的副节点小于n/2+1会发起选举。
48.从配置了master角色的节点中选举。

49.fd发起请求,找到响应请求的所有节点,不包括发起的节点。经过过滤找到符合选举的节点。
如果已经存在活跃master,而且不是自己,则停止。
判断候选节点是否满足指定票数。

50.选举完成后要将节点信息分发到每个节点。
51.集群节点数量为偶数时,es会使一个节点失去选举权,避免脑裂。
grpc:
1.四种模式:单一模式,客户端流,服务端流,双向流。
2.基于http2实现。http支持流和帧的多路复用。
分布式:
1.补偿性事务:
TCC的核心思想是:针对每一个操作都需要注册一个和其相对应的确认和补偿的操作,他分为三个阶段Try、Confirm和Cancel
2.分布式事务使用base理论,实现最终一致性。

3.分布式唯一id:
uuid、数据库子增、批量生成id、redis生成id、雪花算法snowflflake。
4.负载均衡算法:
轮询、加权轮询、随机轮询、最少链接(适用redis实现)、源地址散列(适用session和长链接)
5.计数器,即固定窗口算法。
适用redis的incrby和过期时间实现。
风险在于无法应对突增。如服务器限流60,在00:50有50个请求,在01:00有50个请求。
6.滑动时间窗口
将窗口分为小粒度的几个固定时间窗口,进行计算。
7.漏桶算法

8.令牌桶算法

9.数据库处理大数据
分区、分库、分表、读写分离。
10.服务熔断,服务熔断为了解决服务雪崩,如a->b->c->d,如果d有问题卡住,调用链路都会卡住。
触发熔断之后需要添加标记,后续走降级策略。
11.降级和熔断
熔断会触发降级,但降级还有多种情况。

12.提升系统并发能力
分流:负载均衡、消息队列、数据库拆分
导流:缓存、cdn
13.微服务划分:准确识别系统隔离点也就是系统边界。

14.最大努力消息通知
消息重复通知、消息可查询校对。
内部系统可使用消息队列,外部系统暴露接口。
15.解决缓存不一致问题(cache-asid),使用read/write through,即写入数据时直接写入到缓存中,再由缓存同步数据库。
项目启动时先从数据库读取到缓存中。
gin:
1.基于http/net包实现。
2.gin的特点。支持中间件headlerschain,方便的使用gin.context 并发安全的,路有数radix tree。
3.gin和http包的关系。
蓝色代表gin的功能,红色代表gin的结构,黄色代表http包。

4.gin.engine结构。

5.gin.engine是实现了http接口的实例。
6.sync.pool中包含Context,用来复用。每个请求都会分配一个Context。
7.如果池子里有Context,将会把数据清空,用来复用。
8.自动清理的能力,当两轮gc之后,还未被用到的Context就会被清除。
9.routergroup中所有的配置会被这个组中所有的成员共同使用。会在自己路径之前拼接上routergroup的路径。
10.routergroup中的中间件也会被成员共同使用。
11.engine中会有九棵压缩树,对应http的九种请求,节点会根据路径挂载在树上,当请求到达时,再通过树去查找对应的headers。

12.所有实现了http包handler方法的结构体,都可以被注入到net的框架中。
13.routergroup中表示是否是根节点。默认分配为是。

14.在engine被创建出来时,会初始化Context池。
15.使用中间件会将中间件添加到group所对应的handler的切片中。
16.注册handler流程。

17.核心就是把自己当做http的实现类。
18.http启动之后会循环监听对应的端口,每次调用端口端口监听器的accept方法。使用epoll技术。
19.针对到达的请求会分配goroutine去服务,找到启动时注入的handler,也就是gin的实现。
20.gin框架处理流程。

21.Context用完之后没有进行清理,获取时才执行清理。
22.根据请求的方法找到对应的请求压缩前缀树,从前压缩前缀树中找到对应的处理链条。
23.获取到链路后会挂载到对应的Context上。承载请求参数和处理链条。
24.gin为什么使用压缩前缀树,map适合单点操作,无法应付模糊。

25.补偿机制:每次都是从节点的左边开始遍历子树。
26.Context结构。

27.gin使用sync.pool实现Context复用。
28.sync.pool是物理意义上的缓存,但内存回收不稳定,需要两轮gc。
29.Context中index字段表示遍历到了哪个handlers。

30.最多只能注册62个handler。
31.用户可以在某个handler中调用Context.about。该方法会将index值设置为63。

redigo:
1.连接池使用双端链表存储。
2.获取时从头部获取。
3.close方法是将链接放回链接池,并不是关闭。
gorm:
1.内部使用很多反射,性能较低。编译阶段不容易发现问题。
2.builder设计模式,分为存储数据+处理数据两步。
3.高频重复拼接sql。
docker:
k8s:
1.kube-proxy ipvs和iptables的异同。
都是通过netfilter内核进行转发的。
iptables是为防火墙设计的,ipvs是专门用于高性能负载均衡。使用更高效的hash表结构。
ipvs有更好的性能和扩展性,支持更复杂的负载均衡算法,支持服务健康检测和连接重试的功能。
支持动态修改ipset设置。
网络:
1.tcp/ip网络分层架构。

2.tcp四次挥手。

如果减少为3次,服务端将客户端fin的响应和自己fin的响应合二为一,中间可能会有延迟,因为http是可靠传输,客户端会不停地发起fin请求,造成资源浪费。
3.凡是对端的确认,无论客户端确认服务端,或者服务端确认客户端,都要消耗tcp报文的序列号。因为有重试的行为。
4.半连接队列和syn flood洪泛攻击,

5.tcp fast open利用cookie减少一次请求的往返。

6.tcp报文中时间戳的作用。计算往返时间和解决序列号重用问题。

7.重试时间如何计算,
平滑往返时间。根据上次的重传时间进行计算。适用于波动比较小的时候。

8.tcp流量控制。对于接收方和发送发,都需要把数据放在自己的缓冲区。交互时会将自己的缓冲区大小告诉对方。
缓冲区使用滑动窗口进行。

9.keep alive会定时检查链接存活状态,但是需要7200s,一般不用。

10.端口在传输层的头里面。一个是源端口,一个是目标端口。
临时端口是从48152-65535的。
11.tcp的确认号计算。

12.对应的协议。

13.消息边界

14.netstat用于显示网络连接信息。

15.命令行抓包工具tcpdump。
16.len长度为0的数据是握手和挥手数据。
17.windows抓包工具winreshark。
18.tcp和udp的区别。


19.http是无连接的,指的是交互完成后链接就断开了。
20.http是无状态的。
21.https是http+ssl/tls。
22.ssl+tls处于tcp/ip协议和应用层协议中间的位置。也可以说属于应用层。
23.服务端证书相当于公钥。
24.http1.0只能保持短暂链接,发送大文件需要多次握手。需要提供规范,connection,最常见的为keep-alive。只有get和post两种请求方式。
http 1.1是使用最广泛的协议,支持保持链接,默认包含keep-alive。不需要等待服务端返回就可以发送下一次请求。支持缓存的控制。
25.http2.0 支持多路复用,二进制分帧。
使用二进制传输。
首部压缩。第一次发送头部,后面发送头部的差异就行。
允许服务端推送。
26.cdn内容分发网络,中心平台服务器进行分发,分配到离你最近的边缘节点服务器。
27.在解析域名时,指向的是cname,即cdn的节点,而不是源服务器。
28.cdn全局负载均衡,会根据用户ip找到用户的真实地址,根据用户的真实地址,运营商和节点的压力,为用户分配合适的节点。
29.cdn缓存,如果发现用户请求的资源在缓存中有,会直接返回。命中率在90以上。
30.域名。