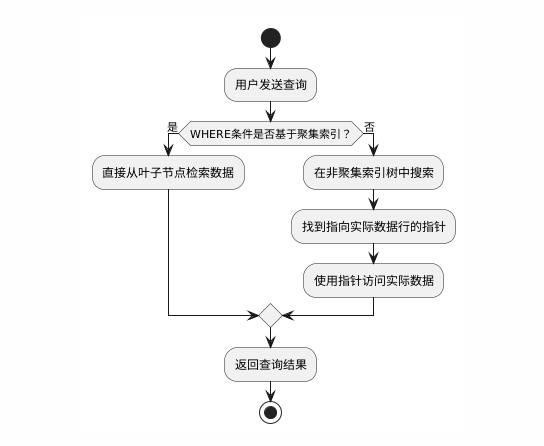
今天我给大家分享一个超实用的小工具,真的是太好用了!这个软件是吾爱大神@无知灰灰制作的,它能直接一键把webp格式的图片转换成png格式。
webp转为png
一键操作,支持压缩
其实,作者最近在工作中经常遇到webp格式的图片,下载后还得一个个转换,特别麻烦。所以,他就写了这么个小工具,方便大家用起来。
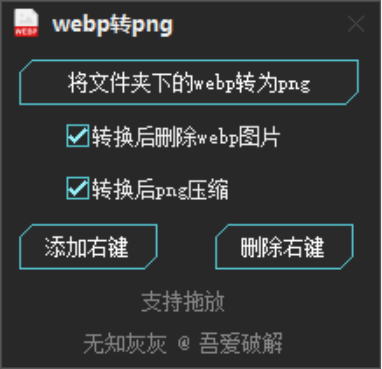
这个软件可以把转换功能直接添加到右键菜单里。
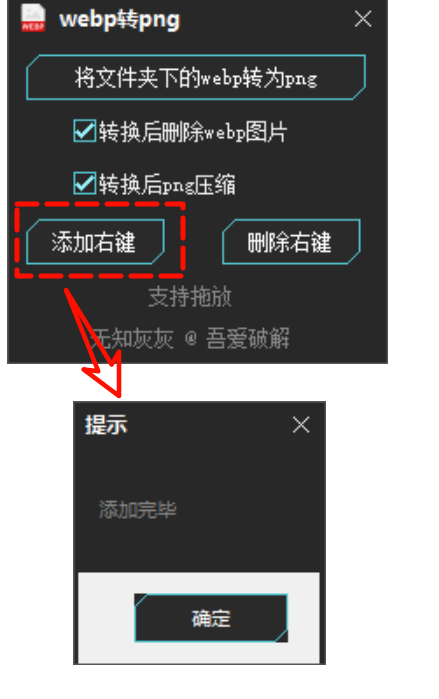
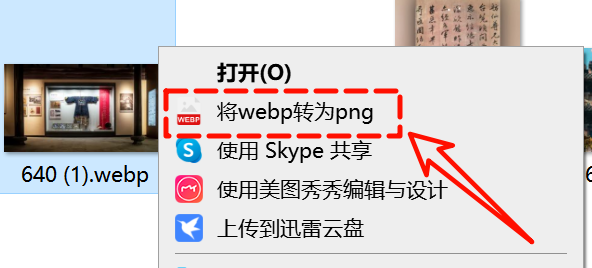
你只需要右键点击图片,轻轻一点,PNG格式的图片就会自动生成。不过,这里要提醒大家一下,这个操作默认是会压缩图片的。

打开软件后,你可以批量选择文件,直接拖到软件界面上,就能批量转换。

如果你希望图片保持原尺寸,记得在软件里把压缩选项取消勾选。

我试用了一下,发现图片的尺寸真的没有被压缩,大家可以放心使用。
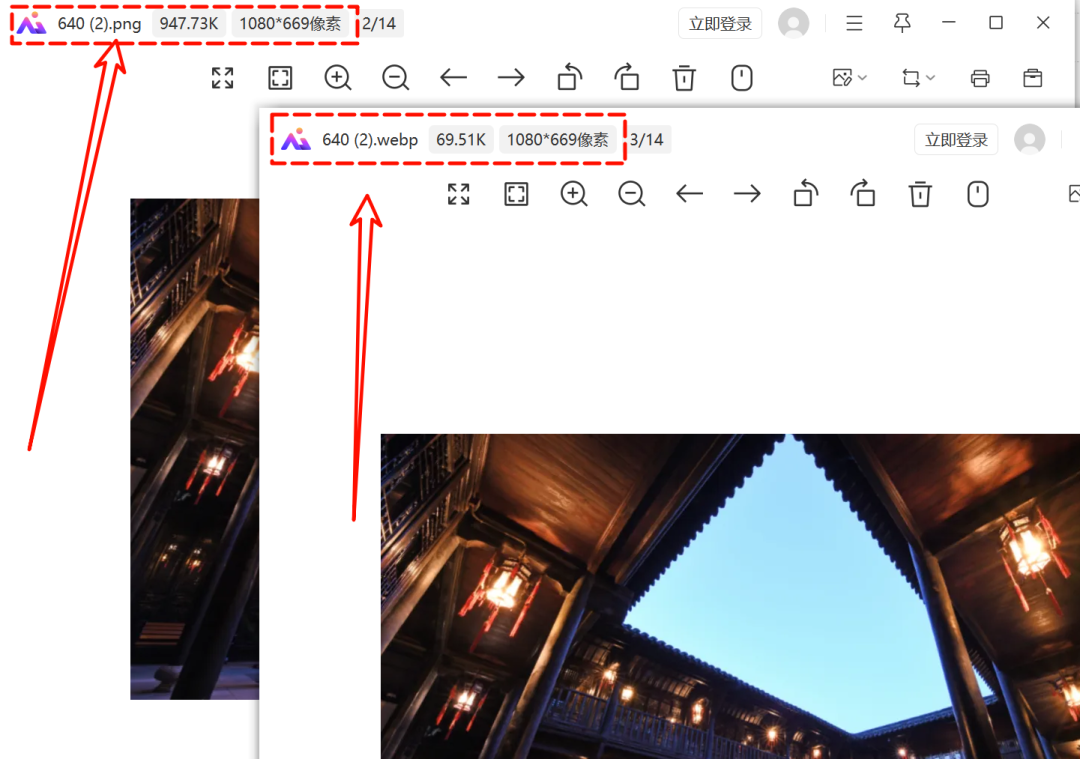
有了这个小工具,以后再也不用费劲去网页上转换webp格式的图片了 。
软件下载链接:
夸克网盘分享